目录
一、项目介绍
二、内存池介绍
2.1、池化技术
2.2、内存池
2.3、内存池主要解决的问题
三、malloc了解
四、设计定长内存池
五、和new(实际malloc)对比性能测试
一、项目介绍
当前项目实现的高并发内存池原型是goole的开源项目tcmalloc,tcmalloc全称为Thread-Caching Malloc,即线程缓存的malloc,该项目实现了高效的多线程内存管理,用于替代系统的相关内存分配函数(malloc free)。
malloc实际就是一个内存池,为什么还要实现tcmalloc,原因时tcmalloc是用于优化C++写的多线程应用,比glibc.23的malloc块,这个模块可以用来让MySQL在高并发内存占用更加稳定(多线程环境下比malloc快)。
优点是相比malloc在多线程管理下能做到更高效的内存管理,替代malloc和free。
二、内存池介绍
2.1、池化技术
"池化技术",就是程序先向系统申请过量资源,然后交由自己管理。之所以要申请过量资源,是因为每次申请内存的时候会有较大的开销,提前申请好内存,需要时使用,可以大大的提高程序运行效率。
在计算机中,除了内存池,还有连接池、线程池、对象池等都用到了池化这种技术。以服务器上的线程为例,它的主要思想是:启动诺干数量的线程,让他们处于睡眠状态,当接收到客户端的请求时,唤醒池中某个睡眠的线程,让它来处理客户端的请求,当处理完这个请求,线程又进入睡眠状态。
2.2、内存池
内存池是指程序预先从操作系统中申请一块足够大的内存,此后,当程序中需要申请内存的时候,不是直接向操作系统申请,而是从内存池中直接获取。同时,当程序释放内存的时候,也不是真正将内存返回给操作系统,而是返回给内存池,当程序退出时,内存池才会将之前申请的大块内存真正释放。
2.3、内存池主要解决的问题
1、效率问题
避免程序频繁向系统申请资源而产生较大的开销,自己提前申请足够内存供自己使用,可以提高程序运行效率。
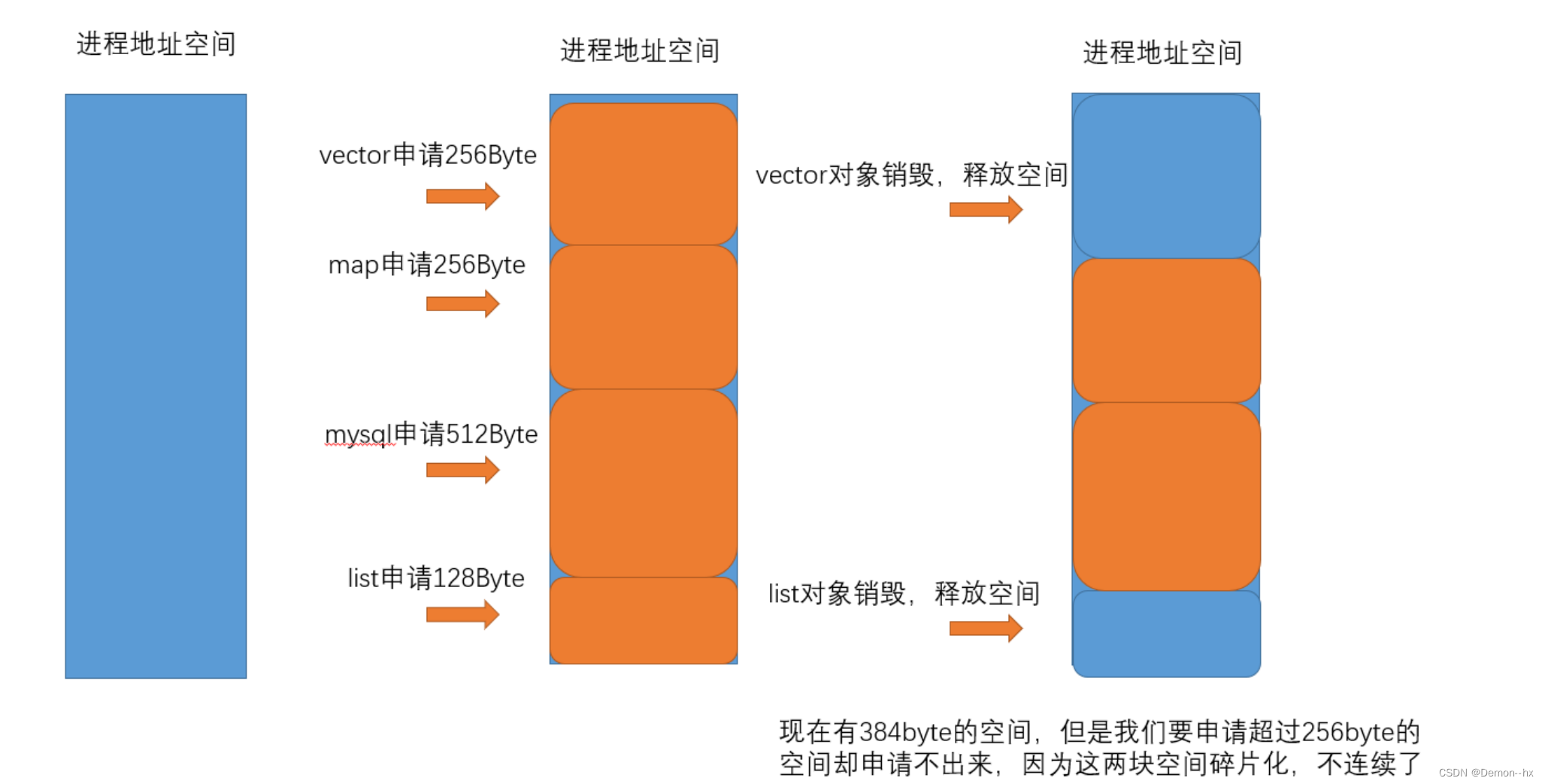
2、内存碎片问题
在系统的内存分配器的角度,需要解决内存碎片问题,内存碎片有内碎片和外碎片两种。
内碎片问题是由于一些对齐需求,导致分配出去的空间中有一些内存无法被利用(部分小块空间利用不上)。
目前先介绍外碎片,所谓外碎片问题,是指一些空间的连续内存区域太小,这些内存空间不连续,以至于即使有足够的内存空间,也无法满足一些内存分配申请的需求(一段连续空间被切出去好多快,但是只有部分还回来了,但是它们不连续,导致要申请超过某个空间申请不出来,即使总空间大于要申请的空间,也申请不下来)。
三、malloc了解
C/动态申请内存都是通过malloc区堆上申请内存,C++借助new/delete去堆上申请释放内存空间,new和delete里面封装的是operator new和operator delete,operator new要符合C++抛异常机制里面封装了malloc,因此在C/C++中申请释放内存块,最终还是使用malloc和free的。
但是我们要知道,我们实际不是区堆上获取内存的。通过调用malloc函数,malloc调用brk()向操作系统申请内存,操作系统执行brk()系统调用,再将申请的内存通过malloc返回。

而malloc就是一个内存池。malloc相当于向操作系统申请了较大的内齿空间,然后零售给程序使用。当全部零售完或者程序需要大量的内存需求时,再根据实际需求向操作系统中申请"进货"内存。malloc的实现方式有多种方式,不同的编译器平台用的都是不同的。例如windows的vs系统用自己的微软写的一套,linux gcc用的glibc中的ptmalloc。
四、设计定长内存池
尺有所短,寸有所长,任何事物都有其优缺点,使用malloc申请内存是广泛应用于各种场景的,但是在什么场景下都可以使用,意味着什么场景下都不会有很高的性能,定长内存池是高并发内存池后续使用的基础组件,本先了解实现该内存池的实现
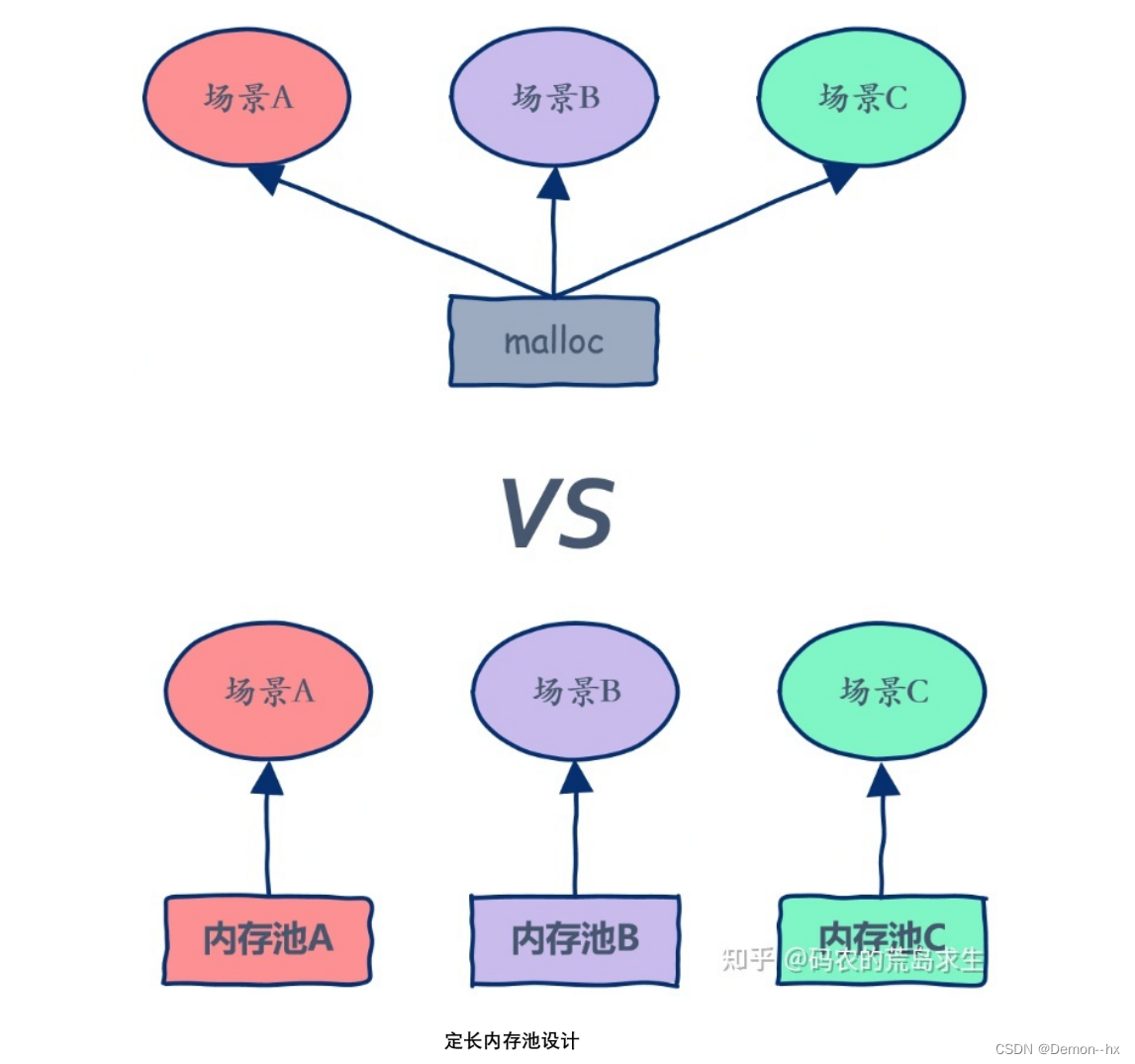
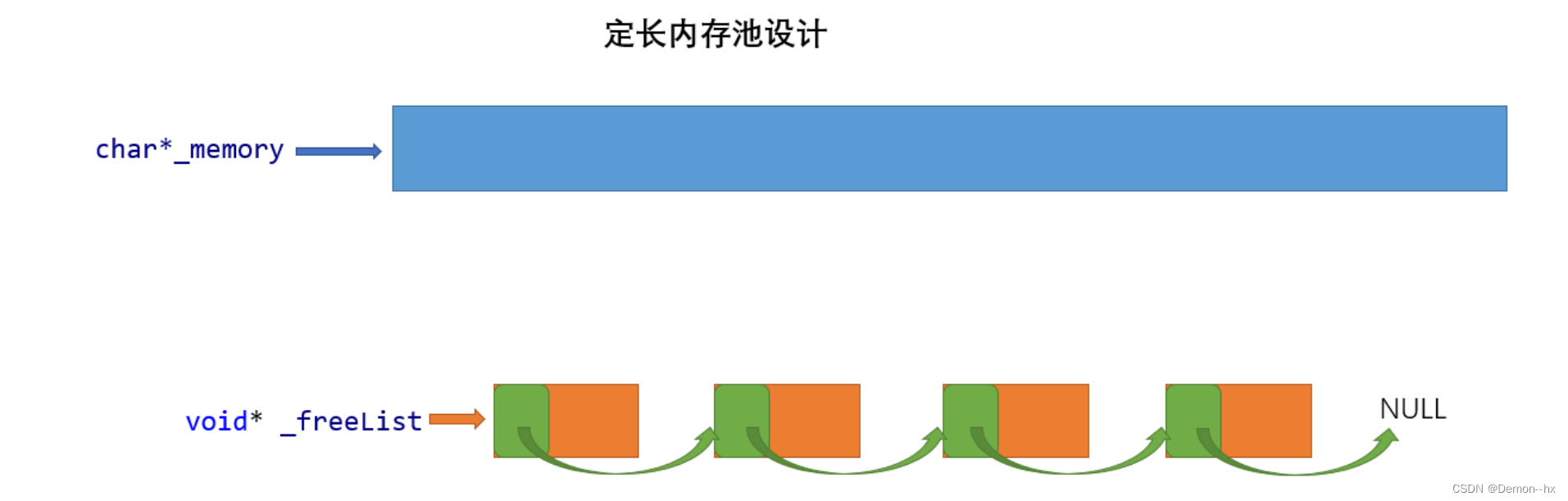
定长内存池可以满足固定大小的申请释放需求,特点是性能达到极致,不需要考虑内存碎片问题。
需要定义一个变量_memory指向申请的大块内存空间,当申请的固定大小内存用完返回后时候需要通过_freeList自由链表把还回来的内存块链接起来管理。
定长内存池可以通过malloc向系统申请空间,也可以直接向操作系统申请空间,window和Linux下可以直接向堆申请页为单位的大块内存。
windows用的接口是VirtuallAlloc,直接跳过malloc内存池,直接找堆按页为单位申请内存。
Linux通过调用brk()和nmap()向系统申请空间。
cLinux进程分配内存的两种方式--brk() 和mmap()
VirtualAlloc
#pragma once
#include<iostream>
#include<vector>
#include<time.h>
#include<stdlib.h>
using std::cout;
using std::endl;#ifdef _WIN32
#include<windows.h>;
#else
#endif//直接去堆上按页申请空间
inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32//kpage左移13位 为 128kvoid* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else//linux下brk mmap等
#endifif (ptr == nullptr)throw std::bad_alloc();return ptr;
}
template<class T>
class ObjectPool
{
public:T* New(){T* obj = nullptr;//_freeList不为空 优先把还回来的内存块对象重复利用if (_freeList){//将自由链表头指针赋值给obj对象指针//obj = (T*)_freeList;_freeList = *(void**)obj;/* void* next = *((void**)_freeList);obj =(T*)_freeList;_freeList = next;*/}else{//剩余内存不够一个对象大小时,则重新开辟空间//要被128*1024整除 刚好就是完整的对象//没有被整除 剩余的一小块不够一个对象来用//用_remainBytes<sizeof(T)来解决if (_remainBytes < sizeof(T)){_remainBytes = 128 * 1024;//_memory = (char*)malloc(_remainBytes);//128kb//128k右移13位 为 16页 _memory = (char*)SystemAlloc(_remainBytes>>13);if (_memory == nullptr){printf("malloc fail!\n");exit(-1);}}//面临问题://内存块可能用完 New申请时需要判断obj = (T*)_memory;//保证可以存下下一个对象的地址size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);_memory += objSize;_remainBytes -= objSize;/*_memory += sizeof(T);_remainBytes -= sizeof(T);*/}//定位new,显示调用T的构造函数初始化//对已经有的空间进行初始化new(obj)T;return obj;}void Delete(T* obj){//显示调用析构函数清理对象obj->~T();//obj的头四个字节存放自由链表的头指针存//更新头指针*(void**)obj = _freeList;_freeList = obj;//if (_freeList == NULL)//{// _freeList = obj;// *(void**)obj = nullptr;//}//else//{// //头插// *(void**)obj = _freeList;// _freeList = obj;//}}
private:char* _memory=nullptr;//指向大块内存块的指针size_t _remainBytes = 0;//大块内存块在切分过程中剩余的字节数void* _freeList=nullptr;//还回来过程中链接的自由链表的头指针
};五、和new(实际malloc)对比性能测试
#define _CRT_SECURE_NO_WARNINGS 1
#include"ObjectPool.h"class TreeNode
{
public:TreeNode() :_val(0), _left(nullptr), _right(nullptr){}int _val;TreeNode* _left;TreeNode* _right;
};
//测试定长内存池和new轮转释放内存效率
void PerformanceTest()
{//申请释放的轮次const size_t Rounds = 3;//每轮申请释放的次数const size_t N = 100000;size_t begin1 = clock();std::vector<TreeNode*> v1;v1.reserve(N);for (size_t i = 0; i < Rounds; i++){for (size_t j = 0; j < N; j++){v1.push_back(new TreeNode);}for (size_t j = 0; j < N; j++){delete v1[j];}v1.clear();}size_t end1 = clock();ObjectPool<TreeNode> TNPool;size_t begin2 = clock();std::vector<TreeNode*> v2;v2.reserve(N);for (size_t i = 0; i < Rounds; i++){for (size_t j = 0; j < N; j++){v2.push_back(TNPool.New());}for (size_t j = 0; j < N; j++){TNPool.Delete(v2[j]);}v2.clear();}size_t end2 = clock();cout << "new cost time:" << end1 - begin1 << endl;cout << "Object pool cost time:" << end2 - begin2 << endl;
}
int main()
{PerformanceTest();return 0;
}