大模型关键技术
- 大模型综述
- 上下文学习
- 思维链 CoT
- 奖励建模
- 参数微调
- 并行训练
- 模型加速
- 永久记忆:大模型遗忘
- LangChain
- 知识图谱
- 多模态
- 大模型系统优化
- AI 绘图
- 幻觉问题
- 从 GPT1 - GPT4 拆解
- GPTs
- 对比主流大模型技术点
- 旋转位置编码
- 层归一化
- 激活函数
- 注意力机制优化
大模型综述
你知道嘛,那个叫大规模语言模型,简单说就像是个超级大的脑袋,里头装的东西比咱们想的还要多,参数得有几百亿那么多。
这玩意儿就像是自学成才的,它通过看特别多的书、文章啥的,不需要别人教,自己就能学会说话和写字。
它的工作就像是个算命先生,总想算出来你下一句话可能会说什么。
比如有一堆词儿,它能算出这些词连一块儿说出来的可能性有多大。
就好像你掷个骰子,算命先生能告诉你可能掷出的点数一样。
要算这些词的联合可能性可不简单,因为要考虑的东西实在太多了。
就好比咱们手头有个《现代汉语词典》,里面有7万多个词。
你想,要是咱们随便组个20个词的句子,那可能的组合比天上的星星还多,数量大得惊人,高达 7.9792x1096 这么个天文数字。
要简化这个算法,咱们可以这么想:一个词出现的可能性,可能就跟前头几个词有关系。
就像咱们盖房子,一块砖接着一块砖,后面这块砖放的位置,得看前面几块砖放哪儿。
用一种叫前馈神经网络的方法,就能算出来每个词跟前面的词搭配的可能性。
例如,要算“把努力变成一种习惯”这句话的可能性,就是算“把”出现的可能,再算“努力”跟在“把”后面的可能,依此类推。
- P ( 把 努力 变成 一种 习惯 ) = P ( 把 ) × P ( 努力|把 ) × P ( 变成|把 努力 ) × P ( 一种 ∣ 把 努力 变成 ) × P ( 习惯 ∣ 把 努力 变成 一种 ) \begin{aligned} P(\text{把 努力 变成 一种 习惯})=& P(\text{把})\times P(\text{努力|把})\times P(\text{变成|把 努力})\times \\ &P(\text{一种}|\text{把 努力 变成})\times P(\text{习惯}|\text{把 努力 变成 一种}) \end{aligned} P(把 努力 变成 一种 习惯)=P(把)×P(努力|把)×P(变成|把 努力)×P(一种∣把 努力 变成)×P(习惯∣把 努力 变成 一种)
恩,这就是大语言模型,就像是个自学成材的超级计算机,它能通过看大量的书和文章,自己学会怎么用词造句。
这模型的本事就是算出来你下句话可能说啥,就像个现代算命先生。
但因为要考虑的可能性太多,就像是从词典里随便拼凑出天文数字那么多的句子一样,所以得用一些巧妙的方法来简化计算。
这就像盖房子,一块砖一个脚印,后面的得看前面的摆放。
用这个方法,这大脑袋计算机就能算出一个词跟它前面的词搭配的可能性,帮我们更好地理解和用语言。
上下文学习
和以前不同的地方在于,他不仅仅是学习单纯的词和句子,还学会了词和词之间的关系。
你想啊,一个词在不同的句子里,意思可能完全不一样,就像“苹果”在“打开苹果电脑”和“我想吃苹果”里的意思就不一样。
这大模型得学会这些变化,才能真正明白咱们说的话。
之所以有今天,都是因为他们发现了一本秘籍。
前置:《【史上最本质】序列模型:RNN、双向 RNN、LSTM、GRU、Seq-to-Seq、束搜索、Transformer、Bert》
秘籍:《从【注意力机制】开始,到【Transformer】的零基础【大模型】系列》。
思维链 CoT
最初的语言模型都是基于经验的,只能根据词汇之间的相关性输出答案,根本没有思考能力……
但是从使用思维链后,大模型已经是有思考能力的。能进行一定的推理。
2021年,OpenAI在训练神经网络过程中有一个意外发现。
神经网络他可以很好地模仿现有的数据,很少犯错误。
可是如果你给他出个没练过的题目,他还是说不好。于是你就让他继续练。
继续训练好像没什么意义,因为现在只要是模仿他就都能说得很好,只要是真的即兴发挥他就不会。
但你不为所动,还是让他练。
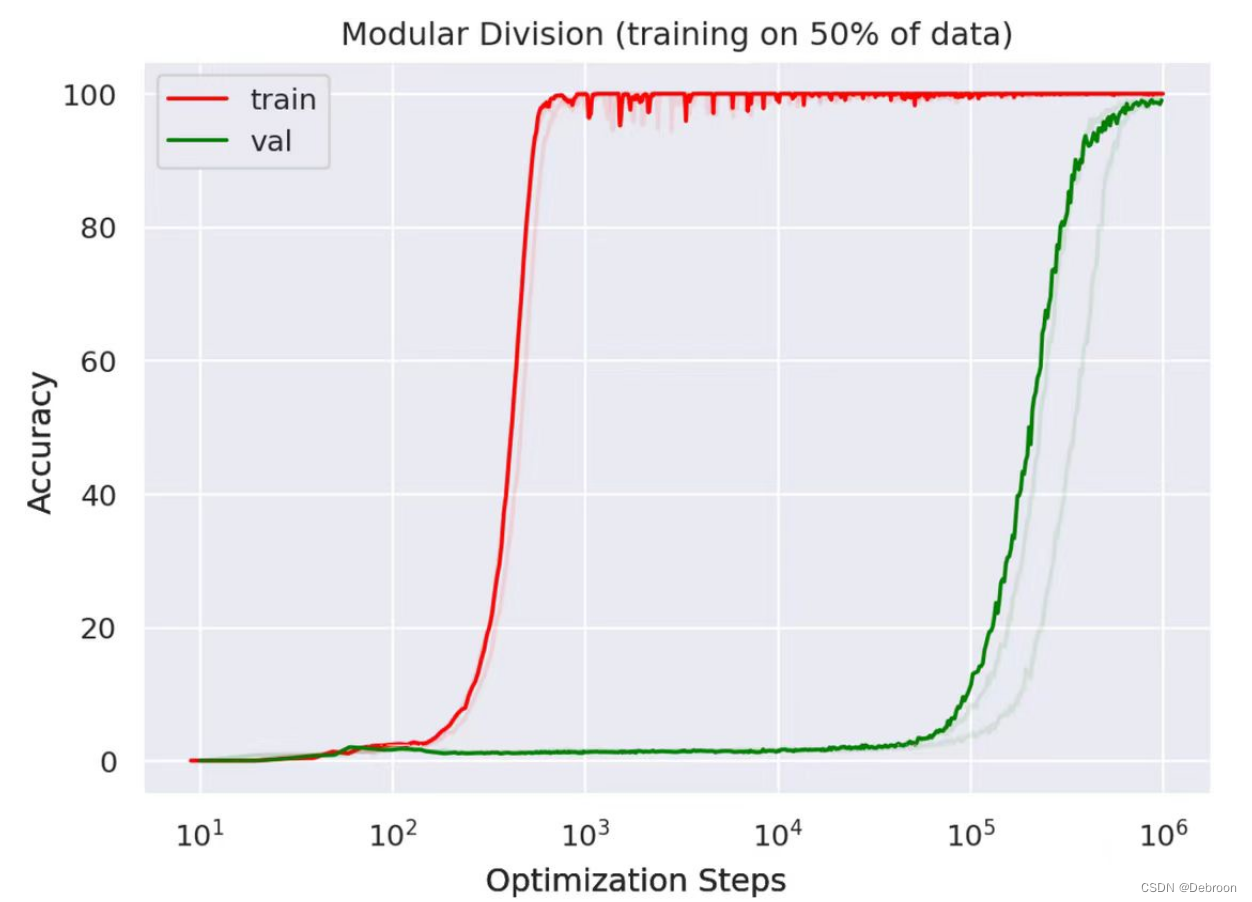
1 0 2 10^2 102 到 1 0 5 10^5 105 训练完全没有成果。
就这样练啊练,惊奇地发现,他会即兴演讲了!给他一个什么题目,他都能现编现讲,发挥得很好!
- 一千步乃至一万步,模型对训练题的表现已经非常好了,但是对生成性题目几乎没有能力
- 练到10万步,模型做训练题的成绩已经很完美,对生成性题也开始有表现了
- 练到100万步,模型对生成性题目居然达到了接近100%的精确度
这就是量变产生质变。研究者把这个现象称为「开悟(Grokking)」。
2022年8月,谷歌大脑研究者发布一篇论文,专门讲了大型语言模型的一些涌现能力,包括少样本学习、突然学会做加减法、突然之间能做大规模、多任务的语言理解、学会分类等等……
而这些能力只有当模型参数超过1000亿才会出现 —— 涌现新能力的关键机制,叫 思维链。
思维链就是当模型听到一个东西之后,它会嘟嘟囔囔自说自话地,把它知道的有关这个东西的各种事情一个个说出来。
思维链是如何让语言模型有了思考能力的呢?
比如你让模型描写一下“夏天”,它会说:“夏天是个阳光明媚的季节,人们可以去海滩游泳,可以在户外野餐……”等等。
只要思考过程可以用语言描写,语言模型就有这个思考能力。
怎么用思维链呢?
思维链的主要思想是通过向大语言模型展示一些少量的样例,在样例中解释推理过程。
那大语言模型在回答提示时也会显示推理过程,这种推理的解释往往会引导出更准确的结果。

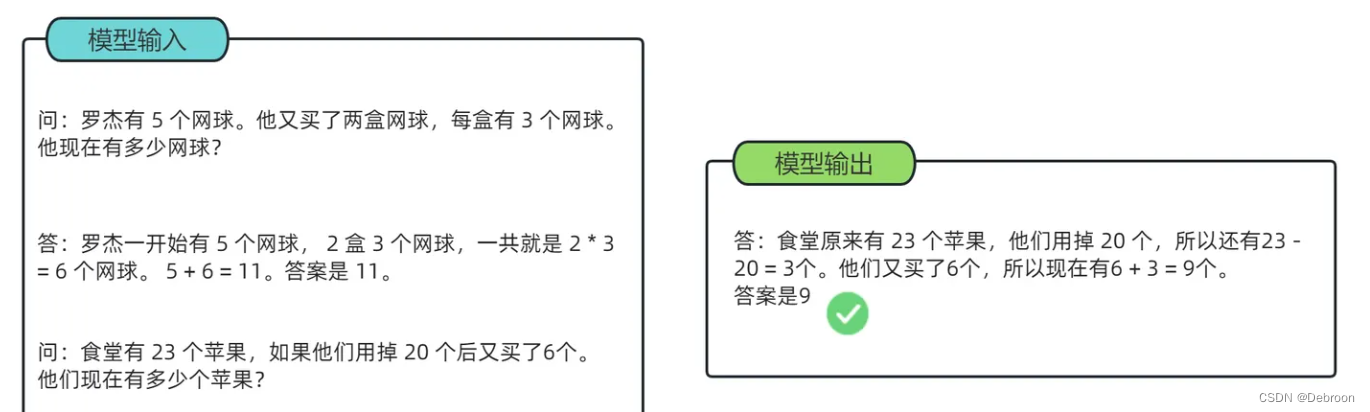
既然如此,只要我们设置好让模型每次都先思考一番再回答问题,ta就能自动使用思维链,ta就有了思考能力。
CoT(链式思考)已被证实能够改善大型AI模型在算术、常识和符号推理等任务上的表现。
用户发现,当他们在问题中添加“让我们一步步来思考”时,模型仿佛被施了魔法,之前答错的数学题突然能够正确解答,原本无理的论述变得有条有理。
不过,CoT对模型性能的提升与模型的大小成正比关系,模型参数至少达到100亿才有效果,达到1000亿效果才明显。
研究中指出,处理策略性问题通常需要大量的世界知识。
然而,小型模型由于其有限的参数,往往难以存储这些庞大的知识信息,这限制了它们在产生正确推理步骤方面的能力。
奖励建模
【挑战全网最易懂】深度强化学习 — 零基础指南
大模型 RLHF 实战!【OpenAI独家绝技RLHF!RLHF的替代算法DPO!Claude 暗黑科技 RAIHF!】
参数微调
大模型微调方法:冻结方法 Freeze、P-Tuning 系列、LoRA、QLoRA
并行训练
大模型并行训练、超大模型分布式训练
模型加速
【所有方法一览】大模型推理优化:在更小的设备运行、推理增速
永久记忆:大模型遗忘
大部分方法都是临时修补,帮助那些大型计算机(LLM)临时记住些东西。
但MemGPT,能让大模型能永远记住东西!
- https://github.com/cpacker/MemGPT#loading-local-files-into-archival-memory
他们搞了个叫虚拟上下文管理的玩意儿,灵感是从电脑操作系统里那一层层的记忆体系里来的。
就好像是给计算机装了个超级大的储物间,让它能记住更多的东西。
这个MemGPT就像是一个聪明的仓库管理员,懂得怎么在快速记忆(内存)和慢速记忆(硬盘)之间转移东西。
就好像有些东西经常用,就放在手边,不常用的就放远点。
这样,计算机就能在有限的记忆空间里,更聪明地处理大量的信息。
而且,它还会自己决定啥时候跟用户聊天,啥时候专心处理信息。
LangChain
【解决复杂链式任务,打造全能助手】LangChain 大模型 打造 钢铁侠的全能助理 Jarvis
知识图谱
统一大语言模型和知识图谱:如何解决医学大模型-问诊不充分、检查不准确、诊断不完整、治疗方案不全面?
多模态
ViT:视觉 Transformer
Swin Transformer:将卷积网络和 Transformer 结合
CLIP 对比预训练 + 文字图像相似度:离奇调查,如何训练视觉大模型?
大模型系统优化
【附带大模型训练数据】大模型系统优化:怎么计算模型所需的算力、内存带宽、内存容量和通信数据量?
AI 绘图
【史上最小白】变分自编码器 VAE:从降维本质,到自编码器,再到变分自编码器
Diffusion 扩散模型:论生成领先多样性,GAN太单一;论尊贵清晰度独占鳌头,VAE常失真
DALL-E 系列:AI绘画背后的惊人真相!!【1个离奇内幕、3个意想不到、5大秘密揭示】
幻觉问题
如何解决大模型的「幻觉」问题?
从 GPT1 - GPT4 拆解
从 GPT1 - GPT4 拆解
GPTs
对比主流大模型技术点
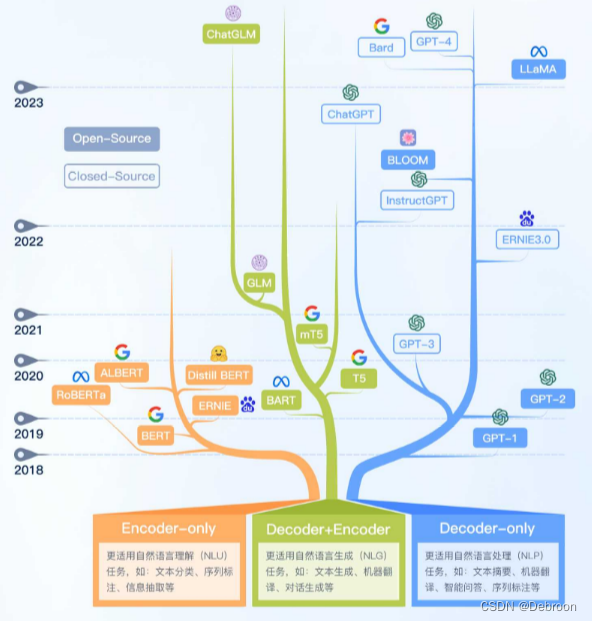
当前绝大多数大语言模型结构都采用了类似GPT架构,使用基于Transformer架构构造的仅由解码器组成的网络结构,采用自回归的方式构建语言模型。
但是在位置编码、层归一化位置以及激活函数等细节上各有不同。
旋转位置编码
层归一化
激活函数
注意力机制优化