目录
引言
AOF 策略
实例演示一
缓冲区
重写机制
手动触发
自动触发
AOF 重写流程
实例演示二
引言
Redis 实现持久化的两大策略
- RDB ——> Redis DataBase(定期备份)
- AOF ——> Append Only File(实时备份)
注意:
- Redis 服务器配置文件默认开启 RDB(定期备份)
- 即 AOF(实时备份) 默认为关闭状态
- 此处我们可以通过修改配置文件,来开启 AOF(实时备份)
可点击下方连接详细了解 RDB 策略
Redis 持久化 RDB 策略

AOF 策略
- 该策略类似于 mysql 的 binlog,会将用户的每个操作均记录到文件中
- 当 Redis 重新启动时,便会读取 aof 文件中的内容,将内存中的数据恢复回来
注意:
- 当开启 AOF 时,rdb 文件便不会生效了
- 即 Redis 启动时将不再读取 rdb 文件的内容用来恢复数据
- 因为 aof 文件中包含的数据比 rdb 文件更全!

实例演示一
- 根据实例演示,我们观察 aof 文件的生成,顺便观察 rdb 文件在 AOF 策略下的 Redis 是否生效
1、当我们将 Redis 配置文件中的 RDB(定期备份)修改为 AOF(实时备份)后
- 由上图可知,即便是没有 rdb 文件,Redis 服务器也可正常重启!
2、此时我们向 redis 中插入 2个键值对
3、查看 appendonly.aof 文件
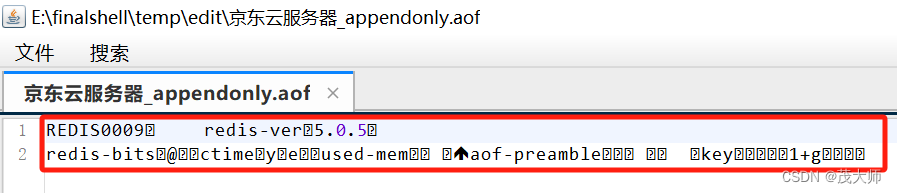
- 由上图可知,aof 文件为文本文件
- 我们在 Redis 中进行的操作,均会被记录到 aof 文件中
- 通过一些特殊符号作为分隔符,来对命令的细节做出区别
4、将现在正在运行的 Redis 服务器重启,看是否能恢复内存之前的状态




缓冲区
- Redis 虽然是一个单线程的服务器,但是速度很快
- 其中一个重要的原因为 Redis 仅操作内存
问题一:
- 引入 AOF(实时备份)后,既要写内存,又要写硬盘,还能和之前一样快吗?
回答:
- 没有什么影响,并不会影响到 Redis 处理请求的速度!
1、AOF 机制并非是直接让工作线程将数据写入硬盘,而是先写入内存中的缓冲区,积累一波后,再统一写入硬盘
- 该方式大大降低了,写硬盘的次数
- 写硬盘时,写入硬盘数据的多少,对于性能没有很大影响,但是写入硬盘的次数则影响很大了
2、AOF 机制每次将新操作写入到原有文件的末尾,属于 顺序写入
- 硬盘上读写数据,顺序读写的速度是比较快的(还是要比内存慢很多),而随机访问的速度则是比较慢的
问题二:
- 数据写入到缓冲区里,其本质还是在内存中呀
- 万一这时候,突然进程挂了 或 主机掉电了,是不是缓冲区中的数据就丢了呢?
回答:
- 是的,缓冲区没来得及写入硬盘的数据是会丢的!
- Redis 给出了一些选项,让程序员根据实际情况决定怎么取舍,即缓冲区的刷新策略
- 刷新频率越高,性能影响就越大,数据可靠性就越高
- 刷新频率越低,性能影响就越小,数据可靠性就越低
- fsync 是一个系统调用,用于强制将文件系统中对应文件的所有修改刷新到磁盘上
注意:
- 默认情况下为 everysec



重写机制
- aof 文件持续增长,其体积将越来越大,从而影响 Redis 下次启动的启动时间
- 因为 Reids 启动的时候要读取 aof 文件的内容
注意:
- aof 中的文件,有很多内容都是冗余的
- 虽然 aof 文件的内容记录了中间的操作过程
- 但实际 Redis 在重新启动时,仅关注最终的结果
- 因此 Redis 存在 重写机制,能够针对 aof 文件进行 整理 操作
- 所谓 整理 就是能够剔除其中的冗余操作,并且合并一些操作,以达到 aof 文件瘦身的效果
手动触发
- 调用 bgrewriteaof 命令即可
自动触发
- 根据配置项参数确定自动触发时机
- auto-aof-rewrite-min-size: 表示触发重写时 aof 文件的最小文件大小
- auto-aof-rewrite-percentage: 表示当前 aof 文件占用大小相比较上次重写时增加的比例


AOF 重写流程
2)4)
- 发生重写时,通过 fork 创建子进程
- 在创建子进程的一瞬间,子进程便继承了当前父进程的内存状态
- 子进程只需要将内存中当前的数据给获取出来,以 aof 的格式写入到一个新的 aof 文件中
- 与此同时 子进程负责针对 aof 文件进行重写
注意点一:
- 子进程里的内存数据是 父进程 fork 之前的状态
- 而 fork 之后,对内存造成修改的新请求,子进程无法知道的!
注意点二:
- 在此过程中并不关心 aof 文件中原来都有啥,仅关心内存中最终的数据状态
- 内存中的数据状态,就已经相当于是把 aof 文件结果整理后的模样了
注意点三:
- 此处 子进程 写数据的过程,非常类似于 RDB 生成一个镜像快照
- 只不过 RDB 这里是按照二进制的方式来生成的
- 而 AOF 重写,则是按照 AOF 这里要求的文本格式来生成的
- 二者 都是为了把当前内存中的所有数据状态记录到文件中
1)2)3.1)
- 在子进程写新 aof 文件的同时,父进程也仍然不停地接收客户端新请求
- 并将这些请求产生的 aof 数据先写入到缓冲区,再刷新到原有的 aof 文件中
2)3.2)
- 正因为子进程里的内存数据是 父进程 fork 之前的状态
- 而 fork 之后,对内存造成修改的新请求,子进程无法知道的!
- 此时父进程这里便准备了一个 aof_rewrite_buf 缓冲区
- 专门放 fork 之后收到的数据
5.1)5.2)
- 子进程将 aof 数据写完后,便会通过 信号 通知父进程
- 父进程再将 aof_rewrite_buf 缓冲区中的内容也写入到 新的 aof 文件中
注意:
- 信号可以认为是 linux 的神经系统
- 进程之间的相互作用(也可以视为是进程间通信的一种手段)
- 但 Java 生态中并不鼓励适用多进程模型编程(网络通信的场景除外)
- 信号能表达的信息有限,并非像 socket 这样的方式可以传输任意的数据
- 这种简单的信号传递,使用信号也是 ok 的
- 信号 接近于 JavaScript 里的 事件
5.3)
- 最后便可以使用新 aof 文件替换旧 aof 文件了
问题一:
- 如果在执行 bgrewriteaof 时,当前 Redis 正在进行 aof 重写,此时会怎样?
回答:
- 此时将不会再次执行 aof 重写,而是直接返回
问题二:
- 如果在执行 bgrewriteaof 时,发现当前 Redis 在生成 rdb 文件的快照,此时会怎样?
回答:
- 此时 aof 重写操作便会等待,等待 rdb 快照生成完毕之后,再执行 aof 重写
问题三:
- 在父进程 fork 完毕后,子进程开始重写新 aof 文件
- 并且随着时间的推移,子进程将会很快写完新 aof 文件
- 最后 新 aof 文件将代替旧 aof 文件
- 那么 父进程此时还在继续写这个即将消亡的旧 aof 文件是否还有意义?
回答:
- 考虑到极端情况
- 假设在重写过程中,重写了一半,服务器挂了,子进程内存的数据就会丢失,此时新 aof 文件内容还不完整
- 所以如果 父进程不坚持写旧 aof 文件,重启时便无法保证数据的完整性了
小总结:
- RDB 对 fork 之后的新数据,便置之不理了
- 而 AOF 则对 fork 之后的新数据,采取了 aof_rewrite_buf 缓冲区的方式来进行处理
- RDB 本身的设计理念,就是用来 定期备份的
- 只要是 定期备份,就难以和最新的数据保持一致
- AOF 的理念则是实时备份
- 当然 实时备份 并不一定就比 定期备份 更好,还是需要结合 实际场景 来看
- 现在的系统,其资源一般都是比较充裕的,即 对于 AOF 所造成的开销也不会有太大负担
- 所以 一般来说 AOF 的适用场景更多一些的!


实例演示二
- 通过该实例演示 观察重写之后的 aof 文件
1、向 Redis 中进行下图操作
2、打开并查看 appendonly.aof 文件
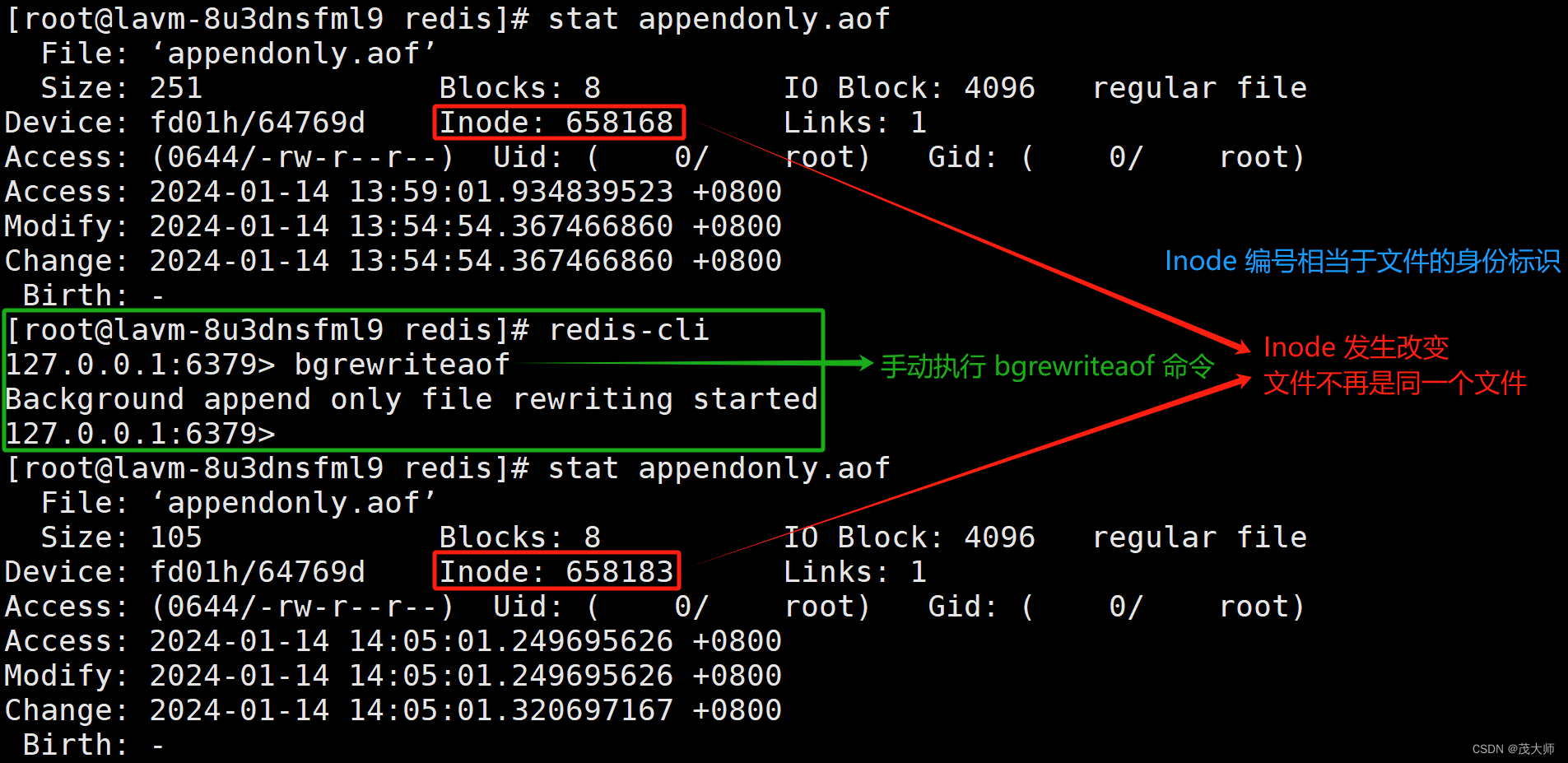
3、在 Redis 中手动执行 bgrewriteaof 命令,手动触发 AOF 重启
4、再次观察 appendonly.aof 文件
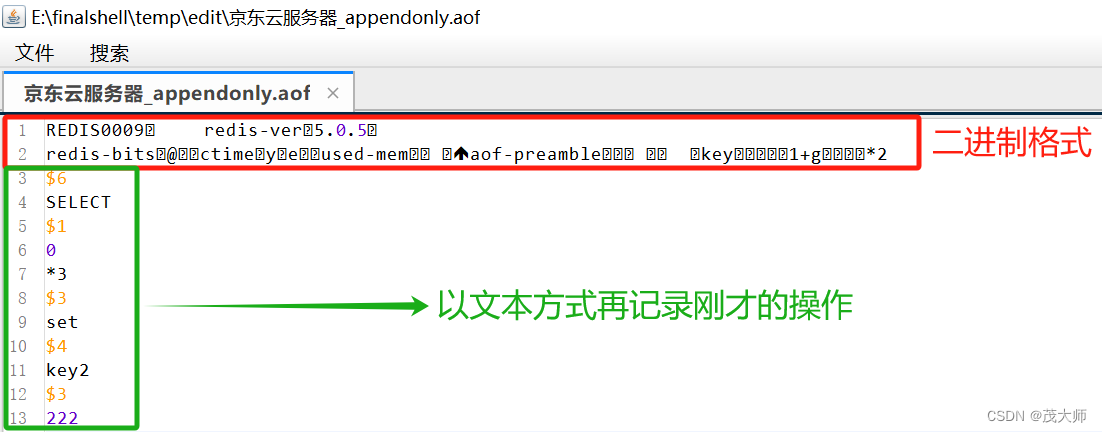
- 此时发现 数据居然以二进制的方式进行存储
注意:
- AOF 本来是按照文本格式来写入文件的
- 但是文本的方式写文件,后续加载的成本是比较高的
- 所以 Redis 便引入了 混合持久化 的方式,即结合了 rdb 和 aof 的特点
具体解释:
- 按照 AOF 的方式,将每个 请求 或 操作,均记录到文件中
- 在触发 AOF 重写后,便将当前内存的状态按照 rdb 的二进制格式写入到新 aof 文件中
- 后续再进行的操作,仍然按照 aof 文本的方式追加到文件后面
5、我们再往 Redis 中插入 1个键值对
6、再次打开并观察 appendonly.aof 文件