目录
Scrapy中下载中间件
概念
方法
process_request(self, request, spider)
参数:
process_response(self, request, response, spider)
参数
基本步骤
示例代码
注意
Scrapy 中 Downloader 设置UA
开发UserAgent下载中间件
代码
三方模块
配置模块到Setting文件
Scrapy 中 Downloader 设置代理
爬虫代理原理
代码
下载中间件-Scrapy与Selenium结合(示例)
Spider文件
middlewares文件
Scrapy中下载中间件
概念
下载中间件是Scrapy请求/响应处理的钩子框架。这是一个轻、低层次的应用。
通过可下载中间件,可以处理请求之前和请求之后的数据。
方法
每个中间件组件都是一个Python类,它定义了一个或多个以下方法,我们可能需要使用方法如下:
-
process_request()
-
process_response()
process_request(self, request, spider)
当每个request通过下载中间件时,该方法被调用
必须返回以下其中之一
-
返回 None
- Scrapy 将继续处理该 request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用,该 request 被执行(其 response 被下载)
-
返回一个 Response 对象
- Scrapy 将不会调用 任何 其他的 process_request()或 process_exception()方法,或相应地下载函数; 其将返回该 response。已安装的中间件的 process_response()方法则会在每个 response 返回时被调用
-
返回一个 Request 对象
- Scrapy 则停止调用 process_request 方法并重新调度返回的 request。当新返回的 request 被执行后, 相应地中间件链将会根据下载的 response 被调用
-
raise IgnoreRequest
- 如果抛出 一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则 request 的 errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)
参数:
- request (Request 对象) – 处理的request
- spider (Spider 对象) – 该request对应的spider
process_response(self, request, response, spider)
当下载器完成http请求,传递响应给引擎的时候调用
process_response()应该是:返回一个 Response对象,则返回一个 Request 对象或引发 IgnoreRequest例外情况。
-
如果它返回
Response(可能是相同的给定响应,也可能是全新的响应),该响应将继续使用process_response()链中的下一个中间件 -
如果它返回一个
Request对象时,中间件链将暂停,返回的请求将重新计划为将来下载。这与从返回请求的行为相同process_request() -
如果它引发了
IgnoreRequest异常,请求的errback函数 (Request.errback)。如果没有代码处理引发的异常,则忽略该异常,不记录该异常(与其他异常不同)。 -
参数
- request (is a
Requestobject) -- 发起响应的请求 - response (
Responseobject) -- 正在处理的响应 - spider (
Spiderobject) -- 此响应所针对的蜘蛛
- request (is a
基本步骤
-
创建一个自定义的下载中间件类,该类需要实现Scrapy提供的下载中间件接口。您可以根据自己的需求,选择性地实现接口中的方法。常用的方法包括
process_request、process_response和process_exception等。 -
在Scrapy的配置文件(一般是settings.py)中,找到
DOWNLOADER_MIDDLEWARES配置项。这是一个包含各个下载中间件的列表。您可以根据需要调整中间件的顺序,以及添加或移除中间件。 -
将您编写的自定义下载中间件类添加到
DOWNLOADER_MIDDLEWARES列表中,以使Scrapy能够使用它。您可以通过指定中间件的路径或导入路径的方式添加中间件。
示例代码
创建一个自定义的下载中间件类:
# myproject/middlewares.pyclass MyCustomDownloaderMiddleware(object):def process_request(self, request, spider):# 在发送请求之前对请求进行处理# 可以修改请求的URL、Headers、添加代理等return None # 继续处理请求def process_response(self, request, response, spider):# 在接收到响应后对响应进行处理# 可以处理响应的内容、状态码、Headers等return response # 继续处理响应def process_exception(self, request, exception, spider):# 处理请求过程中发生的异常# 可以根据异常类型进行相应处理pass
在settings.py文件中,将自定义的下载中间件添加到DOWNLOADER_MIDDLEWARES配置项中:
# settings.pyDOWNLOADER_MIDDLEWARES = {'myproject.middlewares.MyCustomDownloaderMiddleware': 543, # 自定义下载中间件# 其他下载中间件...
}
注意
543是一个中间件的优先级值,用于确定中间件的执行顺序。较小的值表示较高的优先级,中间件将按照优先级从高到低的顺序进行处理。Scrapy 中 Downloader 设置UA
Scrapy 中 Downloader 设置UA
如果使用下载中间件需要在Scrapy中的setting.py的配置DOWNLOADER_MIDDLEWARES才可以使用
DOWNLOADER_MIDDLEWARES = {'myproject.middlewares.CustomDownloaderMiddleware': 543,
}
开发UserAgent下载中间件
问题
每次创建项目后,需要自己复制UserAgent到settings,比较繁琐
解决方案
开发下载中间件,设置UserAgent
代码
from fake_useragent import UserAgentclass MyUserAgentMiddleware:def process_request(self, request, spider):request.headers.setdefault(b'User-Agent', UserAgent().chrome)
三方模块
pip install scrapy-fake-useragent==1.4.4
配置模块到Setting文件
DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,'scrapy.downloadermiddlewares.retry.RetryMiddleware': None,'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,'scrapy_fake_useragent.middleware.RetryUserAgentMiddleware': 401,
}
Scrapy 中 Downloader 设置代理
爬虫设置代理就是让别的服务器或电脑代替自己的服务器去获取数据
爬虫代理原理
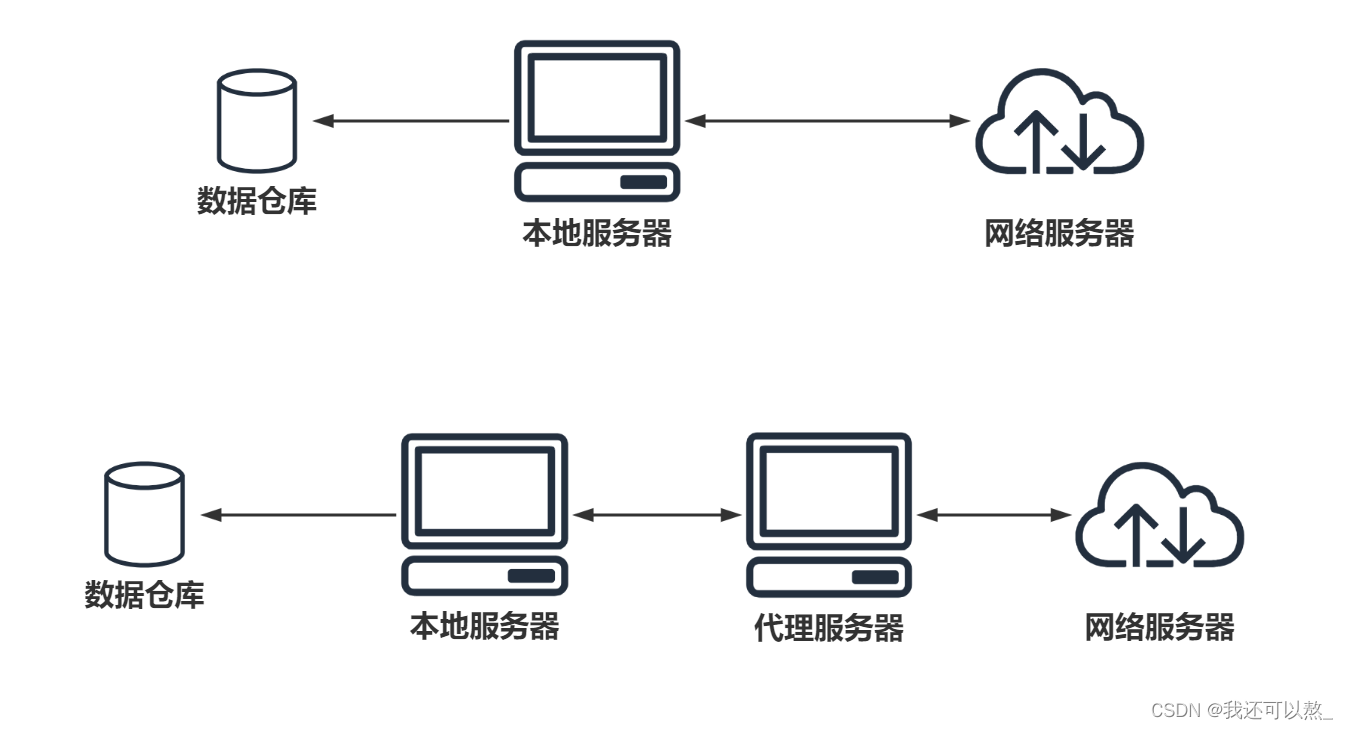
代码
通过request.meta['proxy']可以设置代理,如下:
class MyProxyDownloaderMiddleware:def process_request(self, request, spider):# request.meta['proxy'] ='http://ip:port'# request.meta['proxy'] ='http://name:pwd@ip:port'request.meta['proxy'] ='http://139.224.211.212:8080'下载中间件-Scrapy与Selenium结合(示例)
有的页面反爬技术比较高端,一时破解不了,这时我们就是可以考虑使用selenium来降低爬取的难度。
问题来了,如何将Scrapy与Selenium结合使用呢?
思考的思路: 只是用Selenium来帮助下载数据。因此可以考虑通过下载中间件来处理这块内容。
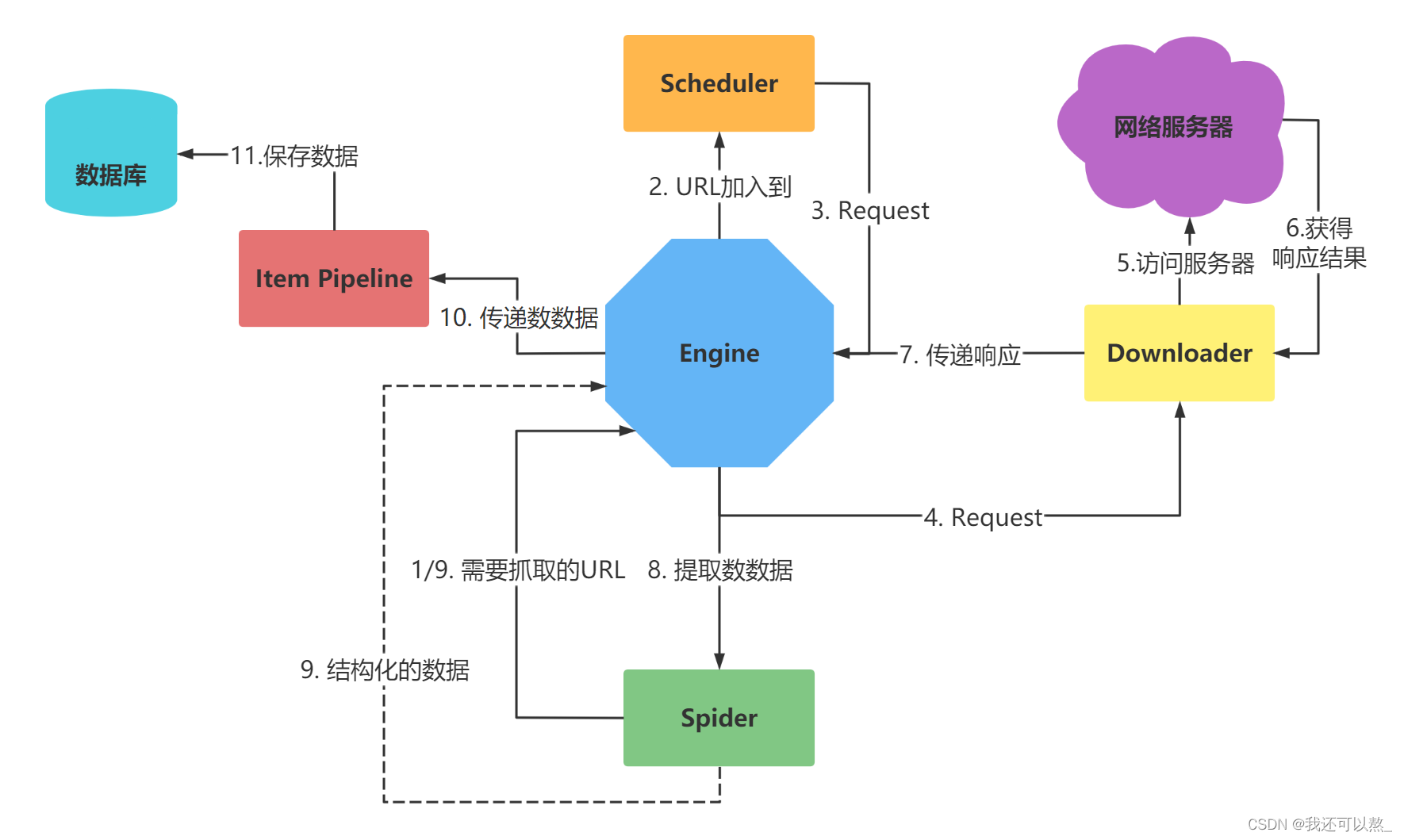
Spider文件
@classmethoddef from_crawler(cls, crawler, *args, **kwargs):spider = super(BaiduSpider, cls).from_crawler(crawler, *args, **kwargs)spider.chrome = webdriver.Chrome(executable_path='../tools/chromedriver.exe')crawler.signals.connect(spider.spider_closed, signal=signals.spider_closed) # connect里的参数 # 1. 处罚事件后用哪个函数处理# 2. 捕捉哪个事件return spiderdef spider_closed(self, spider):spider.chrome.close()
middlewares文件
def process_request(self, request, spider): spider.chrome.get(request.url)html = spider.chrome.page_sourcereturn HtmlResponse(url = request.url,body = html,request = request,encoding='utf-8')