目录
详解pytorch中各种Loss functions
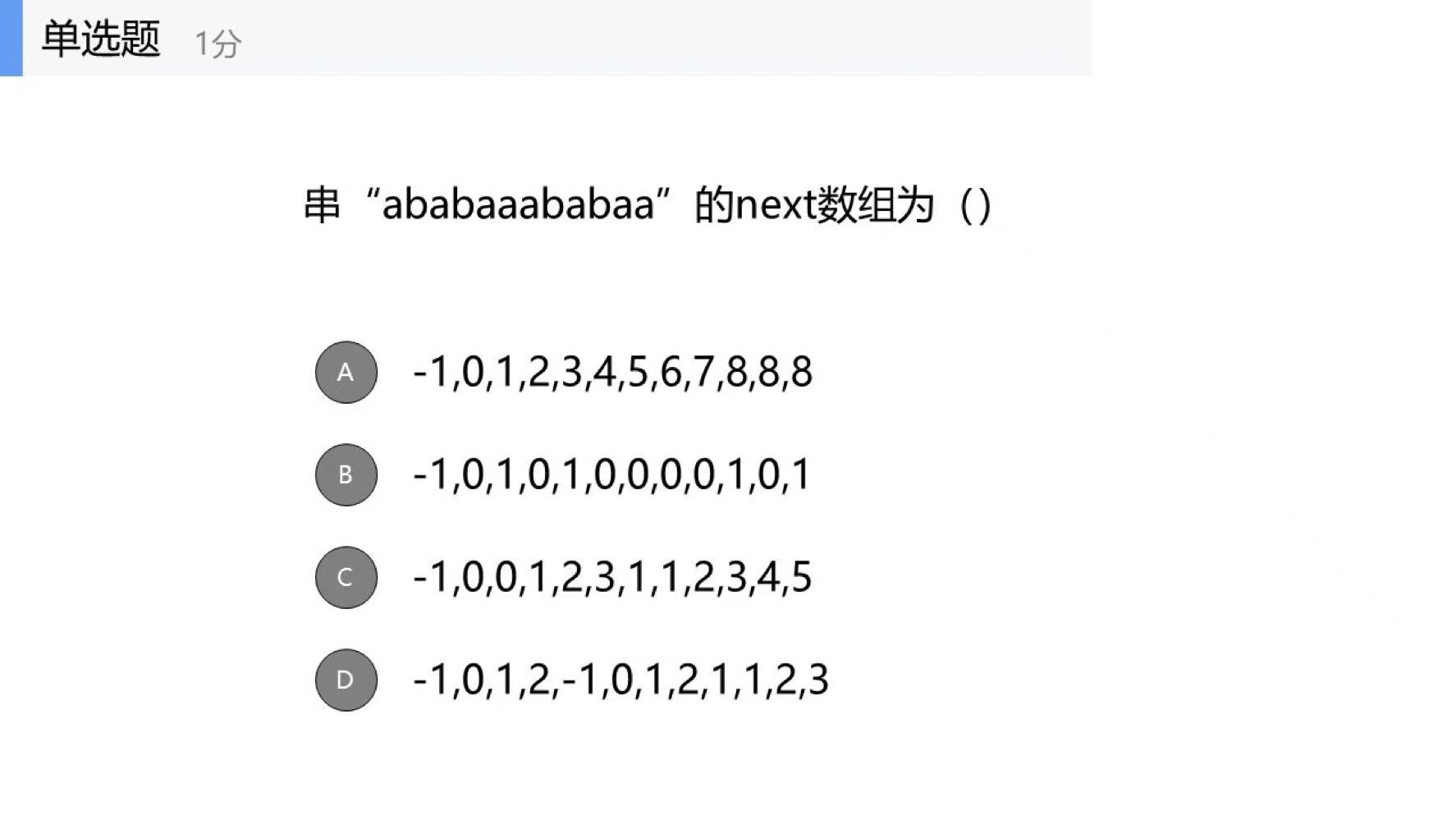
binary_cross_entropy
用途
用法
参数
数学理论
示例代码
binary_cross_entropy_with_logits
用途
用法
参数
数学理论
示例代码
poisson_nll_loss
用途
用法
参数
数学理论
示例代码
cosine_embedding_loss
用途
用法
参数
数学理论
示例代码
cross_entropy
用途
用法
参数
数学理论
示例代码
ctc_loss
用途
用法
参数
数学理论
示例代码
gaussian_nll_loss
用途
用法
参数
数学理论
示例代码
hinge_embedding_loss
用途
用法
参数
数学理论
示例代码
kl_div
用途
用法
参数
数学理论
示例代码
注意
l1_loss
用途
用法
参数
数学理论
示例代码
总结
详解pytorch中各种Loss functions
binary_cross_entropy
torch.nn.functional.binary_cross_entropy 是 PyTorch 中用于测量目标和输入概率之间的二元交叉熵(Binary Cross Entropy, BCE)的函数。这个函数在二分类问题中非常重要,特别是在处理神经网络的输出层时,它用于评估模型的预测准确度。
用途
- 用于二分类问题中,评估模型对正类和负类的预测准确性。
- 常用于神经网络的输出层,特别是在处理概率输出时。
用法
torch.nn.functional.binary_cross_entropy(input, target, weight=None, size_average=None, reduce=None, reduction='mean')
input: 输入张量,表示预测的概率。target: 目标张量,具有与输入相同的形状,值在0和1之间。weight: 可选,手动重新缩放权重张量。reduction: 指定输出的降维方式,可以是 'none'、'mean' 或 'sum'。
参数
input(Tensor): 预测概率的张量。target(Tensor): 目标张量,与输入形状相同,值在0到1之间。weight(Tensor, 可选): 手动重新缩放权重,匹配输入张量的形状。reduction(str, 可选): 输出的降维方式,'none'、'mean' 或 'sum'。
数学理论
二元交叉熵的计算公式为:
其中:
- N 是样本数量。
- yi 是目标值,即
target中的元素。 - pi 是预测概率,即
input中的元素。
示例代码
import torch
import torch.nn.functional as F# 定义输入和目标张量
input = torch.randn(3, 2, requires_grad=True)
target = torch.rand(3, 2)# 计算二元交叉熵损失
loss = F.binary_cross_entropy(torch.sigmoid(input), target)# 反向传播
loss.backward()# 打印损失值
print(loss)
这段代码将输出一个标量值,代表整个批次的平均二元交叉熵损失。由于输入是随机生成的,输出的损失值也会随机变化。
binary_cross_entropy_with_logits
torch.nn.functional.binary_cross_entropy_with_logits 是 PyTorch 中的一个函数,用于测量目标(target)和输入对数几率(logits)之间的二元交叉熵(Binary Cross Entropy)。这个函数对于包含未归一化分数(logits)的二分类问题非常有用,特别是在处理神经网络的输出层时。
用途
- 主要用于二分类问题,尤其当模型的输出是未归一化的分数(即 logits)时。
- 通常用于神经网络的输出层,以计算模型预测的准确性。
用法
torch.nn.functional.binary_cross_entropy_with_logits(input, target, weight=None, size_average=None, reduce=None, reduction='mean', pos_weight=None)
input: 输入张量,表示未归一化的分数(logits)。target: 目标张量,与输入形状相同,值在0和1之间。weight: 可选,手动重新缩放权重张量。reduction: 指定输出的降维方式,可以是 'none'、'mean' 或 'sum'。pos_weight: 正例的权重张量,用于调整正例的重要性。
参数
input(Tensor): 未归一化分数(logits)的张量。target(Tensor): 目标张量,与输入形状相同,值在0到1之间。weight(Tensor, 可选): 手动重新缩放权重,匹配输入张量的形状。reduction(str, 可选): 输出的降维方式,'none'、'mean' 或 'sum'。pos_weight(Tensor, 可选): 正例的权重张量,用于调整正例在损失计算中的重要性。
数学理论
二元交叉熵的计算公式为:
loss = -(pos_weight * target * log(sigmoid(input)) + (1 - target) * log(1 - sigmoid(input)))
如果 reduction='mean',则对所有元素的损失取平均值。如果 reduction='sum',则对损失求和。
示例代码
import torch
import torch.nn.functional as F# 定义输入和目标张量
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)# 计算二元交叉熵损失(带对数几率)
loss = F.binary_cross_entropy_with_logits(input, target)# 反向传播
loss.backward()# 打印损失值
print(loss)
这段代码将输出一个标量值,代表整个批次的平均二元交叉熵损失(带对数几率)。由于输入是随机生成的,输出的损失值也会随机变化。
poisson_nll_loss
torch.nn.functional.poisson_nll_loss 是 PyTorch 中的一个函数,用于计算泊松负对数似然损失(Poisson Negative Log Likelihood Loss)。这个函数主要用于模型输出是泊松分布参数的情况,例如在某些类型的计数数据或事件率建模中。
用途
- 用于处理模型输出为泊松分布期望值的场景,如事件计数或率的预测。
- 在处理计数数据或任何泊松分布数据时,评估模型的预测准确性。
用法
torch.nn.functional.poisson_nll_loss(input, target, log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction='mean')
input: 输入张量,表示泊松分布的期望。target: 目标张量,是泊松分布的随机样本。log_input: 如果为True,则按exp(input) - target * input计算损失;如果为False,则按input - target * log(input + eps)计算。full: 是否计算完整的损失,包括斯特林近似项。eps: 避免当log_input=False时对数为零的小值。reduction: 指定输出的降维方式,可以是 'none'、'mean' 或 'sum'。
参数
input(Tensor): 泊松分布的期望张量。target(Tensor): 与输入形状相同的目标张量,表示泊松分布的样本。log_input(bool): 计算损失的方式,默认为True。full(bool): 是否计算完整的损失,包括斯特林近似项,默认为False。eps(float, 可选): 避免对数为零的小值,默认为1e-8。reduction(str, 可选): 输出的降维方式,'none'、'mean' 或 'sum'。
数学理论
当 log_input=True 时,损失计算为:
loss = exp(input) - target * input
当 log_input=False 时,损失计算为:
loss = input - target * log(input + eps)
如果 full=True,则在损失中加入斯特林近似项:
stirling = target * log(target) - target + 0.5 * log(2 * pi * target)
损失最后根据 reduction 参数进行降维。
示例代码
import torch
import torch.nn.functional as F# 定义输入和目标张量
input = torch.randn(3, requires_grad=True)
target = torch.empty(3).random_(2)# 计算泊松负对数似然损失
loss = F.poisson_nll_loss(input, target)# 反向传播
loss.backward()# 打印损失值
print(loss)
这段代码将输出一个标量值,代表整个批次的平均泊松负对数似然损失。由于输入是随机生成的,输出的损失值也会随机变化。
cosine_embedding_loss
torch.nn.functional.cosine_embedding_loss 是 PyTorch 中的一个函数,用于计算两个输入张量之间的余弦嵌入损失。这个函数主要用于学习两个输入之间的相似度或不相似度,尤其适用于那些需要通过余弦相似度来度量的任务,例如在某些类型的比较或匹配任务中。
用途
- 用于测量两个输入的相似性或不相似性,基于它们的余弦相似度。
- 常用于训练过程中,以确保相似的样本更接近,而不相似的样本更远离。
用法
torch.nn.functional.cosine_embedding_loss(input1, input2, target, margin=0, size_average=None, reduce=None, reduction='mean')
input1: 第一个输入张量。input2: 第二个输入张量。target: 包含1或-1的张量,1表示两个输入是相似的,-1表示不相似。margin: 用于不相似样本的边界值。reduction: 指定输出的降维方式,可以是 'none'、'mean' 或 'sum'。
参数
input1(Tensor): 第一个输入张量。input2(Tensor): 第二个输入张量。target(Tensor): 目标张量,其中1表示两个输入是相似的,-1表示不相似。margin(float): 不相似样本的边界值。reduction(str, 可选): 输出的降维方式,'none'、'mean' 或 'sum'。
数学理论
余弦嵌入损失的计算方式取决于目标标签:
- 当
target == 1,表示两个输入是相似的,损失计算为1 - cos_similarity(input1, input2)。 - 当
target == -1,表示两个输入是不相似的,损失计算为max(0, cos_similarity(input1, input2) - margin)。
示例代码
import torch
import torch.nn.functional as F# 定义输入张量
input1 = torch.randn(3, 128, requires_grad=True)
input2 = torch.randn(3, 128, requires_grad=True)
target = torch.tensor([1, -1, 1])# 计算余弦嵌入损失
loss = F.cosine_embedding_loss(input1, input2, target)# 反向传播
loss.backward()# 打印损失值
print(loss)
这段代码将输出一个标量值,代表整个批次的平均余弦嵌入损失。由于输入是随机生成的,输出的损失值也会随机变化。
cross_entropy
torch.nn.functional.cross_entropy 是 PyTorch 中的一个函数,用于计算输入对数几率(logits)和目标之间的交叉熵损失。这个函数在多分类问题中非常重要,特别是在处理神经网络的输出层时,它用于评估模型的预测准确度。
用途
- 用于多分类问题中,评估模型对各个类别的预测准确性。
- 常用于神经网络的输出层,特别是在处理未归一化的分数(logits)时。
用法
torch.nn.functional.cross_entropy(input, target, weight=None, ignore_index=-100, reduction='mean', label_smoothing=0.0)
input: 预测的未归一化对数概率,即 logits。target: 目标类别索引或类别概率。weight: 可选,给每个类别分配的手动重新缩放权重。ignore_index: 忽略的目标值,不会对输入梯度产生影响。reduction: 指定输出的降维方式,可以是 'none'、'mean' 或 'sum'。label_smoothing: 标签平滑的程度,范围在 0.0 到 1.0 之间。
参数
input(Tensor): 预测的未归一化对数概率(logits)。target(Tensor): 目标类别索引或类别概率。weight(Tensor, 可选): 类别的权重。ignore_index(int, 可选): 要忽略的目标值。reduction(str, 可选): 输出的降维方式,'none'、'mean' 或 'sum'。label_smoothing(float, 可选): 标签平滑的程度。
数学理论
交叉熵损失的计算公式为:
loss = -sum(target * log(softmax(input))) / N
target: 目标类别标签。input: 预测的对数概率(logits)。N: 样本数量。
示例代码
import torch
import torch.nn.functional as F# 示例:目标为类别索引
input = torch.randn(3, 5, requires_grad=True)
target = torch.randint(5, (3,), dtype=torch.int64)
loss = F.cross_entropy(input, target)
loss.backward()# 示例:目标为类别概率
input = torch.randn(3, 5, requires_grad=True)
target = torch.randn(3, 5).softmax(dim=1)
loss = F.cross_entropy(input, target)
loss.backward()
这两段代码分别计算了类别索引和类别概率作为目标时的交叉熵损失,并执行了反向传播。由于输入是随机生成的,输出的损失值也会随机变化。
ctc_loss
torch.nn.functional.ctc_loss 是 PyTorch 中用于计算连接主义时序分类(Connectionist Temporal Classification, CTC)损失的函数。CTC损失在处理序列数据,特别是在语音识别或任何需要对输入序列到目标序列的对齐的任务中非常有用。
用途
- 用于序列对齐问题,特别是在语音识别、手写识别等领域。
- 适用于处理长度不同的输入和目标序列。
用法
torch.nn.functional.ctc_loss(log_probs, targets, input_lengths, target_lengths, blank=0, reduction='mean', zero_infinity=False)
log_probs: 输入的对数概率,通常用torch.nn.functional.log_softmax()获得。targets: 目标序列。input_lengths: 输入序列的长度。target_lengths: 目标序列的长度。blank: 空白标签的索引,默认为0。reduction: 指定损失输出的降维方式,可以是 'none'、'mean' 或 'sum'。zero_infinity: 是否将无限损失及其梯度归零。
参数
log_probs(Tensor): 形状为(T, N, C)的张量,其中C是字符集大小(包括空白),T是输入长度,N是批次大小。targets(Tensor): 形状为(N, S)或总长度为sum(target_lengths)的张量,表示目标序列。input_lengths(Tensor): 长度为N的张量,表示每个输入的长度。target_lengths(Tensor): 长度为N的张量,表示每个目标序列的长度。blank(int, 可选): 空白标签的索引。reduction(str, 可选): 输出的降维方式。zero_infinity(bool, 可选): 是否将无限损失及其梯度归零。
数学理论
CTC损失在给定输入序列和目标序列时,计算所有可能的对齐方式的概率,并将这些概率的负对数求和。
示例代码
import torch
import torch.nn.functional as F# 定义输入对数概率、目标序列、输入和目标序列的长度
log_probs = torch.randn(50, 16, 20).log_softmax(2).detach().requires_grad_()
targets = torch.randint(1, 20, (16, 30), dtype=torch.long)
input_lengths = torch.full((16,), 50, dtype=torch.long)
target_lengths = torch.randint(10, 30, (16,), dtype=torch.long)# 计算CTC损失
loss = F.ctc_loss(log_probs, targets, input_lengths, target_lengths)# 反向传播
loss.backward()
这段代码将计算CTC损失,并执行反向传播。输出是一个标量值,代表根据 reduction 参数计算得到的损失。由于输入是随机生成的,输出的损失值也会随机变化。
gaussian_nll_loss
torch.nn.functional.gaussian_nll_loss 是 PyTorch 中用于计算高斯负对数似然损失(Gaussian Negative Log Likelihood Loss)的函数。这个函数主要用于处理具有高斯分布特性的数据,例如在某些回归问题中,当你希望模型预测值的分布不仅包含均值(mean)而且包含方差(variance)时。
用途
- 用于回归问题,特别是当预测的不确定性很重要时。
- 适用于建模具有高斯(正态)分布噪声的数据。
用法
torch.nn.functional.gaussian_nll_loss(input, target, var, full=False, eps=1e-06, reduction='mean')
input: 高斯分布的期望(均值)。target: 高斯分布的样本。var: 高斯分布的方差,可以是每个输入期望的方差(异方差),或一个单一的方差(同方差)。full: 是否包含常数项在损失计算中。eps: 加到方差上的小值,用于稳定性。reduction: 指定输出的降维方式,可以是 'none'、'mean' 或 'sum'。
参数
input(Tensor): 高斯分布的期望张量。target(Tensor): 高斯分布的样本张量。var(Tensor): 高斯分布的方差张量。full(bool, 可选): 是否包含常数项在损失计算中。eps(float, 可选): 加到方差上的小值,用于稳定性。reduction(str, 可选): 输出的降维方式。
数学理论
高斯负对数似然损失的计算公式为:
loss = 0.5 * (log(var) + (target - input)^2 / (var + eps))
如果 full=True,则在损失中加入常数项。
示例代码
import torch
import torch.nn.functional as F# 定义输入(期望)、目标和方差张量
input = torch.randn(3, requires_grad=True)
target = torch.randn(3)
var = torch.ones(3) * 0.5# 计算高斯负对数似然损失
loss = F.gaussian_nll_loss(input, target, var)# 反向传播
loss.backward()# 打印损失值
print(loss)
这段代码将计算高斯负对数似然损失,并执行反向传播。输出是一个标量值,代表根据 reduction 参数计算得到的损失。由于输入是随机生成的,输出的损失值也会随机变化。
hinge_embedding_loss
torch.nn.functional.hinge_embedding_loss 是 PyTorch 中用于计算铰链嵌入损失(Hinge Embedding Loss)的函数。这种损失函数通常用于学习距离度量,尤其在处理一些涉及相似性和不相似性学习的任务中,如孪生网络或对比学习。
用途
- 用于训练过程中,以确保相似的样本更接近,而不相似的样本更远离。
- 适用于一些需要区分相似与不相似样本的任务,例如人脸识别、签名验证等。
用法
torch.nn.functional.hinge_embedding_loss(input, target, margin=1.0, size_average=None, reduce=None, reduction='mean')
input: 输入张量,通常是两个样本之间的距离。target: 目标张量,其中1表示正样本对(相似),-1表示负样本对(不相似)。margin: 用于不相似样本对的边界值。reduction: 指定输出的降维方式,可以是 'none'、'mean' 或 'sum'。
参数
input(Tensor): 输入张量,通常是样本对之间的距离。target(Tensor): 目标张量,包含1(相似)和-1(不相似)。margin(float): 不相似样本对的边界值。reduction(str, 可选): 输出的降维方式,'none'、'mean' 或 'sum'。
数学理论
铰链嵌入损失的计算方式取决于目标标签:
- 当
target == 1(相似),损失计算为max(0, input)。 - 当
target == -1(不相似),损失计算为max(0, margin - input)。
示例代码
import torch
import torch.nn.functional as F# 定义输入张量和目标张量
input = torch.randn(10, requires_grad=True)
target = torch.tensor([1, -1, 1, 1, -1, -1, 1, 1, -1, -1], dtype=torch.float)# 计算铰链嵌入损失
loss = F.hinge_embedding_loss(input, target)# 反向传播
loss.backward()# 打印损失值
print(loss)
这段代码将计算铰链嵌入损失,并执行反向传播。输出是一个标量值,代表整个批次的平均损失。由于输入是随机生成的,输出的损失值也会随机变化。
kl_div
torch.nn.functional.kl_div 是 PyTorch 中用于计算两个概率分布之间的Kullback-Leibler(KL)散度的函数。KL散度是衡量两个概率分布相似性的常用方法,在机器学习和统计建模中广泛应用,特别是在评估模型预测概率分布与实际概率分布之间的差异时。
用途
- 用于衡量两个概率分布之间的差异或不相似性。
- 常用于生成模型,如变分自编码器(VAE)或在模型校准中评估预测概率分布。
用法
torch.nn.functional.kl_div(input, target, size_average=None, reduce=None, reduction='mean', log_target=False)
input: 输入张量,代表对数概率分布。target: 目标张量,与输入形状相同。log_target: 标志,指示目标是否在对数空间中传递。reduction: 指定输出的降维方式,可以是 'none'、'batchmean'、'sum' 或 'mean'。
参数
input(Tensor): 输入张量,代表对数概率分布。target(Tensor): 目标张量,与输入形状相同。log_target(bool, 可选): 目标是否在对数空间中。reduction(str, 可选): 输出的降维方式,'none'、'batchmean'、'sum' 或 'mean'。
数学理论
KL散度的计算公式为:
KL(P || Q) = sum(P(x) * (log(P(x)) - log(Q(x))))
其中 P 是目标分布,Q 是输入分布。
示例代码
import torch
import torch.nn.functional as F# 定义输入对数概率和目标概率
input = torch.log_softmax(torch.randn(3, 5), dim=1)
target = torch.softmax(torch.randn(3, 5), dim=1)# 计算KL散度
loss = F.kl_div(input, target, reduction='batchmean')# 打印损失值
print(loss)
这段代码将计算KL散度,并输出一个标量值,代表根据 reduction 参数计算得到的损失。由于输入是随机生成的,输出的损失值也会随机变化。
注意
size_average和reduce已被弃用,应使用reduction参数。- 当
reduction='mean'时,不会返回真正的KL散度值。建议使用reduction='batchmean',这与KL散度的数学定义相符。
l1_loss
torch.nn.functional.l1_loss 是 PyTorch 中用于计算L1损失(也称为平均绝对误差(MAE)损失)的函数。L1损失是一种常用的损失函数,用于衡量预测值和实际值之间的差异,特别是在回归问题中。
用途
- 用于回归问题中,计算预测值与实际值之间的差异。
- 在处理异常值时比平方误差(L2损失)更稳健。
用法
torch.nn.functional.l1_loss(input, target, size_average=None, reduce=None, reduction='mean')
input: 输入张量,通常是模型的预测值。target: 目标张量,即实际值。reduction: 指定输出的降维方式,可以是 'none'、'mean' 或 'sum'。
参数
input(Tensor): 输入张量,代表预测值。target(Tensor): 目标张量,代表实际值。reduction(str, 可选): 输出的降维方式,'none'、'mean' 或 'sum'。
数学理论
L1损失的计算公式为:
L1_loss = mean(abs(input - target))
abs(...)表示绝对值。mean(...)表示求平均值。
示例代码
import torch
import torch.nn.functional as F# 定义输入(预测值)和目标(实际值)张量
input = torch.randn(3, 2, requires_grad=True)
target = torch.randn(3, 2)# 计算L1损失
loss = F.l1_loss(input, target)# 反向传播
loss.backward()# 打印损失值
print(loss)
这段代码将计算L1损失,并执行反向传播。输出是一个标量值,代表整个批次的平均L1损失。由于输入是随机生成的,输出的损失值也会随机变化。
总结
本博客介绍了PyTorch中多种损失函数的应用和原理,包括二元交叉熵损失(BCE和BCE with logits)、泊松负对数似然损失、余弦嵌入损失、交叉熵损失、连接主义时序分类(CTC)损失、高斯负对数似然损失、铰链嵌入损失、Kullback-Leibler(KL)散度损失和L1损失。每种损失函数都有其特定的应用场景,从简单的二分类问题到复杂的序列对齐和概率分布比较,这些损失函数在深度学习模型的训练过程中发挥着关键作用。通过对这些损失函数的理解和应用,可以更好地设计和优化神经网络模型,以解决各种不同的机器学习问题。