场景描述
在做数据汇总计算和统计分析时,最头疼的就是去重类指标计算(比如用户数、商家数等),尤其还要带多种维度的下钻分析,由于其不可累加的特性,几乎每换一种统计维度组合,都得重新计算。数据量小时可以暴力的用明细数据直接即时统计,但当数据量大时就不得不考虑提前进行计算了。
典型场景,省、市、区等维度下的支付宝日支付用户数(其中省、市、区为用户下单时所在的地点)。
存在一个情况,某用户早上在杭州市使用支付宝支付了一次,下午跑到绍兴市时又使用支付宝线下支付了一次。那么在统计省+市维度的日支付用户数,需要为杭州市、绍兴市各计1;但在省维度下,需要按用户去重,只能为浙江省计1。针对这种情况,通常就需要以Cube的方式完成数据预计算,同时每个维度组合都需要进行去重操作,因为不可累加。本文将此种场景简称为去重Cube。

这三种写法其实都类似,重点都在于对数据进行膨胀,再进行去重统计。其执行流程如下图所示,核心思路都是先把数据"膨胀"拆为多行,再按照“普通”的Distinct去重统计,因此性能上本身无太大差异,主要在于代码可维护性上。
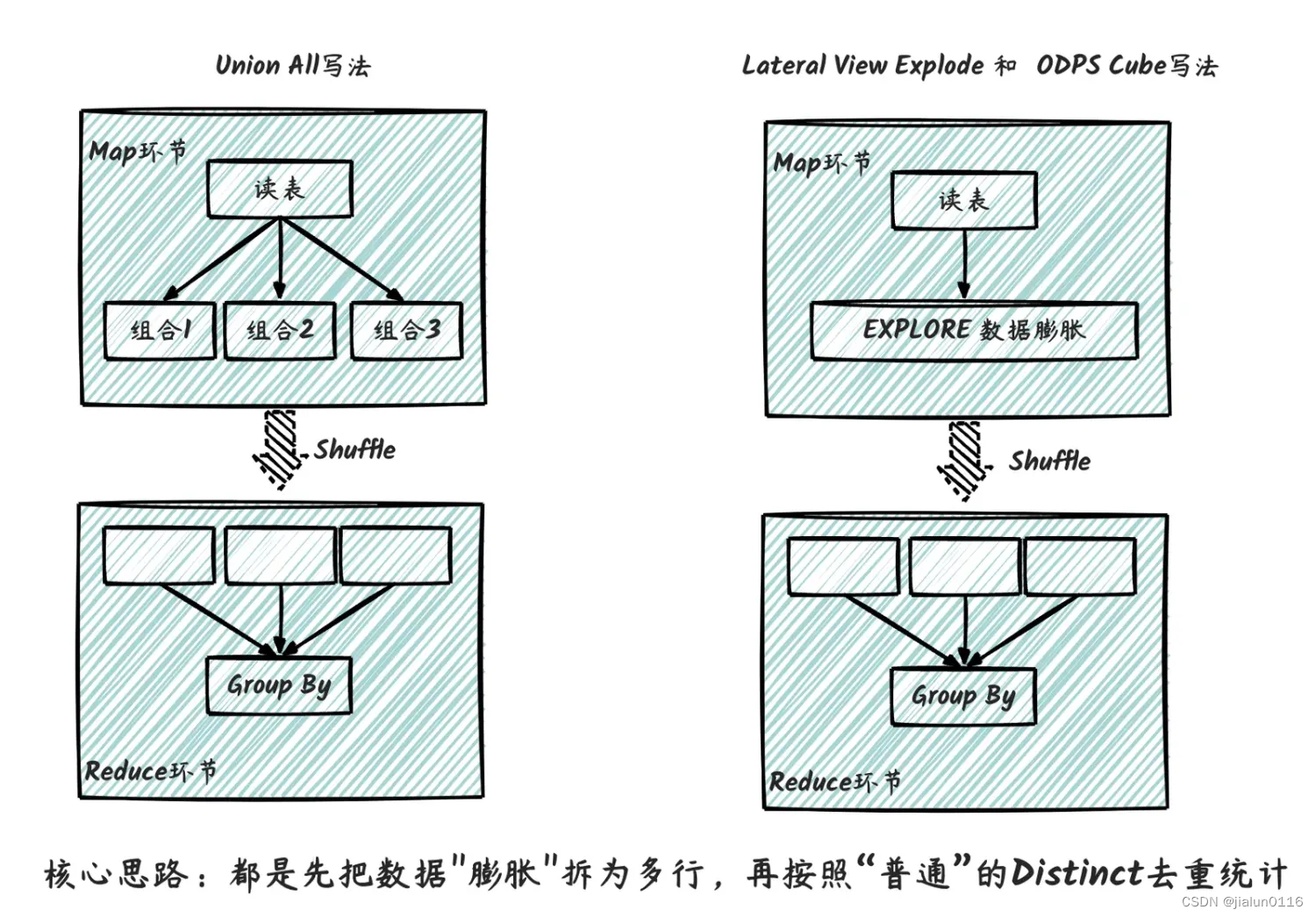
在实际案例中,我们发现,去重Cube的计算过程中,80%+的计算成本消耗在数据膨胀和数据传输上。比如支付宝高管核心指标场景,需要计算各种组合维度下的支付用户数以支持决策分析。实际组合维度达20+,实际执行任务如下图所示,其中R3_2为核心的数据膨胀过程,数据膨胀近10倍,中间结果数据大小由100GB膨胀至1TB、数据量由120亿膨胀至近1300亿,大部分计算资源和计算耗时都花在数据膨胀和传输上了。若实际的组合维度进一步增加的话,数据膨胀大小也将进一步增加。
一种新的思路
首先对问题进行拆解下,去重Cube的计算过程核心分为两个部分,数据膨胀+数据去重。数据膨胀解决的是一行数据同时满足多种维度组合的计算,数据去重则是完成最终的去重统计,核心思路还是在于原始数据去匹配结果数据的需要。其中数据去重本身的计算量就较大,而数据膨胀会导致这一情况加剧,因为计算过程中需要拆解和在shuffle过程中传输大量的数据。数据计算过程中是先膨胀再聚合,加上本身数据内容的中英文字符串内容较大,所以才导致了大量的数据计算和传输成本。
而我们的核心想法是能否避免数据膨胀,同时进一步减少数据传输大小。因此我们联想到,是否可以采用类似于用户打标签的数据打标方案,先进行数据去重生成UID粒度的中间数据,同时让需要的结果维度组合反向附加到UID粒度的数据上,在此过程中并对结果维度进行编号,用更小的数据结构去存储,避免数据计算过程中的大量数据传输。整个数据计算过程中,数据量理论上是逐渐收敛的,不会因为统计维度组合的增加而增加。
核心思路
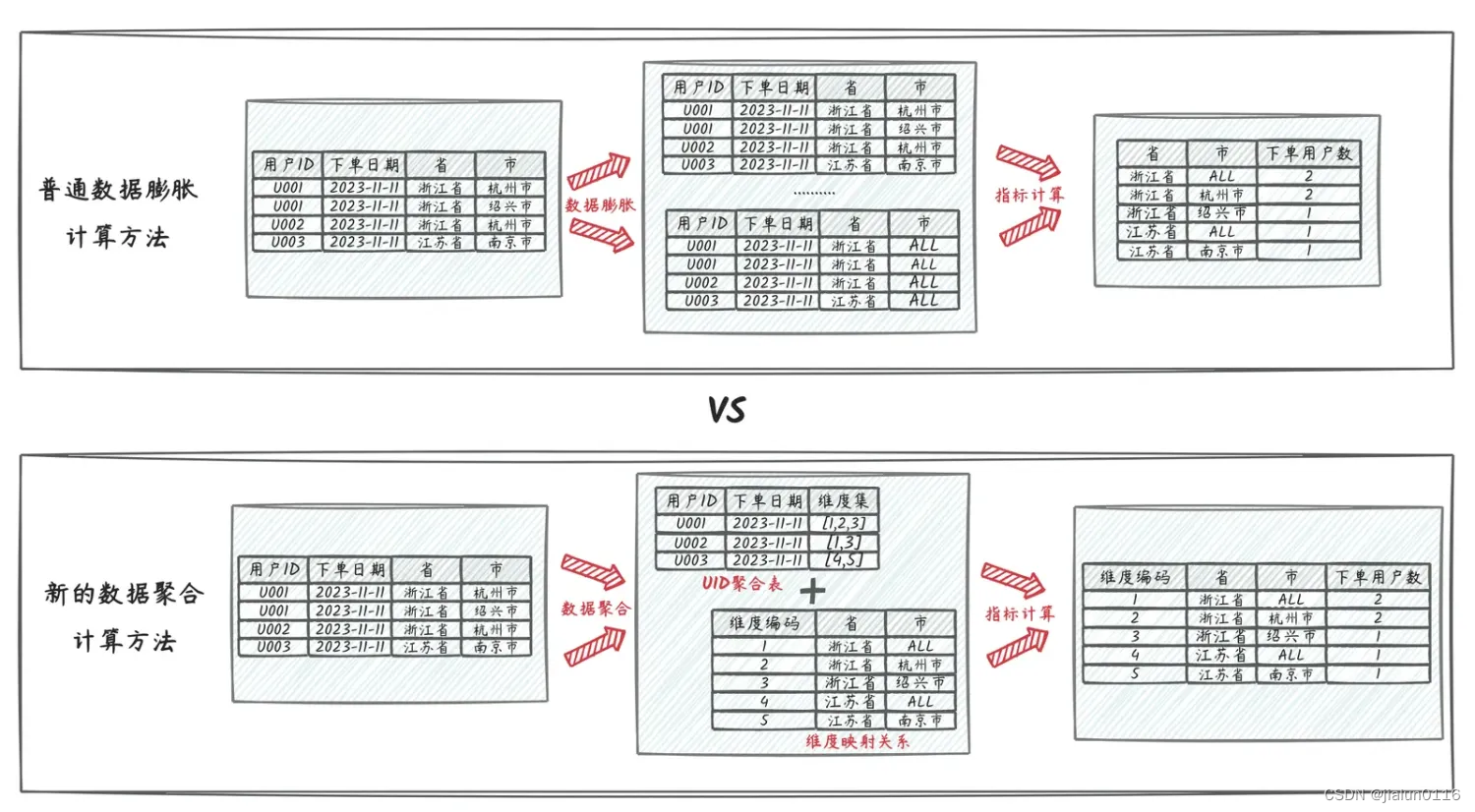
核心计算思路如上图,普通的数据膨胀计算cube的方法,中间需要对数据进行膨胀,再聚合,其中结果统计需要的组合维度数就是数据膨胀的倍数,比如上述的“省、省+市”共计两种维度组合,数据预计要膨胀2倍。
而新的数据聚合方法,通过一定的策略方法将维度组合拆解为维度小表并进行编号,然后将原本的订单明细数据聚合至用户粒度的中间过程数据,其中各类组合维度转换为数字标记录至用户维度的数据记录上,整个计算过程数据量是呈收敛聚合的,不会膨胀。
逻辑实现
明细数据准备:以用户线下支付数据为例,明细记录包含订单编号、用户ID、支付日期、所在省、所在市、支付金额。最终指标统计需求为统计包含省、市组合维度+支付用户数的多维Cube。
订单编号 用户ID 支付日期 所在省 所在市 支付金额
2023111101 U001 2023-11-11 浙江省 杭州市 1.11
2023111102 U001 2023-11-11 浙江省 绍兴市 2.22
2023111103 U002 2023-11-11 浙江省 杭州市 3.33
2023111104 U003 2023-11-11 江苏省 南京市 4.44
2023111105 U003 2023-11-11 浙江省 温州市 5.55
2023111106 U004 2023-11-11 江苏省 南京市 6.66
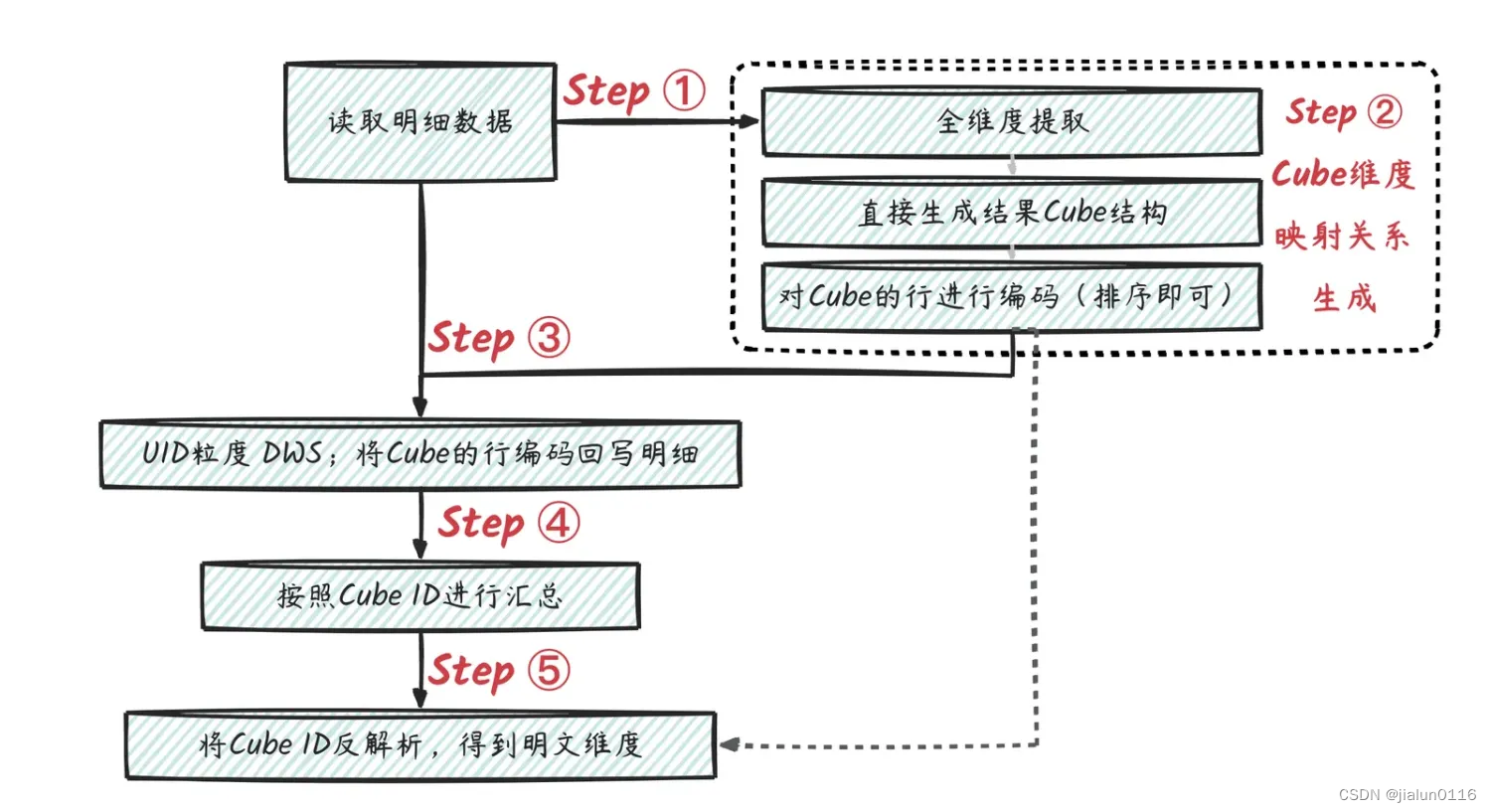
整体方案流程如下图。
-
STEP1:对明细数据进行所需的维度提取(即Group By对应字段),得到维度集合。
所在省 所在市
浙江省 杭州市
浙江省 绍兴市
浙江省 温州市
江苏省 南京市 -
STEP2:对得到的维度集合生成Cube,并对Cube的行进行编码 (假设最终需要所在省、所在省+所在市 2种组合维度),可以用ODPS的Cube功能实现,再根据生成的Cube维度组合进行排序生成唯一编码。
原始维度:所在省 原始维度:所在省 Cube 维度:所在省 Cube 维度:所在市 Cube行ID(可通过排序生成)
浙江省 杭州市 浙江省 ALL 1
浙江省 杭州市 浙江省 杭州市 2
浙江省 绍兴市 浙江省 ALL 1
浙江省 绍兴市 浙江省 绍兴市 3
浙江省 温州市 浙江省 ALL 1
浙江省 温州市 浙江省 温州市 4
江苏省 南京市 江苏省 ALL 5
江苏省 南京市 江苏省 南京市 6 -
STEP3:将Cube的行编码,根据映射关系回写到用户明细上,可用Mapjoin的方式实现。
订单编号 用户ID 支付日期 所在省 所在市 汇总Cube ID
2023111101 U001 2023-11-11 浙江省 杭州市 [1,2]
2023111102 U001 2023-11-11 浙江省 绍兴市 [1,3]
2023111103 U002 2023-11-11 浙江省 杭州市 [1,2]
2023111104 U003 2023-11-11 江苏省 南京市 [5,6]
2023111105 U003 2023-11-11 浙江省 温州市 [1,4]
2023111106 U004 2023-11-11 江苏省 南京市 [5,6] -
STEP4:汇总到用户维度,并对 Cube ID集合字段进行去重 (可以用ARRAY 的DISTINCT)
用户ID 汇总Cube ID
U001 [1,2,3]
U002 [1,2]
U003 [1,4,5,6]
U004 [5,6] -
STEP5:按照Cube ID进行计数计算(由于STEP4已经去重啦,因此这里不需要再进行去重);然后按照映射关系进行维度还原。
Cube ID 下单用户数指标 Cube 维度还原:所在省 Cube 维度还原:所在市
1 3 浙江省 ALL
2 2 浙江省 杭州市
3 1 浙江省 绍兴市
4 1 浙江省 温州市
5 2 江苏省 ALL
6 2 江苏省 江苏省
代码实现
-- CREATE TABLE IF NOT EXISTS tmp_user_pay_order_detail
-- LIFECYCLE 30 AS
-- SELECT '2023111101' AS trade_no,'U001' AS payer_user_id,'20231111' AS gmt_pay,1.11 AS trade_pay_amt,'浙江省' AS province_name,
-- 1 AS province_code,'杭州市' AS city_name, 11 AS city_code
-- UNION ALL SELECT '2023111102','U001','20231111',2.22,'浙江省',1,'绍兴市',12
-- UNION ALL SELECT '2023111103','U002','20231111',3.33,'浙江省',1,'杭州市',11
-- UNION ALL SELECT '2023111104','U003','20231111',4.44,'江苏省',2,'南京市',22
-- UNION ALL SELECT '2023111105','U003','20231111',5.55,'浙江省',1,'温州市',13
-- UNION ALL SELECT '2023111106','U004','20231111',6.66,'江苏省',2,'南京市',22WITH dim_cube AS
(SELECT*,DENSE_RANK() OVER(PARTITION BY 1 ORDER BY cube_province_name,cube_city_name) AS cube_id FROM (SELECT dim_key,COALESCE(IF(GROUPING(province_name) = 0,province_name,'ALL'),'na') AS cube_province_name ,COALESCE(IF(GROUPING(city_name ) = 0,city_name ,'ALL'),'na') AS cube_city_name FROM (SELECT CONCAT('',COALESCE(province_name ,''),'#' ,COALESCE(city_name,''),'#' ) AS dim_key,province_name,city_nameFROM tmp_user_pay_order_detailGROUP BY province_name,city_name)t GROUP BY dim_key,province_name,city_nameGROUPING SETS((dim_key,province_name),(dim_key,province_name,city_name)))
),detail_ext AS
(SELECT payer_user_id,ARRAY_DISTINCT(SPLIT(WM_CONCAT(';',cube_ids),';')) as cube_id_arryFROM (SELECT /*+ MAPJOIN(dim_cube) */ payer_user_id,cube_idsFROM (SELECT payer_user_id,CONCAT('',COALESCE(province_name ,''),'#' ,COALESCE(city_name ,''),'#' ) AS dim_keyFROM tmp_user_pay_order_detail) dwd_detailJOIN (SELECT dim_key,WM_CONCAT(';',cube_id) AS cube_idsFROM dim_cube GROUP BY dim_key) dim_cubeON dwd_detail.dim_key = dim_cube.dim_key)GROUP BY payer_user_id
)
SELECT cube_id,MAX(province_name) AS province_name,MAX(city_name ) AS city_name,MAX(uid_cnt ) AS user_cnt
FROM
(SELECT cube_id AS cube_id,COUNT(1) AS uid_cnt,CAST(NULL AS STRING) AS province_name,CAST(NULL AS STRING) AS city_nameFROM detail_extLATERAL VIEW EXPLODE(cube_id_arry) arr AS cube_idGROUP BY cube_idUNION ALL SELECT CAST(cube_id AS STRING) AS cube_id,CAST(NULL AS BIGINT) AS uid_cnt,cube_province_name AS province_name,cube_city_name AS city_name FROM dim_cube
) base
GROUP BY cube_id```