第 1 章:Kafka概述
1.1 定义
Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分为不同的类别,订阅者只接收感兴趣的消息。
1.2 消息队列
目前企业中比较常见的消息队列产品主要有Kafka、ActiveMQ、RabbitMQ、RocketMQ等。
在大多数场景主要采用Kafka作为消息队列
在JavaEE开发中主要采用ActiveMQ、RabbitMQ、RocketMQ
1.2.1 传统消息队列的应用场景
1、传统的消费队列的主要应用场景有:缓存/削峰(缓冲)、解耦(少依赖)、异步通信(不必要及时处理)
1)缓存/削峰(缓冲):有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
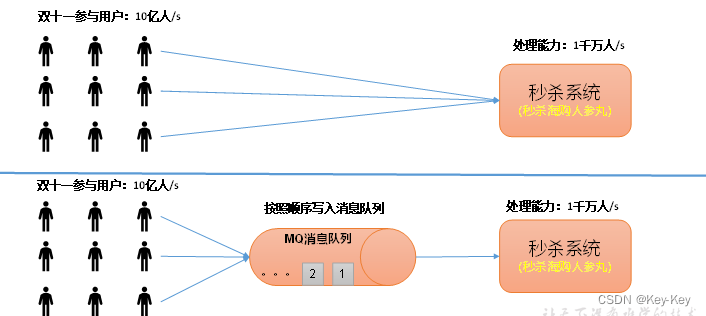
2)解耦:允许你独立的扩展或修改两边的处理过程,只要确保它们遵循同样的接口约束。
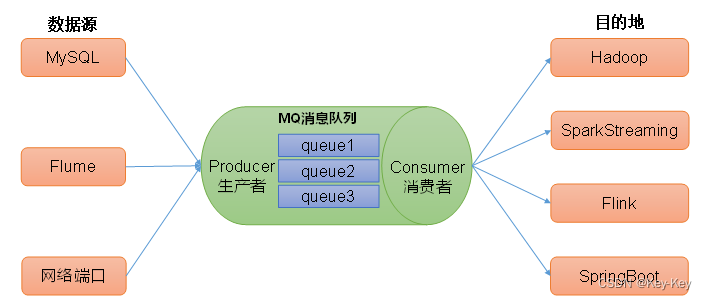
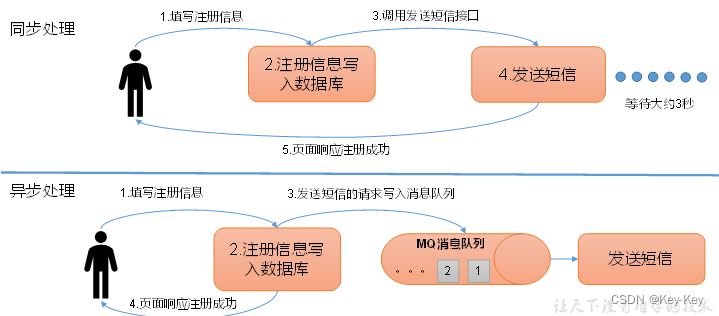
3)异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后再需要的时候再去处理它们。
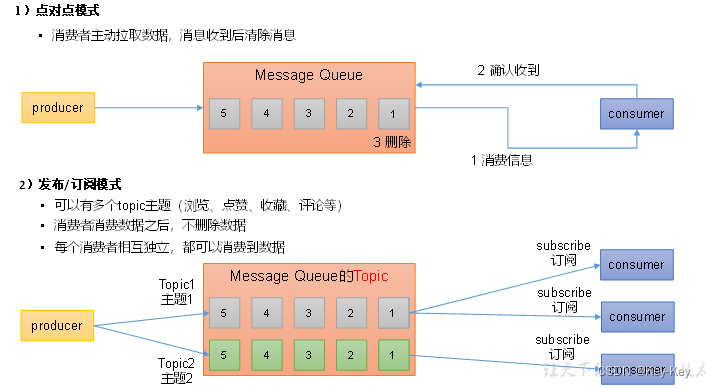
1.2.2 消息队列的两种模式
消息队列主要分为两种模式:点对点模式(一个生产者对口一个消费者)和发布/订阅模式(一对多)
1.3 Kafka基础框架
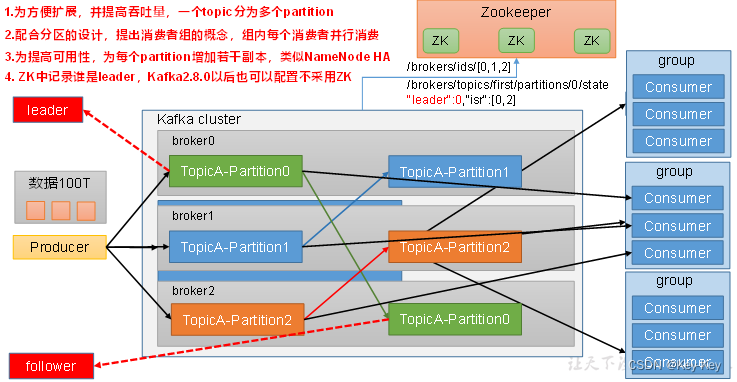
1、Producer:消息生产者,就是向Kafka broker发消息的客户端
2、Consumer:消息消费者,向kafka broker获取消息的客户端
3、Consumer Group(CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个broker可以由多个不同的topic,一个topic下的一个分区只能被一个消费者组内的一个消费者所消费;消费者之间不受影响。消费者组是逻辑上的一个订阅者。
4、Broker:一个kafka服务器就是一个broker。一个broker可以容纳多个不同topic
5、Topic:可以理解为一个队列,生产者和消费者面向的都是一个topic
6、Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列
7、Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个发你去都有若干个副本,一个leader和若干个follower
8、leader:每个分区副本中的”主“,生产者发送数据的对象,以及消费者消费数据的对象都是leader
9、followeer:每个分区副本中的“从”,实现于leader副本保持同步,在leader发送故障时,称为新的leader
第 2 章:Kafka快速入门
2.1 安装部署
2.1.1 集群部署
2.1.2 集群部署
1、官方下载地址:http://kafka.apache.org/downloads.html
2、上传安装包到102的/opt/software目录下:
[atguigu@hadoop102 software]$ ll
-rw-rw-r--. 1 atguigu atguigu 86486610 3月 10 12:33 kafka_2.12-3.0.0.tgz3、解压安装包到/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
4、进入到/opt/module目录下,修改解压包名为kafka
[atguigu@hadoop102 module]$ mv kafka_2.12-3.0.0 kafka
5、修改config目录下的配置文件server.properties内容如下
[atguigu@hadoop102 kafka]$ cd config/
[atguigu@hadoop102 config]$ vim server.properties
#broker的全局唯一编号,不能重复,只能是数字。
broker.id=102
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka运行日志(数据)存放的路径,路径不需要提前创建,kafka自动帮你创建,可以配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/module/kafka/datas
#topic在当前broker上的分区个数
num.partitions=1
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个topic创建时的副本数,默认时1个副本
offsets.topic.replication.factor=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个segment文件的大小,默认最大1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认5分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接Zookeeper集群地址(在zk根目录下创建/kafka,方便管理)
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka6、配置环境变量
[atguigu@hadoop102 kafka]$ sudo vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[atguigu@hadoop102 kafka]$ source /etc/profile7、分发环境变量文件并source
[atguigu@hadoop102 kafka]$ xsync /etc/profile.d/my_env.sh
==================== hadoop102 ====================
sending incremental file listsent 47 bytes received 12 bytes 39.33 bytes/sec
total size is 371 speedup is 6.29
==================== hadoop103 ====================
sending incremental file list
my_env.sh
rsync: mkstemp "/etc/profile.d/.my_env.sh.Sd7MUA" failed: Permission denied (13)sent 465 bytes received 126 bytes 394.00 bytes/sectotal size is 371 speedup is 0.63
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1178) [sender=3.1.2]
==================== hadoop104 ====================
sending incremental file list
my_env.sh
rsync: mkstemp "/etc/profile.d/.my_env.sh.vb8jRj" failed: Permission denied (13)sent 465 bytes received 126 bytes 1,182.00 bytes/sec
total size is 371 speedup is 0.63
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1178) [sender=3.1.2],
# 这时你觉得适用sudo就可以了,但是真的是这样吗?
[atguigu@hadoop102 kafka]$ sudo xsync /etc/profile.d/my_env.sh
sudo: xsync:找不到命令
# 这时需要将xsync的命令文件,copy到/usr/bin/下,sudo(root)才能找到xsync命令
[atguigu@hadoop102 kafka]$ sudo cp /home/atguigu/bin/xsync /usr/bin/
[atguigu@hadoop102 kafka]$ sudo xsync /etc/profile.d/my_env.sh
# 在每个节点上执行source命令,如何你没有xcall脚本,就手动在三台节点上执行source命令。
[atguigu@hadoop102 kafka]$ xcall source /etc/profile8、分发安装包
[atguigu@hadoop102 module]$ xsync kafka/
9、修改配置文件的brokerid
分别在hadoop103和104上修改配置文件server.properties中的broker.id=103、broker.id=104
注:broker.id不得重复
[atguigu@hadoop103 kafka]$ vim config/server.properties
broker.id=103
[atguigu@hadoop104 kafka]$ vim config/server.properties
broker.id=10410、启动集群
1)先启动Zookeeper集群
[atguigu@hadoop102 kafka]$ zk.sh start
2)一次在102、103、104节点启动kafka
[atguigu@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties [atguigu@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties [atguigu@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
11、关闭集群
[atguigu@hadoop102 kafka]$ bin/kafka-server-stop.sh
[atguigu@hadoop103 kafka]$ bin/kafka-server-stop.sh
[atguigu@hadoop104 kafka]$ bin/kafka-server-stop.sh
2.1.4 kafka群起脚本
1、脚本编写
在/home/atguigu/bin目录下创建文件kafka.sh脚本文件:
#! /bin/bash
if (($#==0)); thenecho -e "请输入参数:\n start 启动kafka集群;\n stop 停止kafka集群;\n" && exit
ficase $1 in"start")for host in hadoop103 hadoop102 hadoop104doecho "---------- $1 $host 的kafka ----------"ssh $host "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"done;;"stop")for host in hadoop103 hadoop102 hadoop104doecho "---------- $1 $host 的kafka ----------"ssh $host "/opt/module/kafka/bin/kafka-server-stop.sh"done;;*)echo -e "---------- 请输入正确的参数 ----------\n"echo -e "start 启动kafka集群;\n stop 停止kafka集群;\n" && exit;;
esac2、脚本文件添加权限
[atguigu@hadoop102 bin]$ chmod +x kafka.sh
注意:
停止Kafka集群时,一定要等kafka所有节点进程全部停止后再停止Zookeeper集群。
因为Zookeeper集群当中记录着kafka集群相关信息,Zookeeper集群一旦先停止,Kafka集群就没有办法再获取停止进程的信息,只能手动杀死Kafka进程了。
2.2 Kafka命令行操作
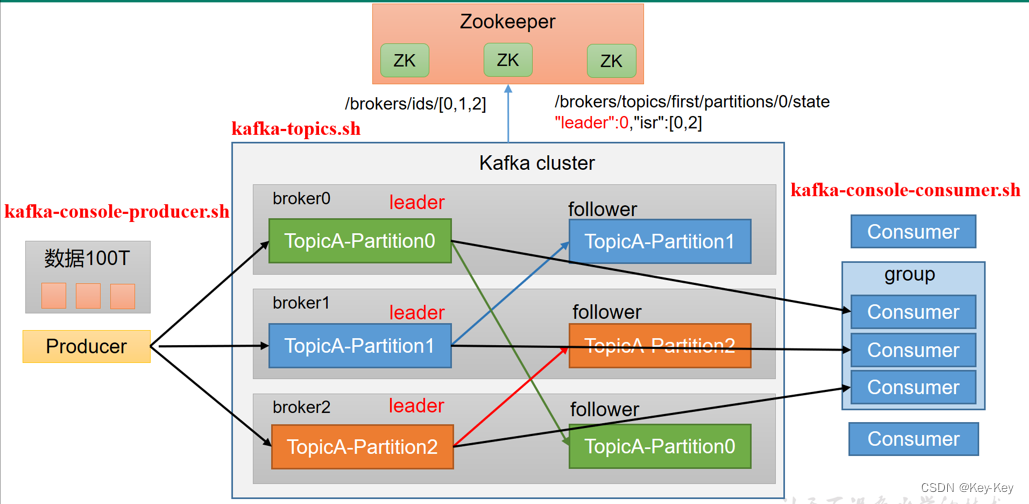
2.2.1 主题命令行操作
1、查看操作主题命令需要的参数
2、重要的参数如下
| 参数 | 描述 |
|---|---|
| –bootstrap-server | 连接kafka Broker主机名称和端口号 |
| –topic | 操作的topic名称 |
| –create | 创建主题 |
| –delete | 删除主题 |
| –alter | 修改主题 |
| –list | 查看所有主题 |
| –describe | 查看主题详细描述 |
| –partitions | 设置主题分区数 |
| –replication-factor | 设置主题分区副本 |
| –config | 更新系统默认的配置 |
3、查看当前服务器中的所有topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --list
4、创建一个主题名称为first的topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --replication-factor 3 --partitions 3 --topic first
5、查看topic的详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
Topic: first TopicId: EVV4qHcSR_q0O8YyD32gFg PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824Topic: first Partition: 0 Leader: 102 Replicas: 102,103,104 Isr: 102,103,104
6、修改分区数(注意:分区数只能增加,不能减少)
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3
7、再次查看Topic的详情
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first
Topic: first TopicId: EVV4qHcSR_q0O8YyD32gFg PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824Topic: first Partition: 0 Leader: 102 Replicas: 102,103,104 Isr: 102,103,104Topic: first Partition: 1 Leader: 103 Replicas: 103,104,102 Isr: 103,104,102Topic: first Partition: 2 Leader: 104 Replicas: 104,102,103 Isr: 104,102,1038、删除topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic first
2.2.2 生产者命令行操作
1、查看命令行生产者的参数
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh
2、重要的参数如下:
| 参数 | 描述 |
|---|---|
| –bootstrap-server | 连接kafka Broker主机名称和端口号 |
| –topic | 操作的topic名称 |
| 3、生产消息 |
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh --broker-list hadoop102:9092 --topic first
>hello world
>atguigu atguigu2.2.3 消费者命令行操作
1、查看命令行消费者的参数
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh
2、重要的参数如下:
| 参数 | 描述 |
|---|---|
| –bootstrap-server | 连接kafka Broker主机名称和端口号 |
| –topic | 操作的topic名称 |
| –from-beginning | 从头开始消费 |
| –group | 指定消费者组名称 |
| 3、消费消息 |
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
4、从头开始消费
[atguigu@hadoop102 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first
思考:再次查看当前kafka中的topic列表,发现了什么?为什么?
第 3 章:Kafka生产者
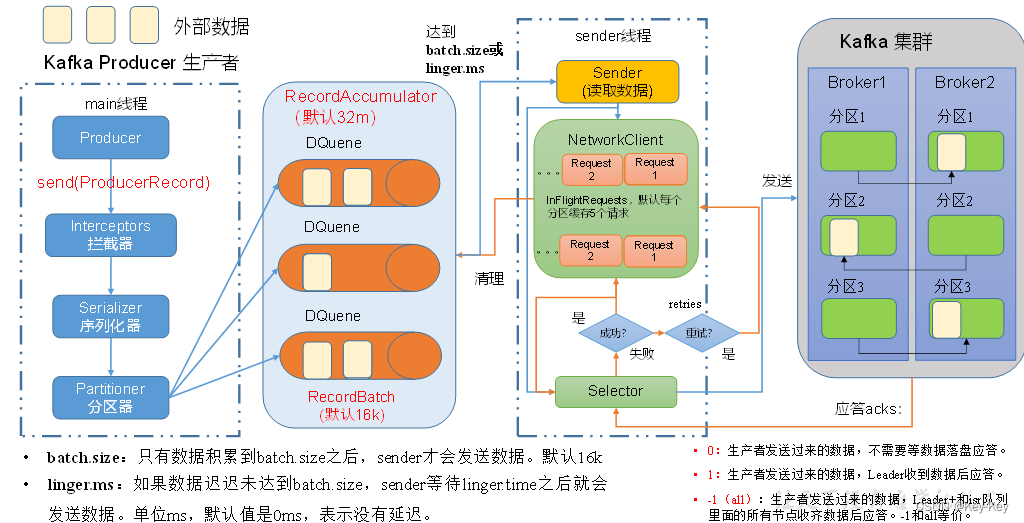
3.1 生产者消息发送流程
3.1.1 发送原理
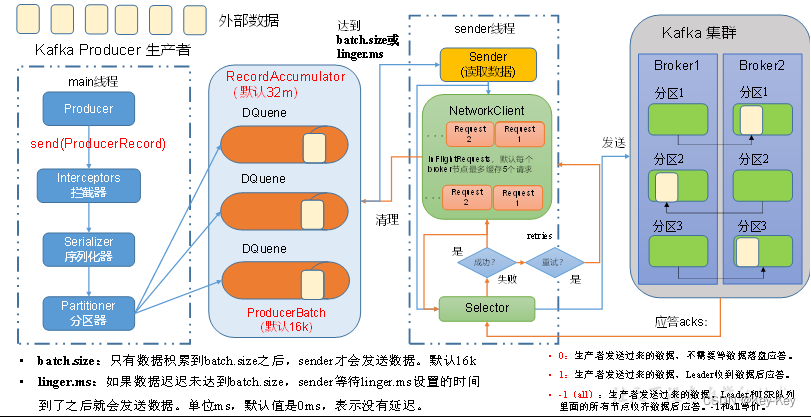
Kafka的Producer发送消息采用的是异步发送的方式。
在消息发送的过程中,涉及到了两个线程:main线程和Sender线程,以及一个线程共享变量:RecordAccumulator。
1、main线程中创建了一个双端队列RecordAccumulator,将消息发送给RecordAccumulator。
2、Sender线程不断从RecordAccumulator中拉取消息发送到Kafka broker。
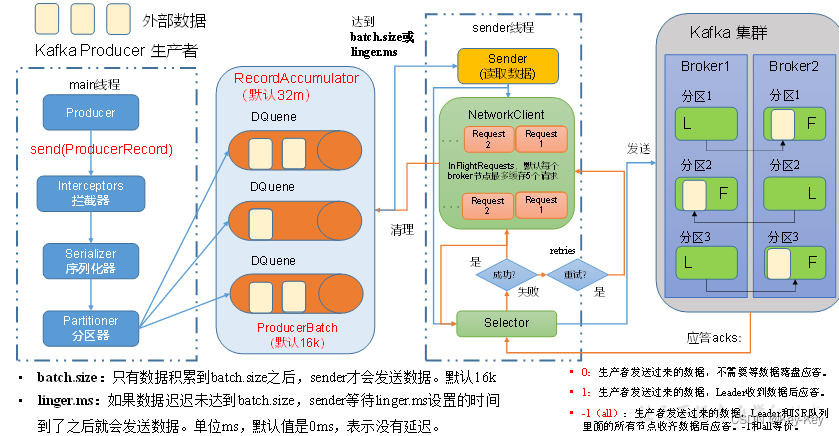
batch.size:只有数据积累到batch size之后,sender才会发送数据。默认16k
linger.ms:如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间到了之后就会发送数据。单位ms,默认值0ms,表示没有延迟。
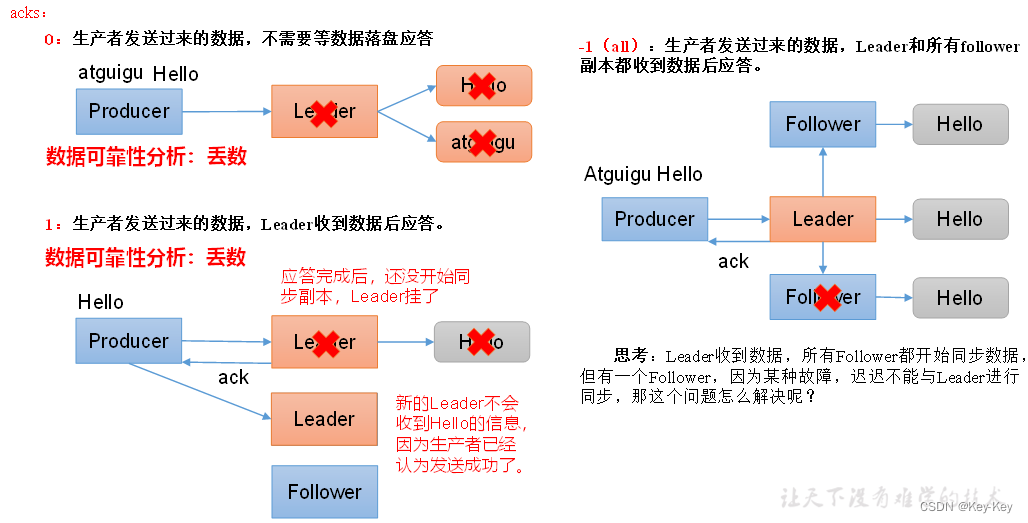
0:生产者发送过来的数据,不需要等数据磁盘应答。
1:生产者发送过来的数据,Leader收到数据后应答。
2:-l(all):生产者发送过来的数据,Leader和SR队列里面的所有节点收起数据后应答。-l和all等价。
3.1.2 生产者重要参数列表
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 生产者连接集群所需的broker地址清单。可以设置1个或者多个,中间用逗号隔开。生产者从给定的broker里查找到其它broker信息。 |
| key.serializer、value.serializer | 指定发送消息的key和value的序列化类型。要写全类名。(反射获取) |
| buffer.memory | RecordAccumulator缓冲区大小,默认32m。 |
| batch.size | 缓冲区一批数据最大值,默认16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。 |
| linger.ms | 如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。单位ms,默认值是0ms,表示没有延迟。生产环境建议该值大小为5-100ms之间。 |
| acks | 0:生产者发送过来的数据,不需要等数据落盘应答。1:生产者发送过来的数据,Leader数据落盘后应答。-1(all):生产者发送过来的数据,Leader和isr队列里面的所有节点数据都落盘后应答。默认值是-1 |
| max.in.flight.requests.per.connection | 允许最多没有返回ack的次数,默认为5,开启幂等性要保证该值是1-5的数字。 |
| Retries(重试) | 当消息发送出现错误的时候,系统会重发消息。retries表示重试次数。默认是int最大值,2147483647。如果设置了重试,还想保证消息的有序性,需要设置MAX_IN_flight_requests_per_connection=1否则在重试此失败消息的时候,其它的消息可能发送成功了。 |
| retry.backoff.ms | 两次重试之间的时间间隔,默认是100ms。 |
| enable.idempotence | 是否开启幂等性,默认true,开启幂等性。 |
| compression.type | 生产者发送的所有数据的压缩方式。默认是none,不压缩。支持压缩类型:none、gzip、snappy、lz4和zstd。 |
3.2 异步发送API
3.2.1 普通异步发送
1、需求:创建Kafka生产者,采用异步的方式发送到Kafka broker
2、异步发送流程如下:
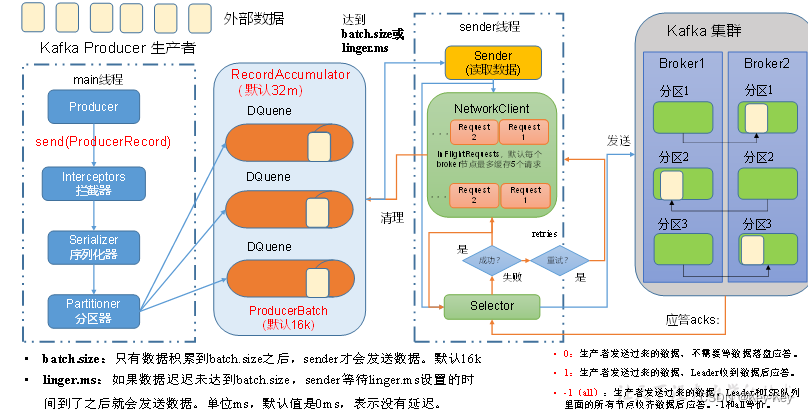
3、代码编写
1)创建工程kafka-demo
2)导入依赖
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependencies><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.0.0</version></dependency>
</dependencies>3)创建包名:com.atguigu.kafka.producer
4)编写代码:不带回调函数的API
package com.atguigu.kafka.producer;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;public class CustomProducer {public static void main(String[] args) throws InterruptedException {// 1. 创建kafka生产者的配置对象Properties properties = new Properties();// 2. 给kafka配置对象添加配置信息properties.put("bootstrap.servers","hadoop102:9092");// key,value序列化properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 3. 创建kafka生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);// 4. 调用send方法,发送消息for (int i = 0; i < 10; i++) {kafkaProducer.send(new ProducerRecord<>("first","kafka" + i));}// 5. 关闭资源kafkaProducer.close();}
} 5)测试:
在hadoop102上开启kafka消费者
[atguigu@hadoop104 kafka]$ sbin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
在IDEA中执行上述代码,观察hadoop102消费者输出
[atguigu@hadoop104 kafka]$ sbin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
kafka0
kafka1
kafka2
kafka3
……3.2.2 带回调函数的异步发送
1、回调函数callback()会在producer受到ack时调用,为异步屌用。
该方法有两个参数分别是RecordMetadata(元数据信息)和Exception(异常信息)。
1)如果Exception为null,说明消息发送成功。
2)如果Exception不为null,说明消息发送不成功。
2、带回掉函数的异步调用发送流程
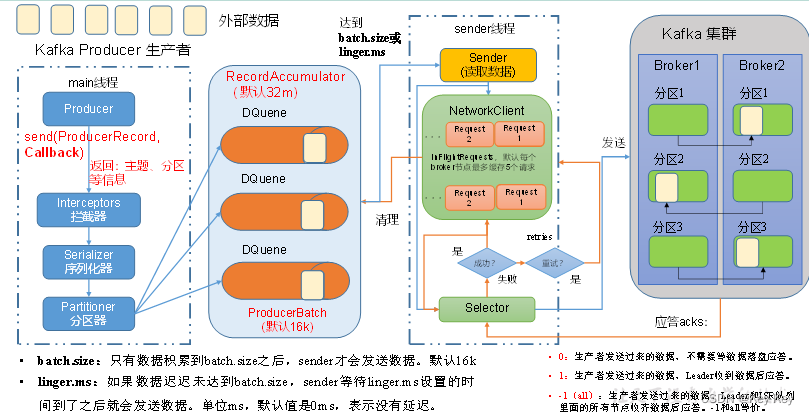
注意:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
3、编写代码:带回调函数的生产者
package com.atguigu.kafka.producer;import org.apache.kafka.clients.producer.*;
import java.util.Properties;public class CustomProducerCallback {public static void main(String[] args) throws InterruptedException {// 1. 创建kafka生产者的配置对象Properties properties = new Properties();// 2. 给kafka配置对象添加配置信息properties.put("bootstrap.servers", "hadoop102:9092");properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key,value序列化(必须)properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 3. 创建kafka生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);// 4. 调用send方法,发送消息for (int i = 0; i < 10; i++) {// 添加回调kafkaProducer.send(new ProducerRecord<>("first", "kafka" + i), new Callback() {// 该方法在Producer收到ack时调用,为异步调用@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception == null) // 没有异常,输出信息到控制台System.out.println("主题"+recordMetadata.topic() +", 分区:"+recordMetadata.partition()+", 偏移量:"+recordMetadata.offset());}});}// 5. 关闭资源kafkaProducer.close();}
}4、测试
1)在hadoop102上开启kafka消费者
[atguigu@hadoop104 kafka]$ sbin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
2)在IDEA中执行代码,观察hadoop102消费者输出
[atguigu@hadoop104 kafka]$ sbin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
kafka0
kafka1
kafka2
……3)在IDEA控制台观察回调函数
主题first, 分区:0, 偏移量:10
主题first, 分区:0, 偏移量:11
主题first, 分区:0, 偏移量:12
主题first, 分区:0, 偏移量:13
主题first, 分区:0, 偏移量:14
主题first, 分区:0, 偏移量:15
主题first, 分区:0, 偏移量:16
主题first, 分区:0, 偏移量:17
主题first, 分区:0, 偏移量:18
主题first, 分区:0, 偏移量:19
……3.3 同步发送API
1、同步发送的意思就是,一条消息发送之后,会阻塞当前线程,直至返回ack。
由于send方法返回的是一个Future对象,根据Future对象的特点,我们也可以实现同步发送的效果,只需要调用Future对象的get方法即可。
2、同步发送流程示意图如下:
3、编写代码:同步发送消息的生产者
package com.atguigu.kafka.producer;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
import java.util.concurrent.ExecutionException;public class ConsumerProducerSync {public static void main(String[] args) throws InterruptedException, ExecutionException {// 1. 创建kafka生产者的配置对象Properties properties = new Properties();// 2. 给kafka配置对象添加配置信息//properties.put("bootstrap.servers","hadoop102:9092");properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// key,value序列化(必须)properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 3. 创建kafka生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);// 4. 调用send方法,发送消息for (int i = 0; i < 10; i++) {// 同步发送kafkaProducer.send(new ProducerRecord<>("first","kafka" + i)).get();}// 5. 关闭资源kafkaProducer.close();}
}4、测试
1)在hadoop102上开启kafka消费者
[atguigu@hadoop104 kafka]$ sbin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
2)在IDEA中执行代码,观察102消费者的消费情况
[atguigu@hadoop104 kafka]$ sbin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
kafka0
kafka1
kafka2
……3.4 生产者分区
3.4.1 分区的原因
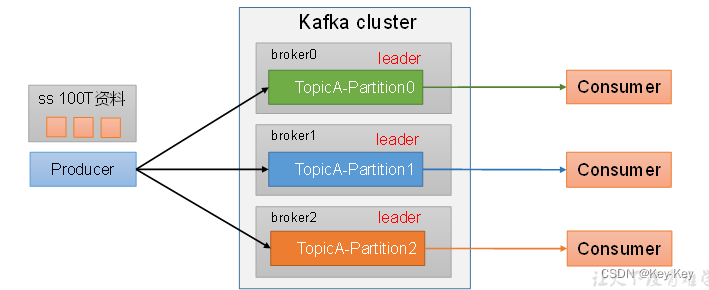
1、便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块一块的数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
2、提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
3.4.2 生产者分区策略
1、默认分区器DefaultPartitioner
The default partitioning strategy:
·If a partition is specified in the record, use it
·If no partition is specified but a key is present choose a partition based on a hash of the key
·If no partition or key is present choose the sticky partition that changes when the batch is full.
public class DefaultPartitioner implements Partitioner {
… …
}
2、使用:
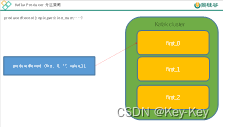
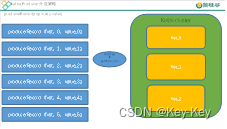
1)我们需要将producer发送的数据封装成一个ProducerRecord对象。
2)上述的分区策略,我们在ProducerRecord对象中进行配置。
3)策略实现
| 代码 | 解释 |
|---|---|
| ProducerRecord(topic,partition_num,…) | 指明partition的情况下直接发往指定的分区,key的分配方式将无效 |
| ProducerRecord(topic,key,value) | 没有指明partition值但有key的情况下:将key的hash值与topic的partition个数进行取余得到分区号 |
| ProducerRecord(topic,value) | 既没有partition值又没有key值得情况下:kafka采用Sticky Partition(黏性分区器),会随机选择一个分区,并尽可能一直使用该分区,待该分区的batch已满或者已完成,kafka再随机一个分区(绝对不会是上一个)进行使用。 |
| 3、案例: | |
| 1)案例1:将数据发送到指定partition的情况下,如:将所有消息发送到分区1中。 |
package com.atguigu.kafka.producer;import org.apache.kafka.clients.producer.*;
import java.util.Properties;public class CustomProducerCallbackPartitions {public static void main(String[] args) {// 1. 创建kafka生产者的配置对象Properties properties = new Properties();// 2. 给kafka配置对象添加配置信息properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");// key,value序列化(必须):properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 3. 创建生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);// 4. 造数据for (int i = 0; i < 5; i++) {// 指定数据发送到1号分区,key为空(IDEA中ctrl + p查看参数)kafkaProducer.send(new ProducerRecord<>("first", 1,"","atguigu " + i), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception e) {if (e == null){System.out.println("主题:" + metadata.topic() + "->" + "分区:" + metadata.partition());}else {e.printStackTrace();}}});}kafkaProducer.close();}
}2)测试:
(1)在hadoop102上开启kafka消费者
[atguigu@hadoop104 kafka]$ sbin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
(2)在IDEA中执行代码,观察hadoop102上的消费者消费情况
[atguigu@hadoop104 kafka]$ sbin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
atguigu0
atguigu1
kafka2
……(3)观察IDEA中控制台输出
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
主题:first->分区:1
主题:first->分区:13)案例2:没有指明partition但是有key的情况下的消费者分区分配
package com.atguigu.kafka.producer;import org.apache.kafka.clients.producer.*;
import java.util.Properties;public class CustomProducerCallbackKey {public static void main(String[] args) {// 1. 创建配置对象Properties properties = new Properties();// 2. 配置属性properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 3. 创建生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);// 4. 造数据for (int i = 1; i < 11; i++) {// 创建producerRecord对象final ProducerRecord<String, String> producerRecord = new ProducerRecord<>("first", i + "",// 依次指定key值为i"atguigu " + i);kafkaProducer.send(producerRecord, new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception e) {if (e == null){System.out.println("消息:"+producerRecord.value()+", 主题:" + metadata.topic() + "->" + "分区:" + metadata.partition());}else {e.printStackTrace();}}});}kafkaProducer.close();}
}4)测试
观察IDEA中控制台输出
消息:atguigu 1, 主题:first->分区:0
消息:atguigu 5, 主题:first->分区:0
消息:atguigu 7, 主题:first->分区:0
消息:atguigu 8, 主题:first->分区:0
消息:atguigu 2, 主题:first->分区:2
消息:atguigu 3, 主题:first->分区:2
消息:atguigu 9, 主题:first->分区:2
消息:atguigu 4, 主题:first->分区:1
消息:atguigu 6, 主题:first->分区:1
消息:atguigu 10, 主题:first->分区:13.4.3 自定义分区器
1、生产环境中,我们往往需要更加自由的分区需求,我们可以自定义分区器。
2、需求:在上面的根据key分区案例中,我们发现与我们知道的hash分区结果不同。那么我们就实现一个。
3、实现步骤:
1)定义类,实现Partitioner接口
2)重写partition()方法
4、代码实现
package com.atguigu.kafka.partitioner;import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;/*** @author leon* @create 2020-12-11 10:43* 1. 实现接口Partitioner* 2. 实现3个方法:partition,close,configure* 3. 编写partition方法,返回分区号*/
public class MyPartitioner implements Partitioner {/*** 分区方法**/@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {// 1. 获取keyString keyStr = key.toString();// 2. 创建分区号,返回的结果int partNum;// 3. 计算key的hash值int keyStrHash = keyStr.hashCode();// 4. 获取topic的分区个数int partitionNumber = cluster.partitionCountForTopic(topic);// 5. 计算分区号partNum = Math.abs(keyStrHash) % partitionNumber;// 4. 返回分区号return partNum;}// 关闭资源@Overridepublic void close() {}// 配置方法@Overridepublic void configure(Map<String, ?> configs) {}
}5、测试
在生产者代码中,通过配置对象,添加自定义分区器
// 添加自定义分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG," com.atguigu.kafka.partitioner.MyPartitioner ");在hadoop102上启动kafka消费者
[atguigu@hadoop102 kafka]$ sbin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
在IDEA中观察回调信息
消息:atguigu 2, 主题:first->分区:2
消息:atguigu 5, 主题:first->分区:2
消息:atguigu 8, 主题:first->分区:2
消息:atguigu 1, 主题:first->分区:1
消息:atguigu 4, 主题:first->分区:1
消息:atguigu 7, 主题:first->分区:1
消息:atguigu 10, 主题:first->分区:1
消息:atguigu 3, 主题:first->分区:0
消息:atguigu 6, 主题:first->分区:0
消息:atguigu 9, 主题:first->分区:03.5 生产经验-生产者如何提高吞吐量
3.5.1 吞吐量

3.5.2 实例
1、编写代码
package com.atguigu.kafka.producer;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;public class CustomProducerParameters {public static void main(String[] args) throws InterruptedException {// 1. 创建kafka生产者的配置对象Properties properties = new Properties();// 2. 给kafka配置对象添加配置信息:bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key,value序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");// batch.size:批次大小,默认16Kproperties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);// linger.ms:等待时间,默认0properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);// RecordAccumulator:缓冲区大小,默认32M:buffer.memoryproperties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);// compression.type:压缩,默认none,可配置值gzip、snappy、lz4和zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");// 3. 创建kafka生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);// 4. 调用send方法,发送消息for (int i = 0; i < 5; i++) {kafkaProducer.send(new ProducerRecord<>("first","atguigu" + i));}// 5. 关闭资源kafkaProducer.close();}
}2、测试:
1)在hadoop102上开启kafka消费者
[atguigu@hadoop102 kafka]$ sbin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
2)在IDEA中执行代码,观察hadoop102上的消费者消费情况
[atguigu@hadoop102 kafka]$ sbin/kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic first
atguigu0
atguigu0
atguigu0
……3.6 生产经验-数据可靠性
1、回顾消费发送流程
2、ack应答机制
3、ack应答级别
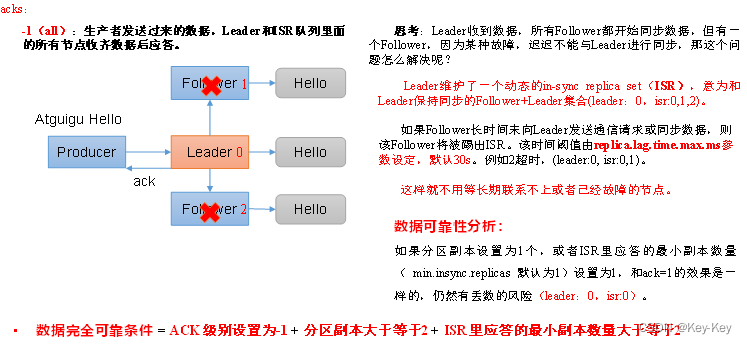
背景:leader收到数据,所有follower都开始同步数据,但有一个follower,因为某种故障,迟迟不能与leader进行同步,那leader就要一直等下去,直到它完成同步,才能发送ack。这个问题怎么解决呢?
Kafka提供的解决方案:ISR队列
1)Leader维护了一个动态的in-sync replica set(ISR)和leader保持同步的follower集合。
2)当ISR中的follower完成数据的同步之后,leader就会给producer发送ack。
3)如果follower长时间(replica.lag.time.max.ms)未向leader同步数据,则该follower将被提出ISR。
Leader发生故障之后,就会从ISR中选举新的leader。
ack应答级别
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等ISR中的follower全部接收成功。
所以Kafka为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置。
| acks=0 | 这一操作提供了一个最低的延迟,partition的leader副本接收到消息还没有写入磁盘就已经返回ack,当leader故障时有可能丢失数据 |
|---|---|
| acks=1 | partition的leader副本落盘后返回ack,如果在follower副本同步数据之前leader故障,那么将对丢失数据 |
| acks=-1 | partition的leader和follower副本全部落盘成功后才返回ack。但是如果在follower副本同步完成后,leader副本所在节点发送ack之前,leader副本发送故障,那么会造成数据重复 |
4、ack应答机制
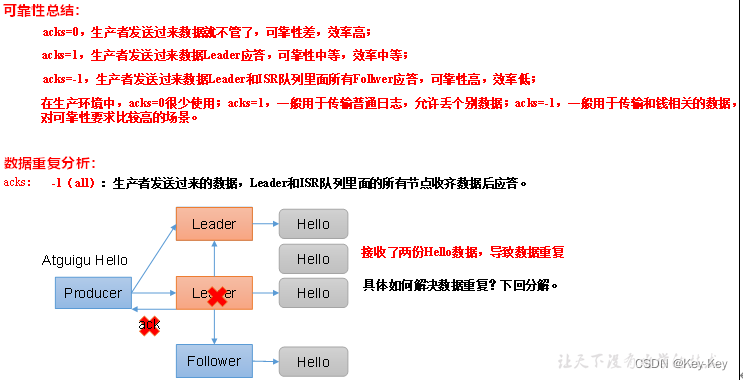
5、案例
代码编写:
package com.atguigu.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;public class CustomProducerAck {public static void main(String[] args) throws InterruptedException {// 1. 创建kafka生产者的配置对象Properties properties = new Properties();// 2. 给kafka配置对象添加配置信息:bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");// key,value序列化(必须):key.serializer,value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 设置acksproperties.put(ProducerConfig.ACKS_CONFIG, "all");// 重试次数retries,默认是int最大值,2147483647properties.put(ProducerConfig.RETRIES_CONFIG, 3);// 3. 创建kafka生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);// 4. 调用send方法,发送消息for (int i = 0; i < 5; i++) {kafkaProducer.send(new ProducerRecord<>("first","atguigu " + i));}// 5. 关闭资源kafkaProducer.close();}
} 3.7 生产经验-数据去重
3.7.1 数据传递语义
至少一次(At Least Once)=ACK级别设置为-1+分区副本大于等于2+ISR里应答的最小副本数量大于等于2
最多一次(At More Once)=ACK级别设置为0
总结:
1)At Least Once可以保证数据不丢失,但是不能保证数据不重复
2)At More Once可以保证数据不重复,但是不能保证数据不丢失
精确一次(Exactly Once):对于一些非常重要的信息,比如和钱相关的数据,要求数据既不能重复也不丢失。
3.7.2 幂等性
1、幂等性原理:
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
精确一次(Exactly Once)=幂等性+至少一次(ack=-1+分区副本数>=2+ISR最小副本数量>=2)。
重复数据的判断标准:具有<PID,Partition,SeqNumber>相同主键的消息提交时,Broker只会持久化一条。其中PID是producer每次重启都会分配一个新的:Partition表示分区号;SequenceNumber是单调自增的。
所以幂等性只能保证的是在单分区单会话内不重复。
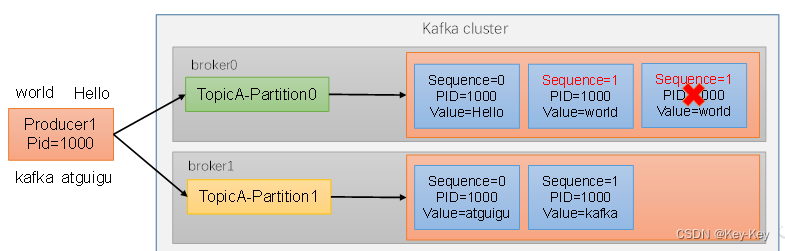
2、开启幂等性
在producer的配置对象中,添加参数enable.idempotence,参数值默认为true,设置为false就关闭了。
3.7.3 生产者事务
1、kafka事务原理
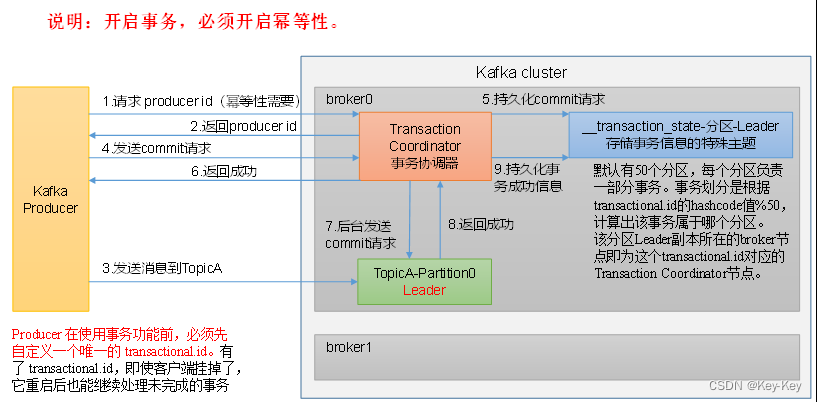
2、事务代码流程
// 1初始化事务
void initTransactions();
// 2开启事务
void beginTransaction() throws ProducerFencedException;
// 3在事务内提交已经消费的偏移量(主要用于消费者)
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,String consumerGroupId) throws ProducerFencedException;
// 4提交事务
void commitTransaction() throws ProducerFencedException;
// 5放弃事务(类似于回滚事务的操作)
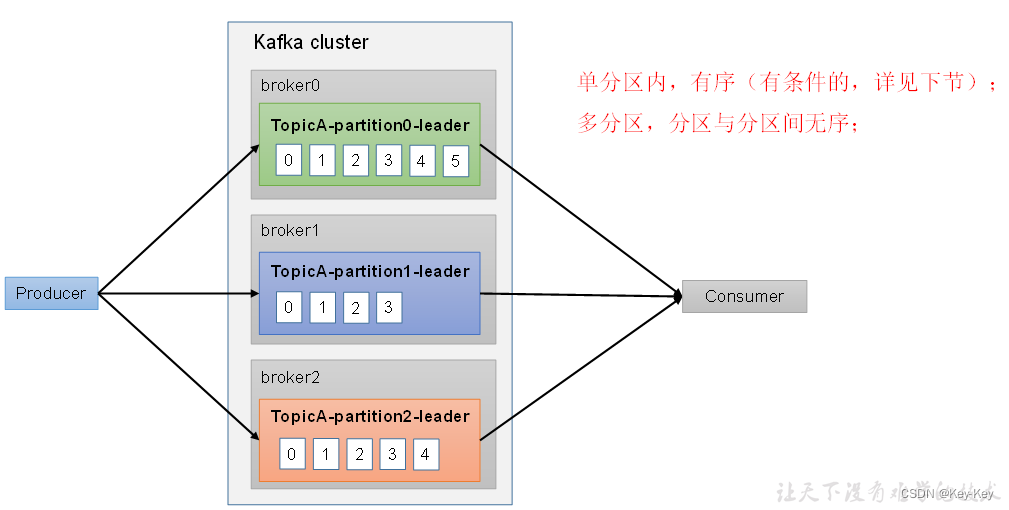
void abortTransaction() throws ProducerFencedException;3.8 生产经验-数据有序
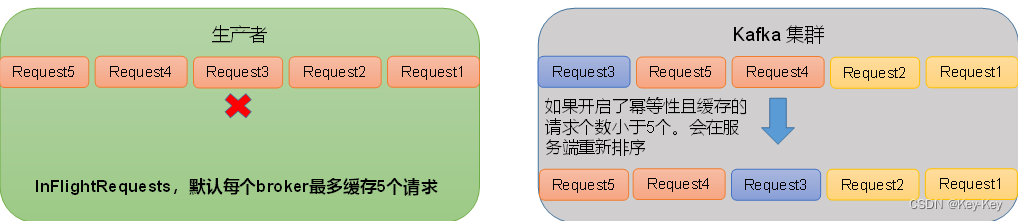
3.9生产经验-数据乱序
1、kafka在1.x版本之前保证单分区有序,条件如下:
max.in.flight.requests.per.connection=1(不需要考虑是否开启幂等性)
2、kafka在1.x及以后版本保证数据单分区有序,条件如下:
1)未开启幂等性
max.in.flight.requests.per.connection需要设置为1
2)开启幂等性
max.in.flight.requests.per.connection需要设置小于等于5
原因说明:因为在kafka1.x以后,启用幂等后,kafka服务器会缓存producer发来的最近5个request的元数据,故无论如何,都可以保证最近5个request的数据都是有序的。