目录
一、位图
1.1、引出位图
1.2、位图的概念
1.3、位图的应用
1.4、位图模拟实现
二、布隆过滤器
2.1、什么是布隆过滤器
2.2、布隆过滤器应用的场景
2.3、布隆过滤器的原理
2.4、布隆过滤器的查找
2.5、布隆过滤器的插入
2.6、布隆过滤器的删除
2.7、布隆过滤器的优缺点
2.8、布隆过滤器的模拟实现
一、位图
1.1、引出位图
我们在了解位图之前,前看一道题:
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中?
对于这道题,我们有两个思路:
1、内存内查找: 面对40亿个无符号整数,我们可以使用搜索树和哈希表,时间复杂度也就为O(n),因为搜索树不仅存储数据,还要存储颜色,parent,child指针等,哈希表还要存储迭代器,size等内置成员,进而导致内存存不下.
2、文件内查找:排序 + 二分查找,时间复杂度为0(log2),将40亿个数据保存在文件中,在进行排序。效率更低。。。
3、位图。unsigned int最大值是42亿多,而这里的40亿个数据都是不重复的,我们可以考虑使用一个32位的位图对这些数据映射(值是多少就映射在对应的位置,占用的内存不超过2G),将要查找的数据进行判断即可。
1.2、位图的概念
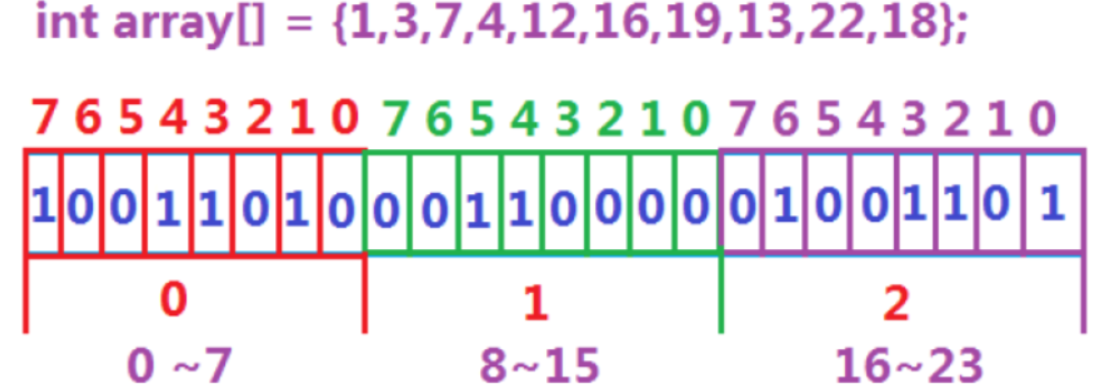

1.3、位图的应用
1 : 快速查找某个数据打是否在一个集合中.
2: 排序 + 去重 . ( 根据位图性质,哈希函数映射原理)
3: 求两个集合的交集,并集等.
4: 操作系统磁块标记.
1.4、位图模拟实现
#pragma once#include <vector>
#include <string>
#include <time.h>template<size_t N>
class bitset
{
public:bitset(){_bits.resize(N/8 + 1, 0);}void set(size_t x){size_t i = x / 8;size_t j = x % 8;_bits[i] |= (1 << j);}void reset(size_t x){size_t i = x / 8;size_t j = x % 8;_bits[i] &= ~(1 << j);}bool test(size_t x){size_t i = x / 8;size_t j = x % 8;return _bits[i] & (1 << j);}private:vector<char> _bits;
};void test_bitset1()
{bitset<100> bs;bs.set(10);bs.set(11);bs.set(15);cout << bs.test(10) << endl;cout << bs.test(15) << endl;bs.reset(10);cout << bs.test(10) << endl;cout << bs.test(15) << endl;bs.reset(10);bs.reset(15);cout << bs.test(10) << endl;cout << bs.test(15) << endl;
}void test_bitset2()
{//bitset<-1> bs1;bitset<0xFFFFFFFF> bs1;
}template<size_t N>
class twobitset
{
public:void set(size_t x){// 00 -> 01if (_bs1.test(x) == false&& _bs2.test(x) == false){_bs2.set(x);}else if (_bs1.test(x) == false&& _bs2.test(x) == true){// 01 -> 10_bs1.set(x);_bs2.reset(x);}// 10}void Print(){for (size_t i = 0; i < N; ++i){if (_bs2.test(i)){cout << i << endl;}}}public:bitset<N> _bs1;bitset<N> _bs2;
};二、布隆过滤器
2.1、什么是布隆过滤器

2.2、布隆过滤器应用的场景
布隆过滤器可以告诉我们 “某样东西一定不存在或者可能存在”,也就是说布隆过滤器说这个数不存在则一定不存,布隆过滤器说这个数存在可能不存在(误判,后续会讲),**利用这个判断是否存在的特点可以做很多有趣的事情。
-
网络爬虫:在爬取网页时,可以使用布隆过滤器来过滤掉已经爬取过的网页,避免重复爬取。
-
垃圾邮件过滤:布隆过滤器可以用来判断一封邮件是否是垃圾邮件,从而进行过滤。
-
URL去重:在爬虫或者搜索引擎中,经常需要对URL进行去重操作,布隆过滤器可以高效地判断一个URL是否已经被处理过。
-
缓存穿透问题:布隆过滤器可以用来解决缓存穿透问题,即某个请求的数据不存在于缓存中,但是频繁地访问会导致缓存服务器压力过大。
-
数据库查询优化:在数据库查询中,可以使用布隆过滤器来过滤掉不存在于数据库中的数据,从而减少不必要的查询开销。
2.3、布隆过滤器的原理
数据结构:布隆过滤器它实际上是一个很长的二进制向量和一系列随机映射函数。
以Redis中的布隆过滤器实现为例,Redis中的布隆过滤器底层是一个大型位数组(二进制数组)+多个无偏hash函数。
一个大型位数组(二进制数组):

多个无偏hash函数:
无偏hash函数就是能把元素的hash值计算的比较均匀的hash函数,能使得计算后的元素下标比较均匀的映射到位数组中。
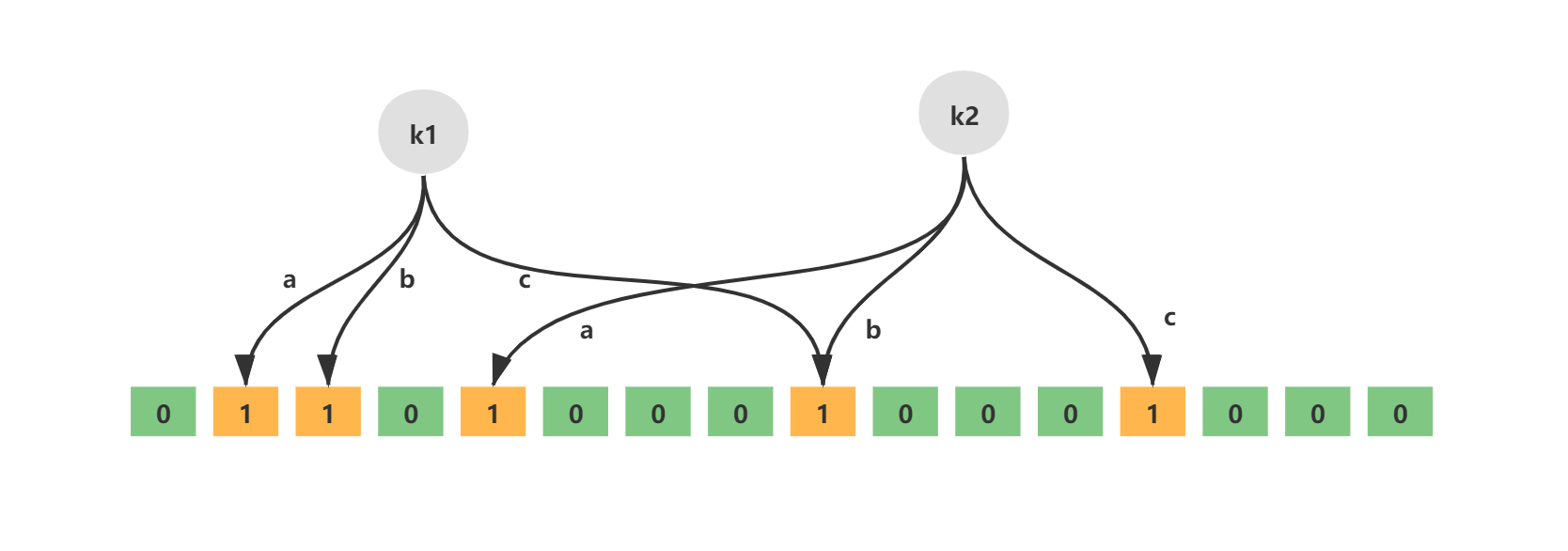
如下就是一个简单的布隆过滤器示意图,其中k1、k2代表增加的元素,a、b、c即为无偏hash函数,最下层则为二进制数组。
在布隆过滤器增加元素之前,首先需要初始化布隆过滤器的空间,也就是上面说的二进制数组,除此之外还需要计算无偏hash函数的个数。布隆过滤器提供了两个参数,分别是预计加入元素的大小n,运行的错误率f。布隆过滤器中有算法根据这两个参数会计算出二进制数组的大小l,以及无偏hash函数的个数k。
- 错误率越低,位数组越长,控件占用较大
- 错误率越低,无偏hash函数越多,计算耗时较长
2.4、布隆过滤器的查找
2.5、布隆过滤器的插入
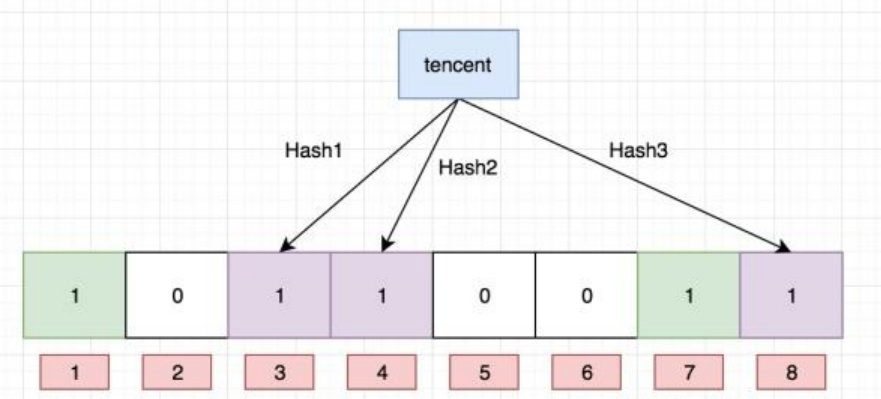
往布隆过滤器增加元素,添加的key需要根据k个无偏hash函数计算得到多个hash值,然后对数组长度进行取模得到数组下标的位置,然后将对应数组下标的位置的值置为1
- 通过k个无偏hash函数计算得到k个hash值
- 依次取模数组长度,得到数组索引
- 将计算得到的数组索引下标位置数据修改为1
例如:向布隆过滤器中插入:"baidu"

2.6、布隆过滤器的删除
2.7、布隆过滤器的优缺点
1、优点:
2.8、布隆过滤器的模拟实现
struct BKDRHash
{size_t operator()(const string& s){size_t hash = 0;for (auto ch : s){hash += ch;hash *= 31;}return hash;}
};struct APHash
{size_t operator()(const string& s){size_t hash = 0;for (long i = 0; i < s.size(); i++){size_t ch = s[i];if ((i & 1) == 0){hash ^= ((hash << 7) ^ ch ^ (hash >> 3));}else{hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));}}return hash;}
};struct DJBHash
{size_t operator()(const string& s){size_t hash = 5381;for (auto ch : s){hash += (hash << 5) + ch;}return hash;}
};// N最多会插入key数据的个数
template<size_t N,
class K = string,
class Hash1 = BKDRHash,
class Hash2 = APHash,
class Hash3 = DJBHash>
class BloomFilter
{
public:void set(const K& key){size_t len = N*_X;size_t hash1 = Hash1()(key) % len;_bs.set(hash1);size_t hash2 = Hash2()(key) % len;_bs.set(hash2);size_t hash3 = Hash3()(key) % len;_bs.set(hash3);//cout << hash1 << " " << hash2 << " " << hash3 << " " << endl << endl;}bool test(const K& key){size_t len = N*_X;size_t hash1 = Hash1()(key) % len;if (!_bs.test(hash1)){return false;}size_t hash2 = Hash2()(key) % len;if (!_bs.test(hash2)){return false;}size_t hash3 = Hash3()(key) % len;if (!_bs.test(hash3)){return false;}// 在 不准确的,存在误判// 不在 准确的return true;}
private:static const size_t _X = 6;bitset<N*_X> _bs;
};