文章目录
- Hardware-Aware-Transformers开源项目笔记
- 开源项目
- 背景知识
- nas
- 进化算法
- 进化算法代码示例
- 开源项目Evolutionary Search
- 1 生成延迟的数据集
- 2 训练延迟预测器
- 3 使延时约束运行搜索算法
- 4. 训练搜索得到的subTransformer
- 5. 根据重训练后的submodel 得到BLEU精度值
- 代码结构分析
Hardware-Aware-Transformers开源项目笔记
开源项目
本文是基于论文《HAT: Hardware-Aware Transformers for Efficient Natural Language Processing》同步开源的项目整理的,如需更详细的内容,请移步至项目https://github.com/mit-han-lab/hardware-aware-transformers
背景知识
nas
Neural Architecture Search,神经网络结构搜索。
-
定义搜索空间;
-
执行搜索策略采样网络
基于强化学习的方法
基于进化算法的方法
种群:针对当前问题的候选解集合
母种群
重组(
Crossover):交叉重组,两父代个体随机匹配并将部分结构加以替换重组形成新个体。 突变种群(
Mutation):变异,以一定的概率对子代进行变异,引入新的基因。 突变率
基于梯度的方法
-
对采样的网络进行性能评估
进化算法
对网络结构进行编码,维护结构的集合(种群),
从种群中挑选结构训练并评估,留下高性能网络而淘汰低性能网络。
接下来通过预设定的结构变异操作形成新的候选,通过训练和评估后加入种群中,
迭代该过程直到满足终止条件(如达到最大迭代次数或变异后的网络性能不再上升)
进化算法代码示例
1.问题表示;
2.评估函数;
3.种群;
4.父代选择机制;
5.变异操作算子,包括重组和突变;
6.生存选择机制。
将loss作为优化目标。
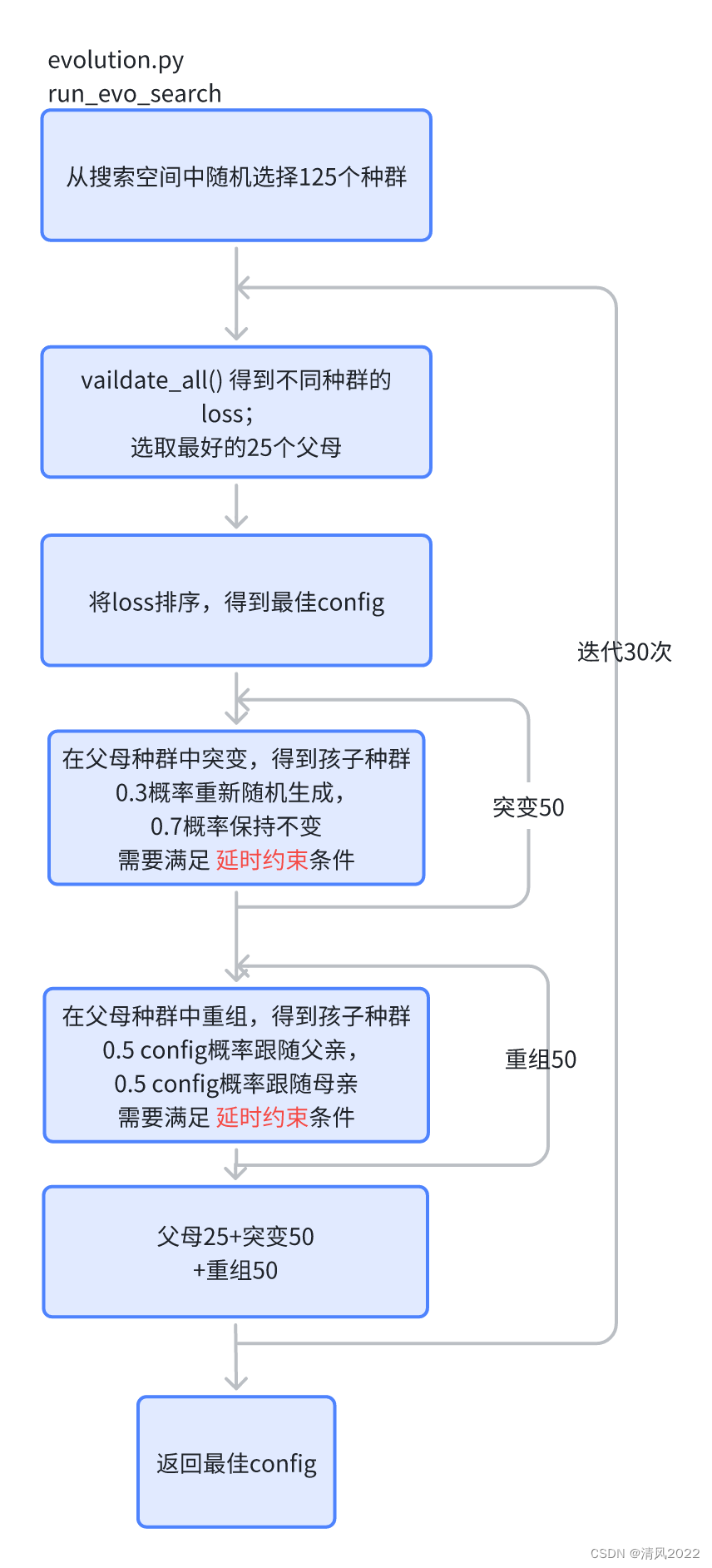
搜索算法如下所示:
注意搜索子网络的过程中没有训练

进化搜索参数
种群大小 125,母种群大小 25,重组 (Crossover) 种群大小 50,突变 (Mutation) 种群大小 50,0.3 突变几率。
每个硬件提供了2000个样本,按照8:1:1的方法划分数据集, 训练了一个三层的MLP。Latency Predictor只用在搜索过程中,在最后实验的时候还是用的真实测得的Latency。
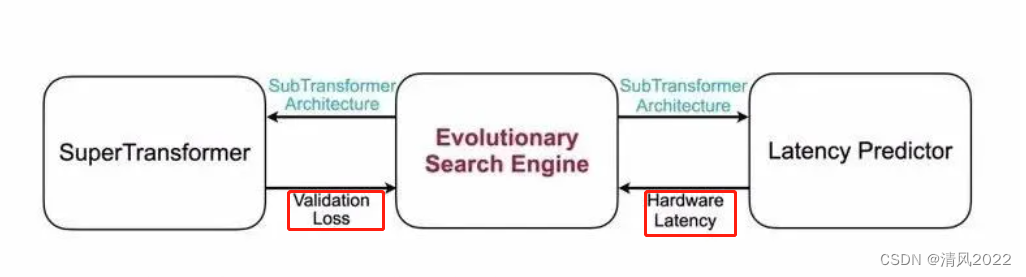
开源项目Evolutionary Search
https://github.com/mit-han-lab/hardware-aware-transformers
训练好的SuperTransformer中进行进化搜索,并在搜索循环中增加硬件延迟约束。我们训练一个延迟预测器,以快速获得准确的延迟反馈。
1 生成延迟的数据集
python latency_dataset.py --configs=configs/[task_name]/latency_dataset/[hardware_name].yml
# for example
python latency_dataset.py --configs=configs/wmt14.en-de/latency_dataset/cpu_raspberrypi.yml
hardware_name 可以是 cpu_raspberrypi,cpu_xeon and gpu_titanxp.
--configs 文件为设计空间,在其中对模型进行采样以获得(model_architecture, real_latency)数据对。
--configs 文件示例如下
lat-dataset-path: ./latency_dataset/wmt14ende_gpu_titanxp.csv
lat-dataset-size: 2000
latgpu: True
latiter: 20 #循环20次获取硬件推理性能
latsilent: True
# below is the configs for the data point sampling space for the latency predictor# model
arch: transformersuper_wmt_en_de
share-all-embeddings: True
max-tokens: 4096
data: data/binary/wmt16_en_de# SuperTransformer configs
encoder-embed-dim: 640
decoder-embed-dim: 640
encoder-ffn-embed-dim: 3072
decoder-ffn-embed-dim: 3072
encoder-layers: 6
decoder-layers: 6
encoder-attention-heads: 8
decoder-attention-heads: 8qkv-dim: 512
# SubTransformers search space
encoder-embed-choice: [640, 512]
decoder-embed-choice: [640, 512]encoder-ffn-embed-dim-choice: [3072, 2048, 1024, 512]
decoder-ffn-embed-dim-choice: [3072, 2048, 1024, 512]encoder-layer-num-choice: [6]
decoder-layer-num-choice: [6, 5, 4, 3, 2, 1]encoder-self-attention-heads-choice: [8, 4, 2]
decoder-self-attention-heads-choice: [8, 4, 2]
decoder-ende-attention-heads-choice: [8, 4, 2]# for arbitrary encoder decoder attention. -1 means attending to last one encoder layer
# 1 means last two encoder layers, 2 means last three encoder layers
decoder-arbitrary-ende-attn-choice: [-1, 1, 2]latency_dataset目录中有该数据集示例,示例如下
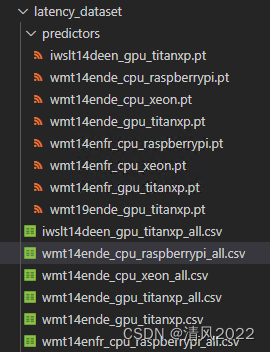
wmt14ende_gpu_titanxp_all.csv中 的数据内容如下,共2000条数据
encoder_embed_dim, #640
encoder_layer_num, #6
encoder_ffn_embed_dim_avg, #1962.666
encoder_self_attention_heads_avg, # 6.0
decoder_embed_dim, #512
decoder_layer_num, #4
decoder_ffn_embed_dim_avg, #1920.0
decoder_self_attention_heads_avg, #2.5
decoder_ende_attention_heads_avg, # 5.5
decoder_arbitrary_ende_attn_avg, #1.5latency_mean_encoder, # 5.495
latency_mean_decoder,# 124.549 训练时使用时间为(latency_mean_encoder+latency_mean_decoder)/lat-norm
latency_std_encoder, #0.0519
latency_std_decoder #0.4439#后4个参数来源np.mean(encoder_latencies), np.mean(decoder_latencies), np.std(encoder_latencies), np.std(decoder_latencies)
2 训练延迟预测器
使用上述收集的数据集训练一个预测器
python latency_predictor.py --configs=configs/[task_name]/latency_predictor/[hardware_name].yml
# for example
python latency_predictor.py --configs=configs/wmt14.en-de/latency_predictor/cpu_raspberrypi.yml --ckpt-path latency_dataset/ckpts/save.pt
–ckpt-path 保存预测器模型输出路径
--configs 文件中包含 预测器模型的结构和训练设置,内容示例如下:
lat-dataset-path: ./latency_dataset/wmt14ende_gpu_titanxp_all.csv #延时数据集
feature-norm: [640, 6, 2048, 6, 640, 6, 2048, 6, 6, 2]
lat-norm: 200 #训练时数据除以200,预测后再乘回来
feature-dim: 10
hidden-dim: 400
hidden-layer-num: 3
ckpt-path: ./latency_dataset/predictors/wmt14ende_gpu_titanxp.pt
train-steps: 5000
bsz: 128
lr: 1e-5
在latency_dataset/predictors 目录中我们提供了预训练的预测器;
延时预测器输入与1中数据集格式一致)是:
1. Encoder layer number,
2. Encoder Embedding dim,
3. Encoder hidden dim,
4. Encoder average self-attention heads,5. Decoder layer number,
6. Decoder Embedding dim,
7. Decoder hidden dim8. Decoder average self-attention heads,
9. average encoder-decoder attention heads,
10. average number of encoder: layers each decoder layer attends (每个decoder层关注的encoder层数量的均值)。
输出是:Predicted Latency。
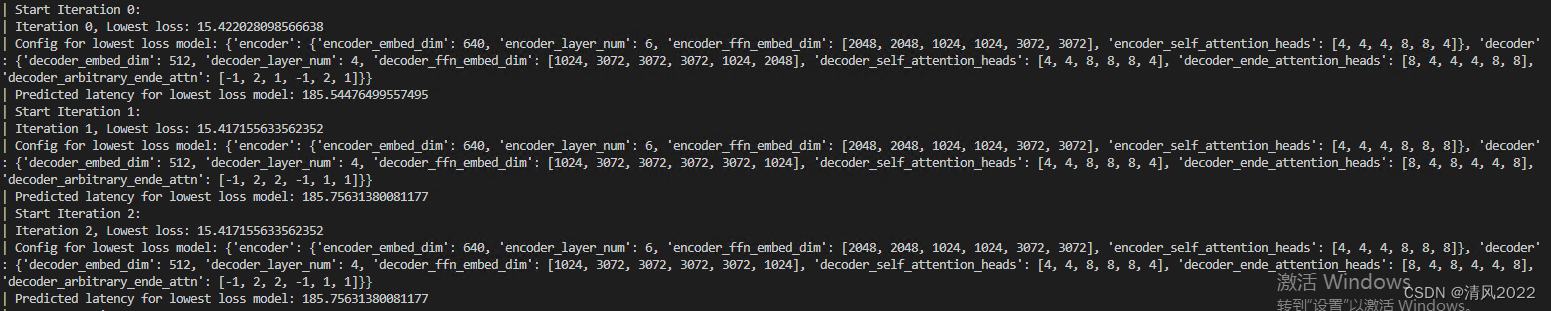
运行截图示例如下


3 使延时约束运行搜索算法
python evo_search.py --configs=[supertransformer_config_file].yml --evo-configs=[evo_settings].yml
# for example
python evo_search.py --configs=configs/wmt14.en-de/supertransformer/space0.yml --evo-configs=configs/wmt14.en-de/evo_search/wmt14ende_titanxp.yml
-
–write-config-path是输出路径,保存搜索的subtransformer 结构的结果路径;
-
–configs 是SuperTranformer训练配置文件,包括搜索空间配置等,示例如下
# model
arch: transformersuper_wmt_en_de
share-all-embeddings: True
max-tokens: 4096
data: data/binary/wmt16_en_de #数据集# training settings
optimizer: adam
adam-betas: (0.9, 0.98)
clip-norm: 0.0
weight-decay: 0.0
dropout: 0.3
attention-dropout: 0.1
criterion: label_smoothed_cross_entropy
label-smoothing: 0.1
ddp-backend: no_c10d
fp16: True
# warmup from warmup-init-lr to max-lr (warmup-updates steps); then cosine anneal to lr (max-update - warmup-updates steps)
update-freq: 16
max-update: 40000
warmup-updates: 10000
lr-scheduler: cosine
warmup-init-lr: 1e-7
max-lr: 0.001
lr: 1e-7
lr-shrink: 1
# logging
keep-last-epochs: 20
save-interval: 10
validate-interval: 10
# SuperTransformer configs
encoder-embed-dim: 640
decoder-embed-dim: 640
encoder-ffn-embed-dim: 3072
decoder-ffn-embed-dim: 3072
encoder-layers: 6
decoder-layers: 6
encoder-attention-heads: 8
decoder-attention-heads: 8
qkv-dim: 512
# SubTransformers search space
encoder-embed-choice: [640, 512]
decoder-embed-choice: [640, 512]
encoder-ffn-embed-dim-choice: [3072, 2048, 1024]
decoder-ffn-embed-dim-choice: [3072, 2048, 1024]
encoder-layer-num-choice: [6]
decoder-layer-num-choice: [6, 5, 4, 3, 2, 1]
encoder-self-attention-heads-choice: [8, 4]
decoder-self-attention-heads-choice: [8, 4]
decoder-ende-attention-heads-choice: [8, 4]
# for arbitrary encoder decoder attention. -1 means attending to last one encoder layer
# 1 means last two encoder layers, 2 means last three encoder layers
decoder-arbitrary-ende-attn-choice: [-1, 1, 2]
—evo-configs 包含进化搜索的设置 ,示例如下
#进化算法设置
evo-iter: 30
population-size: 125
parent-size: 25
mutation-size: 50
crossover-size: 50
mutation-prob: 0.3# 延时预测器模型路径
ckpt-path: ./latency_dataset/predictors/wmt14ende_gpu_titanxp.pt
# feature-norm should match with that when train the latency predictor
feature-norm: [640, 6, 2048, 6, 640, 6, 2048, 6, 6, 2]
# lat-norm should match with that when train the latency predictor
lat-norm: 200
# supertransformer 权重路径
restore-file: ./downloaded_models/HAT_wmt14ende_super_space0.pt# subtransformer配置路径
write-config-path: configs/wmt14.en-de/subtransformer/wmt14ende_titanxp@200ms.yml
# latency constraint
latency-constraint: 200
运行结构图示
4. 训练搜索得到的subTransformer
最后需要从头训练 SubTransformer
python train.py --configs=[subtransformer_architecture].yml --sub-configs=configs/[task_name]/subtransformer/common.yml
# for example
python train.py --configs=configs/wmt14.en-de/subtransformer/wmt14ende_titanxp@200ms.yml --sub-configs=configs/wmt14.en-de/subtransformer/common.yml
参数解释:
–configs 是步骤3中的 --write-config-path路径
–sub-configs 包含SubTransformer的训练设置

5. 根据重训练后的submodel 得到BLEU精度值

代码结构分析
latency_dataset.py
encoder 输入: src_tokens [1, 30]
decoder 输入
[5, 1] , 原因是num_beams=5
[5, 2]
[5, 3]
[5, 4]
[5, 5]
…
[5, 30]