Node.JS 中 Buffer 和 Stream 的区别
缓冲区和流
今天我将讨论缓冲区和流。当我开始使用 Node.JS 时,我很难掌握这些概念,所以我分享了围绕这些概念的学习,以帮助开发人员。
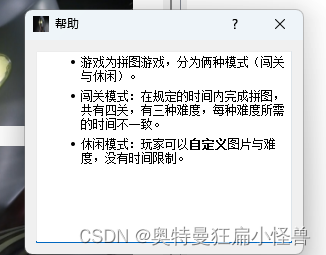
首先,让我用简单的术语解释什么是缓冲和流。
缓冲只是当我们播放视频时收集数据的动作。
流是从服务器向客户端发送数据。
首先,我们将讨论缓冲区。
缓冲区
当我们在 Node.JS 中读取文件时,它会分配与文件大小相等的内存,并将其存储在内存中。我们称这个内存空间为缓冲区。
如上例所示,Buffer.from() 用于将字符串、数组、缓冲区或 arrayBuffer 的值转换为缓冲区,toString() 用于将其转换回字符串。
我想强调缓冲区的一个主要问题。
- 如果在你的应用程序中,用户正在上传巨大的文件,如 50MB 或更多,那么服务器将很快过载,因为 50MB 的文件需要 50MB 的内存缓冲区。想象一下,如果 100 个用户同时上传,那么它将消耗 100 * 50 = 5000MB 内存。
- 在可以执行任何操作之前,用户必须等待整个数据加载到内存中
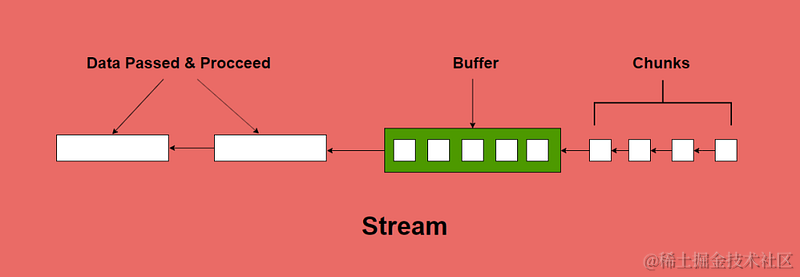
流
为了说明这一点,我将创建一个文件 test.txt,然后使用 createReadStream() 读取该文件。
1. 使用以下内容创建一个 test.txt 文件。

2. 该文件的大小为 29 字节
3. 在下面的代码中,我使用 createReadStream 来读取数据,其中有一个 highWaterMark 选项。该选项指定块缓冲区的大小。如您所见,数据正在分两块读取,然后在结束事件中打印出来。

流
使用流,我们可以逐块处理数据,不需要将整个数据保存在内存中。这就是为什么当我们需要处理大量数据时,推荐使用流。
希望现在您会对 Node.JS 中的 Buffer 和 Stream 有更好的理解。如果你喜欢这篇文章,请点赞和订阅。