mysql中的联合索引为什么要遵循最佳左前缀法则?
- 一、什么是联合索引
- 二、联合索引的优化
- 1.常规的写法(回表查询)
- 2.优化写法(索引覆盖)
- 三、 为什么要遵循最佳左前缀法则?
- 1.如下查询语句可以使用到索引:
- 2.如下查询条件也会使用索引:
- 3.如下查询条件只用到联合索引的一部分:
- 4.如下查询条件完全用不到索引
- 四、如何选择合适的联合索引
- 五、什么是索引覆盖?
- 1.索引覆盖可以带来很多的好处:
- 2.判断一条语句是否用到索引覆盖:
- 六、索引下推
- 不用索引下推的执行过程:
- 使用索引下推的执行过程:
一、什么是联合索引
联合索引(也叫组合索引、复合索引、多列索引),是一种特殊的索引类型,它由多个字段组成,而不是只针对单一字段进行索引。这种索引结构是一颗B+树,其特点是在对索引排序时,会对所有索引列进行排序,而非只是单列排序。因此,联合索引能够更有效地支持多条件的查询,尤其是当查询中使用了多个字段的条件时。
联合索引的创建方法跟单个索引的创建方法一样,不同之处仅在于有多个索引列
二、联合索引的优化
下面以查询表中以字母"L"开头的姓名及年龄为例。
1.常规的写法(回表查询)
SELECT name,age FROM `t_user` where name like 'l%' ;
这种写法,明显效率是低下的,我们用explain 分析一下:

由图中可以看出,分析后type的值为all,即在数据库中进行了全表扫描,效率是最低的。
2.优化写法(索引覆盖)
因为我们要查询name和age。所以,我们对name和age建立了联合索引,建立后的索引图如下:
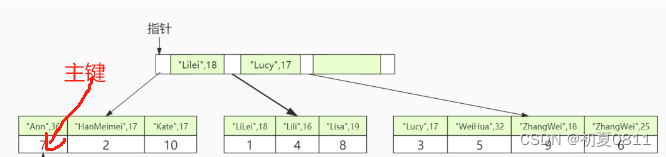
从图中我们可以看出,叶子节点中的键值都是按顺序存储的并且都包含了名字和年龄,即(“Ann”,36)、(“HanMeimei”,17)、(“Kate”,17)、(“LiLei”,18)、(“Lili”,16)、(“Lisa”,19)、(“Lucy”,17)、(“WeiHua”,32)、(“ZhangWei”,18)、(“ZhangWei”,25)。
索引会先根据 name 排序,如果 name 相同,再根据 age 进行排序。
我们对name和age建立索引后,当我们查询name和age二个字段时,直接会从索引中查出来而不需要回表查询,这种方式就是索引覆盖。执行步骤是这样的:
第一步:使用联合索引(name,age)查询以“l”开头的数据
第二步:在索引中取出name和age.
这种方式是不是高效多了,你要是还不信,我们用explain看一下,如下图:
EXPLAIN SELECT name,age FROM `t_user` where name like 'l%' ;

从图中我们看的出,使用了(name,age)索引。
三、 为什么要遵循最佳左前缀法则?
联合索引在使用的时候一定要注意顺序,一定要注意符合最左匹配原则。
最左匹配原则:在通过联合索引检索数据时,从索引中最左边的列开始,一直向右匹配,如果遇到范围查询(>、<、between、like等),就停止后边的匹配。
这个定义不太好理解,我解释一下:
假如对字段 (a, b, c) 建立联合索引,现在有这样一条查询语句:
select * from student
where a > xxx and b=yyy and c=zzz;select * from student
where a like 'xxx%' and b=yyy and c=zzz
在这个条件语句中,只有a用到了索引,后面的b,c就不会用到索引。这就是“如果遇到范围查询(>、<、between、like等),就停止后边的匹配。”的意思。
1.如下查询语句可以使用到索引:
where a = xxx
where a = xxx and b = xxx
where a = xxx and b = xxx and c = xxx
where a like 'xxx%'
where a > xxx
where a = xxx order by b
where a = xxx and b = xxx order by c
group by a
2.如下查询条件也会使用索引:
where b = xxx and a = xxx
where a = xxx and c = xxx and b = xxx
虽然b和a的顺序换了,但是mysql中的优化器会帮助我们调整顺序。
3.如下查询条件只用到联合索引的一部分:
where a = xxx and c = xxx 可以用到 a 列的索引,用不到 c 列索引。where a like 'xxx%' and b = xxx 可以用到 a 列的索引,用不到 b 列的索引。where a > xxx and b = xxx 可以用到 a 列的索引,用不到 b 列的索引。
4.如下查询条件完全用不到索引
where b = xxx
where c = xxx
where a like '%xxx' -- 不满足最左前缀
where d = xxx order by a -- 出现非排序使用到的索引列 d
where a + 1 = xxx -- 使用函数、运算表达式及类型隐式转换等
四、如何选择合适的联合索引
-
where a = xxx and b = xxx and c = xxx 如果我们的查询是这样的,建索引时,就可以考虑将选择性高的列放在索引的最前列,选择性低的放后边。
-
如果是 where a > xxx and b = xxx 或 where a like ‘xxx%’ and b = xxx 这样的语句,可以对 (b, a) 建立索引。
-
如果是 where a = xxx order by b 这样的语句,可以对 (a, b) 建立索引。
五、什么是索引覆盖?
我们对name和age建立索引后,当我们查询name和age二个字段时,直接会从索引中查出来而不需要回表查询,这种方式就是索引覆盖,例如以下sql查询就做不到索引覆盖,需要二次回表查询:
select name,age,address from student;
因为我们仅仅对name,age做了联合索引,在查询时根据联合索引查到了name,age字段以及对应的主键id,此时address字段需要通过id去回表查询,需要做二次查询,故效率会低一些。
由上面的介绍我们知道,建立了联合索引后,直接在索引中就可以得到查询结果,从而不需要回表查询聚簇索引中的行数据信息。
1.索引覆盖可以带来很多的好处:
-
辅助索引不包含行数据的所有信息,故其大小远小于聚簇索引,因此可以减少大量的IO操作。
-
索引覆盖只需要扫描一次索引树,不需要回表扫描聚簇索引树,所以性能比回表查询要高。
-
索引中列值是按顺序存储的,索引覆盖能避免范围查询回表带来的大量随机IO操作。
2.判断一条语句是否用到索引覆盖:
这个我们需要用explain查看一下。

Using index 就表示使用到了索引 , 并且所取的数据完全在索引中就能拿到,也就是用到了索引覆盖。
六、索引下推
索引下推是索引下推是 MySQL 5.6 及以上版本上推出的,用于对查询进行优化。
索引下推是把本应该在 server 层进行筛选的条件,下推到存储引擎层来进行筛选判断,这样能有效减少回表。
举例说明:
首先使用联合索引(name,age),现在有这样一个查询语句:
select * from t_user where name like 'L%' and age = 17;
这条语句从最左匹配原则上来说是不符合的,原因在于只有name用的索引,但是age并没有用到。
不用索引下推的执行过程:
第一步:利用索引找出name带'L'的数据行:LiLei、Lili、Lisa、Lucy 这四条索引数据
第二步:再根据这四条索引数据中的 id 值,逐一进行回表扫描,从聚簇索引中找到相应的行数据,将找到的行数据返回给 server 层。
第三步:在server层判断age = 17,进行筛选,最终只留下 Lucy 用户的数据信息。
使用索引下推的执行过程:
第一步:利用索引找出name带'L'的数据行:LiLei、Lili、Lisa、Lucy 这四条索引数据
第二步:根据 age = 17 这个条件,对四条索引数据进行判断筛选,最终只留下 Lucy 用户的数据信息。
(注意:这一步不是直接进行回表操作,而是根据 age = 17 这个条件,对四条索引数据进行判断筛选)
第三步:将符合条件的索引对应的 id 进行回表扫描,最终将找到的行数据返回给 server 层。
比较二者的第二步我们发现,索引下推的方式极大的减少了回表次数。
索引下推需要注意的情况:
下推的前提是索引中有 age 列信息,如果是其它条件,如 gender = 0,这个即使下推下来也没用
开启索引下推:
索引下推是 MySQL 5.6 及以上版本上推出的,用于对查询进行优化。默认情况下,索引下推处于启用状态。我们可以使用如下命令来开启或关闭。
set optimizer_switch='index_condition_pushdown=off'; -- 关闭索引下推
set optimizer_switch='index_condition_pushdown=on'; -- 开启索引下推