文章目录
- 前言
- 一、啥叫微调
- 二、为啥要微调
- 三、不是所有模型都可以微调的
- 四、总述微调的基本流程,以及涉及的主要函数,参数
- 1. 安装
- 2. 准备训练数据
- 3. openai.api_key = os.getenv() 进行一个说明
- 4. 通过API 调用模型 常用函数
- 5. 微调模型 常用函数
- 6. OpenAI CLI 开始微调
- --------------------------- 1. 创建微调模型---------------------------
- --------------------------- 2. 微调中断 恢复---------------------------
- --------------------------- 3. 微调中的其他操作---------------------------
- --------------------------- 4. 使用微调模型---------------------------
- --------------------------- 5. 删除微调模型---------------------------
前言
ChatGPT出来时间也不短了,最近听同事们说在面试时候,很多公司都会问,有没有微调GPT的经历,因此觉得,这东西需要掌握住,正好公司自己搭建的平台,api秘钥也是免费用,就趁着这个机会,好好琢磨下这个东西。
大致分为以下几步走:
第一:总述 微调 的基本流程
第二:微调用的数据
第三:微调的一些特殊用法
第四:实际例子分析
一、啥叫微调
微调是指在训练好的机器学习模型上进行进一步调整和优化,以提高其性能和适应特定任务或领域的能力。在微调过程中,我们通常会使用一个较小的数据集来重新训练模型,这个数据集包含与目标任务或领域相关的样本。通过微调,模型可以学习到更加具体和精确的特征,从而提升其在特定任务上的表现。微调是深度学习和迁移学习中常用的技术之一,可以使得模型更好地适应实际应用场景。
二、为啥要微调
用过GPT网页版的,或者通过api直接调用的,都知道,它有不错的通用能力,但是一到特别领域就不行。
但是但是,微调后就有这写好处:
-
个性化适应:通过微调,可以根据特定的需求和场景来训练ChatGPT,使其具有更加个性化、定制化的回答能力。可以引入特定领域的语料库或样本集,以便ChatGPT对该领域的问题和主题有更深入的了解。 -
消除偏见:微调可以帮助消除模型中可能存在的偏见。通过重新训练模型并提供多样化的数据,可以减少模型在回答问题时对某些群体或观点的偏见,从而提高模型的公平性和中立性。 -
控制输出:微调可以让更好地控制ChatGPT的输出内容。可以通过微调来约束模型生成的答案,确保其符合特定的要求,比如遵守特定的规则、避免敏感信息泄露等。 -
提高准确性:微调可以显著提高ChatGPT的准确性和质量。通过使用与目标任务相关的数据进行微调,模型可以更好地理解和回答相关问题,提供更准确的答案
并且通过微调可让从 API 提供的模型中获得更多收益:
- 比即时设计更高质量的结果
- 能够训练比提示中更多的例子
- 由于更短的提示而节省了代币
- 更低的延迟请求
GPT-3 已经在来自开放互联网的大量文本上进行了预训练。当给出仅包含几个示例的提示时,它通常可以凭直觉判断出您要执行的任务并生成合理的完成。这通常称为“小样本学习”。
微调通过训练比提示中更多的示例来改进小样本学习,让咱们在大量任务中取得更好的结果。对模型进行微调后,将不再需要在提示中提供示例。这样可以节省成本并实现更低延迟的请求。
总述就是,微调涉及以下步骤:
- 准备和上传训练数据
- 训练微调模型
- 使用微调模型
三、不是所有模型都可以微调的
微调目前仅适用于以下基础模型:davinci、curie、babbage和ada。这些是原始模型,在训练后没有任何说明(例如text-davinci-003)。还可以继续微调微调模型以添加其他数据,而无需从头开始。
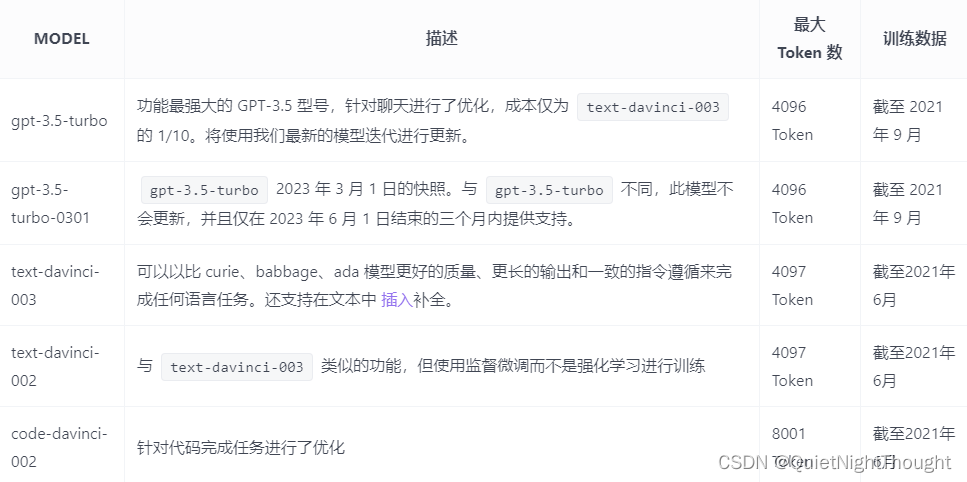
我只关注ChatGPT3.5系列:如图
四、总述微调的基本流程,以及涉及的主要函数,参数
1. 安装
这个是openai给的安装方法:
建议使用的 OpenAI 命令行界面 (CLI)。要安装这个,运行
pip install --upgrade openai
(以下说明适用于0.9.4及更高版本。此外,OpenAI CLI 需要 python 3。)
OPENAI_API_KEY通过将以下行添加到您的 shell 初始化脚本(例如 .bashrc、zshrc 等)或在微调命令之前的命令行中运行它来设置您的环境变量:
export OPENAI_API_KEY="<OPENAI_API_KEY>"
2. 准备训练数据
后面咱们专门说这个
3. openai.api_key = os.getenv() 进行一个说明
openai.api_key = os.getenv() 函数
import os
import openai# Load your API key from an environment variable or secret management service
openai.api_key = os.getenv("OPENAI_API_KEY")
这行代码的含义是将环境变量中存储的OpenAI API密钥赋值给openai.api_key变量。
这可以用于对OpenAI API进行身份验证,以便在使用API时向OpenAI发送请求。
os.getenv():是Python标准库os中的一个函数,它用于获取操作系统环境变量的值。
"OPENAI_API_KEY":是要获取的环境变量的名称,这里我们想要获取OpenAI的API密钥。
openai.api_key:是OpenAI提供的一个变量,用于存储API密钥。将os.getenv("OPENAI_API_KEY")的返回值赋值给它,
即可将API密钥保存在该变量中,方便后续使用。
4. 通过API 调用模型 常用函数
openai.Completion.create() 函数
response = openai.Completion.create(
model="text-davinci-003",
prompt="Say this is a test",
temperature=0,
max_tokens=7)
openai.Completion.create():是OpenAI提供的一个函数,用于创建文本生成的请求。
model="text-davinci-003":指定了使用的模型。在这个例子中,模型被命名为"text-davinci-003"。模型名称通常表明了它所擅长的任务和能力。
prompt="Say this is a test":是输入给模型的提示文本。在这个例子中,模型的生成将基于这个提示进行。
temperature=0:是控制文本生成的随机性的参数。较低的温度值(如0)会使生成结果更加确定性,较高的温度值(如1)会使生成结果更加随机。
max_tokens=7:指定了生成文本的最大长度。在这个例子中,生成的文本将不超过7个标记(tokens)。
通过调用openai.Completion.create()函数并传入相应的参数,可以向OpenAI API发送请求,并获得生成的文本结果。
5. 微调模型 常用函数
fine_tunes.create() 函数
fine_tunes.create: 这个函数用于创建一个微调任务。
主要参数:
-t <TRAIN_FILE_ID_OR_PATH>: 指定训练文件的标识符或路径,它包含了用于微调的数据集。
该参数,允许根据训练文件是本地存储还是上传到OpenAI API来指定文件的标识符或路径。
如果这个文件位于C:\path\to\train.txt,命令会是这样的:
-t C:\path\to\train.txt
另外,如果你已经将训练文件上传到了OpenAI API,并获得了一个文件标识符,你可以将这个标识符作为-t参数的值。
例如,如果文件标识符是file-abc123,命令会是这样的:
-t file-abc123
-m <BASE_MODEL>: 指定基础模型的选择,即预训练模型的名称或标识符。
-n <NUM_ITERATIONS>: 指定微调的迭代次数,即完成微调的总步骤数。
-b <BATCH_SIZE>: 指定每个微调步骤(iteration)的批量大小,即每次更新模型时一次处理的样本数量。
-e <EVALUATION_INTERVAL>: 指定模型在微调过程中进行评估的间隔,即多少个微调步骤后进行一次模型评估。
-s : 指定随机种子,以确保微调过程的可重复性。
-o <OUTPUT_DIR>: 指定输出目录,用于存储微调过程中生成的模型权重和其他相关文件。
通过使用这些参数,您可以指定微调所使用的训练数据、基础模型以及微调任务的其他相关参数。
执行fine_tunes.create函数后,OpenAI API将开始进行模型微调,并在指定的迭代次数内更新模型权重和优化参数,
最终生成一个经过个性化训练的模型。
openai.常用函数
openai.Completion.create(): 用于创建文本生成的请求。
openai.Davinci(models='davinci'): 用于选择Davinci模型。
openai.Gpt3(models='gpt-3.5-turbo'): 用于选择GPT-3.5 Turbo模型。
openai.ChatCompletion.create(): 用于创建对话式生成的请求。
openai.File.create(): 用于上传文件到OpenAI API中,并返回一个文件标识符。
openai.File.retrieve(): 用于从OpenAI API中检索已上传的文件。
6. OpenAI CLI 开始微调
--------------------------- 1. 创建微调模型---------------------------
使用 OpenAI CLI 开始微调工作:
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>'''
也可以给模型增加上名字最多 40 个字符的后缀'''
openai api fine_tunes.create -t test.jsonl -m ada --suffix "custom model name"结果名称将是:
ada:ft-your-org:custom-model-name-2022-02-15-04-21-04
执行这行代码后,开始执行下面的操作…
- 使用文件 API上传文件(或使用已经上传的文件)
- 创建微调作业
- 流式传输事件直到作业完成(这通常需要几分钟,但如果队列中有很多作业或您的数据集很大,则可能需要数小时)
注意:
成功创建微调任务后,
API将返回一个响应包含有关微调的信息,其中包括相应的模型ID。您可以从API响应中提取该模型ID,这个后面会需要使用
--------------------------- 2. 微调中断 恢复---------------------------
使用这行代码就行恢复…
openai api fine_tunes.follow -i <YOUR_FINE_TUNE_JOB_ID>
fine_tunes.follow: 这个函数用于跟踪模型微调任务的状态和进展。
主要参数:
-i <YOUR_FINE_TUNE_JOB_ID>: 指定模型微调任务的标识符,即您的微调的唯一ID。
通过使用fine_tunes.follow函数并提供相应的微调ID,您可以获取有关模型微调过程的实时状态更新。
这些状态更新可能包括每个迭代步骤的训练损失、验证指标、当前轮次等信息。通过跟踪微调任务的状态,
您可以了解模型微调的进展情况,并根据需要进行必要的监控和后续操作。
!!!请注意!!!,上述参数是一个示例,需要将<YOUR_FINE_TUNE_JOB_ID>替换为实际的模型微调作业ID。这个作业ID通常是在启动微调任务时由OpenAI API返回的。
--------------------------- 3. 微调中的其他操作---------------------------
除了创建微调,恢复微调外,还可以 列出现有微调、检索微调状态 或 取消微调。
列出现有微调(有点类似 pip list) # List all created fine-tunes
openai api fine_tunes.list
检索微调# Retrieve the state of a fine-tune. The resulting object includes
# job status (which can be one of pending, running, succeeded, or failed)
# and other information
openai api fine_tunes.get -i <YOUR_FINE_TUNE_JOB_ID>
取消微调任务# Cancel a job
openai api fine_tunes.cancel -i <YOUR_FINE_TUNE_JOB_ID>
看到了吧,这里的 工作ID 其实就是上面创建微调模型的时候 返回的 ID
--------------------------- 4. 使用微调模型---------------------------
方式一:OpenAI 命令行界面:
openai api completions.create -m <FINE_TUNED_MODEL> -p <YOUR_PROMPT>
方式二:Python:
import openai
openai.Completion.create(model=FINE_TUNED_MODEL,prompt=YOUR_PROMPT)'''
这个函数上面有详细解释
'''
如果您使用了OpenAI API中的fine_tunes.create函数进行微调,则在成功创建微调任务后,
API将返回一个响应包含有关微调作业的信息,其中包括相应的模型ID。您可以从API响应中提取该模型ID,
并将其用作<FINE_TUNED_MODEL>参数的值。
--------------------------- 5. 删除微调模型---------------------------
方式一:OpenAI 命令行界面:
openai api models.delete -i <FINE_TUNED_MODEL>
方式二:Python:
import openai
openai.Model.delete(FINE_TUNED_MODEL)