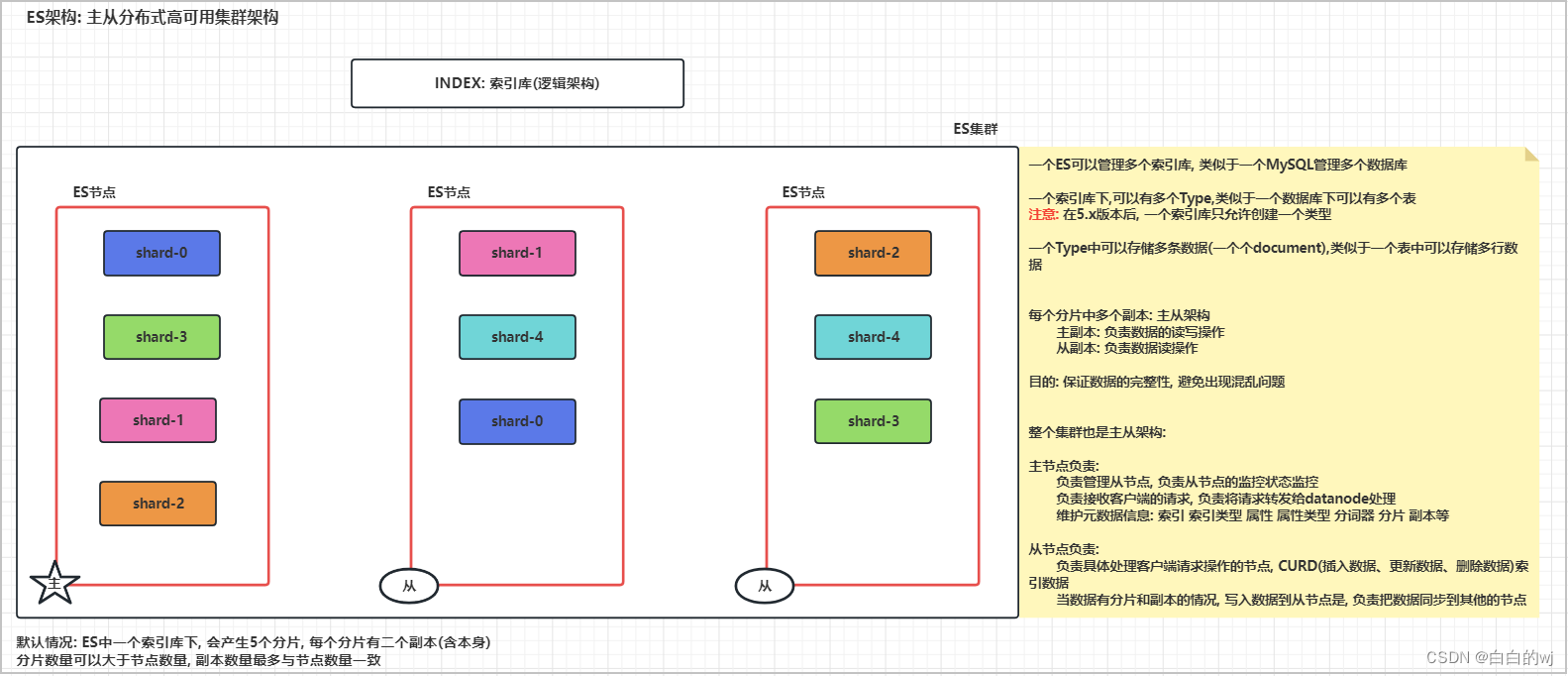
XPath
xpath介绍
是一门在XML文档中查找信息的语言
html文档准备
doc='''
<html><head><base href='http://example.com/' /><title>Example website</title></head><body><div id='images'><a href='image1.html' aa='bb'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a><a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a><a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a><a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a><a href='image5.html' class='li li-item' name='items'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a><a href='image6.html' name='items'><span><h5>test</h5></span>Name: My image 6 <br /><img src='image6_thumb.jpg' /></a></div></body>
</html>
'''
xpath选择器使用
from lxml import etreehtml=etree.HTML(doc)
html=etree.parse('search.html',etree.HTMLParser())
1 所有节点
a=html.xpath('//*')2 指定节点(结果为列表)
a=html.xpath('//head')3 子节点,子孙节点
a=html.xpath('//div/a')
a=html.xpath('//body/a') #无数据
a=html.xpath('//body//a')4 父节点
a=html.xpath('//body//a[@href="image1.html"]/..')
a=html.xpath('//body//a[1]/..')
也可以这样
a=html.xpath('//body//a[1]/parent::*')5 属性匹配
a=html.xpath('//body//a[@href="image1.html"]')6 文本获取(重要) /text() 取当前标签的文本
a=html.xpath('//body//a[@href="image1.html"]/text()')
a=html.xpath('//body//a/text()')7 属性获取 @href 取当前标签的属性
a=html.xpath('//body//a/@href')# 注意从1 开始取(不是从0)
a=html.xpath('//body//a[1]/@href')8 属性多值匹配
a 标签有多个class类,直接匹配就不可以了,需要用contains
a=html.xpath('//body//a[@class="li"]') # 标签有且只有一个时才能找到,否则None
a=html.xpath('//body//a[contains(@class,"li")]') # 只要包含就可以
a=html.xpath('//body//a[contains(@class,"li")]/text()')9 多属性匹配
a=html.xpath('//body//a[contains(@class,"li") or @name="items"]')
a=html.xpath('//body//a[contains(@class,"li") and @name="items"]/text()')
a=html.xpath('//body//a[contains(@class,"li")]/text()')10 按序选择
a=html.xpath('//a[2]/text()')
a=html.xpath('//a[2]/@href')
取最后一个
a=html.xpath('//a[last()]/@href')
位置小于3的
a=html.xpath('//a[position()<3]/@href')
倒数第二个
a=html.xpath('//a[last()-2]/@href')11 节点轴选择
ancestor:祖先节点
使用了* 获取所有祖先节点
a=html.xpath('//a/ancestor::*')
# 获取祖先节点中的div
a=html.xpath('//a/ancestor::div')
attribute:属性值
a=html.xpath('//a[1]/attribute::*')
a=html.xpath('//a[1]/@aa')
child:直接子节点
a=html.xpath('//a[1]/child::*')
a=html.xpath('//a[1]/child::img/@src')
descendant:所有子孙节点
a=html.xpath('//a[6]/descendant::*')
a=html.xpath('//a[6]/descendant::h5/text()')
following:当前节点之后所有节点(兄弟节点和兄弟内部的节点)
a=html.xpath('//a[1]/following::*')
a=html.xpath('//a[1]/following::*[1]/@href')
following-sibling:当前节点之后同级节点(只找兄弟)
a=html.xpath('//a[1]/following-sibling::*')
a=html.xpath('//a[1]/following-sibling::a')
a=html.xpath('//a[1]/following-sibling::*[2]')
a=html.xpath('//a[1]/following-sibling::*[2]/@href')
Xpath重点总结
1. //:代表从整篇文档中寻找例如://body,代表在整篇文档中寻找所有的body标签 2. /:代表从当前节点中寻找例如://body/a,在所有的body标签下寻找a标签 3. /@属性名:获取当前标签的属性例如://div/a/@href,在所有的div标签下寻找a标签得到a标签的href属性值 4. /text():获取当前标签的文本例如://body//a[@href="image1.html"]/text(),在所有的body标签下寻找href属性是image1.html的a标签的文本
以后查找标签有三种方式
- bs4的find系列(find & find_all)
- css选择器
- xpath选择器
selenium工具
介绍
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
安装
pip install selenium
使用
下载浏览器驱动
selenium工具在使用的时候需要借助浏览器驱动
浏览器驱动下载:npm.taobao.org/mirrors/chr…
驱动要和浏览器版本对应:
根据不同的操作系统下载不同的文件,解压之后就是不同平台的可执行文件

selenium工具使用
- 基本使用
from selenium import webdriver
import time# 首先得到一个谷歌浏览器对象,并指定使用浏览器驱动(这里我的驱动放在与执行文件相同的文件夹下)
browser = webdriver.Chrome(executable_path='./chromedriver.exe')
time.sleep(2)# 相当于在地址栏中输入百度
browser.get('https://www.baidu.com/')
time.sleep(2)print(browser.page_source) # page_source包括js的前端源码
time.sleep(2)# 关闭浏览器:用完之后一定要关闭,如果不关闭的话,不断地开新的程序就会不断地开启谷歌浏览器的进程,导致内存被撑爆,而且谷歌浏览器的每个标签页都是开启一个进程
browser.close()
- 模拟登陆百度
from selenium import webdriver
import time# 1.得到谷歌浏览器对象
browser = webdriver.Chrome(executable_path='./chromedriver.exe')
# 2.在地址栏中输入百度的网址
browser.get('https://www.baidu.com/')
time.sleep(0.1)
# 3.获取输入框,通过id获取输入框表标签对象
input_k = browser.find_element_by_id('kw')
# 4.在输入框中写入'蜡笔小新',可以直接模拟键盘的回车键
input_k.send_keys('蜡笔小新')
# 模拟键盘输入
# from selenium.webdriver.common.keys import Keys
# input_k.send_keys(Keys.ENTER) # 如果模拟键盘的回车键,后续就不需要点击搜索按钮time.sleep(2)
# 5.找到搜索按钮
button = browser.find_element_by_id('su')
# 6.点击搜索按钮,或者模拟键盘的回车键
button.click()
time.sleep(10)
# 关闭浏览器
browser.close()
等待页面元素被加载
有时候在使用selenium工具的时候,由于等待时间非常短页面中的组件还未加载完毕,可能会出现报错的情况,因此可以设置一个等待页面元素加载的时间。
页面元素加载等待分为隐式等待和显式等待
- 隐式等待(推荐使用)
bro=webdriver.Chrome(executable_path='./chromedriver.exe')
# 隐式等待:需要写在get('url')之前,针对所有元素,找一个空间,如果没有加载出来就等待5s
bro.implicitly_wait(5)
bro.get('https://www.baidu.com/')
- 显式等待
加载每个控件都需要手动睡几秒(time.sleep(5)),不方便,不推荐使用
选择器
1、find_element_by_id # 通过id查找控件
2、find_element_by_link_text # 通过a标签内容找
3、find_element_by_partial_link_text # 通过a标签内容找,模糊匹配
4、find_element_by_tag_name # 标签名
5、find_element_by_class_name # 类名
6、find_element_by_name # name属性
7、find_element_by_css_selector # 通过css选择器
8、find_element_by_xpath # 通过xpaht选择器
========================强调==============================
9、find_elements_by_xxx的形式是查找到多个元素,结果为列表
获取标签属性
- 重要
tag.get_attribute('href') # 找当前控件 的href属性对的值
tag.text # 获取文本内容
- 了解
print(tag.id) # 当前控件id号
print(tag.location) # 当前控件在页面位置
print(tag.tag_name) # 标签名
print(tag.size) #标签的大小
浏览器有无界面
- 有界面浏览器
参考上面模拟在百度搜素蜡笔小新
- 无界面浏览器
谷歌浏览器支持不打开页面
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
chrome_options = Options()
chrome_options.add_argument('window-size=1920x3000') #指定浏览器分辨率
chrome_options.add_argument('--disable-gpu') #谷歌文档提到需要加上这个属性来规避bug
chrome_options.add_argument('--hide-scrollbars') #隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 提升速度chrome_options.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败bro=webdriver.Chrome(chrome_options=chrome_options,executable_path='./chromedriver.exe')
bro.get('https://www.baidu.com/')
print(bro.page_source)
bro.close()
元素交互
tag.send_keys() # 往里面写内容
tag.click() # 点击控件
tag.clear() # 清空控件内容
执行js
try:browser=webdriver.Chrome()browser.get('https://www.baidu.com')browser.execute_script('alert("hello world")') #打印警告
finally:browser.close()# 如何把屏幕拉到最后(js控制)
bro.execute_script('window.scrollTo(0,document.body.offsetHeight)')
模拟浏览器的前进后退
import time
from selenium import webdriverbrowser=webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.get('https://www.taobao.com')
browser.get('http://www.sina.com.cn/')browser.back()
time.sleep(10)
browser.forward()
browser.close()
模拟键盘输入
# 模拟键盘输入
from selenium.webdriver.common.keys import Keys
input_k.send_keys('小新')
# 模拟键盘的回车键
input_k.send_keys(Keys.ENTER)
获取cookie
from selenium import webdriverbrowser=webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')# 获取所有cookies
print(browser.get_cookies())# 获取指定cookie
print(browser.get_cookie(name))# 增加cookie
browser.add_cookie({'k1':'xxx','k2':'yyy'})
print(browser.get_cookies())
异常处理
from selenium import webdriver
from selenium.common.exceptions import TimeoutException,NoSuchElementException,NoSuchFrameException
browser=webdriver.Chrome()
try:browser.get('')
except Exception as e:print(e)
finally:# 无论是否出异常,最终都要关掉browser.close()
动作链
动作链就是一连串动作,即鼠标执行的一系列动作。
用selenium做自动化,有时候会遇到需要模拟鼠标操作才能进行的情况,比如单击、双击、点击鼠标右键、拖拽等等。而selenium给我们提供了一个类来处理这类事件——ActionChains
"""
# 核心方法
ActionChains(driver).click_and_hold(sourse)
ActionChains(driver).move_by_offset :移动x轴和y轴的拒绝
ActionChains(driver).move_to_element() :直接移动到某个控件是上
ActionChains(driver).move_to_element_with_offset() #移动到某个控件的某个位置
ActionChains(driver).release()
# 所有的动作最后都要执行perform(),真正的去执行
"""# 示例:http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable
from selenium import webdriver
from selenium.webdriver import ActionChains
import timedriver = webdriver.Chrome(executable_path='./chromedriver.exe')
driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
driver.implicitly_wait(3) # 使用隐式等待try:driver.switch_to.frame('iframeResult') ##切换到iframeResultsourse=driver.find_element_by_id('draggable')target=driver.find_element_by_id('droppable')ActionChains(driver).click_and_hold(sourse).perform()distance=target.location['x']-sourse.location['x']track=0while track < distance:ActionChains(driver).move_by_offset(xoffset=20,yoffset=0).perform()track+=20# 释放动作链ActionChains(driver).release().perform()time.sleep(10)finally:driver.close()
选项卡
切换选项卡,有js的方式windows.open,有windows快捷键:ctrl+t等,最通用的就是js的方式import time
from selenium import webdriverbrowser=webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')print(browser.window_handles) #获取所有的选项卡
browser.switch_to_window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(10)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://www.sina.com.cn')
browser.close()
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!