目录
ES和数据库的类比
ELK集中日志协议栈介绍
ES的介绍
ES的架构
ES中的名词
ES中的角色
分片与副本的区别在于:
MYSQL分库与分表:
倒排序索引:
ES写入数据原理:
ES读取、检索数据原理:
重点: ES 的架构 , ES读写的原理
ES和数据库的类比
| 关系型数据库 | 非关系型数据库 |
| 数据库Database | 索引Index |
| 表Table | 类型Type |
| 数据行Row | 文档Document |
| 数据列Column | 字段Field |
| 约束Schema | 映射Mapping |
ELK集中日志协议栈介绍
ELK是Elasticserarch、Logstash 、Kibana三个开源项目的首字母缩写
Elasticsearch:主要是用于做全文检索 , 功能是数据的存储和查询。
Logstash: 主要是用于进行数据的传递采集工作,将数据搬运到另一个地方。
Kibana:用于图表展示,类似BI。
ES的介绍
Elasticsearch是一个分布式的全文搜索引擎,具有高性能、可扩展性和数据可靠性等特点。
它使用Lucene作为底层引擎,支持快速地存储、搜索和分析大量的数据。
选择ES的原因:
1- 目前ES和大数据生态圈都能很好的稳定结合在一起,技术相对比较成熟。
2- 业务标签数据需要经常进行插入和更新,ES支持海量数据的存储插入和更新,更适合当前项目特点。
3- 未来,后续我们会建设标签体系检索平台,基于平台更好的进行用户群体分类检索工作,ES就是建设搜索系统最好的工具,所以选择ES。
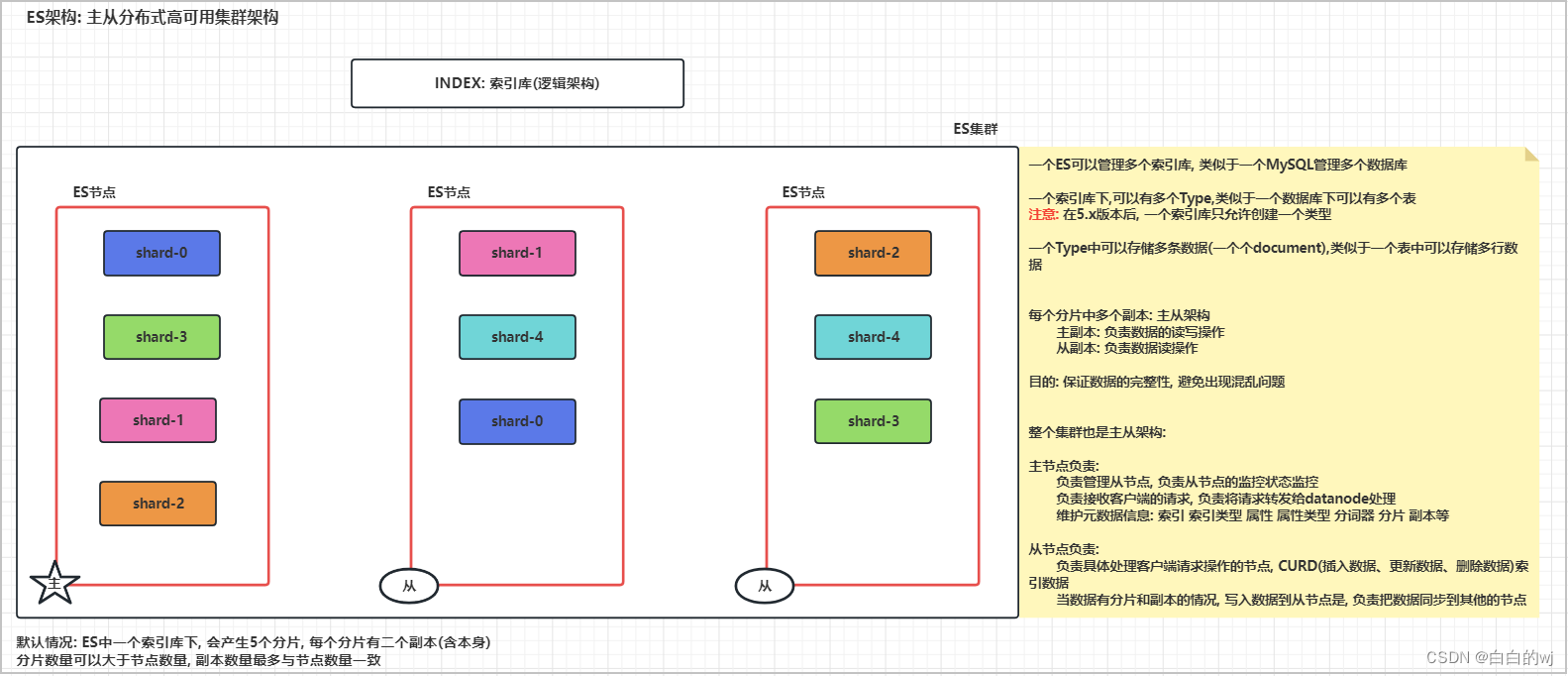
ES的架构
ES具备两套主从结构:节点主从(Master和DataNode)分片主从(PrimaryShard和ReplicaShard)
ES中的名词
index: 索引库,一个es下可以有多个索引库。
setting: 主要对索引库和副本的设置,默认有5分片 和 2副本。
type: 在一个索引库下,可以有多个类型,类似数据库中可以有多个表。
注意: 目前新的版本中, 已经只允许创建一个type(_doc)
filed:字段,从一个type下可以有多个字段,类似表中的列。
mapping: 映射关系,主要是对字段进行相关的设置。
docment:文档,表示每一行的数据。
cluster: es的集群。
node: es中的节点。
shard: 分片,一个索引库中有5个。
replcas: 副本 默认每一个分片 都有一个副本,加上本身就是2个。
Index索引创建完成以后,可以任意时间动态修改副本的数量;但是不能修改分片的数量
如果后续数量增大了,分片数量不够了如何解决?
1- 先创建一个具有更多分片的新Index索引库
2- 后续的新数据写入到这个新的Index索引库
3- 旧的Index索引库数据导入到新的Index索引库
ES中的角色
Master: 主节点
作用:
负责管理从节点, 负责从节点的监控状态监控
负责接收客户端的请求, 负责将请求转发给datanode处理
维护元数据信息: 索引 索引类型 属性 属性类型 分词器 分片 副本等
注意:
1- 集群架构可以分成分布式和单机版。单机版的时候,该节点既是主节点也是从节点
2- 当是分布式的时候,主节点是一个轻量级的节点,尽可能不会去存储数据,即使存储也只存放从副本,只负责数据的读DataNode: 从节点
作用:
负责具体处理客户端请求操作的节点, CURD(插入数据、更新数据、删除数据)索引数据
当数据有分片和副本的情况, 写入数据到从节点时, 负责把数据同步到其他的节点
注意: 数据写入请求,会被发送到从节点,先写入到从节点中的主副本,再从主副本同步到其他从副本。也就是从节点上可能有主副本,也可能有从副本。
分片与副本的区别在于:
当分片设置为5,数据量为30时,ES就会自动帮用户把数据均衡的分配到5个分片上,每个分片大概有6g数据\
当你查询数据时,ES会把查询发送给每个相关的分片,并将结果组合在一起。
而副本,就是对分布在5个分片的数据进行复制。因为分片是把数据进行分割而已,数据依然只有一份\
这样的目的是保障数据的高可靠性,完整性.
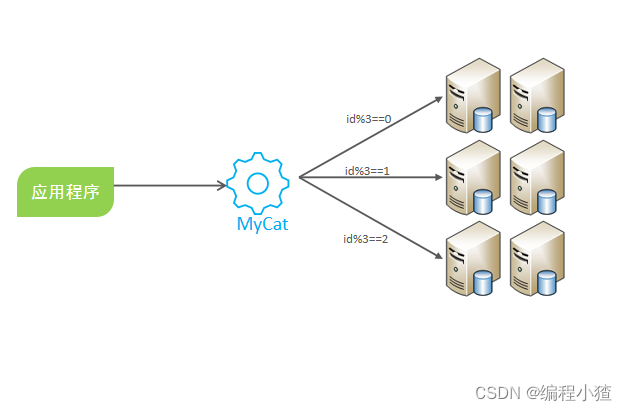
MYSQL分库与分表:
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。分库分表包括分库和分表两个部分,在生产中通常包括:垂直分库、水平分库、垂直分表、水平分表四种方式。(大库拆成小库,大表拆成小表)
倒排序索引:
全文检索就是通过词找到索引,查询到文本内容;
倒排索引就是根据单词快速获取包含这个单词的文档列表。
1- 当用户输入关键字后,将关键字分词。
2- 构建索引库,第一列是分词后的具体的词语,第二列是词语的ID列表。
3- 到索引库中根据分词后的数据,寻找相关列表信息,然后找到对应的内容。
ES写入数据原理:
1- 客户端进行数据写入操作,随机连接一台节点,连接的那台就会成为coordinating node协调者,并且也是该请求的管理者。
2- 协调节点计算当前写入的数据要存储到哪个分片的主副本上,底层是基于文档ID的哈希取模方案。
3- 计算完成后,找到分片的主副本,如果就在当前节点那么就直接写入、
如果不在当前节点,就将请求转发给到对应的分片主副本所在的节点。
4- 对应节点的主副本接收到请求后,执行写入操作,写入成功后将数据同步到其他副本中。
(注:写入的操作只有主副本拥有,从副本只有读取功能,这样的作用是为了避免数据混乱)
5- 当主副本和从副本都对数据同步完成后,最终将写入成功的请求由协调节点返回给客户端。
ES读取、检索数据原理:
1- client发起查询请求,连接到任意一台ES节点上,谁被连上谁就成为协调者,并成为此次请求的管理者。
2- 查询的方案:
2.1- 如果是基于文档ID查询,此时会计算当前这个ID的数据存放在哪个分片上,接着将请求转发给对应的分片的副本.
2.2- 如果不是基于文档ID查询,例如通过文本内容关键字查询,此时需要将查询请求广播给所有的节点,由各个节点查询自己服务器上的数据,并且将查询到的结果汇聚到协调节点.
3- 由协调节点负责汇总数据,并且对数据进行排序操作,是全局降序排序.
4- 最后将结果返回给客户端.