系列文章目录
第一章 TensorRT优化部署(一)–TensorRT和ONNX基础
第二章 TensorRT优化部署(二)–剖析ONNX架构
第三章 TensorRT优化部署(三)–ONNX注册算子
第四章 TensorRT模型优化部署(四)–Roofline model
第五章 TensorRT模型优化部署(五)–模型优化部署重点注意
第六章 TensorRT模型优化部署(六)–Quantization量化基础(一)
第七章 TensorRT模型优化部署(七)–Quantization量化(PTQ and QAT)(二)
第八章 TensorRT模型优化部署 (八)–模型剪枝Pruning
文章目录
- 系列文章目录
- 前言
- 一、模型剪枝是什么?
- 二、模型剪枝流程
- 2.1 对模型进行剪枝
- 2.2 对剪枝后的模型进行fine-tuning
- 2.3 获取到一个压缩的模型
- 2.4 模型剪枝和量化
- 三、模型剪枝的分类
- 3.1 Coarse Grain Pruning (粗粒度剪枝)
- 3.1 Fine Grain Pruning(细粒度剪枝)
- 四、channel-level pruning
- 4.1 L1 & L2 regularization
- 4.2 BN中的scaling factor
- 五、Pruning和fine-tuning
- 总结
前言
自学视频笔记,专题内容后续有补充。
一、模型剪枝是什么?
模型剪枝是不同于量化的另外一种模型压缩的方式。如果说“量化”是通过改变权重和激活值的表现形式从而让内存占用变小和计算变快的话,“剪枝”则是直接“删除”掉模型中没有意义的,或者意义较小的权重,来让推理计算量减少的过程。更准确来说,是skip掉一些没有必要的计算。
模型剪枝的目的:
主要是因为学习的过程中会产生过参数化导致会产生一些意义并不是很大的权重,或者值为0的权重(ReLU)。对于这些权重所参与的计算是占用计算资源且没有作用的。需要想办法找到这些权重并让硬件去skip掉这些权重所参与的计算。
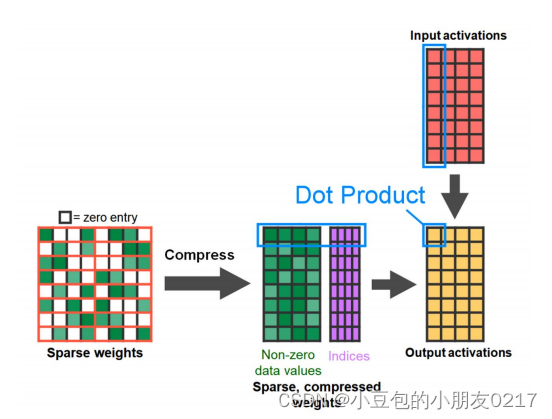
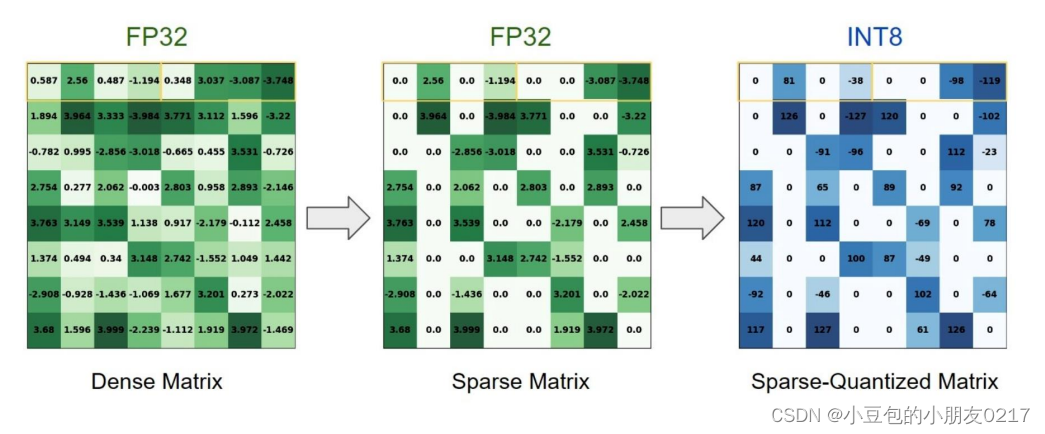
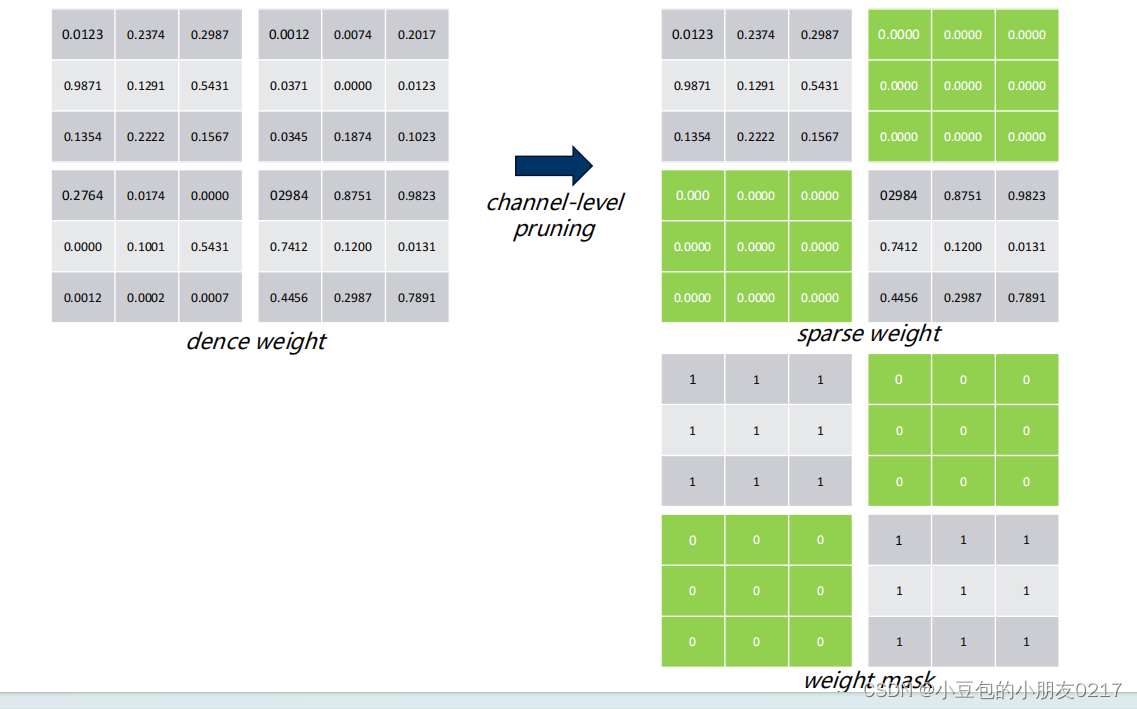
如图,我们可以把一个dense里面的不重要的权重归0,然后压缩,从88压缩成84和索引,再将压缩好的权重与激活值进行计算,就可以skip掉一些不重要的权重。
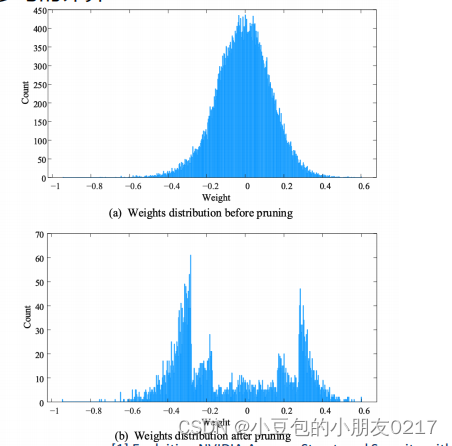
在剪枝前一般是以0为中心呈高斯分布,剪枝后0附近的权重就稀疏了。
二、模型剪枝流程
- 获取一个已经训练好的初始模型
- 对这个模型进行剪枝
- 对剪枝后的模型进行fine-tuning
- 获取到一个压缩的模型
2.1 对模型进行剪枝
- 可以通过训练的方式让DNN去学习哪些权重是可以归零的(使用L1 regularization和BN中的scaling factor让权重归零)
- 可以通过自定义一些规则,手动的有规律的去让某些权重归零.(对一个1x4的vector进行2:4的weight prunning)
2.2 对剪枝后的模型进行fine-tuning
有很大的可能性,在剪枝后初期的网络的精度掉点比较严重,则需要fine-tuning这个过程来恢复精度,Fine-tuning后的模型有可能会比之前的精度还要上涨。
2.3 获取到一个压缩的模型
如果压缩不满足要求可以回到步骤2再次剪枝,然后fine-tuning,压缩,直至满足要求。
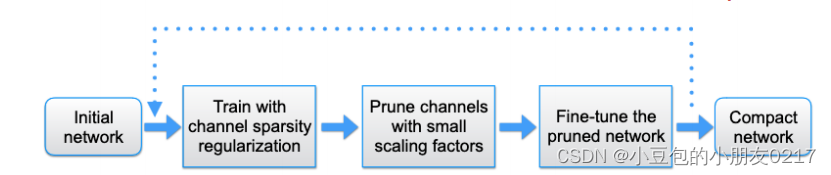
2.4 模型剪枝和量化
模型剪枝是可以配合着量化一起进行的。
三、模型剪枝的分类
按照减枝的方法按照一定规律与否
{ 结构化减枝 非结构化减枝 \left\{ \begin{array}{l} 结构化减枝 \\ \\ 非结构化减枝 \\ \end{array}\right. ⎩ ⎨ ⎧结构化减枝非结构化减枝
按照减枝的粒度与强度
{ 粗粒度减枝 细粒度减枝 \left\{ \begin{array}{l} 粗粒度减枝 \\ \\ 细粒度减枝 \\ \end{array}\right. ⎩ ⎨ ⎧粗粒度减枝细粒度减枝
3.1 Coarse Grain Pruning (粗粒度剪枝)
粗粒度剪枝包括Channel/Kernel Pruning,但Channel/Kernel Pruning也是结构化减枝(Structured pruning)。
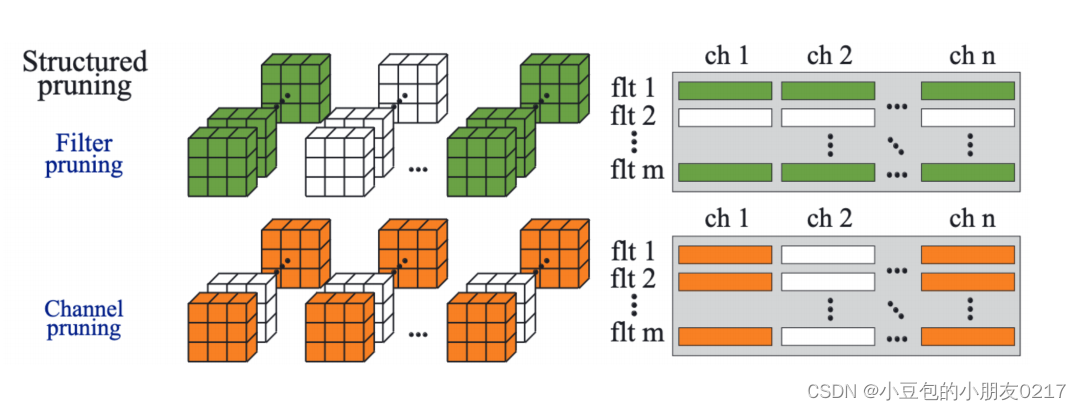
Kernel Pruning也就是直接把某些卷积核给去除掉,比较常见的方法就是通过L1Norm寻找权重中影响度比较低的卷积核。Channel Pruning就是把部分channel去除掉 。
Coarse Grain Pruning的优势劣势
- 优势:
不依赖于硬件,可以在任何硬件上跑并且得到性能的提升 - 劣势:
- 由于减枝的粒度比较大(卷积核级别的),所以有潜在的掉精度的风险
- 不同DNN的层的影响程度是不一样的
- 减枝之后有可能反而不适合硬件加速(比如Tensor Core的使用条件是channel是8或者16的倍数)
3.1 Fine Grain Pruning(细粒度剪枝)
Fine Grain Pruning(细粒度剪枝)主要是对权重的各个元素本身进行分析减枝。这里面可以分为结构化减枝(structed)与非结构化减枝(unstructed)。
-
结构化减枝
Vector-wise的减枝: 将权重按照4x1的vector进行分组,每四个中减枝两个的方式减枝权重 Block-
wise的减枝: 将权重按照2x2的block进行分区,block之间进行比较的方式来减枝block
-
非结构化减枝
Element-wise的减枝:每一个每一个减枝进行分析,看是不是影响度比较高

Fine Grain Pruning的优势劣势
- 优势:
相比于Coarse Grain Pruning,精度的影响并不是很大 - 劣势:
- 需要特殊的硬件的支持(Tensor Core可以支持sparse)
- 需要用额外的memory来存储哪些index是可以保留计算的
- memory的访问不是很效率(跳着访问)数)
- 支持sparse计算的硬件内部会做一些针对sparse的tensor的重编,这个会比较耗时
四、channel-level pruning
原文地址:https://arxiv.org/pdf/1708.06519.pdf
结构化剪枝中比较常用以及使用起来比较简单的方式是channel-level pruning,不依赖于硬件的特
性可以简单的实现粗粒度的剪枝。
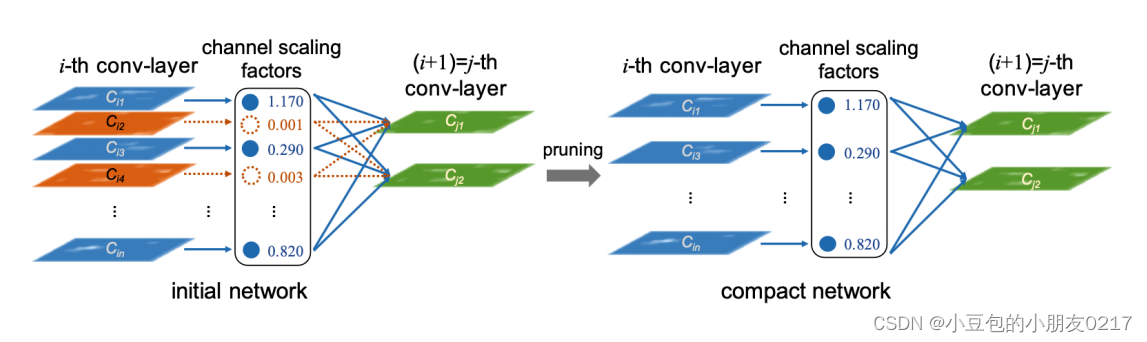
通过使用BN中的scaling factor,与使用L1-regularization的训练可以让权重趋向零这一特点,找到conv中不是很重要的channel,实现channel-level的pruning。通过对scaling factor进行L1正则,这里面的𝐶𝑖2和𝐶𝑖4会逐渐趋向零,我们可以认为这些channel不是很重要,可以称为pruning的候选。
4.1 L1 & L2 regularization
两者都是通过在loss损失函数中添加L1/L2范数(L1/L2-norm),实现对权重学习的惩罚(penalty)来限制权重的更新方式。根据L1/L2范数的不同,两者的作用也是不同的。训练的目的是让loss function逐渐变小。
• L1 regularization: 可以用来稀疏参数,或者说让参数趋向零。Loss function的公式是:

• L2 regularization: 可以用来减少参数值的大小。Loss function的公式是:
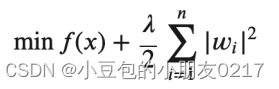
4.2 BN中的scaling factor
Batch normalziation一般放在conv之后,对conv的输出进行normalization。整个计算是channel-wise的,所以每一个channel都会有自己的BN参数(均值、方差、缩放因子、偏移因子)。如果BN之后发现某一个channel的scaling非常小,或者为零,可以认为这个channel做参与的计算并没有非常大强度的改变/提取特征,并不是那么重要。
使用BN和L1-norm对模型的权重进行计算以及重要度排序
在channel-wise pruning中,同样使用L1-norm作为惩罚项添加到loss中,但是L1-norm的参数不再是每一个权重,而是BN中对于conv中每一个channel的scaling factor。从而在学习过程中让scaling factor趋向零,并最终变为零。(负的scaling factor会变大,正的scaling factor会变小)。
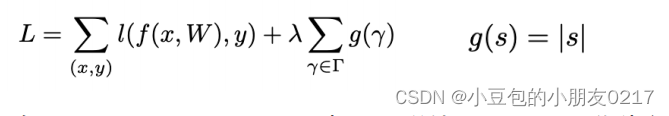
整个pruning的过程中𝜆和𝑐ℎ𝑎𝑛𝑛𝑒𝑙的剪枝力度是超参,需要不断的实验找到最优。𝜆表示的是在
loss中L1-norm这个penalty所占的比重。𝜆越大就整个模型就会越趋近稀疏。
对于scaling factor不是很大的channel,在pruning的时候可以把这些channel直接剪枝掉,但同时也需要把这些channel所对应的input/outputd的计算也skip掉。最终得到一个紧凑版的网络。这个方法比较方便去选择剪枝的力度,通过不断的实验找到最好的剪枝百分比。
• 0% pruning
• 25% pruning
• 50% pruning
• 75% pruning
注意:
-
刚剪枝完的网络,由于权重信息很多信息都没了,所以需要fine-tuning来提高精度(需要使用mask)
-
剪枝完的channel size可能会让计算密度变低(64channel通过75% pruning后变成16channel)
-
pruning后的channel尽量控制在64的倍数
• 要记住最大化tensor core的使用
• 对哪些层可以大力度的pruning需要进行sensitive analysis
• 要记住DNN中哪些层是敏感层
五、Pruning和fine-tuning
Pruning
fine-tuning
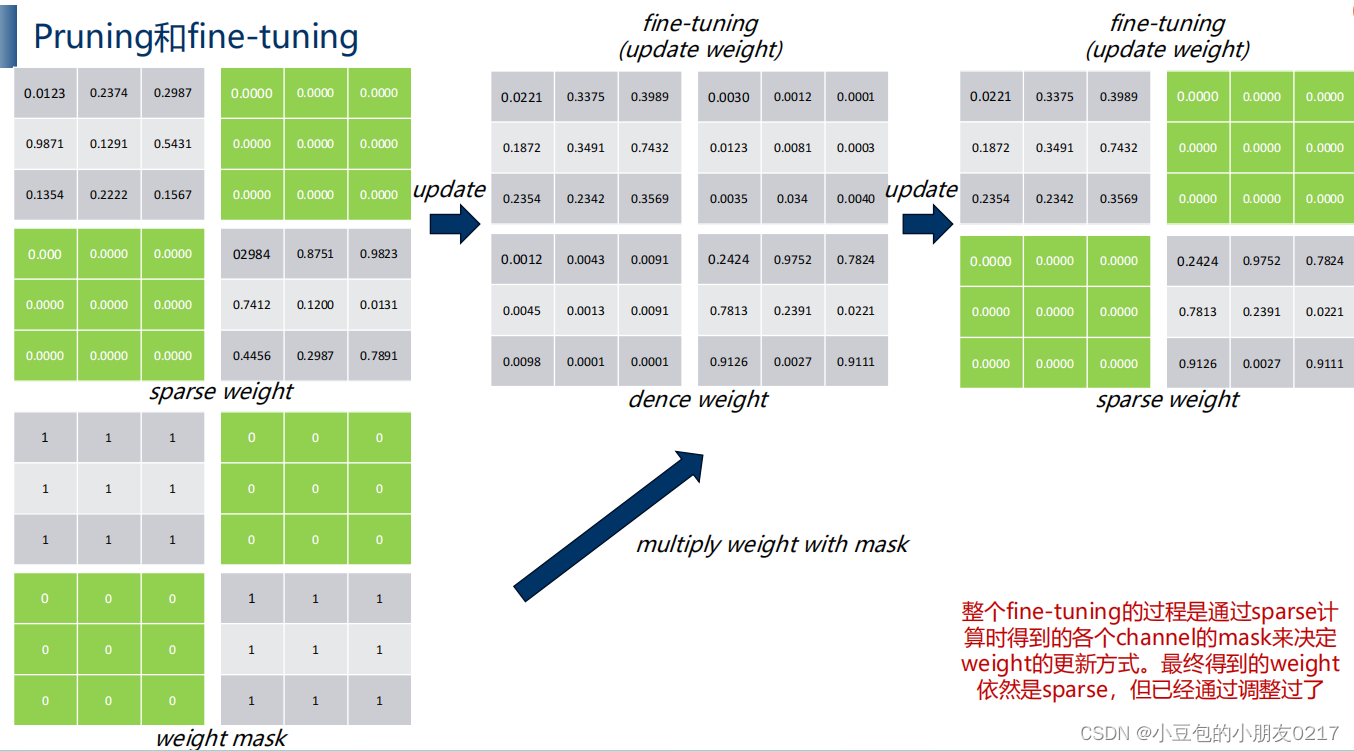
先训练,更新权重,然后根据weight mask 决定哪部分更新,与weight mask相乘,为1的部分不变,为0的相乘后为0。
总结
本章为专题内容,主要介绍TensorRT优化部署,可移步专题查看其他内容。