简介
dataset:数据集,提供数据
dataloader:数据加载器,对数据进行加载,可以讲数据加载到神经网络当中
从dataset中取数据时,通过在dataloader中设置参数来确定取数据的方式
用法
要from torch.utils.data import DataLoader
参数:大部分参数都有默认值
Args:dataset (Dataset): 指定数据集batch_size (int, optional): how many samples per batch to load (default: ``1``). 每次加载多少数据shuffle (bool, optional): set to ``True`` to have the data reshuffledat every epoch (default: ``False``). 每次训练后是否进行无序操作(默认为False,一般设置为True)sampler (Sampler or Iterable, optional): defines the strategy to drawsamples from the dataset. Can be any ``Iterable`` with ``__len__``implemented. If specified, :attr:`shuffle` must not be specified.batch_sampler (Sampler or Iterable, optional): like :attr:`sampler`, butreturns a batch of indices at a time. Mutually exclusive with:attr:`batch_size`, :attr:`shuffle`, :attr:`sampler`,and :attr:`drop_last`.num_workers (int, optional): how many subprocesses to use for dataloading. ``0`` means that the data will be loaded in the main process.(default: ``0``) 每次加载时是否采用多进程加载(但是在windows下可能会出现错误)collate_fn (Callable, optional): merges a list of samples to form amini-batch of Tensor(s). Used when using batched loading from amap-style dataset.pin_memory (bool, optional): If ``True``, the data loader will copy Tensorsinto device/CUDA pinned memory before returning them. If your data elementsare a custom type, or your :attr:`collate_fn` returns a batch that is a custom type,see the example below.drop_last (bool, optional): set to ``True`` to drop the last incomplete batch,if the dataset size is not divisible by the batch size. If ``False`` andthe size of dataset is not divisible by the batch size, then the last batchwill be smaller. (default: ``False``) 除不尽时是否舍去timeout (numeric, optional): if positive, the timeout value for collecting a batchfrom workers. Should always be non-negative. (default: ``0``)worker_init_fn (Callable, optional): If not ``None``, this will be called on eachworker subprocess with the worker id (an int in ``[0, num_workers - 1]``) asinput, after seeding and before data loading. (default: ``None``)multiprocessing_context (str or multiprocessing.context.BaseContext, optional): If``None``, the default `multiprocessing context`_ of your operating system willbe used. (default: ``None``)generator (torch.Generator, optional): If not ``None``, this RNG will be usedby RandomSampler to generate random indexes and multiprocessing to generate``base_seed`` for workers. (default: ``None``)prefetch_factor (int, optional, keyword-only arg): Number of batches loadedin advance by each worker. ``2`` means there will be a total of2 * num_workers batches prefetched across all workers. (default value dependson the set value for num_workers. If value of num_workers=0 default is ``None``.Otherwise, if value of ``num_workers > 0`` default is ``2``).persistent_workers (bool, optional): If ``True``, the data loader will not shut downthe worker processes after a dataset has been consumed once. This allows tomaintain the workers `Dataset` instances alive. (default: ``False``)pin_memory_device (str, optional): the device to :attr:`pin_memory` to if ``pin_memory`` is``True``.实践
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 准备测试数据集
test_data = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=torchvision.transforms.ToTensor())# 加载测试集
test_loader = DataLoader(test_data,shuffle=True, batch_size = 64, num_workers=0, drop_last=False)img, target = test_data[0]
print(img.shape)
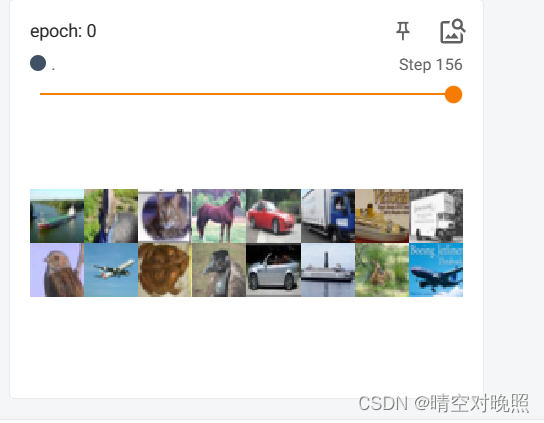
print(target)writer = SummaryWriter('logs')
for epoch in range(2):step = 0for data in test_loader:imgs, targets = data# print(imgs.shape)# print(targets)writer.add_images("epoch: {}".format(epoch), imgs, step)step = step+1writer.closeshuffle为True时,可以发现每轮训练数据的顺序是不一致的
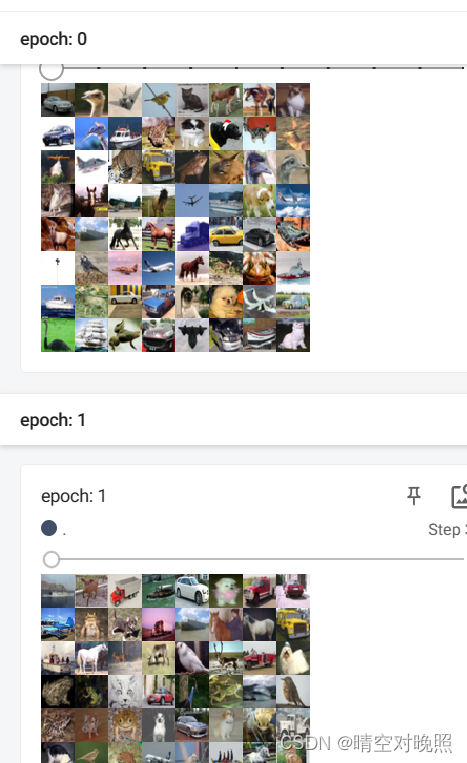
drop_last=False时,则没有整除的数据保留,即最后一步会不足所设置的batch大小