np.argsort 与获取位相关问题
位次: 数组中的数据在其排序之后的另一个数组中的位置
[1,0,2,3] 中 0的位次是1 1的位次是2 2的位次是3 3的位次是4
这里先直接给出结论,np.argsort()返回的索引排序与实际位次在确实在某些情况下会出现一致,但后来numpy的开发人员给我举例回复这是巧合,如果想获取位次,可以考虑使用scipy.stats.rankdata()方法,也组合numpy中其他函数。
- 如果你是想解决问题的开发人员直接根据目录跳转到最后方法总结查看示例代码,或者按照函数名直接搜索官方文档即可
- 如果你有相关问题的思考想直接看一下我和开发人员的探讨内容,直接点击链接去GitHub中查看即可
链接: https://github.com/numpy/numpy/issues/25601
我当时以为没有重复数据的时候就可以返回位次,但是有重复数据的时候不行,所以提问的标题是当时以为的情况,但后续讨论就是我这篇博客标题说的内容了
- 如果你想了解一下问题产生的原因和和听我絮叨拆解补充分析一下一下我俩对话的内容,可以扫一下下面的内容,或者根据经验自己跳着读。
1.问题的产生
事情是这样的在做项目的时候我遇到了这样一个问题,我要对某一个对象的收入进行分析,emmmm, 还是要举一个实际的例子,假设我要对一种奶茶店的收入进行分析,例如我要分析10个店面的这个月的收入情况,每个店面的收入由三部分组成,奶茶,果茶,冰淇淋。
| 店铺编号 | 总收入 | 果茶收入 | 奶茶收入 | 冰淇淋收入 |
|---|---|---|---|---|
| 店铺1 | 1954 | 100 | 911 | 754 |
| 店铺2 | 1663 | 300 | 949 | 705 |
| 店铺3 | 1765 | 200 | 822 | 388 |
| 店铺4 | 1437 | 500 | 911 | 252 |
| 店铺5 | 1410 | 400 | 105 | 932 |
首先先根据总收入这一列的数据对每一行进行排序
以下是常用的代码
# 原始列表
original_list = [['店铺1', 1954, 100, 911, 754],['店铺2', 1663, 300, 949, 705], ['店铺3', 1765, 200, 822, 388], ['店铺4', 1437, 500, 911, 252],['店铺5', 1410, 400, 105, 932]
]# 使用.sort()方法根据总收入对列表进行排序
original_list.sort(key=lambda x: x[1], reverse=True)
那么从大到小的排序结果如下,按照顺序其实就是总收入的排名
| 店铺编号 | 总收入 | 果茶收入 | 奶茶收入 | 冰淇淋收入 |
|---|---|---|---|---|
| 店铺1 | 1954 | 100 | 911 | 754 |
| 店铺3 | 1765 | 200 | 822 | 388 |
| 店铺2 | 1663 | 300 | 949 | 705 |
| 店铺4 | 1437 | 500 | 911 | 252 |
| 店铺5 | 1410 | 400 | 105 | 932 |
好那接下来我想在这个表里在果茶收入,奶茶收入,冰淇淋收入前面各加一列,分别为果茶收入排名,奶茶收入排名,冰淇淋收入排名。
| 店铺编号 | 总收入 | 果茶收入排名 | 果茶收入 | 奶茶收入排名 | 奶茶收入 | 冰淇淋收入排名 | 冰淇淋收入 |
|---|---|---|---|---|---|---|---|
| 店铺1 | 1954 | 待计算 | 100 | 待计算 | 911 | 待计算 | 754 |
| 店铺3 | 1765 | 待计算 | 200 | 待计算 | 822 | 待计算 | 388 |
| 店铺2 | 1663 | 待计算 | 300 | 待计算 | 949 | 待计算 | 705 |
| 店铺4 | 1437 | 待计算 | 500 | 待计算 | 911 | 待计算 | 252 |
| 店铺5 | 1410 | 待计算 | 400 | 待计算 | 105 | 待计算 | 932 |
那这个排名怎么得到,首先拿出奶茶这一列的数据。
然后就想用什么函数, 这时候忽然依稀的想起,数据对应的位置就是索引+1, 例如索引为0的数据实际上是列表的第1个数据,也就是位置为1,然后好像记得np.argsort()就是返回排序的索引,索引+1表示的应该就是他的位置,又排序了又有位置,虽然下意识有点怀疑感觉哪里不对,但是决定还是直接用一下再说,
然后我就使用了类似于果茶排名的数据进行了下面的操作(默认从小到大)
import numpy as np
data = [100, 200, 300, 500, 400]
rank = np.argsort(data) + 1
print(rank)
# [1 2 4 5 3]
呀(二声)!?
从小到大的看∑( 口 ||好像是对的哈,是位次
然后我就对所有的列都这样操作了将返回结果作为了位序的结果,由于收入数据很少有一样的而且数量很多所以其实不太好一眼看出逻辑错误,可能就观察了前几个,发现相对关系好像没问题就没再仔细检查了,但是在后续实际数据中由于有一些数据不存在,所以我直接都给赋值成了-1我认为这样的话他会被排在两边,但是存在大量的-1之后发现了问题。
如果按照位次的逻辑,下面的结果不就是胡排八排吗
默认是从小到大排的-1对应的位置是4,和3 在中间是怎么回事,1,2才是对的把,或者两个都是1
import numpy as np
data = [1, -1, 3, -1, 4]
rank = np.argsort(data) + 1
print(rank)
# [2 4 1 3 5]
在浏览了各种资料之后,有人说可能是排序方式选择的问题,默认是快速排序,快速排序有可能有问题,我就把文档里的np.argsort()的四种排序方式实验了一遍,加上好像其他人好像也都是对有重复数据的排序结果产生了质疑。此时我把我同样做算法的也是刚毕业的研究生航宝(昵称)叫了过来,让其帮我在stackflow上也简单搜索了下,也有人提出了这个问题,但是但是没有能直接一眼瞄到的问题的答案(也不排除看的不认真)。我俩也是鬼使神差的觉得这应该是由于有重复数据的问题。
之后我开始尝试写了一个可以实现返回位序的代码。
import numpy as np
data = [1, -1, 3, -1, 4]def my_sort(x):arg_x = np.sort(x)rank = [np.where(arg_x == i)[0][0] for i in x]return np.array(rank)rank = my_sort(data) + 1
print(rank)
# [3 1 4 1 5] 现结果
# [2 4 1 3 5] 原结果
然后找航宝来帮我验证,发现确实可以实现获得位序的功能,然后航宝提议,去GitHub上问一问,顺便搜一搜,我俩在问题里输入argsort同样也是简单翻了一翻,我俩认为这应该是个应该比较常见的问题,应该一搜就能搜到所以也没怎么往后面翻,发现没有之后,我俩就开始着手准备提问,点开了issue,在写issue中,我们又看了一遍np.argsort(data)官方文档的描述,述其描述如下
np.argsort performs an indirect sort on an array, returning the indices that would sort the array.
我们两个人又重新理解了一遍这个意思,np.argsort 返回一个不是对一个array直接排序结果,返回的是indices(索引们),而这些indices会对这个数组进行排序。
我们翻译成土话,可以理解的就是你按照np.argsort(data)的返回结果(一个有顺序的包含索引值的列表),把列表中的索引值替换为data[索引值],最后你会得到一个有序的数组。
嗯,真适合作为一道面试题,之前的话我可能会脱口而出他返回的是排序之后的索引(其实对不懂的人来说这句话可能并不清晰)
此时我们理解了np.argsort()的功能但是依旧认为他对非包含重复值的数组依然可以返回位序但是只不过如果含重复数值的话可能由于其使用的算法关系失去了这个功能
因此我们关闭了提出issue的选项,因为np.argsort()本身没有问题不是BUG,转而选择了一个给numpy增添新功能的选项,写完正文发送了之后,又给邮箱发了一遍邮件。以下是邮件内容
不敢兴趣可以跳过
2.鄙人给numpy讨论邮箱发送的邮件内容
汉语是我本来的意思,英语是连机翻再改的结果,可能有点对不上但是大致是一个意思
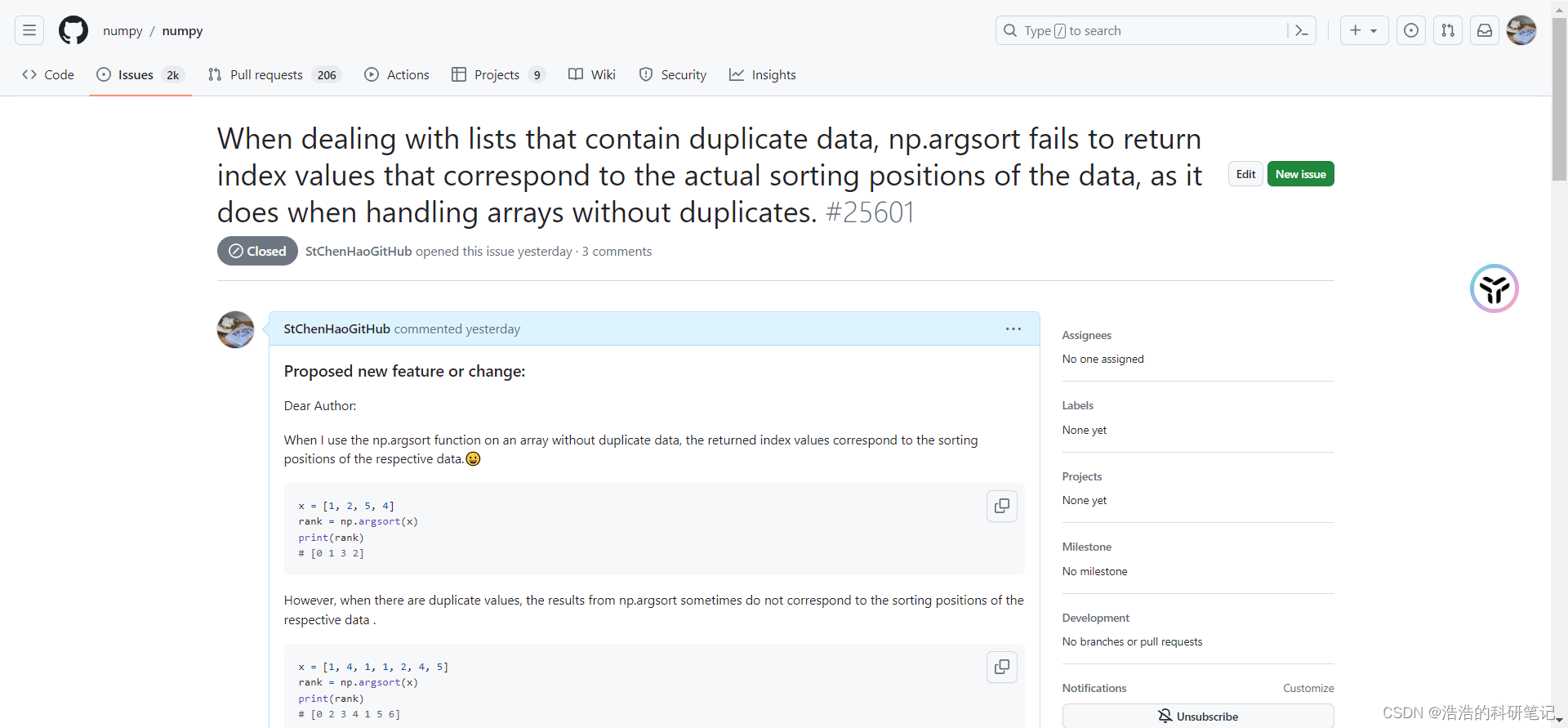
尊敬的作者:
Dear Author:
当我使用np.argsort 函数处理具有非重复数据的数组的时候,他返回的索引值,与其排序之后所处的位置有关联
When I use the np.argsort function on an array without duplicate data, the returned index values correspond to the sorting positions of the respective data.😀
x = [1, 2, 5, 4]
rank = np.argsort(x)
print(rank)
# [0 1 3 2]
但当数组中包含重复数据时,np.argsort函数有时就无法返回与数据位置相关的信息了。
However, when there are duplicate values, the results from np.argsort sometimes do not correspond to the sorting positions of the respective data .
x = [1, 4, 1, 1, 2, 4, 5]
rank = np.argsort(x)
print(rank)
# [0 2 3 4 1 5 6]
有可能一个人经常使用np.argsrot处理具有非重复数据的数组来获取位置信息,有重复数据的话,可能会产生一些不易察觉的错误,如果数据长度非常大的话发现这个问题可能更具有挑战性。
Assuming a person frequently uses np.argsort to obtain positions by sorting data without duplicates, introducing duplicate values in the data may lead to inconspicuous errors in positions that are difficult to detect. Moreover, as the dataset grows, identifying such issues may become even more challenging.
可能对于有这种需求的用户来说,他们想要得到的结果可以由以下函数实现
For users in this situation, the desired results might be achieved using the following function:
def my_sort(x):arg_x = np.sort(x)rank = [np.where(arg_x == i)[0][0] for i in x]return np.array(rank)x = [1, 4, 1, 1, 2, 4, 5]
rank_arg = np.argsort(x)
rank_position = my_sort(x)
print("rank_arg",rank_arg)
print("rank_position",rank_position)
# rank_arg [0 2 3 4 1 5 6]
# rank_position [0 4 0 0 3 4 6]这个方法在处理具有非重复数据的时候与np.argsort函数的返回结果一致(补充:后来证明这是巧合)
This method produces results consistent with np.argsort when applied to arrays without duplicate values.
x = [1, 2, 5, 4]
rank_arg = np.argsort(x)
rank_position = my_sort(x)
print("rank_arg",rank_arg)
print("rank_position",rank_position)
# rank_arg [0 1 3 2]
# rank_position [0 1 3 2]
尽管其实np.argsort函数文档本身描述的内容没有问题,但是这种需求可能是广泛存在的,因此能不能考虑新加一个功能,例如np.position(data),去提升numpy功能性
Although there is no issue with the documentation of np.argsort itself, the need you’ve highlighted may be widespread. Therefore, it might be worth considering the addition of a function, for example, np.position(data), to enhance the functionality of numpy.
我的设备
My device:
系统
system: win10 64x
python版本
python version: 3.9.11
numpy 版本
numpy version: 1.21.2
真诚的期待您的回复
Sincerely, Looking forward to your response! ❤❤❤❤
3. numpy 官方人员的回复
回复我的是 Robert Kern 职位尚不清楚 所属机构是 Enthought(开发numpy 和 scipy的公司) line_profiler 库的开发者,该项目有3.6K个星,该大佬第一次在半个小时内回复了我,由于我是中午发的,所以他在美丽国的半夜十一点给我回复了邮件/(ㄒoㄒ)/~~,美丽国大佬恐怖如斯。

下面的翻译中(括号里的内容不是作者说的话是我的补充)翻译的不好请多见谅
3.1 第一次回复
这并不是argsort函数内容打算做的或者文档里描述的
这里指我说的在处里具有非重复数据中返回位次的功能
他返回的是一索引数组,他是指向(into)x的,如果你按照这个顺序从x中拿数的话你会得到一个有序的数组,如果说把x 排序成sorted_x,对于所有的i in range(len(x))会满足
x[rank[i]] == sorted_x[i],argsort返回的索引,是数据在x中的位置,而不是在sorted_x中的位置。你例子中的出现的关联情况,是在一些小的例子中偶然发生的(我:🤡),但是考虑一个例子[20, 30, 10, 40]
That is not what argsort is intended or documented to do. It returns an array of indices into x such that if you took the values from x in that order, you would get a sorted array. That is, if x were sorted into the array sorted_x, then x[rank[i]] == sorted_x[i] for all i in range(len(x)). The indices in rank are positions in x, not positions in sorted_x. They happen to correspond in this case, but that’s a coincidence that’s somewhat common in these small examples. But consider [20, 30, 10, 40]:
(他在下面的代码中对他提到的例子使用np.argsort()处理,发现虽然没有重复数据但是返回的仍然不正确的位次信息,然后大佬自己写写了一个position()内容和我的不同,但是返回了同样的结果,这里的np.searchsorted()的作用是查找数据在目标数组中的插入位置)
>>> x = np.array([20, 30, 10, 40])
>>> ix = np.argsort(x)
>>> def position(x):
... sorted_x = np.array(x)
... sorted_x.sort()
... return np.searchsorted(sorted_x, x)
...
>>> ip = position(x)
>>> ix
array([2, 0, 1, 3])
>>> ip
array([1, 2, 0, 3])
但也得注意的是:
But also notice:
>>> np.argsort(np.argsort(x))
array([1, 2, 0, 3])
用两次argsort你看,也能返回这个结果(当时我:啊😦(二声),这也行),这取决于你对重复项的处理想达到什么效果,你是想返回重复值在排序之后的数组中第一次出现的索引,还是想返回特定项被排序到的索引。
This double-argsort is what you seem to be looking for, though it depends on what you want from the handling of duplicates (do you return the first index into the sorted array with the same value as in my position() implementation, or do you return the index that particular item was actually sorted to).
不管怎么样,我们可能不打算把这个添加到我们的功能里,以上的两种目的都可以用现有的基础功能直接组合得到。
Either way, we probably aren’t going to add this as its own function. Both options are straightforward combinations of existing primitives.
3.2 第二次回复
在第二天凌晨2点,美丽国刚吃完午饭,我收到了第二次回复
也可以考虑一下使用 scipy.stats.rankdata(),它提供了许多处理重复值的选项
ties 其实实际意思是并列值,但是感觉还是翻译成重复值感觉更符合语境和之前探讨的内容

也就是其实scripy 中 已经实现了这个函数,但是可能并没有太被人们所熟知,以至于大佬第一次回复都没想到可能.
4.返回位序方法总结
以上就得到了四种返回位序的方法
4.1 scipy.stats.rankdata (推荐)
其中功能最强大的那就是scipy.stats 中的rankdata 方法了
import numpy as np
from scipy.stats import rankdata# 创建一个数组
x = np.array([40, 20, 30, 20, 40])# 使用 rankdata 对数组中的元素进行排名,分别使用四种不同的方法
ranks_average = rankdata(x, method='average') # 默认方法,平均排名
# [4.5, 1.5, 3. , 1.5, 4.5]
ranks_min = rankdata(x, method='min') # 最小排名
# [4, 1, 3, 1, 4]
ranks_max = rankdata(x, method='max') # 最大排名
# [5, 2, 3, 2, 5]
ranks_dense = rankdata(x, method='dense') # 密集排名
# [3, 1, 2, 1, 3]
ranks_ordinal = rankdata(x, method='ordinal') # 序数排名
# [4, 1, 3, 2, 5]- 平均排名(average):如果存在相同的元素,它们被赋予其排名的平均值。
- 最小排名(min):并列元素被赋予所有可能排名中的最小值。
- 最大排名(max):并列元素被赋予所有可能排名中的最大值。
- 密集排名(dense):并列元素被赋予相同的排名,且排名之间没有间隔。
- 序数排名(ordinal):每个元素被赋予一个唯一的排名,即使它们的值相同
4.2 double np.argsort()
这是第二种方法,其等效于scipy.stats.rankdata的序数排名模式,代码精简,看起来比较炫酷
import numpy as np
x = np.array([40, 20, 30, 20, 40])
rank = np.argsort(np.argsort(x))+1
print(x)
# [4 1 3 2 5]
4.3 Robert Kern Position
这是第三种,在邮件中Robert Kern回复我的position 函数
等效于scipy.stats.rankdata的最小排名模式,个人认为这个不是非常好的选择,首先他肯定不如scipy.stats.rankdata精简,而且又引入了一个新的知名度可能不是很高的函数np.searchsorted
import numpy as np
x = np.array([40, 20, 30, 20, 40])def position(x):sorted_x = np.array(x)# 排序sorted_x.sort()# 寻找插入位置return np.searchsorted(sorted_x, x)rank = position(x) + 1
print(rank)
# [4 1 3 1 4]
4.4 My Position
最后就是我的了,我写的吧,算法效率必然是最低又占内存运行的又慢,就是代码逻辑可能相对好理解一点(也许)
- My Position Min
等效于scipy.stats.rankdata的最小排名模式
import numpy as np
x = np.array([40, 20, 30, 20, 40])
def position_min(x):x = np.array(x)# 排序arg_x = np.sort(x)# 查找重复元素在排序数组中第一次出现的位置 # np.where() 返回的是元组 np.where()[0] 取元组里包含索引值的列表# np.where()[0][0] 第一次出现的索引 np.where()[0][-1]最后一次rank = [np.where(arg_x == i)[0][0] for i in x]return np.array(rank)rank = position_min(x) + 1
print(rank)
# [4 1 3 1 4]
- My Position Max
等效于scipy.stats.rankdata的最大排名模式
import numpy as np
x = np.array([40, 20, 30, 20, 40])
def position_max(x):x = np.array(x)# 排序arg_x = np.sort(x)# 查找重复元素在排序数组中第一次出现的位置 # np.where() 返回的是元组 np.where()[0] 取元组里包含索引值的列表# np.where()[0][0] 第一次出现的索引 np.where()[0][-1]最后一次rank = [np.where(arg_x == i)[0][-1] for i in x]return np.array(rank)rank = position_max(x) + 1
print(rank)
# [5 2 3 2 5]
结束语
我会专门想办法再去测试一个各个算法的运行效率,然后根据运行时间给出一个最终的结论