目录
- kafka 消费者API用法
- 消费者API
- 使用消费者API消费消息
- 消费者消费消息的代码演示
- 1、官方API示例
- 2、创建消费者类
- 3、演示消费结果
- 1、演示消费者属于同一个消费者组
- 2、演示消费者不属于同一个消费者组
- 3、停止线程不适用
- 4、一些参数解释
- 代码
- 生产者:MessageProducer
- 消费者 Consumer01
- 消费者 Consumer02
- pom.xml
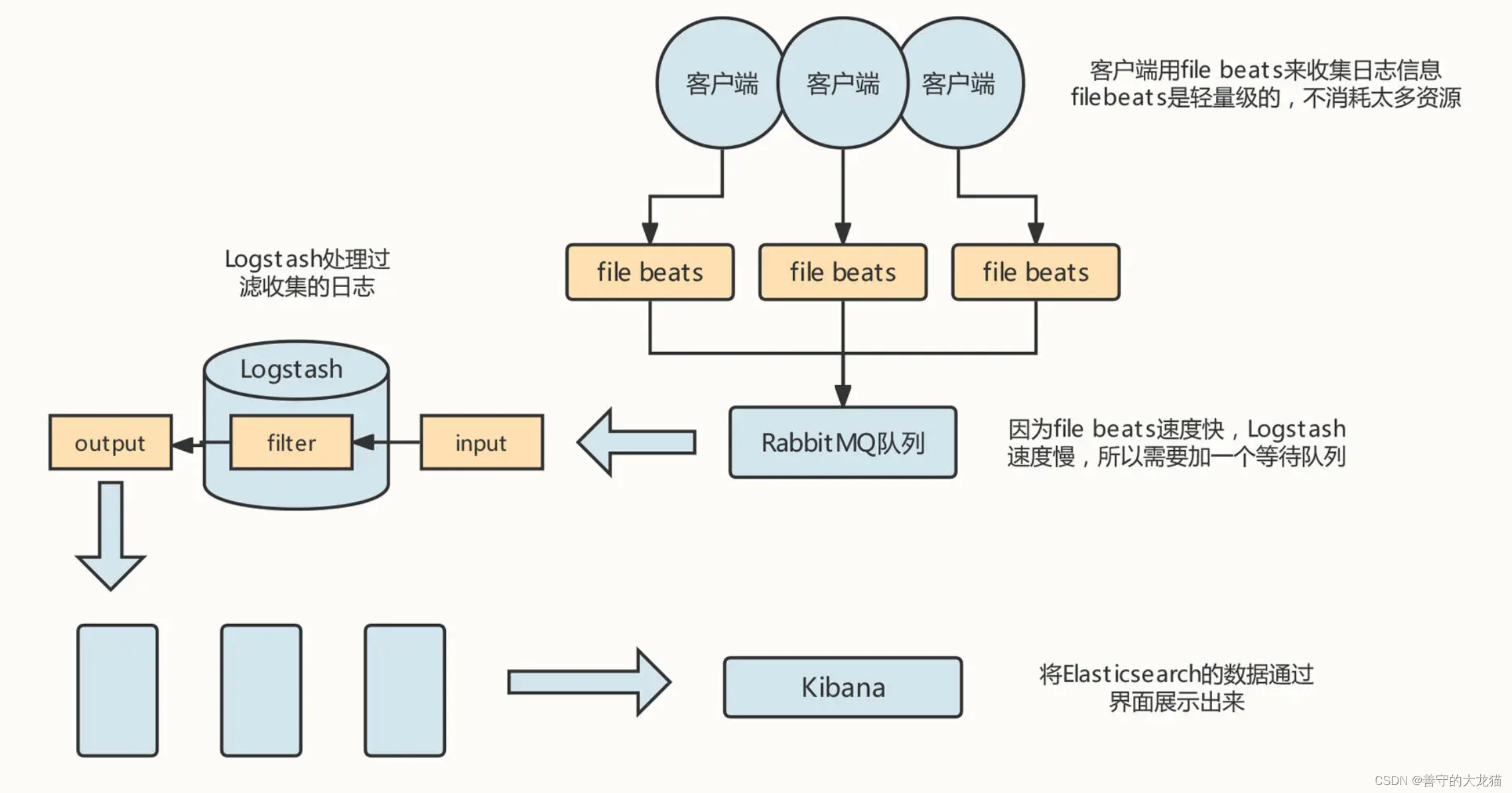
kafka 消费者API用法
消费者API
消费者API的核心类是 KafkaConsumer,它提供了如下常用方法:
- subscribe(Collection<String> topics):订阅主题。- subscribe(Pattern pattern):订阅符合给定正则表达式的所有主题。- subscription():返回该消费者所订阅的主题集合。- unsubscribe():取消订阅。- close():关闭消费者。- poll(Duration timeout):拉取消息。- assign(Collection<TopicPartition> partitions):手动为该消费者分配分区。- assignment():返回分配该消费者的分区集合。- commitAsync():异步提交offset。- commitSync():同步提交offset。提示:如果开启了自动提交offset,则无需调用上面commitAsync()或commitSync()方法进行手动提交;自动提交offset比较方便,但手动提交offset则更精确,消费者程序可以等到消息真正被处理后再手动提交offset。——该选项有点类似于JMS、RabbitMQ的消息消费者的,消息确认机制。- enforceRebalance():强制执行重平衡。
下面这些方法都体现了Kafka是一个数据流平台,消费者通过这些方法可以从分区的任意位置、重新开始读取数据。
- seek(TopicPartition partition, long offset):跳到指定的offset处,即下一条消息从offset处开始拉取。- seekToBeginning(Collection<TopicPartition> partitions):跳到指定分区的开始处。- seekToEnd(Collection<TopicPartition> partitions):跳到指定分区的结尾处。- position(TopicPartition partition):返回指定分区当前的offset。
使用消费者API消费消息
根据KafkaConsumer不难看出,使用消费者API拉取消息很简单,基本只要几步:
1、创建KafkaConsumer对象,创建该对象时要传入Properties对象,用于对该消费者进行配置。
2、调用KafkaConsumer对象的poll()方法拉取消息,该方法返回ConsumerRecords。
3、对ConsumerRecords执行迭代,即可获取到抓取的每条消息。
4、程序结束时,取消订阅,关闭KafkaConsumer。
消费者消费消息的代码演示
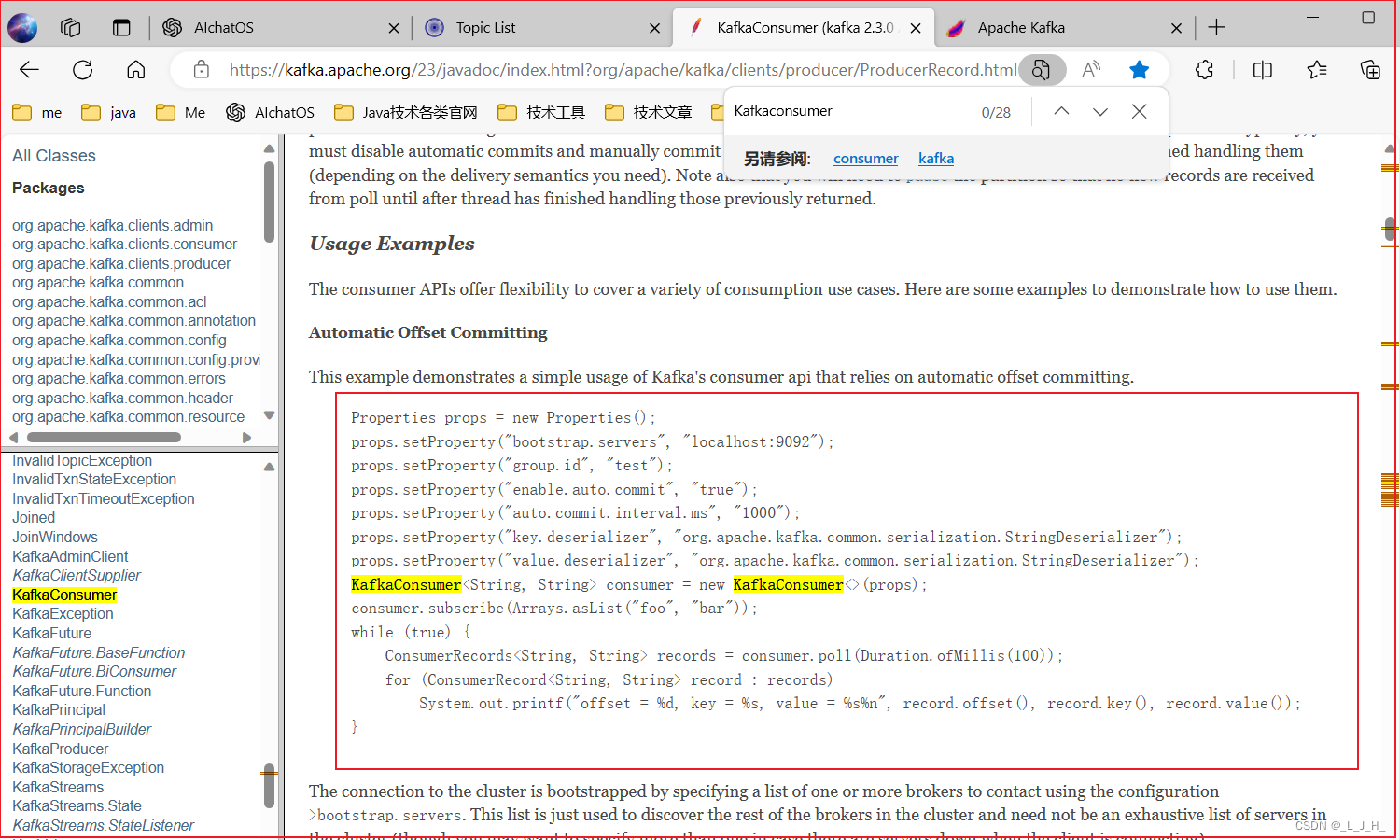
1、官方API示例
KafkaConsumer
2、创建消费者类
在上一篇的生产者项目中,再写2个消费者来消费消息
Kafka 生产者API 用法
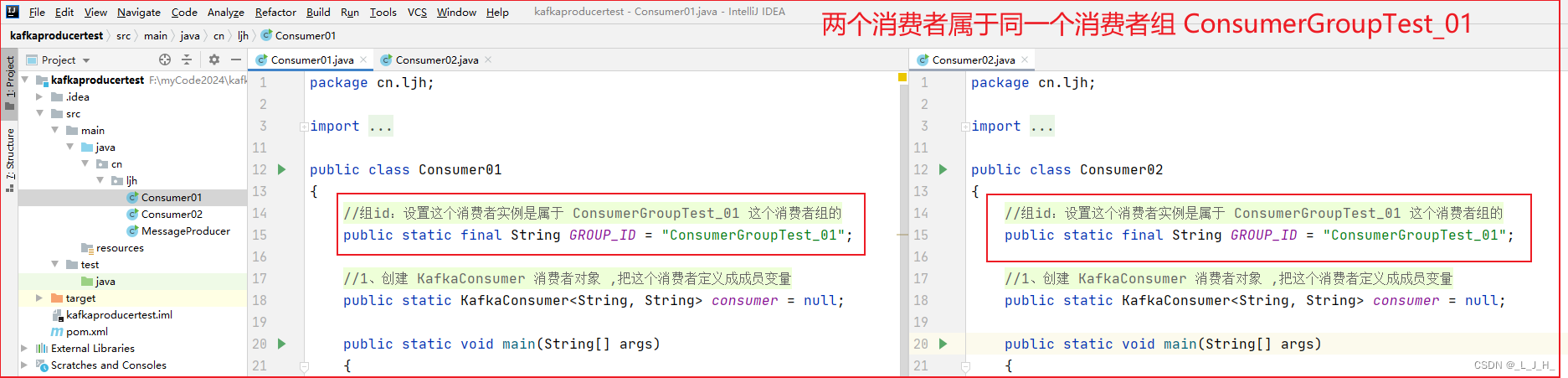
如图,创建2个消费者类,这个是消费者01,消费者02和01都是一模一样的。

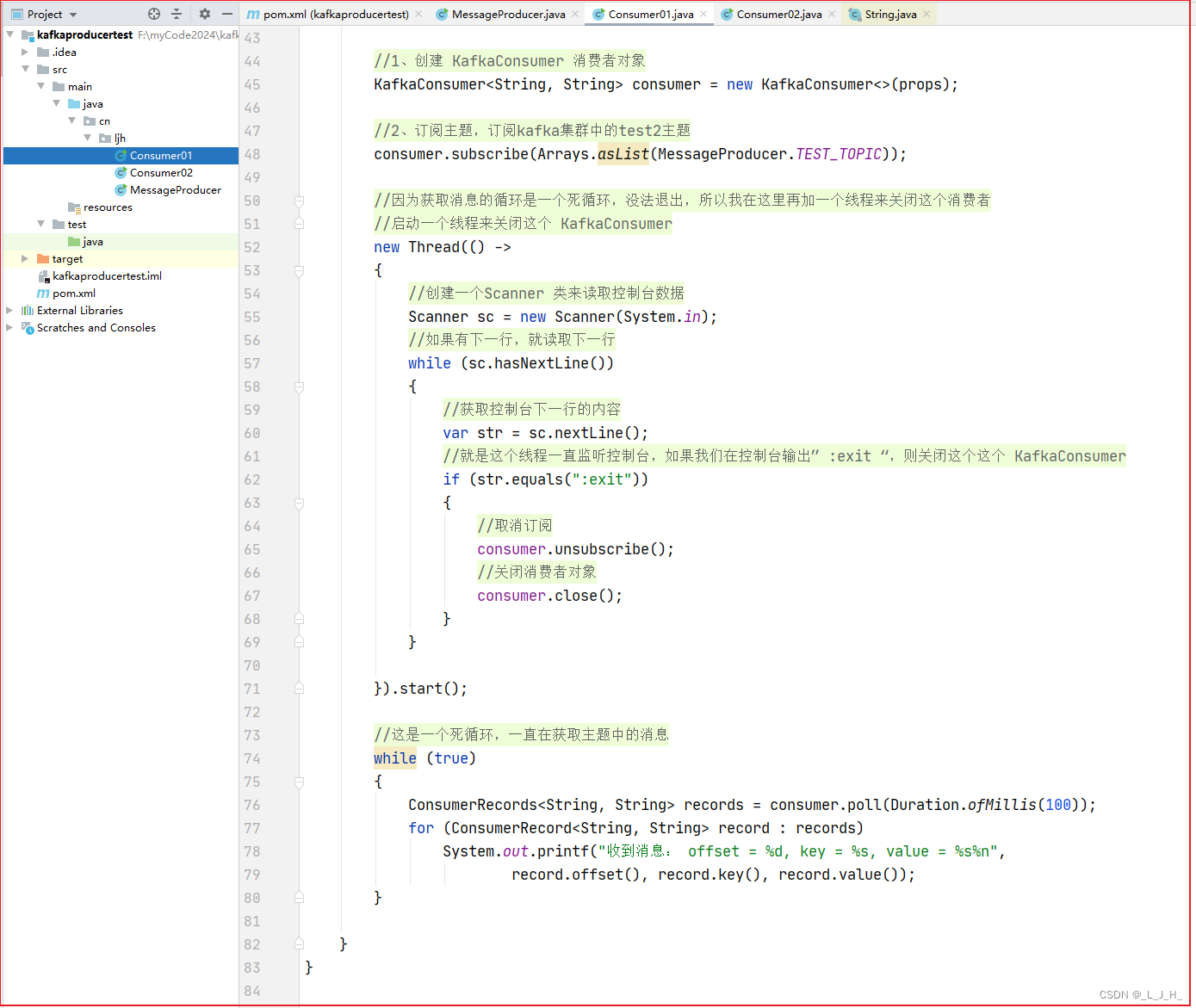
3、演示消费结果
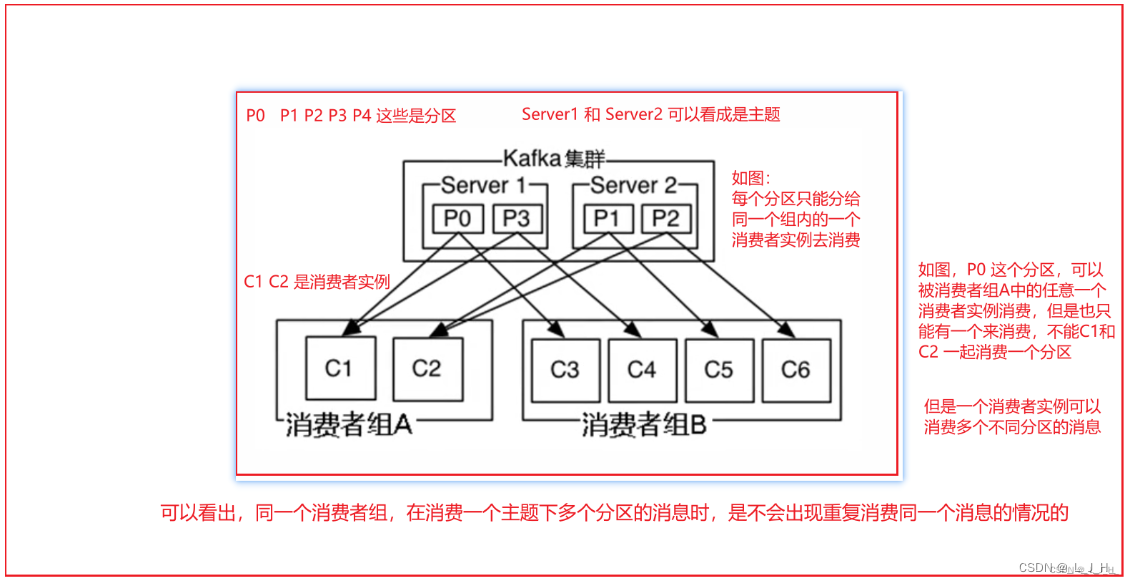
1、演示消费者属于同一个消费者组
如上图,可以看出,两个消费者属于同一个消费者组 ConsumerGroupTest_01 ,所以两个消费者消费到的消息是不重复的。因为每个消费者消费的分区都是不同的。
演示前预期结果:因为两个消费者属于同一个消费者组,所以每个消费者消费的分区都是不同的,也就是不会重复消费消息
演示结果:
演示步骤:启动两个消费者实例,然后启动生产者,往test2主题中发送20条消息,10条消息带key,10条消息不带key,大概率这各10条的消息就会被分配在不同的2个分区中。
根据kafka默认的分区消费规则,应该是一个消费者消费一个分区的消息
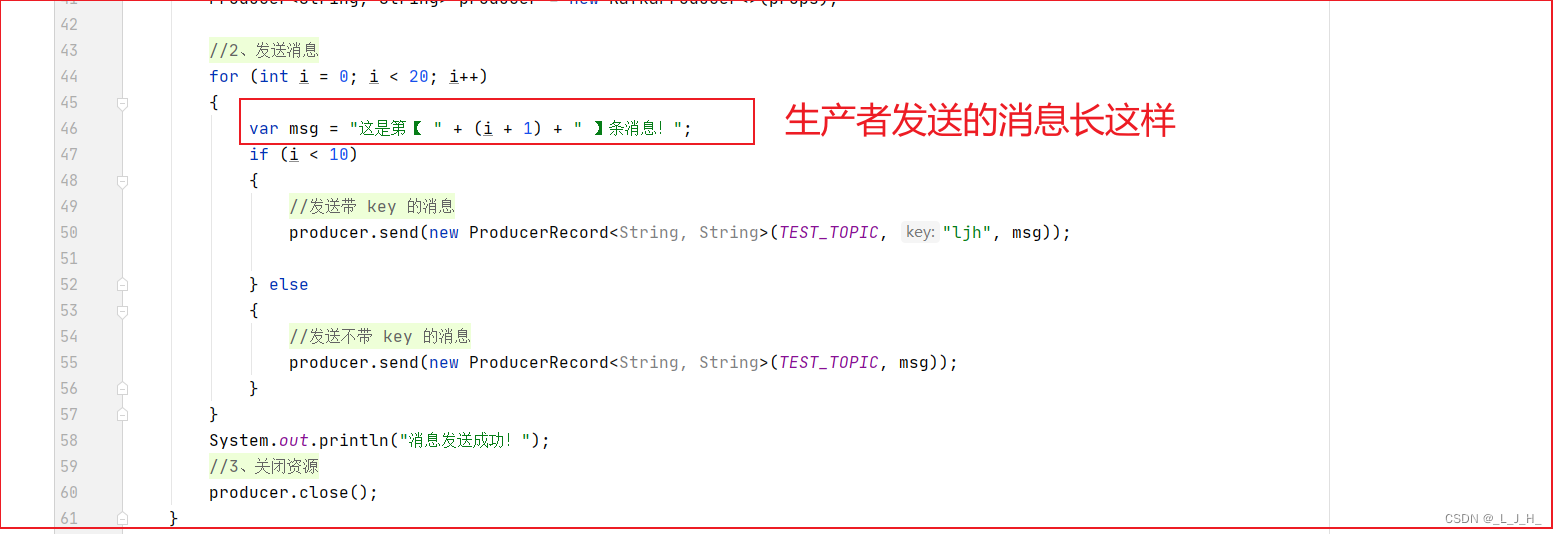
生产者发送消息:
生产者代码在这篇:
Kafka 生产者API 用法
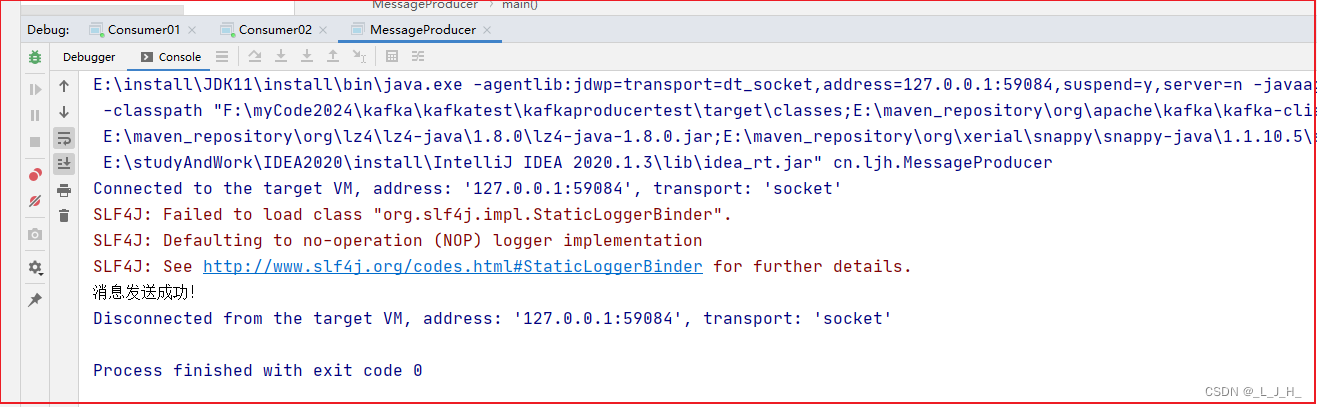
消费者消费:
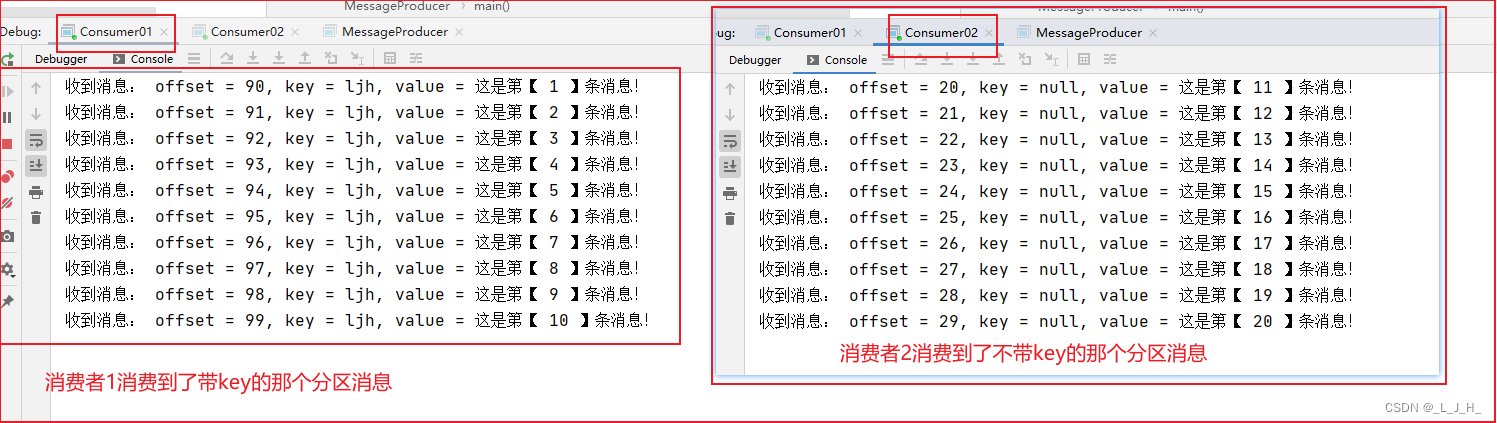
如图:消费者01 获取到了带key的消息并消费,消费者02 获取到了不带key的消息并消费,这里的消费消息先弄成打印就可以了。
注意:演示中,多次重启消费者,然后再启动生产者发送消息,总是消费者01消费到所有消息,消费者02没有消费到消息,然后生产者重新发送消息,才能有以下的演示结果。
类似集群模式,就是消息只能被一个消费者消费
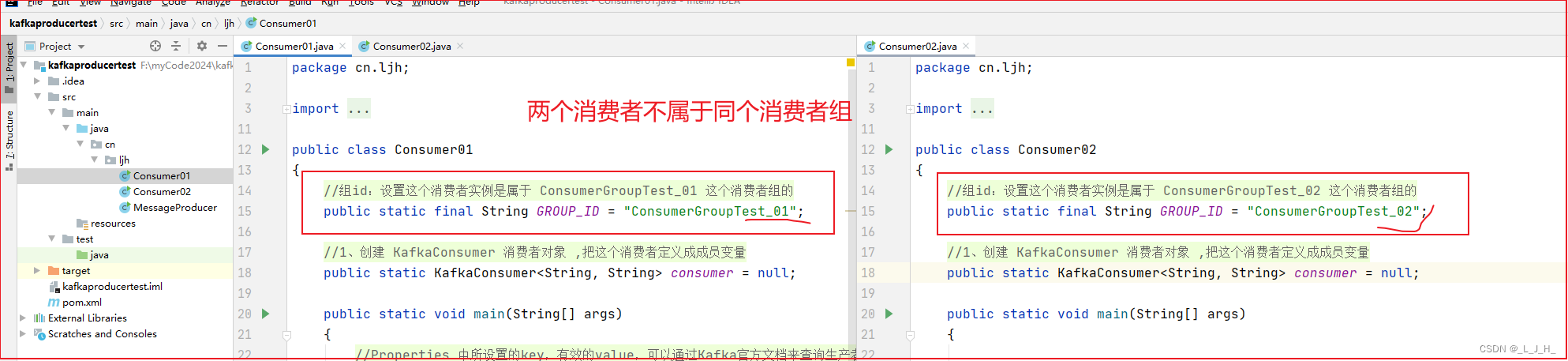
2、演示消费者不属于同一个消费者组
因为两个消费者不属于同一个消费者组,所以两个消费者都能消费到test2主题下的所有分区的消息。
演示步骤:其他代码没变,只是修改了他们所属的消费者组
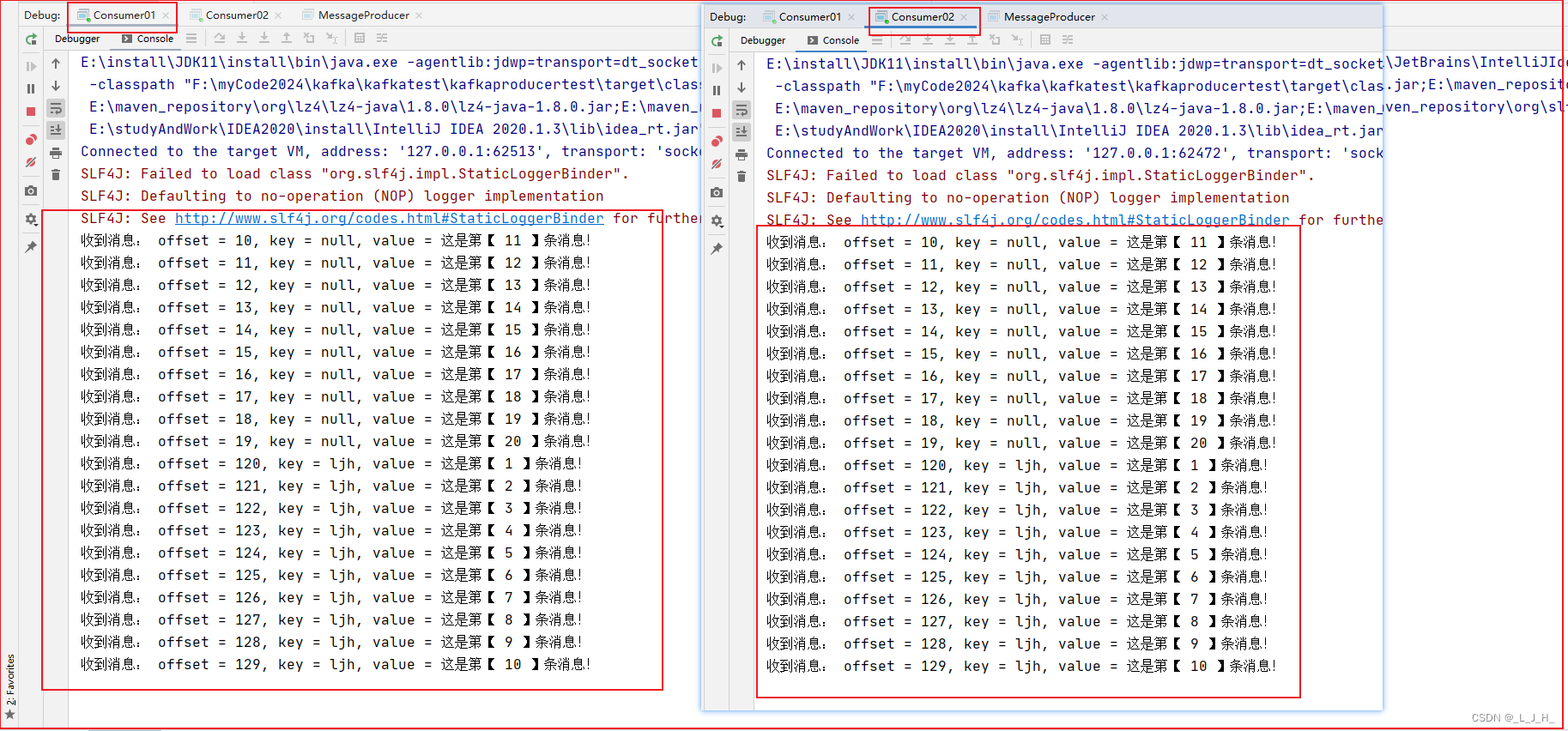
演示结果如图:两个消费者不属于同一个消费者组,每个消费者都能消费到所有消息,
类似于广播模式、或者是发布/订阅模式,
发布/订阅模型可以让一条消息能被多个消费者消费
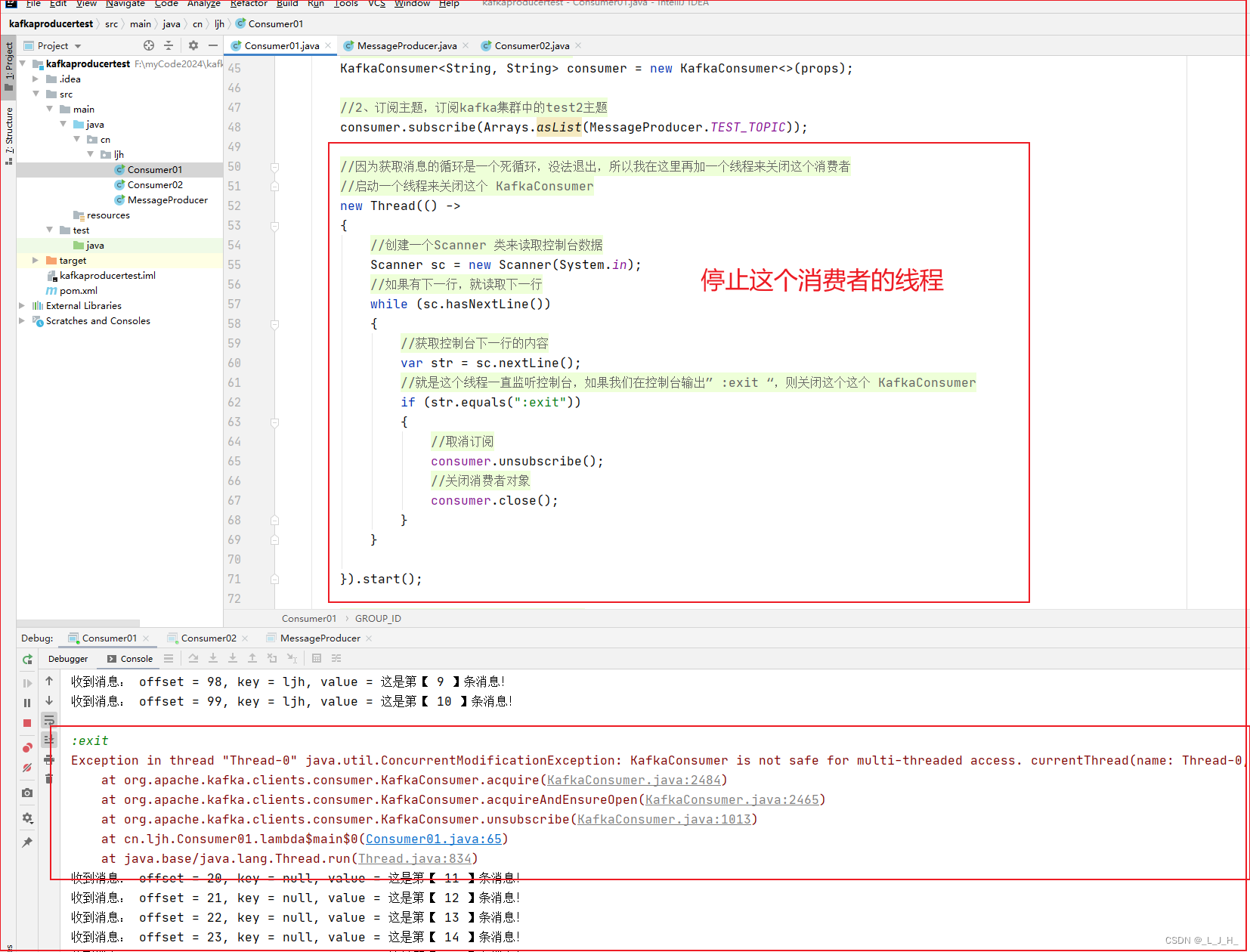
3、停止线程不适用
这个停止消费者的线程好像没有用,如图,我生产者再发送消息后,这个消费者还是能消费到消息,并没有想象中的被停止。
现阶段要关闭消费者的话,直接关闭项目就可以了
4、一些参数解释

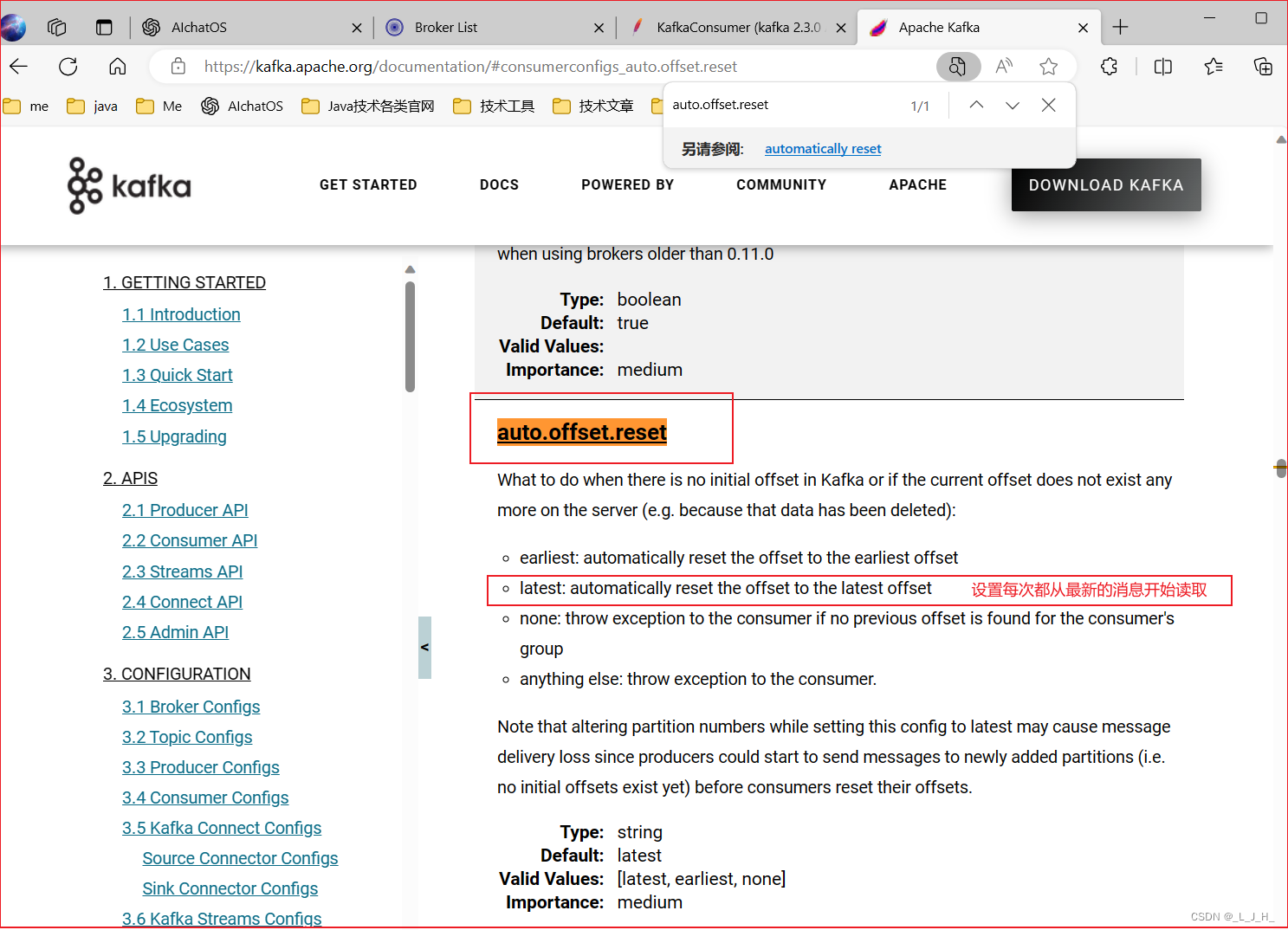
auto.offset.reset
设置从哪里读取消息
代码
生产者:MessageProducer
package cn.ljh;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;import java.util.Properties;/*** Properties: Kafka 设计了 Properties 来封装所有的配置属性* <p>* KafkaProducer:用来创建消息生产者,是 生产者API 的核心类,* 它提供了一个 send()方法 来发送消息,该方法需要传入一个 ProducerRecord<K,V>对象* <p>* ProducerRecord:代表了一条消息,Kafka 的消息是包含了key、value、timestamp*/
public class MessageProducer
{//主题常量public static final String TEST_TOPIC = "test2";public static void main(String[] args){//Properties 中所设置的key,有效的value,可以通过Kafka官方文档来查询生产者API支持哪些配置属性Properties props = new Properties();//指定连接Kafka的地址,多个地址之间用逗号隔开props.put("bootstrap.servers", "localhost:9092,localhost:9093,localhost:9094");//指定Kafka的消息确认机制//0:不等待消息确认;1:只等待领导者分区的消息写入之后确认;all:等待所有分区的消息都写入之后才确认props.put("acks", "all");//指定消息发送失败的重试多少次props.put("retries", 0);//控制生产者在发送消息之前等待的时间//props.put("linger.ms", 3);//设置序列化器props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");//1、创建 KafkaProducer 时,需要传入 Properties 对象来配置消息生产者Producer<String, String> producer = new KafkaProducer<>(props);//2、发送消息for (int i = 0; i < 20; i++){var msg = "这是第【 " + (i + 1) + " 】条消息!";if (i < 10){//发送带 key 的消息producer.send(new ProducerRecord<String, String>(TEST_TOPIC, "ljh", msg));} else{//发送不带 key 的消息producer.send(new ProducerRecord<String, String>(TEST_TOPIC, msg));}}System.out.println("消息发送成功!");//3、关闭资源producer.close();}
}消费者 Consumer01
package cn.ljh;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import java.util.Scanner;public class Consumer01
{//组id:设置这个消费者实例是属于 ConsumerGroupTest_01 这个消费者组的public static final String GROUP_ID = "ConsumerGroupTest_01";//1、创建 KafkaConsumer 消费者对象 ,把这个消费者定义成成员变量public static KafkaConsumer<String, String> consumer = null;public static void main(String[] args){//Properties 中所设置的key,有效的value,可以通过Kafka官方文档来查询生产者API支持哪些配置属性Properties props = new Properties();//指定连接Kafka的地址,多个地址之间用逗号隔开props.put("bootstrap.servers", "localhost:9092,localhost:9093,localhost:9094");//设置这个消费者实例属于哪个消费者组props.setProperty("group.id", GROUP_ID);//自动提交offset,就是类似之前的自动消息确认props.setProperty("enable.auto.commit", "true");//多个消息之间,自动提交消息的时间间隔props.setProperty("auto.commit.interval.ms", "1000");//设置session的超时时长,默认是10秒,这里设置15秒props.setProperty("session.timeout.ms", "15000");//设置每次都从最新的消息开始读取props.setProperty("auto.offset.reset","latest");//设置序列化器props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");//1、创建 KafkaConsumer 消费者对象consumer = new KafkaConsumer<>(props);//2、订阅主题,订阅kafka集群中的test2主题consumer.subscribe(Arrays.asList(MessageProducer.TEST_TOPIC));//因为获取消息的循环是一个死循环,没法退出,所以我在这里再加一个线程来关闭这个消费者//启动一个线程来关闭这个 KafkaConsumernew Thread(() ->{//创建一个Scanner 类来读取控制台数据Scanner sc = new Scanner(System.in);//如果有下一行,就读取下一行while (sc.hasNextLine()){//获取控制台下一行的内容var str = sc.nextLine();//就是这个线程一直监听控制台,如果我们在控制台输出” :exit “,则关闭这个这个 KafkaConsumerif (str.equals(":exit")){//取消订阅consumer.unsubscribe();//关闭消费者对象consumer.close();}}}).start();//这是一个死循环,一直在获取主题中的消息while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records)System.out.printf("收到消息: offset = %d, key = %s, value = %s%n",record.offset(), record.key(), record.value());}}
}消费者 Consumer02
package cn.ljh;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
import java.util.Scanner;public class Consumer02
{//组id:设置这个消费者实例是属于 ConsumerGroupTest_02 这个消费者组的public static final String GROUP_ID = "ConsumerGroupTest_02";//1、创建 KafkaConsumer 消费者对象 ,把这个消费者定义成成员变量public static KafkaConsumer<String, String> consumer = null;public static void main(String[] args){//Properties 中所设置的key,有效的value,可以通过Kafka官方文档来查询生产者API支持哪些配置属性Properties props = new Properties();//指定连接Kafka的地址,多个地址之间用逗号隔开props.put("bootstrap.servers", "localhost:9092,localhost:9093,localhost:9094");//设置这个消费者实例属于哪个消费者组props.setProperty("group.id", GROUP_ID);//自动提交offset,就是类似之前的自动消息确认props.setProperty("enable.auto.commit", "true");//多个消息之间,自动提交消息的时间间隔props.setProperty("auto.commit.interval.ms", "1000");//设置session的超时时长,默认是10秒,这里设置15秒props.setProperty("session.timeout.ms", "15000");//设置每次都从最新的消息开始读取props.setProperty("auto.offset.reset","latest");//设置序列化器props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");//1、创建 KafkaConsumer 消费者对象consumer = new KafkaConsumer<>(props);//2、订阅主题,订阅kafka集群中的test2主题consumer.subscribe(Arrays.asList(MessageProducer.TEST_TOPIC));//因为获取消息的循环是一个死循环,没法退出,所以我在这里再加一个线程来关闭这个消费者//启动一个线程来关闭这个 KafkaConsumernew Thread(() ->{//创建一个Scanner 类来读取控制台数据Scanner sc = new Scanner(System.in);//如果有下一行,就读取下一行while (sc.hasNextLine()){//获取控制台下一行的内容var str = sc.nextLine();//就是这个线程一直监听控制台,如果我们在控制台输出” :exit “,则关闭这个这个 KafkaConsumerif (str.equals(":exit")){//取消订阅consumer.unsubscribe();//关闭消费者对象consumer.close();}}}).start();//这是一个死循环,一直在获取主题中的消息while (true){ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records)System.out.printf("收到消息: offset = %d, key = %s, value = %s%n",record.offset(), record.key(), record.value());}}
}pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>cn.ljh</groupId><artifactId>kafkaproducertest</artifactId><version>1.0.0</version><!-- 项目名,和 artifactId 保持一致 --><name>kafkaproducertest</name><properties><!-- 在这里指定编译器的版本 --><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target><java.version>11</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><!-- 导入 Kafka 客户端API的JAR包 --><dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.6.1</version></dependency></dependencies></project>