前言

Elasticsearch(ES)是一个基于Apache Lucene的分布式、高扩展、近实时的搜索引擎,主要用于海量数据快速存储、实时检索、高效分析的场景。通过简单易用的RESTful API,Elasticsearch隐藏了Lucene的复杂性,使得全文搜索变得简单。
以下是Elasticsearch的主要特点:
- 分布式:由于其分布式特性,Elasticsearch可以将海量数据分散到多台服务器上存储、检索和分析。
- 高扩展性:Elasticsearch可以扩展到上百台服务器,支持大规模数据存储和检索。
- 近实时性:Elasticsearch提供了近乎实时的搜索和分析功能,数据写入后几乎可以立即进行搜索和分析。
- 全文检索:Elasticsearch支持全文检索,能够快速检索数据并返回匹配的结果。
- 分布式分析:通过分布式特性,可以在多台服务器上并行处理数据,提高分析效率。
- 数据丰富:无论数据是结构化还是非结构化,Elasticsearch都能高效地存储和索引数据,并提供快速检索和分析。
- 易于使用:通过RESTful API,Elasticsearch提供了简单易用的接口,方便开发人员进行数据检索和查询。
由于以上特点,Elasticsearch广泛应用于各种业务场景,如维基百科、Stack Overflow、GitHub等均有使用。此外,Elasticsearch也是Elastic Stack的核心组件之一,与其他组件如Logstash、Kibana等配合使用,可以更方便地进行数据收集、处理、分析和可视化等工作。
下面是操通过服务器 3 台实现集群的安装
一、Elasticsearch 集群安装
1、准备工作创建对应安装目录并下载 elasticsearch rpm包
1.1 创建安装目录并下载资源包
mkdir es-node-1-7.7.1
cd es-node-1-7.7.1
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.7.1-x86_64.rpm效果如图:
1.2 部署前配置,修改limits.conf 文件
注:limits.conf 是 PAM (Pluggable Authentication Modules) 的配置文件,用于设置用户和组的资源限制。通过这个文件,你可以限制用户或组可以使用的系统资源,如 CPU、内存、磁盘空间等。
#修改limits.conf 文件,该文件为通过PAM登录的用户设置资源限制,它不影响系统服务的资源限制。
#这里的 * 标识所有用户
#noproc 是代表最大进程数
#nofile 是代表最大文件打开数
#memlock 最大锁定内存地址空间
#hard limit 严格的设定,必定不能超过这个设定的数值
#soft limit 警告的设定,可以超过这个设定值,但是若超过则有警告信息
#unlimited 无限制
[root@localhost es-node-1-7.7.1 ~] vim /etc/security/limits.conf
hard nofile 65536 # es要求文件数最小为65536
soft nproc 2048
hard nproc 4096
soft memlock unlimited
hard memlock unlimited#修改sysctl.conf文件,Sysctl是一个允许您改变正在运行中的Linux系统的接口,用sysctl可以读取设置超过五百个系统变量。
[root@localhost es-node-1-7.7.1 ~] vim /etc/sysctl.conf
vm.max_map_count=655360 # 限制一个进程可以拥有的VMA(虚拟内存区域)的数量
fs.file-max=655360 # 系统级打开最大文件句柄的数量永久生效的修改#使sysctl.conf 修改生效
[root@localhost es-node-1-7.7.1 ~] sysctl -p2、开始安装
2.1 Root 用户安装
sudo rpm -ivh elasticsearch-7.7.1-x86_64.rpm
2.2 重新加载服务并启动
1、sudo systemctl daemon-reload
注意:sudo systemctl daemon-reload 用于重新加载 systemd 服务的命令。当你修改了 systemd 的服务文件后,需要运行这个命令来使修改生效。这是因为 systemd 服务文件中的配置在修改后并不会自动应用到已运行的服务上,需要通过重新加载来应用新的配置。
如果你在编辑完 systemd 服务文件后直接启动或重启服务,可能会因为配置错误而导致服务无法正常启动。因此,在修改完服务文件后,应该先运行 sudo systemctl daemon-reload 命令,然后再启动或重启服务,以确保配置正确。
请注意,运行 sudo systemctl daemon-reload 命令需要管理员权限,因此需要使用 sudo 命令来执行。
2、sudo systemctl enable elasticsearch.service
用于启用 systemd 服务单元的命令。当你安装了一个服务并将其配置为开机自启时,可以使用这个命令来使其在系统启动时自动启动。
3、sudo systemctl start elasticsearch.service 用于启动 systemd 服务单元的命令
3、创建对应的数据目录和日志目录
创建数据存储目录
mkdir -p /home/app_user/es-node-1-7.7.1/data
mkdir -p /home/app_user/es-node-1-7.7.1/logs/jvmlogs修改ES目录权限
chown -R app_user:app_user /etc/elasticsearch/
chown -R app_user:app_user /usr/share/elasticsearch/
chown -R app_user:app_user /home/app_user/es-node-1-7.7.1/data
chown app_user:app_user /etc/sysconfig/elasticsearch
chown -R app_user:app_user /home/app_user/es-node-1-7.7.1/logs/jvmlogs
# 以上操作都是为了赋予app_user用户操作权限4、安装完生成配置文件
安装完毕后会生成很多文件,包括配置文件日志文件等等,下面几个是最主要的配置文件路径 /etc/elasticsearch/elasticsearch.yml # els的配置文件
/etc/elasticsearch/jvm.options # JVM相关的配置,内存大小等等
/etc/elasticsearch/log4j2.properties # 日志系统定义
/usr/share/elasticsearch # elasticsearch 默认安装目录
/var/lib/elasticsearch # 数据的默认存放位置
5、修改集群配置
5.1 修改elasticsearch.yml配置文件
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: es-7.7.1
node.name: node-1
path.data: /home/app_user/es-node-1-7.7.1/data
path.logs: /home/app_user/es-node-1-7.7.1/logs
network.host: 10.10.1.11
http.port: 9200
transport.port: 9300 # tcp的端口号,默认是9300
discovery.seed_hosts: ["10.10.1.11", "10.10.1.12","10.10.1.13"]
cluster.initial_master_nodes: ["node-1", "node-2"]
http.cors.enabled: true #是否开启跨域访问
http.cors.allow-origin: "*" #开启跨域访问后的地址限制,*表示无限制配置文件如图:


elasticsearch.yml 文件的配置本次配置是循环主节点
5.2 JVM的参数修改
$ vim /etc/elasticsearch/jvm.options
-XX:ErrorFile=/home/app_user/es-node-1-7.7.1/logs/jvmlogs/hs_err_pid%p.log
8:-Xloggc:/home/app_user/es-node-1-7.7.1/logs/jvmlogs/gc.log
9-:-Xlog:gc*,gc+age=trace,safepoint:file=/home/app_user/es-node-1-7.7.1/logs/jvmlogs/gc.log:utctime,pid,tags:filecount=32,filesize=64m
详细如图:

注意:JVM(Java虚拟机)的配置文件名为jvm.options,通常位于Java项目的根目录下。该文件用于设置JVM的参数,以优化Java应用程序的性能和行为。
在jvm.options文件中,可以设置各种JVM参数,包括堆内存大小、垃圾回收器选项、JIT编译器选项等。这些参数可以影响Java应用程序的启动速度、内存使用、运行性能等。
5.3 修改elasticsearch的默认启动用户
vim /usr/lib/systemd/system/elasticsearch.service User=app_user Group=app_user
6、启动Elasticsearch
Root用户下执行:
systemctl restart elasticsearch.service
6.1 浏览器访问:
直接在浏览器内输入:http://10.10.1.11:9200/
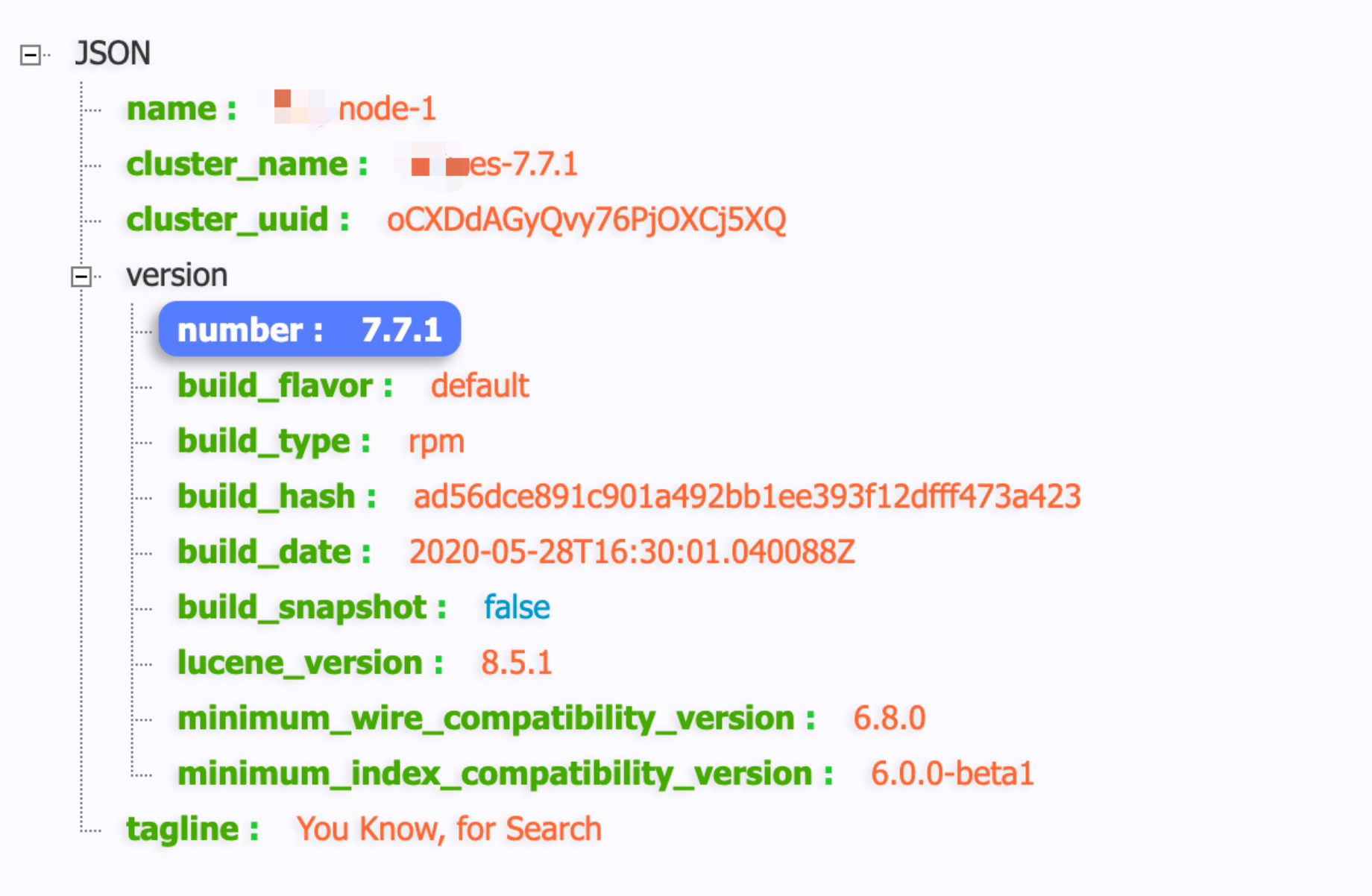
6.2 服务端直接 curl 请求
curl 请求:curl -i "http://10.10.1.12:9200/"
二、ElasticSearch7.7.1 集群安装 IK 和 pinyin 扩展插件
1、下载并安装扩展插件
1.1 下载 elasticsearch-analysis-ik
https://github.com/medcl/elasticsearch-analysis-ik/releases
1.2 下载 elasticsearch-analysis-pinyin
https://github.com/medcl/elasticsearch-analysis-pinyin/releases
详细如图:
cd /usr/local/tools/elasticsearch/elasticsearch-7.7.1
# 直接下载 ik 扩展插件
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.7.1/elasticsearch-analysis-ik-7.7.1.zip
# 直接下载 pinyin 扩展插件
wget https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v7.7.1/elasticsearch-analysis-pinyin-7.7.1.zip#新建il文件夹
mkdir -P plugins/ik
# 解压到 插件 到ik目录
mv elasticsearch-analysis-ik-7.7.1.zip /ik/
unzip elasticsearch-analysis-ik-7.7.1.zip# 拼音扩展同样的操作#切换目录 cd /usr/share/elasticsearch
#查看是否安装完成
bin/elasticsearch-plugin list1.3 查看安装扩展插件列表

2、重启es,让分词器生效,操作shell如下
2.1 Root用户下执行重启
systemctl restart elasticsearch.service
2.2 或者 jps 查看 elesticsearch 进程杀掉重启

$ kill -9 8448
#重启启动esbin/elasticsearch -d
确保整个es集群上的每台机器都操作了以上步骤后,就可以在kibana上测试了
三、ElasticSearch7.7.1 集群 kibana 看板
1、下载对应版本的 kibana 包
https://elasticsearch.cn/download/#seg-2 官方下载地址
https://artifacts.elastic.co/downloads/kibana/kibana-7.7.1-linux-x86_64.tar.gz
2、下载完kibana 包,直接解压并修改配置文件
kibana 运行用户 app_user
路径:/home/app_user/kibana-7.7.1-linux-x86_64
2.1 修改配置文件 kibana.yml
操作效果如图:
cd /home/app_user
#直接解压
$ tar -zxvf kibana-7.7.1-linux-x86_64.tar.gz
$ cd kibana-7.7.1-linux-x86_64/config/
$ vi kibana.ymlserver.port: 5601
server.host: "0.0.0.0"
server.name: "Kibana"
elasticsearch.hosts: ["http://10.10.1.11:9200", "http://10.10.1.12:9200","http://10.10.1.13:9200"]
kibana.index: ".kibana"
kibana.defaultAppId: "home"# 后台运行Kibana
$ nohup ./bin/kibana &
#或者
#nohup ./bin/kibana >logs/kibana.log 2>&1 &#浏览器访问
http://10.10.1.11:5601/app/kibana.
#/home###
# 查看 kibana
ps -ef|grep kibana
ps -ef|grep 5601
#都找不到
#使用 fuser -n tcp 5601 - 哎呀有了
kill -9 #端口
ps -ef|grep node 或 netstat -anltp|grep 5601
#启动即可 ./kibana
#后台启动:
nohup …/bin/kibana &2.2 运行并访问
$ nohup /home/app_user/kibana-7.7.1-linux-x86_64/bin/kibana
最终执行是可以配置后台执行
就这样,Kibana安装完成,可以尝试配置一下吧。
参考文献:
https://blog.csdn.net/LXWalaz1s1s/article/details/111697177
https://www.likecs.com/show-306320469.html