文章目录
- 为什么有持久化
- 什么是持久化
- RDB
- 文件创建
- SAVE
- BGSAVE
- 文件载入
- 优缺点
- AOF日志
- 步骤
- 对比
- 数据恢复
- 总结
Redis是一个开源的内存数据结构存储系统,被广泛应用于Web应用中,可以用作数据库和缓存服务器。它具有高性能、高并发、高可用性等特点,因此在大规模的数据处理和高并发访问的场景下表现出色。
为什么有持久化
由于Redis默认是将数据存储在内存中,一旦服务重启或崩溃,所有的数据将会丢失。
什么是持久化
为了解决这个问题,Redis提供了持久化机制,可以将数据存储到硬盘上,以保证数据不会因为服务重启或崩溃而丢失。
利用永久性存储介质将数据进行保存,在特定的时间将保存的数据进行恢复的工作机制称为持久化
Redis目前支持两种持久化机制:RDB快照和AOF日志。

RDB
RDB快照是Redis的默认持久化方式,它会定期将内存中的数据快照保存到硬盘上。
文件创建
RDB 持久化功能所生成的 RDB 文件是一个经过压缩的紧凑二进制文件,通过该文件可以还原生成 RDB 文件时的数据库状态,有两个 Redis 命令可以生成 RDB 文件,一个是 SAVE,另一个是 BGSAVE
SAVE
SAVE 指令:手动执行一次保存操作,该指令的执行会阻塞当前 Redis 服务器,客户端发送的所有命令请求都会被拒绝,直到当前 RDB 过程完成为止,有可能会造成长时间阻塞,线上环境不建议使用
配置 redis.conf:
dir path #设置存储.rdb文件的路径,通常设置成存储空间较大的目录中,目录名称data
dbfilename "x.rdb" #设置本地数据库文件名,默认值为dump.rdb,通常设置为dump-端口号.rdb
rdbcompression yes|no #设置存储至本地数据库时是否压缩数据,默认yes,设置为no节省CPU运行时间
rdbchecksum yes|no #设置读写文件过程是否进行RDB格式校验,默认yes
BGSAVE
BGSAVE:bg 是 background,代表后台执行,命令的完成需要两个进程,进程之间不相互影响,所以持久化期间 Redis 正常工作
工作原理:

流程:客户端发出 BGSAVE 指令,Redis 服务器使用 fork 函数创建一个子进程,然后响应后台已经开始执行的信息给客户端。子进程会异步执行持久化的操作,持久化过程是先将数据写入到一个临时文件中,持久化操作结束再用这个临时文件替换上次持久化的文件
文件载入
RDB 文件的载入工作是在服务器启动时自动执行,期间 Redis 会一直处于阻塞状态,直到载入完成
Redis 并没有专门用于载入 RDB 文件的命令,只要服务器在启动时检测到 RDB 文件存在,就会自动载入 RDB 文件
优缺点
RDB快照的优点是对硬盘空间的利用率高,恢复数据的速度快,适合用于备份和灾难恢复。缺点是在服务意外重启的情况下,最后一次快照之后的数据将会丢失。
AOF日志
AOF(append only file)持久化:以独立日志的方式记录每次写命令(不记录读)来记录数据库状态,增量保存只许追加文件但不可以改写文件,与 RDB 相比可以理解为由记录数据改为记录数据的变化
AOF 主要作用是解决了数据持久化的实时性
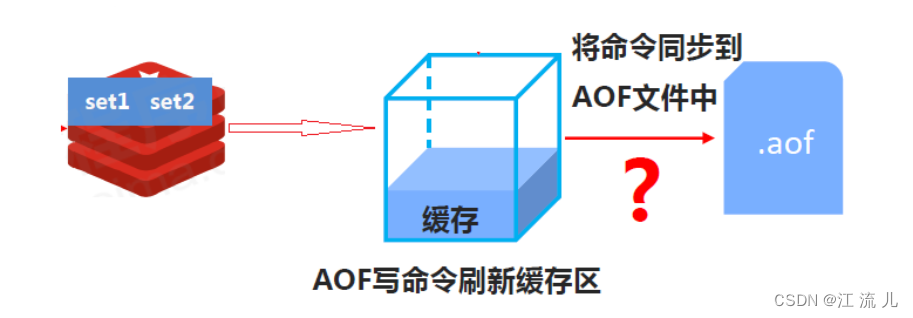
步骤
AOF 持久化功能的实现可以分为命令追加(append)、文件写入、文件同步(sync)三个步骤
命令追加:服务器在执行完一个写命令之后,会以协议格式将被执行的写命令追加到服务器状态的 aof_buf 缓冲区的末尾
文件写入:服务器在处理文件事件时会执行写命令,追加一些内容到 aof_buf 缓冲区里,所以服务器每次结束一个事件循环之前,就会执行 flushAppendOnlyFile 函数,判断是否需要将 aof_buf 缓冲区中的内容写入和保存到 AOF 文件里
文件同步:在现代操作系统中,当用户调用 write 函数将数据写入文件时,操作系统通常会将写入数据暂时保存在一个内存缓冲区空间,等到缓冲区写满或者到达特定时间周期,才真正地将缓冲区中的数据写入到磁盘里面(刷脏)
对比
RDB 的特点
-
RDB 优点:
- RDB 是一个紧凑压缩的二进制文件,存储效率较高,但存储数据量较大时,存储效率较低
- RDB 内部存储的是 Redis 在某个时间点的数据快照,非常适合用于数据备份,全量复制、灾难恢复
- RDB 恢复数据的速度要比 AOF 快很多,因为是快照,直接恢复
-
RDB 缺点:
- BGSAVE 指令每次运行要执行 fork 操作创建子进程,会牺牲一些性能
- RDB 方式无论是执行指令还是利用配置,无法做到实时持久化,具有丢失数据的可能性,最后一次持久化后的数据可能丢失
- Redis 的众多版本中未进行 RDB 文件格式的版本统一,可能出现各版本之间数据格式无法兼容
AOF 特点:
- AOF 的优点:数据持久化有较好的实时性,通过 AOF 重写可以降低文件的体积
- AOF 的缺点:文件较大时恢复较慢
AOF 和 RDB 同时开启,系统默认取 AOF 的数据(数据不会存在丢失)
应用场景:
-
对数据非常敏感,建议使用默认的 AOF 持久化方案,AOF 持久化策略使用 everysecond,每秒钟 fsync 一次,该策略 Redis 仍可以保持很好的处理性能
注意:AOF 文件存储体积较大,恢复速度较慢,因为要执行每条指令
-
数据呈现阶段有效性,建议使用 RDB 持久化方案,可以做到阶段内无丢失,且恢复速度较快
注意:利用 RDB 实现紧凑的数据持久化,存储数据量较大时,存储效率较低
综合对比:
- RDB 与 AOF 的选择实际上是在做一种权衡,每种都有利有弊
- 灾难恢复选用 RDB
- 如不能承受数分钟以内的数据丢失,对业务数据非常敏感,选用 AOF;如能承受数分钟以内的数据丢失,且追求大数据集的恢复速度,选用 RDB
- 双保险策略,同时开启 RDB 和 AOF,重启后 Redis 优先使用 AOF 来恢复数据,降低丢失数据的量
- 不建议单独用 AOF,因为可能会出现 Bug,如果只是做纯内存缓存,可以都不用
除了RDB快照和AOF日志之外,Redis还提供了混合持久化方式,即同时使用RDB快照和AOF日志。这种方式可以兼顾两者的优点,保证了数据的完整性和灾难恢复的速度。
数据恢复
“借用二哥中的一个流程图”:
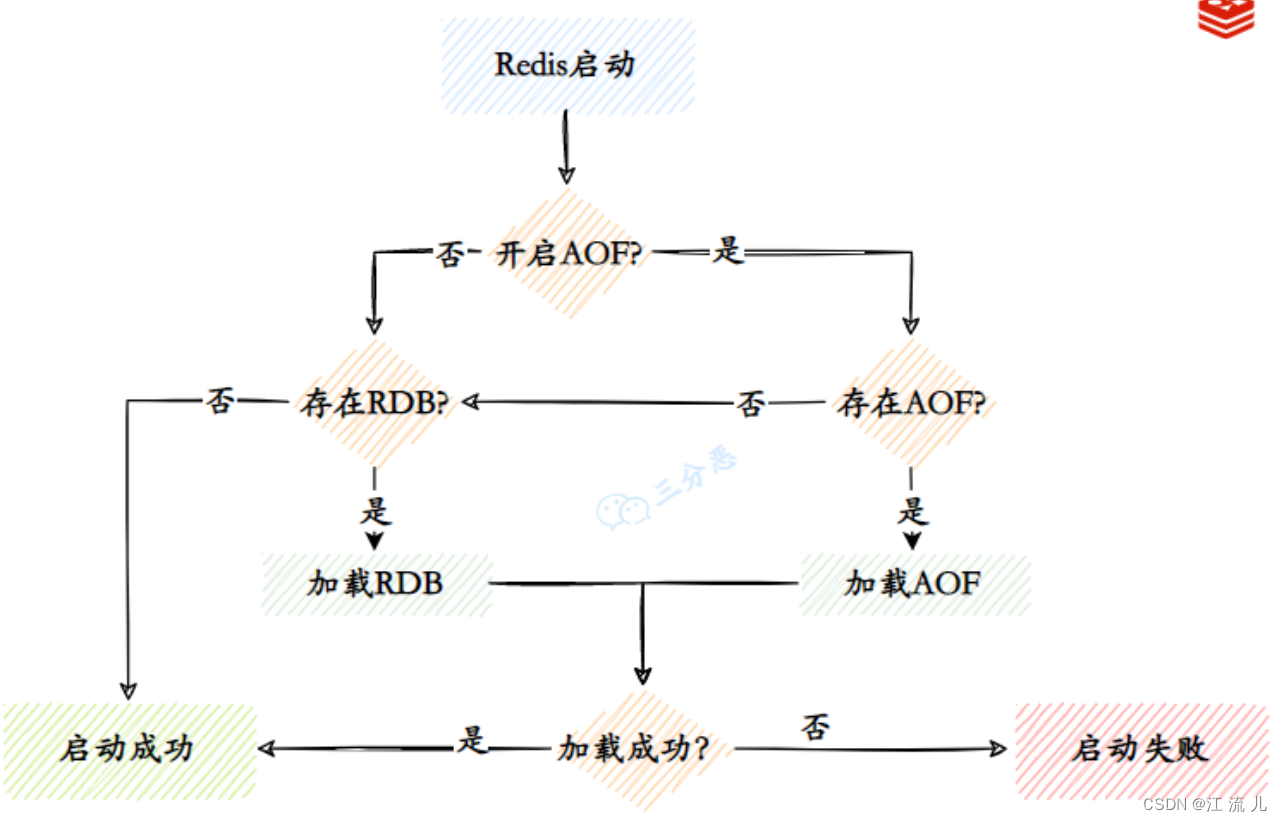
总结
Redis的持久化机制可以保证数据的可靠性和一致性,是必不可少的功能。根据实际需求和场景,我们可以选择合适的持久化方式,并通过一些优化手段来提高性能。正是由于Redis的持久化机制,使得它成为了一种可靠的数据存储和缓存解决方案。