SLAB分配器(slab allocator)
SLAB分配器用于小内存空间管理,基本思想是:先利用页面分配器分配出单个或多个连续的物理页面,然后再此基础上将整块页面分割为多个相等的小内存单元,来满足小内存空间分配的需要。有效地管理这些小的内存单元并保证极高的内存使用速度和效率是非常难的。
关键数据结构
关键成员的含义在注释中解释
kmem_cache
/** Definitions unique to the original Linux SLAB allocator.*/struct kmem_cache {struct array_cache __percpu *cpu_cache;/* 1) Cache tunables. Protected by slab_mutex */unsigned int batchcount;unsigned int limit;unsigned int shared;unsigned int size;struct reciprocal_value reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */slab_flags_t flags; /* constant flags */unsigned int num; /* # of objs per slab *//* 3) cache_grow/shrink *//* order of pgs per slab (2^n) *///该kmem_cache中每个slab占用的页面数量,2^gfporder个unsigned int gfporder;/* force GFP flags, e.g. GFP_DMA *///影响通过伙伴系统寻找空闲页时的行为,GFP Flagsgfp_t allocflags;size_t colour; /* cache colouring range */unsigned int colour_off; /* colour offset */struct kmem_cache *freelist_cache;unsigned int freelist_size;/* constructor func *///构造函数,当在kmem_cache中分配一个新的slab时,用来初始化slab中的所有内存对象void (*ctor)(void *obj);/* 4) cache creation/removal *///该kmem_cache的名字,导出到/proc/slabinfo中const char *name;//将该kmem_cache加入到cache_chain链表中struct list_head list;int refcount;int object_size;int align;/* 5) statistics */
#ifdef CONFIG_DEBUG_SLABunsigned long num_active;unsigned long num_allocations;unsigned long high_mark;unsigned long grown;unsigned long reaped;unsigned long errors;unsigned long max_freeable;unsigned long node_allocs;unsigned long node_frees;unsigned long node_overflow;atomic_t allochit;atomic_t allocmiss;atomic_t freehit;atomic_t freemiss;
#ifdef CONFIG_DEBUG_SLAB_LEAKatomic_t store_user_clean;
#endif/** If debugging is enabled, then the allocator can add additional* fields and/or padding to every object. 'size' contains the total* object size including these internal fields, while 'obj_offset'* and 'object_size' contain the offset to the user object and its* size.*/int obj_offset;
#endif /* CONFIG_DEBUG_SLAB */#ifdef CONFIG_MEMCGstruct memcg_cache_params memcg_params;
#endif
#ifdef CONFIG_KASANstruct kasan_cache kasan_info;
#endif#ifdef CONFIG_SLAB_FREELIST_RANDOMunsigned int *random_seq;
#endifunsigned int useroffset; /* Usercopy region offset */unsigned int usersize; /* Usercopy region size */struct kmem_cache_node *node[MAX_NUMNODES];
};
kmem_cache_node
/** The slab lists for all objects.*/
struct kmem_cache_node {spinlock_t list_lock;#ifdef CONFIG_SLAB//将kmem_cache中所有半空闲的slab加入到该链表中struct list_head slabs_partial; /* partial list first, better asm code *///将kmem_cache中所有已经满员的slab加到该链表中struct list_head slabs_full;//将kmem_cache中所有完全空闲的slab加入到该链表中struct list_head slabs_free;unsigned long total_slabs; /* length of all slab lists */unsigned long free_slabs; /* length of free slab list only */unsigned long free_objects;unsigned int free_limit;unsigned int colour_next; /* Per-node cache coloring */struct array_cache *shared; /* shared per node */struct alien_cache **alien; /* on other nodes */unsigned long next_reap; /* updated without locking */int free_touched; /* updated without locking */
#endif#ifdef CONFIG_SLUBunsigned long nr_partial;struct list_head partial;
#ifdef CONFIG_SLUB_DEBUGatomic_long_t nr_slabs;atomic_long_t total_objects;struct list_head full;
#endif
#endif};
slab
/* Reuses the bits in struct page */
struct slab {unsigned long __page_flags;struct kmem_cache *slab_cache;union {struct {union {struct list_head slab_list;
#ifdef CONFIG_SLUB_CPU_PARTIALstruct {struct slab *next;int slabs; /* Nr of slabs left */};
#endif};/* Double-word boundary */union {struct {void *freelist; /* first free object */union {unsigned long counters;struct {unsigned inuse:16;unsigned objects:15;unsigned frozen:1;};};};
#ifdef system_has_freelist_abafreelist_aba_t freelist_counter;
#endif};};struct rcu_head rcu_head;};unsigned int __unused;atomic_t __page_refcount;
#ifdef CONFIG_MEMCGunsigned long memcg_data;
#endif
};
如何组合使用这些数据结构?
struct kmem_cache和struct slab在一个slab分配器中形成分级管理。
kmem_cache管理者旗下所有的struct slab,它通过三个链表成员
struct list_head slabs_full,表示链表中每一个slab所在的物理内存页面都已经分配完
struct list_head slabs_partial, 表示链表中每一个slab所在的物理内存页面都部分空闲
struct list_head slabs_free, 表示链表中每一个slab所在的物理内存页面都是完全空闲的
将旗下的所有slab实例都加入链表。
各数据结构之间的关系:

struct slab结构用于管理一块连续的物理页面中内存对象的分配。实际存放slab的位置有两种做法:
- 像上图这样,放在起始的物理页面的首部。
- 放在物理页面的外部
宏CFLGS_OFF_SLAB用于表示slab对象存放于外部
kmem_cache之间通过list成员链接起来
cache_cache
每一个slab分配器,都需要一个struct kmem_cache实例,那么,在slab系统尚未完全建立起来时,kmem_cache实例所在的空间从哪里分配?
系统在初始化期间提供了一个特殊的slab分配器kmem_cache_boot,专门用来分配struct kmem_cache空间。
因为kmem_cache_boot在slab系统还未完备时就被创造了出来,所以这个struct kmem_cache结构采用了静态的内存分配方式:
mm/slab.c
/* internal cache of cache description objs */
static struct kmem_cache kmem_cache_boot = {.batchcount = 1,.limit = BOOT_CPUCACHE_ENTRIES,.shared = 1,.size = sizeof(struct kmem_cache),.name = "kmem_cache",
};
.name为kmem_cache,他所领衔的slab分配器,专门用来分配struct kmem_cache这样的内存对象。
.buffer_size = sizeof(struct kmem_cache)其buffersize是kmem_cache结构的大小。
系统在初始化kmem_cache_boot时buddy组件已经完备,所以可以把slab放在页面内部,这个slab分配器就可以工作了(不需要其他分配组件给这个slab寻找内存)。
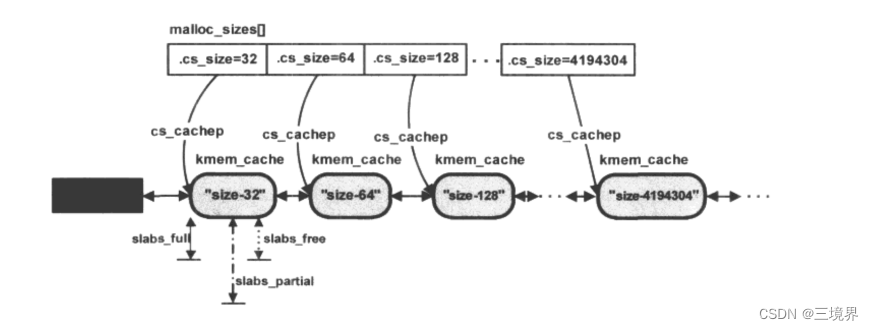
cache_sizes
cache_sizes是实现kmalloc函数的基础
/include/linux/slab_def.h
/* Size description struct for general caches. */
struct cache_sizes {size_t cs_size;struct kmem_cache *cs_cachep;
#ifdef CONFIG_ZONE_DMAstruct kmem_cache *cs_dmacachep;
#endif
};
extern struct cache_sizes malloc_sizes[];
/mm/slab.c
/** These are the default caches for kmalloc. Custom caches can have other sizes.*/
struct cache_sizes malloc_sizes[] = {
#define CACHE(x) { .cs_size = (x) },
#include <linux/kmalloc_sizes.h>CACHE(ULONG_MAX)
#undef CACHE
};
EXPORT_SYMBOL(malloc_sizes);
<linux/kmalloc_sizes.h>文件里包含了所有可支持的slab大小。
在系统初始化期间,内核委托kmem_cache_init函数遍历数组,对应每个元素,都调用kmem_cache_create函数在kmem_cache_boot中分配一个kmem_cache实例
/** Initialisation. Called after the page allocator have been initialised and* before smp_init().*/
void __init kmem_cache_init(void)
{size_t left_over;struct cache_sizes *sizes;struct cache_names *names;int i;int order;int node;if (num_possible_nodes() == 1)use_alien_caches = 0;for (i = 0; i < NUM_INIT_LISTS; i++) {kmem_list3_init(&initkmem_list3[i]);if (i < MAX_NUMNODES)cache_cache.nodelists[i] = NULL;}set_up_list3s(&cache_cache, CACHE_CACHE);/** Fragmentation resistance on low memory - only use bigger* page orders on machines with more than 32MB of memory.*/if (totalram_pages > (32 << 20) >> PAGE_SHIFT)slab_break_gfp_order = BREAK_GFP_ORDER_HI;/* Bootstrap is tricky, because several objects are allocated* from caches that do not exist yet:* 1) initialize the cache_cache cache: it contains the struct* kmem_cache structures of all caches, except cache_cache itself:* cache_cache is statically allocated.* Initially an __init data area is used for the head array and the* kmem_list3 structures, it's replaced with a kmalloc allocated* array at the end of the bootstrap.* 2) Create the first kmalloc cache.* The struct kmem_cache for the new cache is allocated normally.* An __init data area is used for the head array.* 3) Create the remaining kmalloc caches, with minimally sized* head arrays.* 4) Replace the __init data head arrays for cache_cache and the first* kmalloc cache with kmalloc allocated arrays.* 5) Replace the __init data for kmem_list3 for cache_cache and* the other cache's with kmalloc allocated memory.* 6) Resize the head arrays of the kmalloc caches to their final sizes.*/node = numa_mem_id();/* 1) create the cache_cache */INIT_LIST_HEAD(&cache_chain);list_add(&cache_cache.next, &cache_chain);cache_cache.colour_off = cache_line_size();cache_cache.array[smp_processor_id()] = &initarray_cache.cache;cache_cache.nodelists[node] = &initkmem_list3[CACHE_CACHE + node];/** struct kmem_cache size depends on nr_node_ids, which* can be less than MAX_NUMNODES.*/cache_cache.buffer_size = offsetof(struct kmem_cache, nodelists) +nr_node_ids * sizeof(struct kmem_list3 *);
#if DEBUGcache_cache.obj_size = cache_cache.buffer_size;
#endifcache_cache.buffer_size = ALIGN(cache_cache.buffer_size,cache_line_size());cache_cache.reciprocal_buffer_size =reciprocal_value(cache_cache.buffer_size);for (order = 0; order < MAX_ORDER; order++) {cache_estimate(order, cache_cache.buffer_size,cache_line_size(), 0, &left_over, &cache_cache.num);if (cache_cache.num)break;}BUG_ON(!cache_cache.num);cache_cache.gfporder = order;cache_cache.colour = left_over / cache_cache.colour_off;cache_cache.slab_size = ALIGN(cache_cache.num * sizeof(kmem_bufctl_t) +sizeof(struct slab), cache_line_size());/* 2+3) create the kmalloc caches */sizes = malloc_sizes;names = cache_names;/** Initialize the caches that provide memory for the array cache and the* kmem_list3 structures first. Without this, further allocations will* bug.*/sizes[INDEX_AC].cs_cachep = kmem_cache_create(names[INDEX_AC].name,sizes[INDEX_AC].cs_size,ARCH_KMALLOC_MINALIGN,ARCH_KMALLOC_FLAGS|SLAB_PANIC,NULL);if (INDEX_AC != INDEX_L3) {sizes[INDEX_L3].cs_cachep =kmem_cache_create(names[INDEX_L3].name,sizes[INDEX_L3].cs_size,ARCH_KMALLOC_MINALIGN,ARCH_KMALLOC_FLAGS|SLAB_PANIC,NULL);}slab_early_init = 0;//!!! 初始化malloc_sizeswhile (sizes->cs_size != ULONG_MAX) {/** For performance, all the general caches are L1 aligned.* This should be particularly beneficial on SMP boxes, as it* eliminates "false sharing".* Note for systems short on memory removing the alignment will* allow tighter packing of the smaller caches.*/if (!sizes->cs_cachep) {sizes->cs_cachep = kmem_cache_create(names->name,sizes->cs_size,ARCH_KMALLOC_MINALIGN,ARCH_KMALLOC_FLAGS|SLAB_PANIC,NULL);}
#ifdef CONFIG_ZONE_DMAsizes->cs_dmacachep = kmem_cache_create(names->name_dma,sizes->cs_size,ARCH_KMALLOC_MINALIGN,ARCH_KMALLOC_FLAGS|SLAB_CACHE_DMA|SLAB_PANIC,NULL);
#endifsizes++;names++;}/* 4) Replace the bootstrap head arrays */{struct array_cache *ptr;ptr = kmalloc(sizeof(struct arraycache_init), GFP_NOWAIT);BUG_ON(cpu_cache_get(&cache_cache) != &initarray_cache.cache);memcpy(ptr, cpu_cache_get(&cache_cache),sizeof(struct arraycache_init));/** Do not assume that spinlocks can be initialized via memcpy:*/spin_lock_init(&ptr->lock);cache_cache.array[smp_processor_id()] = ptr;ptr = kmalloc(sizeof(struct arraycache_init), GFP_NOWAIT);BUG_ON(cpu_cache_get(malloc_sizes[INDEX_AC].cs_cachep)!= &initarray_generic.cache);memcpy(ptr, cpu_cache_get(malloc_sizes[INDEX_AC].cs_cachep),sizeof(struct arraycache_init));/** Do not assume that spinlocks can be initialized via memcpy:*/spin_lock_init(&ptr->lock);malloc_sizes[INDEX_AC].cs_cachep->array[smp_processor_id()] =ptr;}/* 5) Replace the bootstrap kmem_list3's */{int nid;for_each_online_node(nid) {init_list(&cache_cache, &initkmem_list3[CACHE_CACHE + nid], nid);init_list(malloc_sizes[INDEX_AC].cs_cachep,&initkmem_list3[SIZE_AC + nid], nid);if (INDEX_AC != INDEX_L3) {init_list(malloc_sizes[INDEX_L3].cs_cachep,&initkmem_list3[SIZE_L3 + nid], nid);}}}g_cpucache_up = EARLY;
}
在whille循环里初始化malloc_sizes数组中的每个cache_sizes结构实例,cs_cachep指针指向动态kmem_cache_create函数生成的kmem_cache实例,每个kmem_cache的实例的kmem_cache_node成员里的三条链表,都还没有初始化,即还没有任何slab对象挂上去。直到有内核其他组件调用了kmalloc函数。
kmalloc和kzalloc
kmalloc函数时驱动程序中使用最多的一个内存分配函数,其分配出的内存空间在物理上是连续的。
void *kmalloc(size_t size, gfp_t flags)
这个函数建立在slab分配器基础之上,其实现主要围绕cache_sizes展开。
kmalloc的简洁版本:

根据上层传入的size,在malloc_sizes数组中找一个比size大的最小cs_size,找到一个合适的cache_size后,也就找到了合适的kmem_cache对象cachep,它在上面说的kmem_cache_init中已经初始化过了。
最后调用kmem_cache_alloc来在cachep领衔的slab分配其中执行内存分配。此时会遇到两种情况:
- slab分配器中有空闲的内存对象 --> 返回
- slab分配器中没有空闲的内存对象 --> 利用下层的页面分配器来分配一段新的物理页面,调用链:
a. __cache_alloc()
b. __do_cache_alloc()
c. cache_alloc_refill()
d. cache_grow()
e. kmem_getpages()
f. alloc_pages_exact_node()
g. __alloc_pages()
最终还是调到了页面管理器核心的分配函数__alloc_pages去分配2^orders个连续的物理页面
cache_grow
cache_grpw中,主要是设置对传入的flags再次处理,随后调用kmem_getpages获取物理页面

flags的处理很有意思:
BUG_ON里判断了flags是否带有GFP_SLAB_BUG_MASK,这个宏的定义
/* Do not use these with a slab allocator */
#define GFP_SLAB_BUG_MASK (__GFP_DMA32|__GFP_HIGHMEM|~__GFP_BITS_MASK)
看注释可知,slab分配器不欢迎这种组合的flgs,也即,不能来自高端内存区域和DMA32区域。如果上层传入了他俩的组合,会触发BUG_ON,这个函数差不多是个空操作。
#define BUG_ON(condition) do { if (unlikely(condition)) BUG(); } while (0)
这不是一个严格的惩罚,但是也体现了一个原则,底层的页面分配来自低端物理内存区域。
local_flags也严格践行了这一原则,GFP_CONSTRAINT_MASK和GFP_RECLAIM_MASK这两个宏会清除掉__GFP_DMA32|__GFP_HIGHMEM。以此来调用分配内存,函数最终会返回低端物理物理内存页面说对应的线性内核虚拟地址,而不是vmalloc区或者其他动态映射区的虚拟地址。
最后,仔细检查kmalloc的返回值,如果是NULL则代表没有可用的内存而分配失败了。