文章目录
- 回顾
- Google Net
- Inception
- 1*1卷积
- Inception模块的实现
- 网络构建
- 完整代码
- ResNet
- 残差模块 Resedual Block
- 残差网络的简单应用
- 残差实现的代码
- 练习
回顾
这是一个简单的线性的卷积神经网络
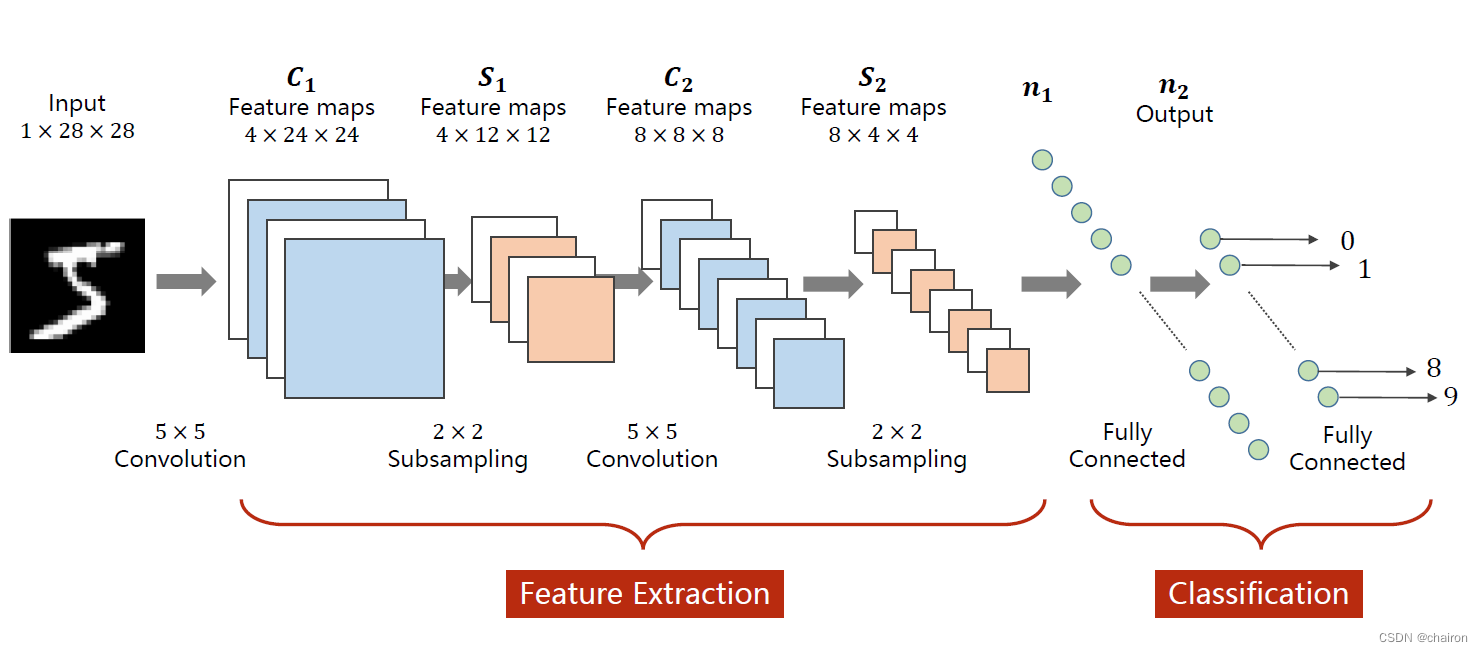
然而有很多更为复杂的卷积神经网络。
Google Net
Google Net 也叫Inception V1,是由Inception模块堆叠而成的卷积神经网络。
详情请见我的另一篇博客

Inception
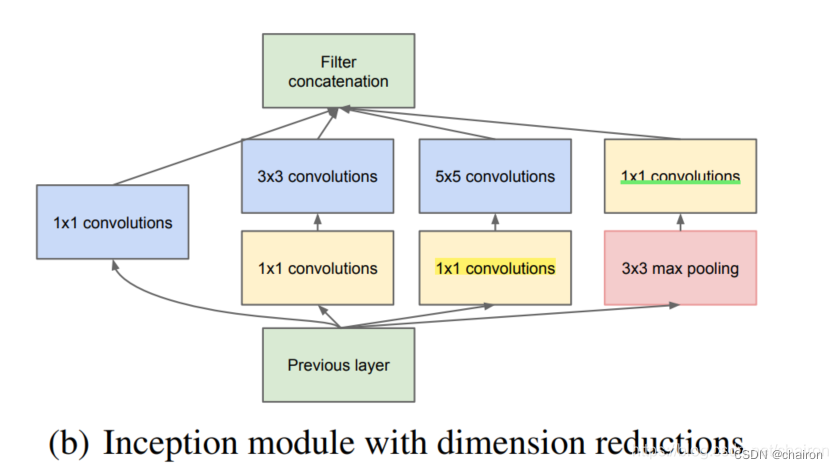
基本思想
- 首先通过1x1卷积来降低通道数把信息聚集
- 再进行不同尺度的特征提取以及池化,得到多个尺度的信息
- 最后将特征进行叠加输出
- (官方说法:可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能)
主要过程: - 在3x3卷积和5x5卷积前面、3x3池化后面添加1x1卷积,将信息聚集且可以有效减少参数量(称为瓶颈层);
- 下一层block就包含1x1卷积,3x3卷积,5x5卷积,3x3池化(使用这样的尺寸不是必需的,可以根据需要进行调整)。这样,网络中每一层都能学习到“稀疏”(3x3、5x5)或“不稀疏”(1x1)的特征,既增加了网络的宽度,也增加了网络对尺度的适应性;
- 通过按深度叠加(deep concat)在每个block后合成特征,获得非线性属性。
- 注:在进行卷积之后都需要进行ReLU激活,这里默认未注明。
1*1卷积
- 1*1卷积:卷积核大小为1的卷积,主要用于改变通道数,而不会改变特征图W、H。
- 也可以用于进行特征融合。
- 在执行计算昂贵的 3 x 3 卷积和 5 x 5 卷积前,往往会使用 1 x 1 卷积来减少计算量。


Inception模块的实现
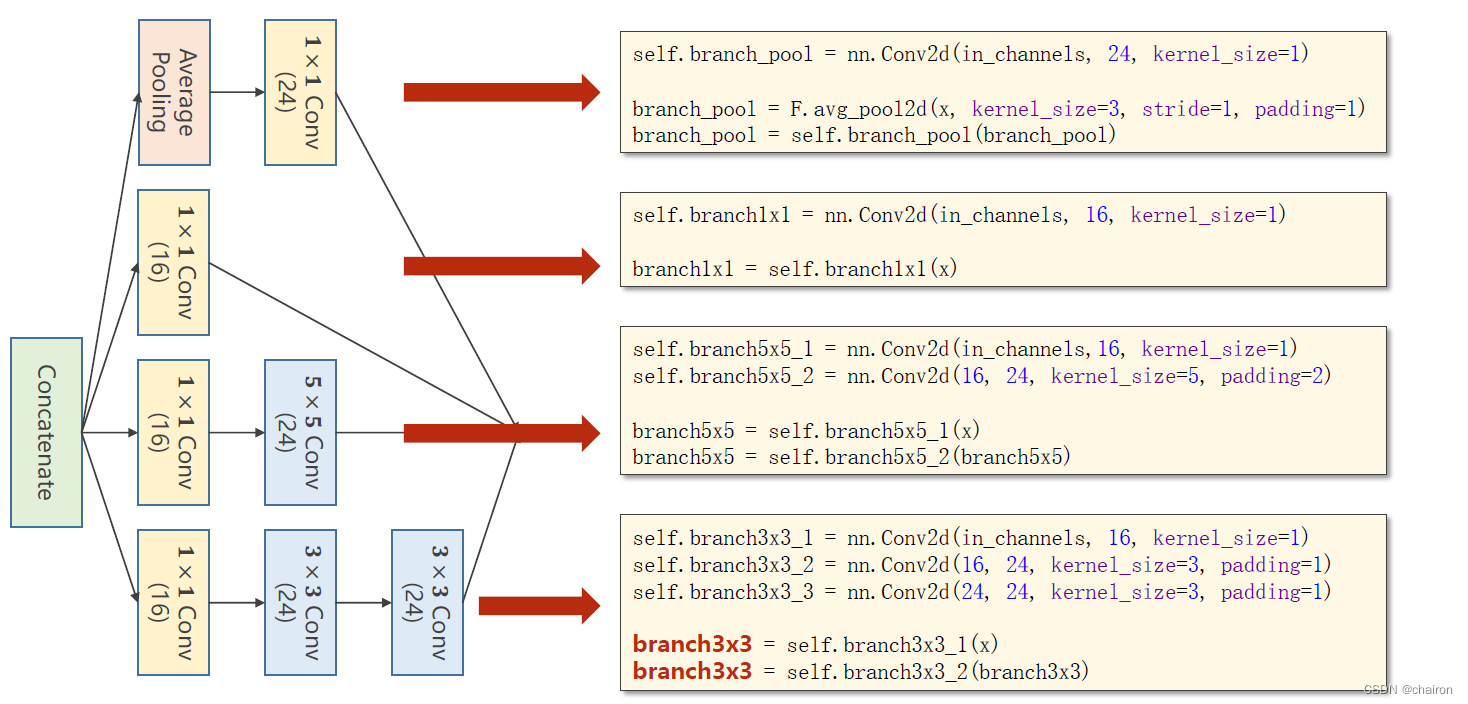
注意:只有所有特征图大小一样(W、H一样),才能进行拼接,通道数可以不同。

网络构建
# design model using class
class InceptionA(nn.Module):def __init__(self, in_channels):super(InceptionA, self).__init__()self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)#1*1卷积self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)#1*1卷积self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)#padding=2,大小不变self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)#1*1卷积self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)#padding=1,大小不变self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)#padding=1,大小不变self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)#1*1卷积def forward(self, x):branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3 = self.branch3x3_1(x)branch3x3 = self.branch3x3_2(branch3x3)branch3x3 = self.branch3x3_3(branch3x3)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch5x5, branch3x3, branch_pool]return torch.cat(outputs, dim=1) # b,c,w,h c对应的是dim=1class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.incep1 = InceptionA(in_channels=10) # 与conv1 中的10对应self.conv2 = nn.Conv2d(88, 20, kernel_size=5) # 88 = 24x3 + 16self.incep2 = InceptionA(in_channels=20) # 与conv2 中的20对应self.mp = nn.MaxPool2d(2)self.fc = nn.Linear(1408, 10)#1408=88*4*4,是x展开之后的值;其实可以不用自己计算def forward(self, x):in_size = x.size(0)x = F.relu(self.mp(self.conv1(x)))#W、H=12x = self.incep1(x)x = F.relu(self.mp(self.conv2(x)))#W、H=4x = self.incep2(x)x = x.view(in_size, -1)x = self.fc(x)return x
完整代码
import numpy as np
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim# prepare datasetbatch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差train_dataset = datasets.MNIST(root='dataset', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='dataset', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design model using class
class InceptionA(nn.Module):def __init__(self, in_channels):super(InceptionA, self).__init__()self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)#1*1卷积self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)#1*1卷积self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)#padding=2,大小不变self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)#1*1卷积self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)#padding=1,大小不变self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)#padding=1,大小不变self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)#1*1卷积def forward(self, x):branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3 = self.branch3x3_1(x)branch3x3 = self.branch3x3_2(branch3x3)branch3x3 = self.branch3x3_3(branch3x3)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch5x5, branch3x3, branch_pool]return torch.cat(outputs, dim=1) # b,c,w,h c对应的是dim=1class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.incep1 = InceptionA(in_channels=10) # 与conv1 中的10对应self.conv2 = nn.Conv2d(88, 20, kernel_size=5) # 88 = 24x3 + 16self.incep2 = InceptionA(in_channels=20) # 与conv2 中的20对应self.mp = nn.MaxPool2d(2)self.fc = nn.Linear(1408, 10)#1408=88*4*4,是x展开之后的值;其实可以不用自己计算def forward(self, x):in_size = x.size(0)x = F.relu(self.mp(self.conv1(x)))#W、H=12x = self.incep1(x)x = F.relu(self.mp(self.conv2(x)))#W、H=4x = self.incep2(x)x = x.view(in_size, -1)x = self.fc(x)return xmodel = Net()device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#定义device,如果有GPU就用GPU,否则用CPUmodel.to(device)
# 将所有模型的parameters and buffers转化为CUDA Tensor.criterion=torch.nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.5)
def train(epoch):running_loss=0.0for batch_id,data in enumerate(train_loader,0):inputs,target=datainputs,target=inputs.to(device),target.to(device)#将数据送到GPU上optimizer.zero_grad()# forward + backward + updateoutputs=model(inputs)loss=criterion(outputs,target)loss.backward()optimizer.step()running_loss +=loss.item()if batch_id% 300==299:print('[%d,%5d] loss: %.3f' % (epoch+1,batch_id,running_loss/300))running_loss=0.0accracy = []
def test():correct=0total=0with torch.no_grad():for data in test_loader:inputs,target=datainputs,target=inputs.to(device),target.to(device)#将数据送到GPU上outputs=model(inputs)predicted=torch.argmax(outputs.data,dim=1)total+=target.size(0)correct+=(predicted==target).sum().item()print('Accuracy on test set : %d %% [%d/%d]'%(100*correct/total,correct,total))accracy.append([100*correct/total])if __name__ == '__main__':for epoch in range(10):train(epoch)test()x=np.arange(10)plt.plot(x, accracy)plt.xlabel("Epoch")plt.ylabel("Accuracy")plt.grid()plt.show()训练结果:
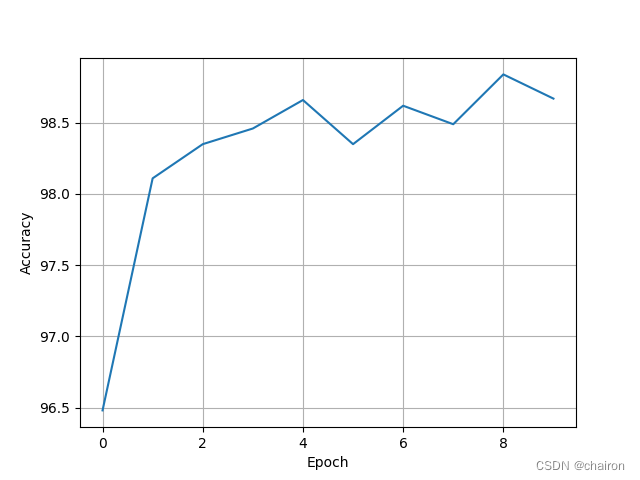
ResNet
卷积层是不是越多越好?
- 在CIFAR数据集上利用20层卷积和56层卷积进行训练,56层卷积的loss还要大一些。
- 这是因为网络层数太多,可能会出现梯度消失和梯度爆炸。
- 梯度消失和梯度爆炸:是在反向传播计算梯度时,梯度太小或者太大,随着网络层数不断加深,梯度值是呈现指数增长,变得趋近于0或者很大。比如说 0. 4 n 0.4^n 0.4n,n=100时,值就已结很小了;比如说 1. 5 n 1.5^n 1.5n,n=100时也非常大了。

残差模块 Resedual Block
**残差连接:
- **很简单!就是一个跳连接,将输入X和卷积之后的特征图相加就行了,即y=x+f(x)。
- 相加需要两个特征图的大小和通道数都一样。
- 可以获得更丰富的语义特征,避免梯度消失和爆炸。
- 非常常用!!!是必须学会的一个小技巧。


残差连接,可以跨层进行跳连接!发挥创造力炼丹吧!

残差网络的简单应用
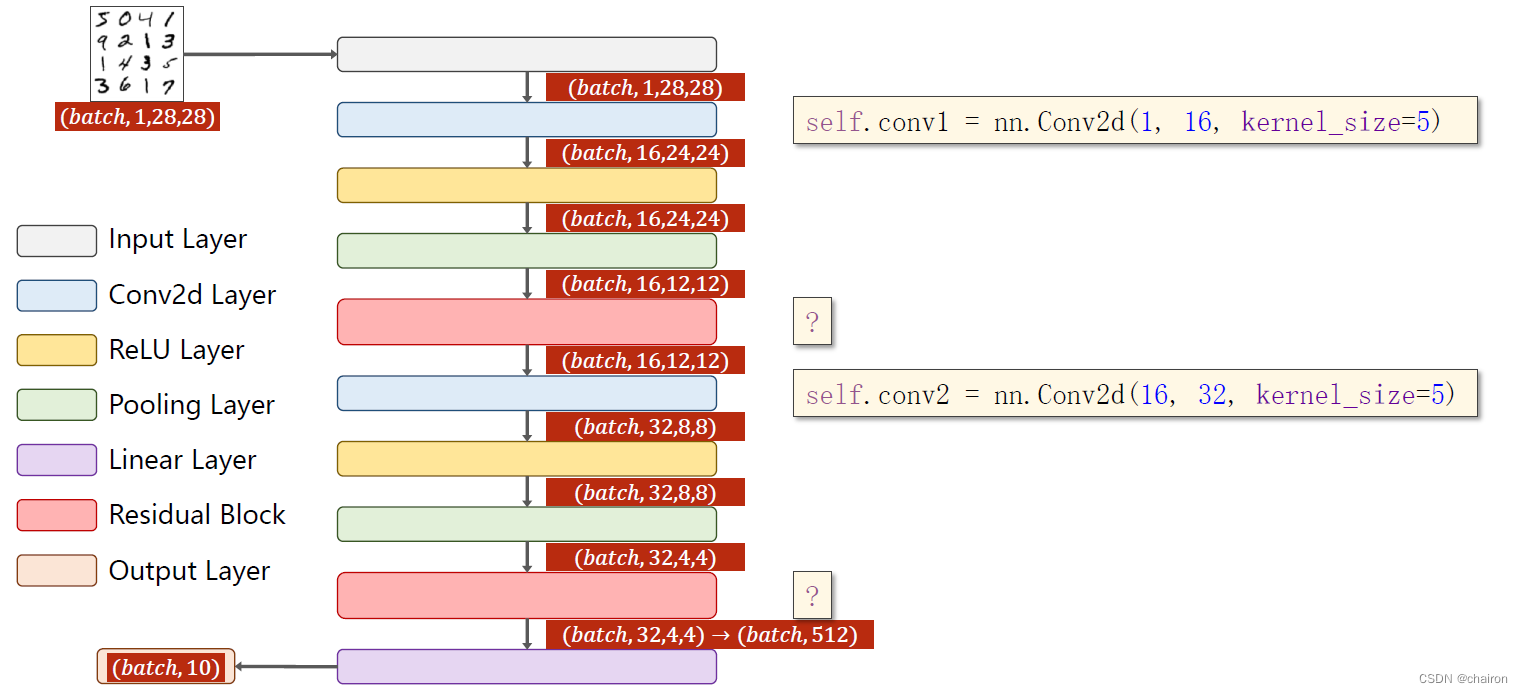
残差实现的代码

class ResidualBlock(torch.nn.Module):def __init__(self,channels):super(ResidualBlock,self).__init__()self.channels=channelsself.conv1=torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)#保证输出输入通道数都一样self.conv2=torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)self.conv3=torch.nn.Conv2d(channels,channels,kernel_size=1)def forward(self,x):y=F.relu(self.conv1(x))y=self.conv2(y)return F.relu(x+y)
接下来,笔交给你了!

我的训练结果:
Accuracy on test set : 98 % [9872/10000]
[7, 299] loss: 0.027
[7, 599] loss: 0.032
[7, 899] loss: 0.032
Accuracy on test set : 98 % [9874/10000]
[8, 299] loss: 0.028
[8, 599] loss: 0.026
[8, 899] loss: 0.026
Accuracy on test set : 99 % [9901/10000]
[9, 299] loss: 0.022
[9, 599] loss: 0.025
[9, 899] loss: 0.027
Accuracy on test set : 99 % [9900/10000]
[10, 299] loss: 0.024
[10, 599] loss: 0.019
[10, 899] loss: 0.027
Accuracy on test set : 98 % [9895/10000]
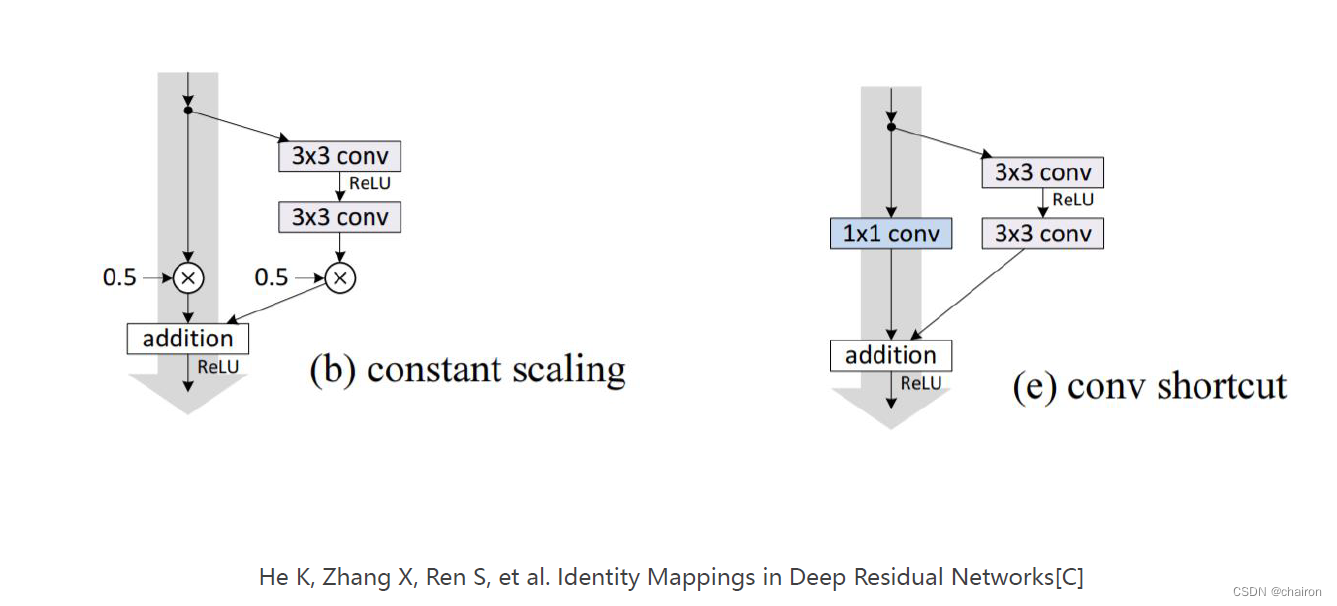
练习
请实现以下两种残差结构,并用他们构建网络跑模型。