1.前言
相 信 很 多 通 过 之 前 摄 像 头 的 基 础 知 识 讲 解 , 已 经 对 车 载 摄 像 头 有 一 定 的 了 解 , 摄 像头 两 大 主 要 功 能 是 定 位 和 感 知 , 我 们 通 过 不 同 的 软 硬 件 来 实 现 前 向 碰 撞 预 警 、 行 人 探 测 与 防撞 预 警 、 车 道 保 持 与 危 险 预 警 、 车 道 偏 离 预 警 、 交 通 标 志 识 别 等 功 能 , 那 么 摄 像 头 在 我 们 现有 汽 车 上 这 些 辅 助 驾 驶 功 能 是 如 何 实 现 的 呢 ?
本 期 整 理 了 一 些 视 觉 传 感 器 相 关 技 术 方 面
的 资 料 , 让 我 们 一 起 来 探 究 一 下 吧
2. 视觉感知概述
目前自动驾驶的视觉感知算法,业内一般分成传统视觉算法和深度学习算法,两者既有着关联,也有着不同点。本期小编通过传统视觉感知的几个关键步骤来为大家讲解,我们下期再聊关于深度学习方面的视觉感知算法。

3. 标 定 及 特 征 提 取
3.1 标 定
标定,是为了帮助摄像头最终成像时获得清晰图像或通过摄像头获得物体大小、测量距离结果准确度所作的软硬件校准及相应算法调试的过程。
标定的精度及算法的稳定性将直接影响摄像头的准确性。
根据摄像头自身产品因素和外部安装因素,自身内部标定简称内参,外部安装的标定简称外参。
3.2 内参
摄像可以用来标定的自身参数称为内参。
内参的参数一般包含镜头畸变,焦距,像素尺寸宽,像素尺
寸高,中心点坐标宽,中心点坐标高,图片尺寸。
下面我们就来探究一下关键的内参值:镜头畸变、光心以及焦距。
3.3 镜头畸变
我们所熟知的摄像头镜头是由几片透镜组成的光学仪器,但是由于透镜的固有特性(凸透镜汇聚光
线、凹透镜发散光线)会导致相机成像存在着透视失真,透视失真也被统称为镜头畸变。
因为这种镜头畸变是物理层面无法消除的,只能改善,所以就需要对镜头畸变进行校准标定。
镜头畸变根据成像效果又分为径向畸变和切向畸变。
径向畸变,被摄物体在经过光学系统成像时,会造成图像点从主点开始沿着径向线发生位移,如下图所示:
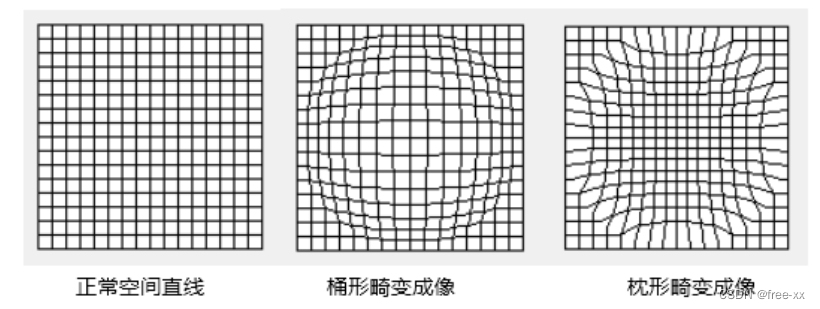
切向畸变,由于装配方面的误差,相机传感器(CMOS或CCD)与光学镜头之间并非完全平行,因此成像存在切向畸变,但在成像方面通常没有径向畸变那么严重。
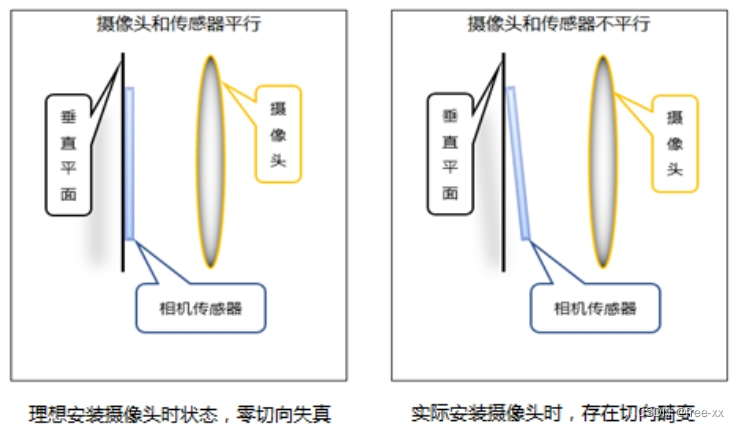
光心,是位于透镜主轴上中央的一个特殊点,凡是通过该点的光,其传播方向不变。通过标定光心的真实位置,才能计算出摄像头的焦点和焦距所在的准确位置。
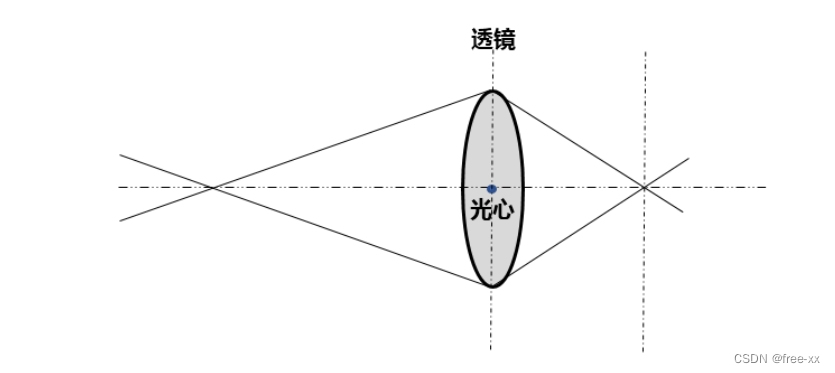
焦距,也称为焦长,以相机为例,焦距是从镜片光心到底片、CCD或CMOS等成像平面的距离。当对同一距离远的同一个被摄目标拍摄时,镜头焦距长的所成的像大,镜头焦距短的所成的像小。标定焦距后的准确度将决定相机最终成像的清晰度和成像大小

3.4 外参
外参标定,是摄像头将自身的位置坐标与被观测物体的现实世界坐标系之间建立相对位置关系。
摄像头不仅需要上述的内部标定,也需要在安装到汽车内后进行外部软硬件联动调试,以确保摄像头的成像效果和物体位置测量距离的准确度
4 传 统 图 像 特 征 提 取
众所周知,计算机是不认识图像的,只认识数字0和1。
为了使计算机能够“理解”图像,从而具有真正意义上的“视觉”,于是我们通过从图像中提取有用的数据或信息,得到图像的“非图像表示或描述”,如数值、向量和符号等,这一过程就是特征提取,而提取出来的这些“非图像表示或描述”就是特征。
有了这些数值或向量形式的特征,再通过建立特征库,我们就可以通过训练过程教会计算机如何懂得这些特征,从而使计算机具有识别图像的本领。
上述的特征提取一般包括点、线,图像分割,光流,机器学习特征,SVM行人车辆识别等要素提取。
看起来挺简单的原理,其实是个十分复杂的过程,曾在《摄像头基础介绍》里面举过一个例子,比如说我们打开搜索网站搜索“桌子”,会发现有很多种的样子。

虽然桌子样式有很多,但是它也是由点、线、面组成的。
计算机为了更好的识别出物体是什么,还会将图片上相同颜色区域进行图像分割,再配合光流变化和机器学习得到的特征要素等,计算机就能识别出图片上的物体是桌子而不是椅子。
目前图像特征的提取主要有两种方法:传统图像特征提取方法和深度学习方法。
传统的特征提取方法:基于图像本身的特征进行提取;
深度学习方法:基于样本自动训练出区分图像的特征分类器;
传统的图像特征提取一般分为三个步骤:预处理、特征提取、特征处理;然后在利用机器学习等方法对特征进行分类等操作。

预处理:预处理的目的主要是排除干扰因素,突出特征信息;主要的方法有:
图片标准化:调整图片尺寸;
图片归一化:调整图片重心为0;
特征提取:
利用特殊的特征子空间,完成对图像的特征提取。
涉及算法主要有:Harris、SIFT、SURF、LBF、HOG、DPM;
特征处理:主要目的是为了排除信息量小的特征,减少计算量等。常见的特征处理方法是降维,常见的降维方法有:主成分分析、奇异值分解、线性判别分析;
Harris算法
是一种角点特征描述子;角点对应于物体图像关键的局部结构特征,通过邻近像素点
灰度差值概念,从而判断是否为角点、边缘、平滑区域。
例如:道路的十字路口等。
SIFT算法尺度不变特征变换(Scale invarialt feature transform)
是基于物体上的一些局部外
观的兴趣点,该算法与影像的旋转、尺度大小缩放、亮度变化无关;对视角变化、仿射变换、噪
声也保持一定程度的稳定性;基于这些特性,SIFT算法在庞大的特征数据库中,很容易辨识出物
体而且鲜有误认。使用SIFT特征描述对于部分物体遮蔽的侦测率也相当高,甚至只需要3个以上
的SIFT物体特征就足以计算出位置与方位。
SURF算法(Speeded Up Robust Features)
直译为:加速版的具有鲁棒特性的特征算法,该算
法对经典的尺度不变特征变换算法(SIFT算法)进行了改进,以更高效的方式改进了特征提取和描
述的方式。SURF算法采用了Haar特征以及积分图像的概念,这大大的加速了程序的运行时间,
需要硬件或者专门的图像处理器进行加速。SURF算法一般应用于计算机视觉中的物体识别、图
像拼接、图像配准以及3D重建中。
HOG算法(Histogram of Oriented Gradient)
方向梯度直方图,是通过计算和统计图像局部区
域的梯度方向直方图来构成特征提取的算法。Hog特征结合SVM(Surpport Vector
Machine)分类器特别适合于做图像中的行人检测。
DPM算法(Deformable Parts Model)
是一个目标检测算法,已成为众多分类器、分割、人体姿
态和行为分类的重要部分。DPM可以看做是HOG算法的扩展,大体思路与HOG一致。先计算梯
度方向直方图,然后用SVM训练得到物体的梯度模型(Model)。有了这样的模板就可以直接用
来分类了,简单理解就是模型和目标匹配。DPM只是在模型上做了很多改进工作。
5. 常 见 视 觉 算 法
VSLAM定位,SLAM(SimultaneousLocalization andMapping)
是同步定位与地图构建,是指根据传感器的信息,一边计算自身位置,一边构建环境地图的过程,解决在未知环境下运动时的定位与地图构建问题。
VSLAM(VisualSLAM算法)
则更为高级,是基于camera图像做SLAM的算法,即视觉的定位与建图,中文也叫视觉SLAM,相当于装上眼睛,通过眼睛来完成定位和扫描,更加精准和迅速。
Sfm(Structurefrom Motion)是一种从运动中实现3D重建。
也就是从时间系列的2D图像中推算3D信息。
用于自动驾驶环境稠密点云重建。
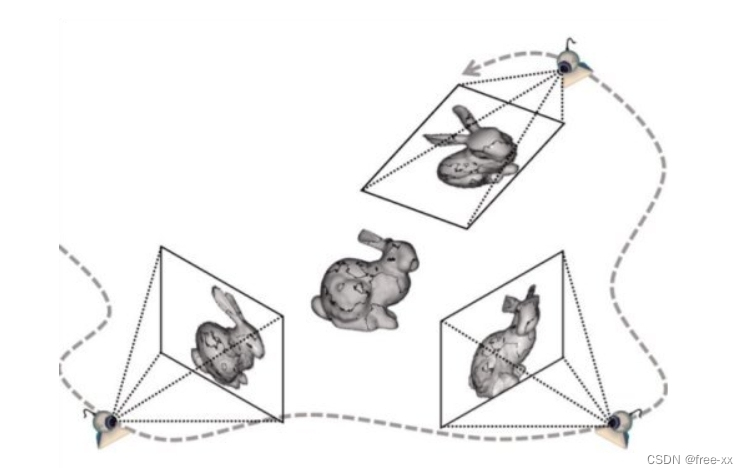
MVS(Multi-viewstereo,多视重建)
立体视觉法将多个相机设置于视点,或用单目相机在多个不同的视点拍摄图像以增加稳健性,通常使用环视摄像头来重建稠密点云。

VADAR(视觉点云,是SFM和MVS统称)
通过VADAR得到和Lidar同样的点云,可以做更多的检测和分割功能。目前特斯拉和mobileyeQ5均使用多个摄像头拍摄的2D图像进行深度学习处理,生成3D模型,从而为自动驾驶决策提供所需的环境信息。说得简单一点,就是依靠算法和芯片的强大计算量,将多个摄像头输出的2D画面“升级”为3D画面实现自动驾驶。
结语
相信通过上述传统摄像头算法的介绍,大家也深深的感受到了单目摄像头视觉传感器要帮助我们行车更加安全、便捷,不是一个容易的事情。
需要通过工程师们对摄像头硬件的标定,各种特征点提取软
件算法,还有芯片、视觉方面的硬件匹配等。
传统单目摄像头视觉算法已经如此的繁琐,那么深度学
习算法又是怎样实现的呢?带着这些问题,下期继续整理深度学习视觉算法相关技术资
料,敬请期待吧!