目录
- 管理 Solr 的 core
- 创建 Core
- 方式1:solr 命令创建
- 演示:使用 solr 命令创建 Core:
- 演示:命令删除 Core(彻底删除)
- 方式2:图形界面创建
- Web控制台创建Core
- Web控制台删除 Core(未彻底删除)
- 重新加回刚刚删除的core
- Core 目录下的文件介绍:
- 创建的 core 对应的目录下的文件:
- Core 目录的 conf 子目录下的文件:
- managed-schema
- solrconfig.xml
- protwords.txt
- stopword.txt
- synonyms.txt
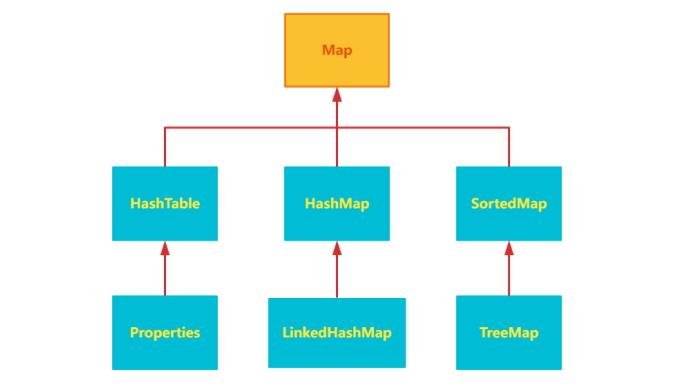
管理 Solr 的 core
管理 Solr 的 core,类似于管理传统的关系型数据库里面的表。
演示怎么创建core、怎么删除core
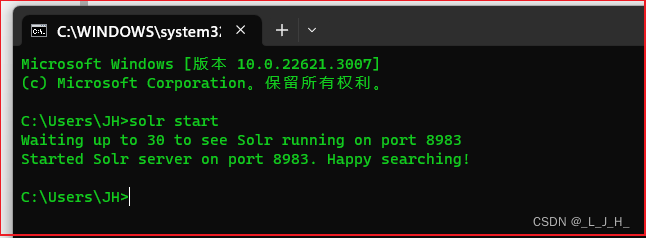
学习之前需要先启动 Solr
执行如下命令即可启动Solr:
solr start -p <端口>
如果不指定端口,Solr 默认的端口是8983
直接输入 solr start 启动就可以了;
显示:在8983端口上启动Solr服务器,等待长达30分钟。寻找快乐!
创建 Core
Solr 使用 Core 保存索引文档,Solr 的 Core 有点类似于 RDBMS 的表。
因此,在正式使用Solr之前,必须先创建Core。
Solr 提供了两种方式来创建 Core:
方式1:使用 solr 命令的 create_core子命令(或用 create子命令也行)创建Core。
Solr所支持的子命令:
create:根据Solr的运行状态选择创建Core或Collection;如果Solr以单机方式运行,该命令创建core;若Solr以云模式运行,该命令创建Collection。
方式2:通过图形界面创建Core。
方式1:solr 命令创建
演示:使用 solr 命令创建 Core:
solr create_core -c ljhCore -d sample_techproducts_configs-c: 指定所创建Core的名字。
-d:指定所创建Core以哪个目录为模板。以 E:\install\Solr\solr-8.11.2\server\solr\configsets 目录下的子目录作为配置模板。
演示:
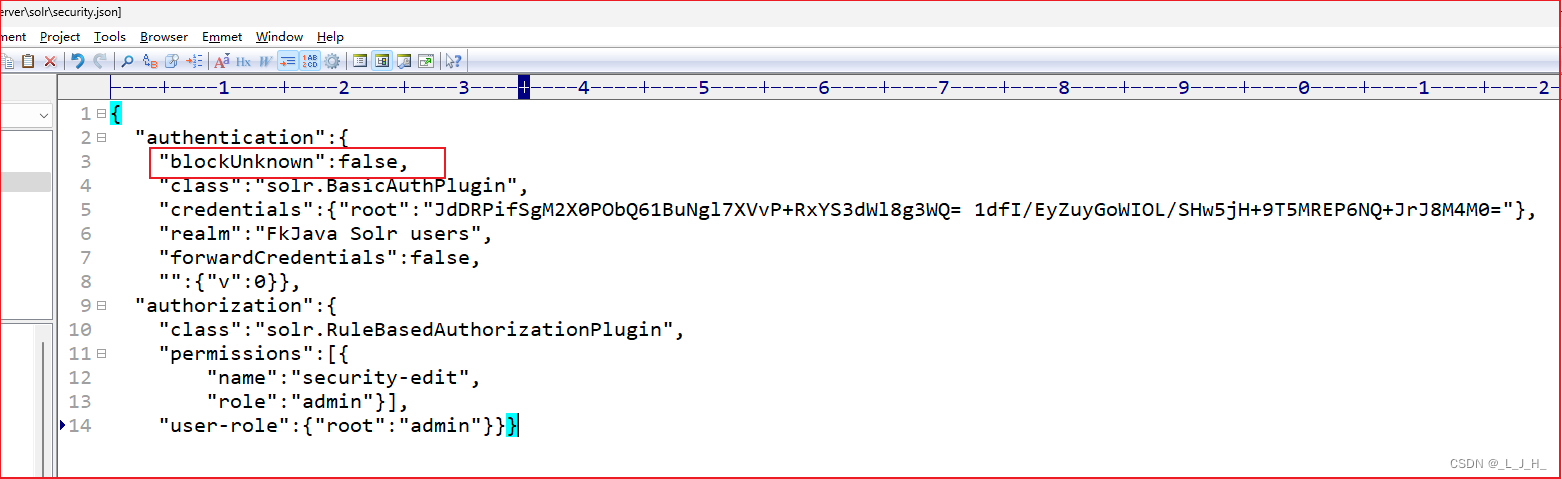
1、先把 security.json 这个配置文件的这个 blockUnknown 属性改为 false ,就是对未知的用户,先不阻塞,可以访问图形管理界面。不然得话,用上面那个命令创建 Core 就会失败。
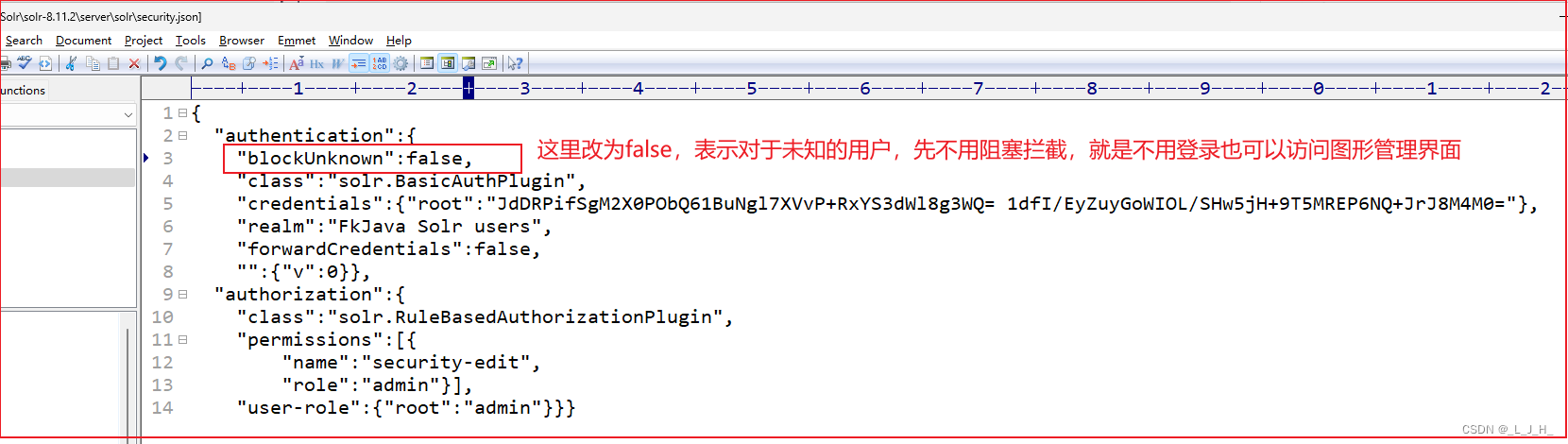
如图:重启之后,可以不用登录,就可以访问这个web图形控制平台。
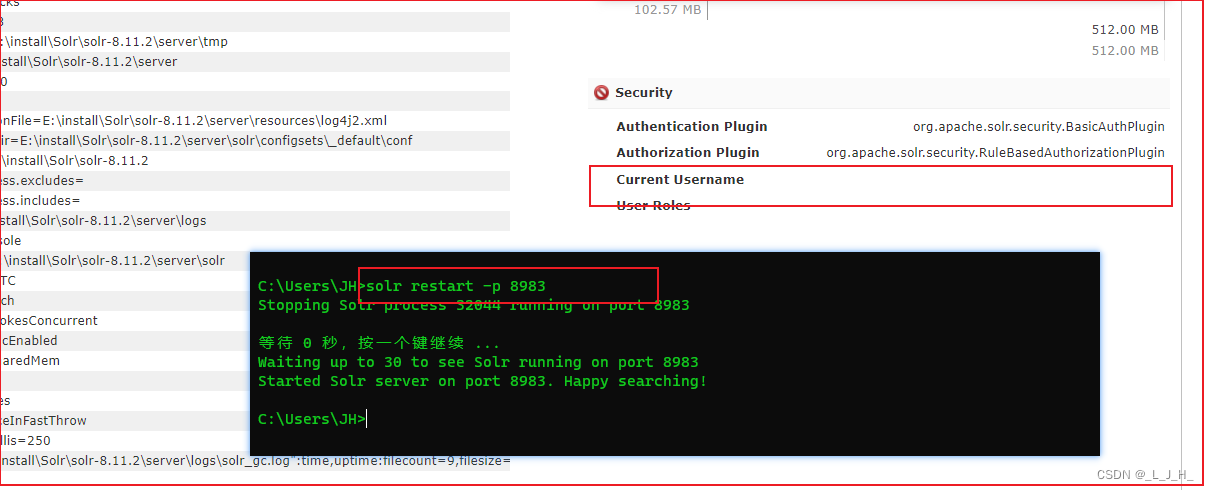
接下来就输入这个命令来创建core
solr create_core -c ljhCore -d sample_techproducts_configs
可以看到,成功创建一个叫 ljhCore 的 core

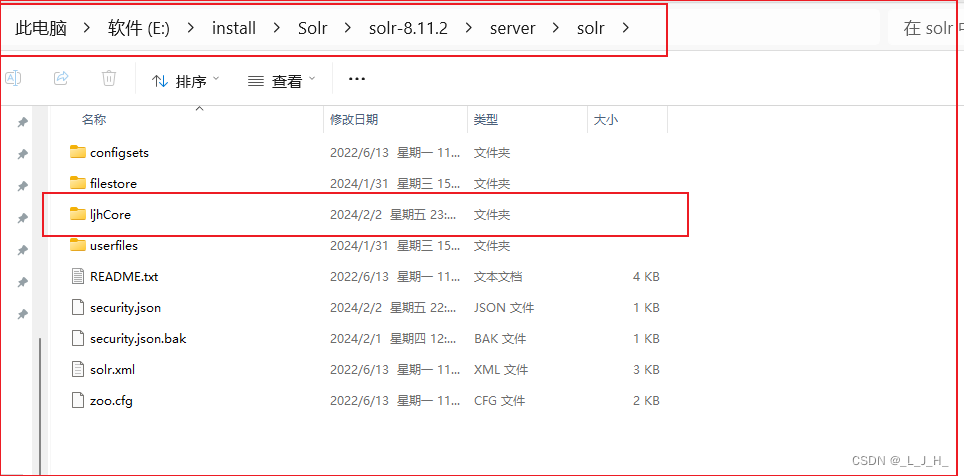
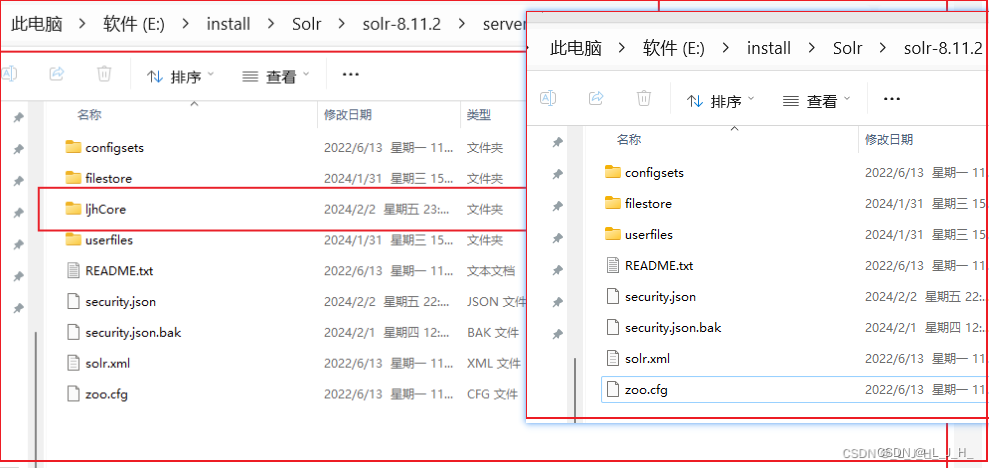
可以看到,创建的 ljhCore 就放在这里
新创建得到的Core保存在: E:\install\Solr\solr-8.11.2\server\solr
- d: 的解释:
自己的话解释 -d sample_techproducts_configs :
简单来说,我创建这个 ljhCore 这个core,也就是逻辑索引库,也叫反向逻辑库,
在通过这个cord 进行全文检索的时候,需要用到各种 solr 的配置文件,而需要用到的这些配置文件,在 _default 和 sample_techproducts_configs 这两个文件夹里面都存在,区别就是 sample_techproducts_configs 文件夹里面的配置文件比_default 文件夹里面的配置文件更多更完善。
所以在创建 ljhCore 这个core 时,就指定了 -d sample_techproducts_configs 这个文件夹,表示到时候这个core需要用到的配置文件,就去这个文件夹里面获取就可以了。
详细解释:
使用 create core 创建 Core 时,需要使用 -d 选项指定配置文件目录。正如前面所言,
Solr 使用 Core 保存索引文档,因此在每个 Core 中都需要配置唯一标识、字段类型、字段、停用词等大量与索引库相关的信息,
这些配置信息需要分别提供各种不同的配置文件。所以Solr 允许通过 -d 选项指定到哪个目录去找配置文件。通俗地说,Solr 每次创建 Core 时都需要大量的配置文件,而 -d 选项就用于指定这些配置模板所在的路径;
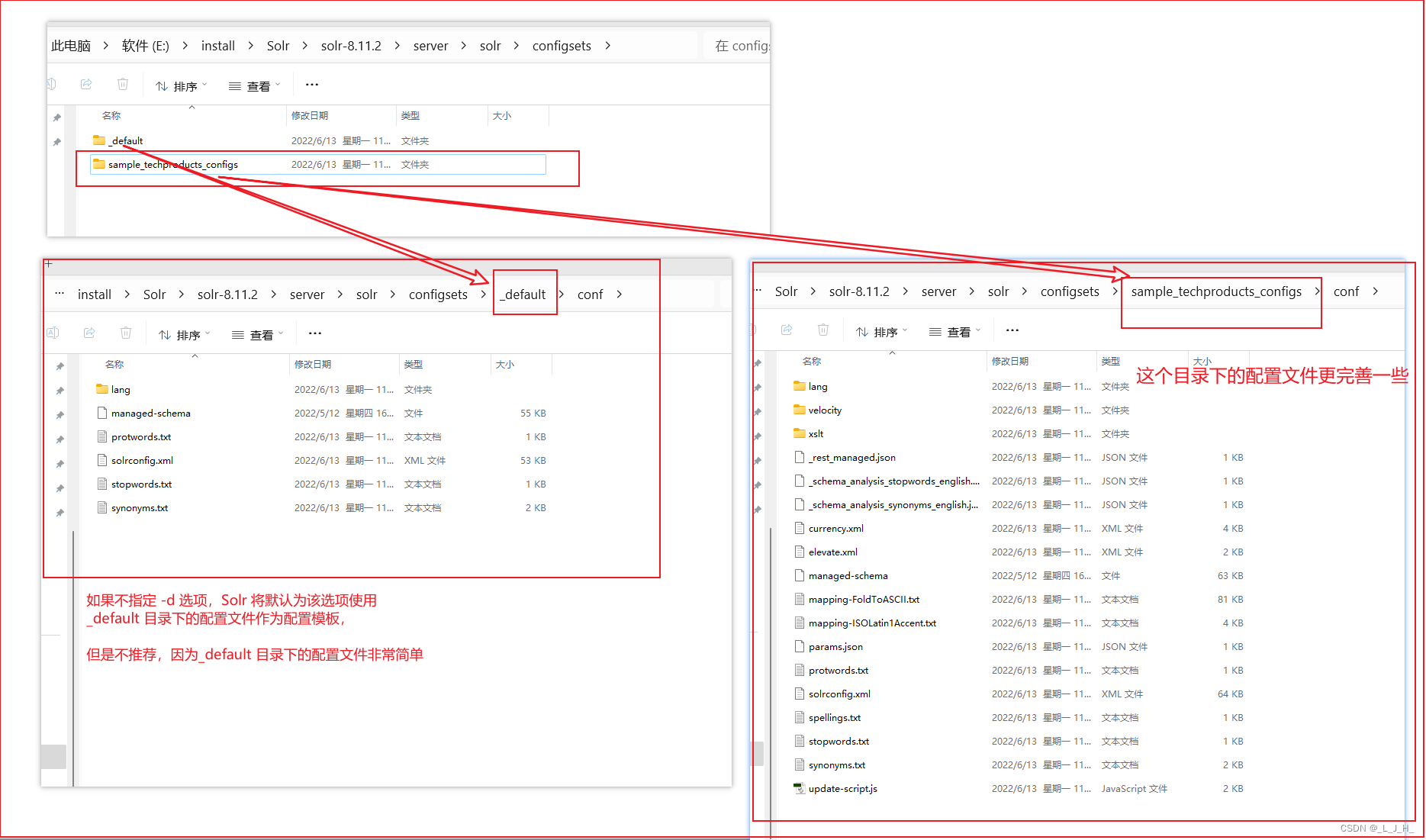
如果不指定 -d 选项,Solr 将默认为该选项使用 _defaut 值,
也就是使用 server\solr\confgsets 路径下 _default 目录下的配置文件作为配置模板。
但不推荐将_default 目录下的配置文件作为产品级的 Core 来使用。在 serversolr\confgsets 路径下还提供了一个 sample_techproducts_confgs 目录,
该目录下的配置文件可作为产品级的 Core 来使用,因此推荐使用该目录作为 Core 配置文件的目录。
演示:命令删除 Core(彻底删除)
命令格式:
solr delete [-c Core名称] [-p 端口]
使用solr命令的create_core子命令创建Core时或delete子命令删除Core时,没有提供选项指定用户名和密码,因此需要先将前面security.json文件中blockUnknown属性设为false,它表示关闭Solr的用户验证功能。
演示:
端口如果不指定,那么就会使用默认的8983端口
输入这个命令来删除刚刚创建的 core
solr delete -c ljhCore
删除 core 成功

刚刚创建的 ljhCore 对应的文件夹目录也看不到,这是彻底删除;
方式2:图形界面创建
Web控制台创建Core
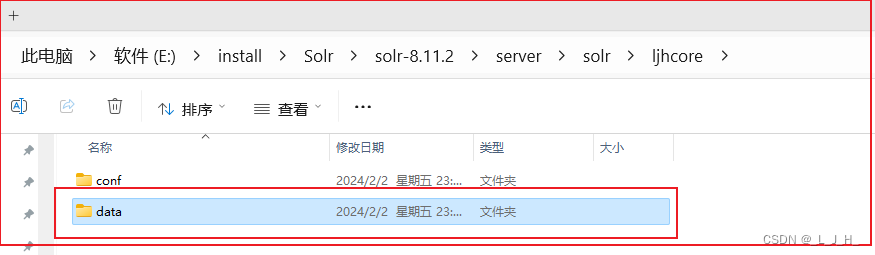
(1)在server\solr路径下创建一个 ljhcore 目录——该目录就是要创建的 Core 所在的目录。
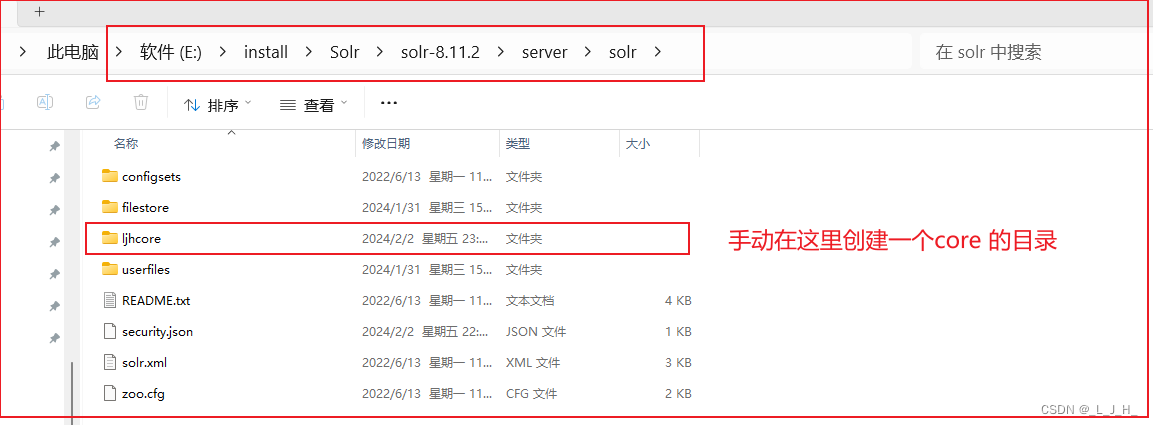
(2)将server\solr\configsets\sample_techproducts_configs 目录内 conf 整个目录(配置文件模板)
复制到第一步创建的 ljhcore 目录中。
(注意:通过这种方式创建Core时,它不会自动生成配置文件,所以需要手动把配置文件复制过来)

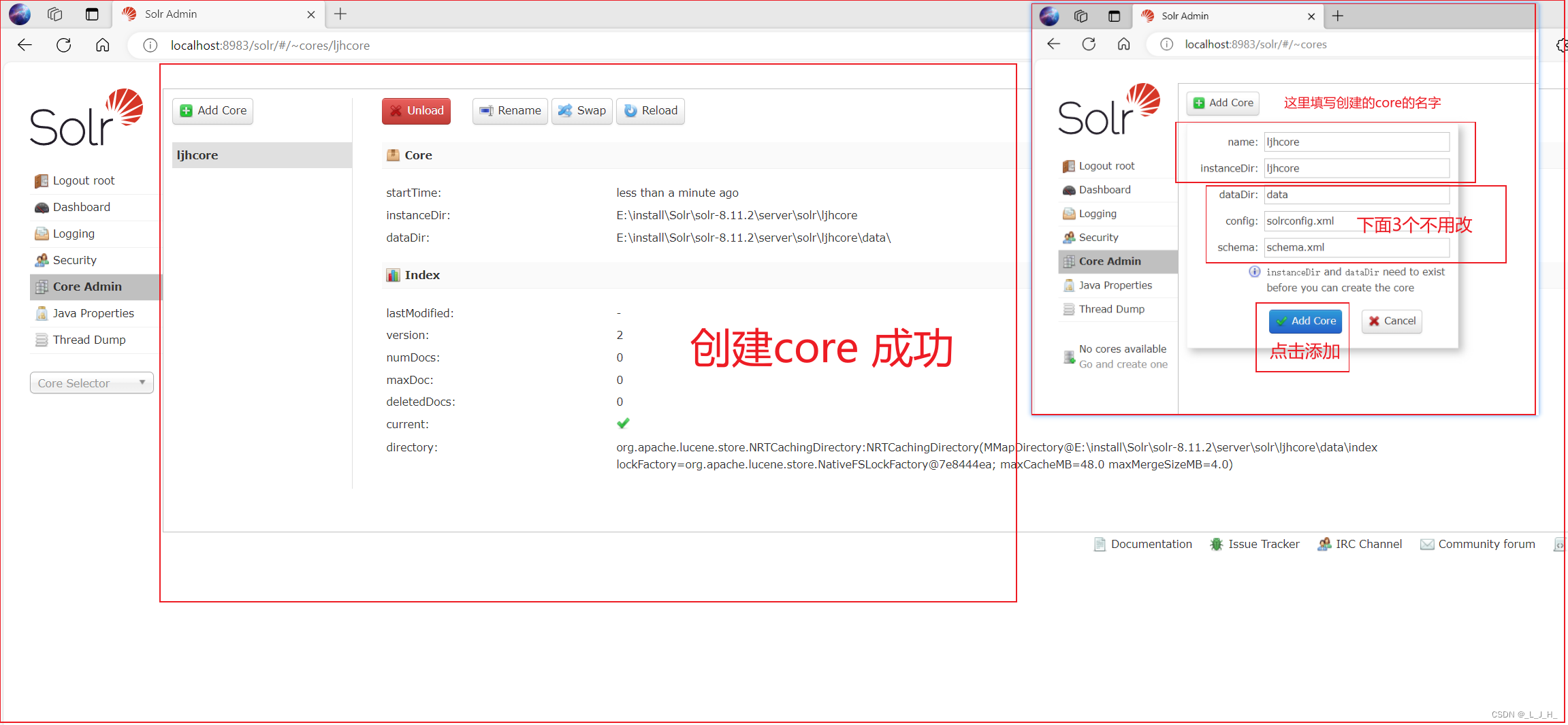
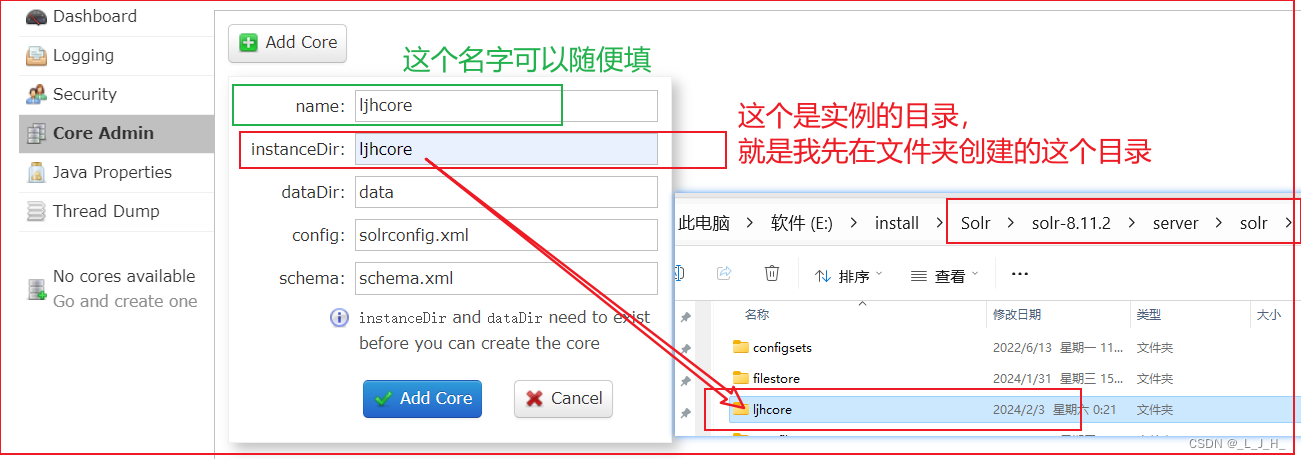
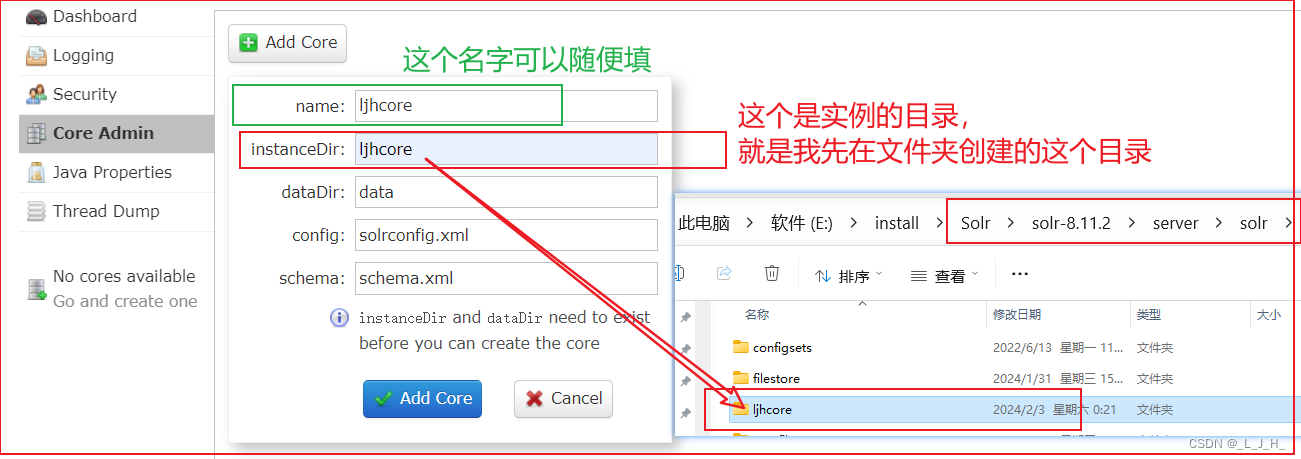
(3)在Web控制台填写 Core 的 name 和 directory 后,然后单击“Add Core”按钮创建Core
——通过这种方式创建Core时,无需关闭 blockUnknown 选项。

如图:创建 core 成功
如图,再看文件夹目录,多出了这些,表示初始化成功。
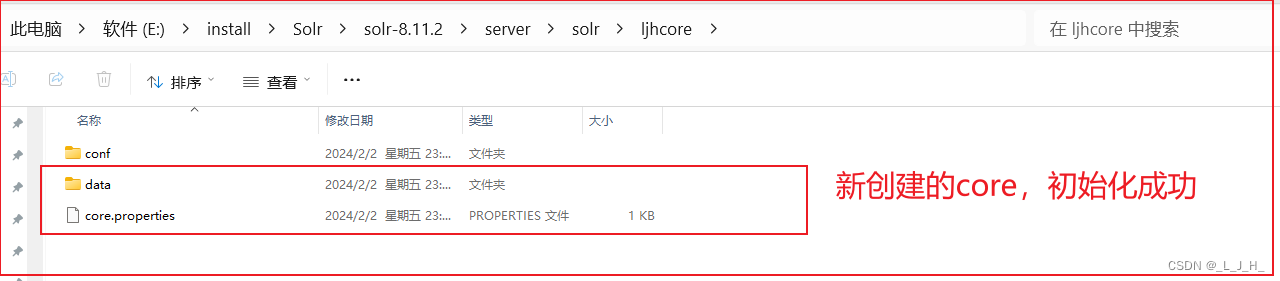
小提示:name 可以随便写,但是实例的目录要对应好
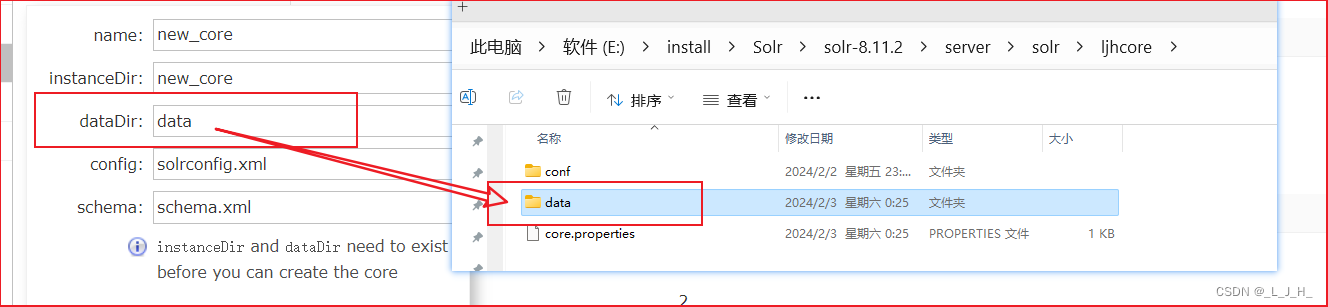
这个 dataDir 这里,名字也可以自己起,我也可以写成 mydata 之类的。
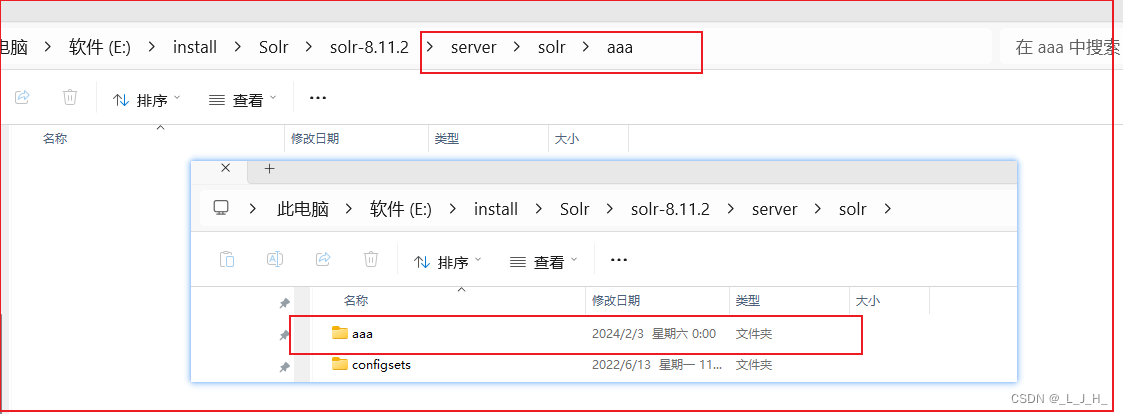
如果不在文件夹先创建core的目录和添加配置文件(conf文件夹),直接在控制台创建,是创建失败的,如图:
我直接创建个aaa,没有在 solr-8.11.2\server\solr 路径下先提前创建 core 的目录和添加配置文件,所以创建失败。
失败原因如图:
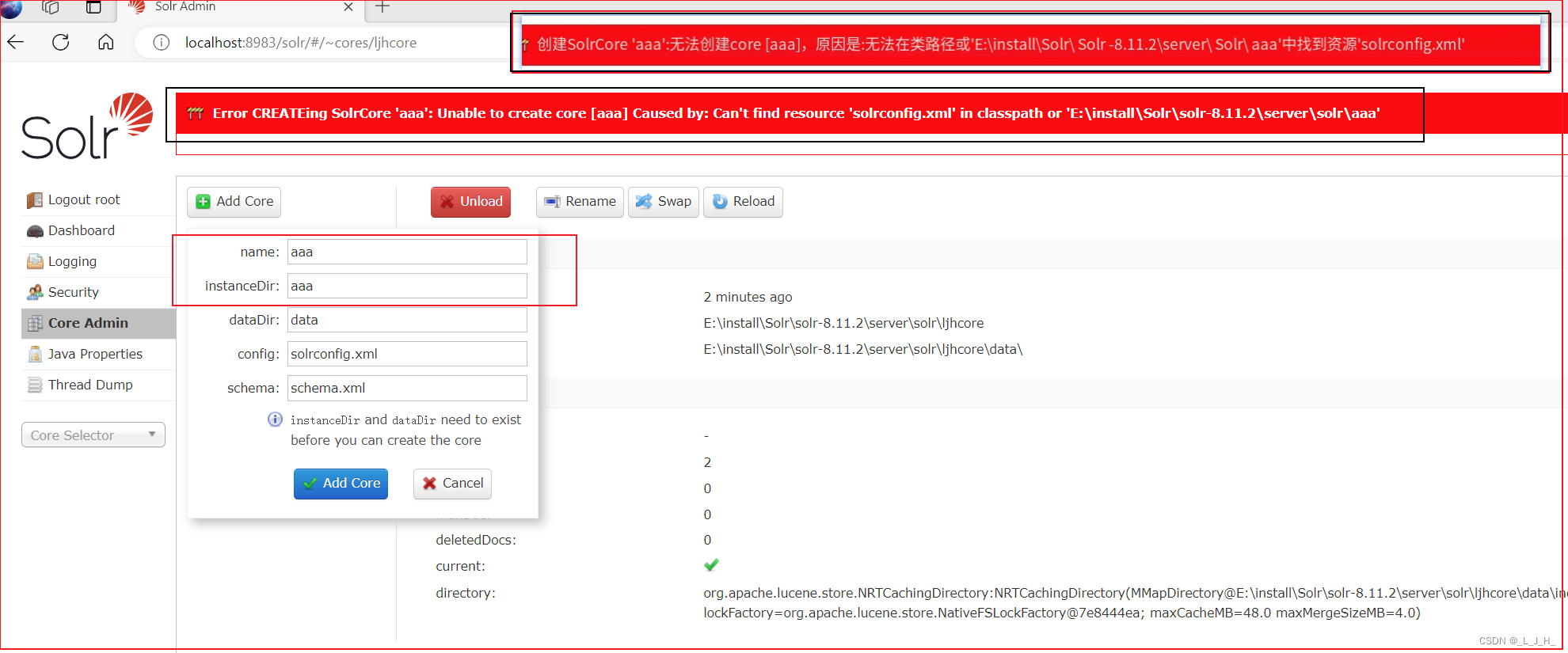
再看下文件夹目录:solr 会自动创建一个 aaa 文件夹,但是里面是空的。
Web控制台删除 Core(未彻底删除)
在Web控制台先选中指定 Core,然后单击该界面上“Unload”按钮即可删除被选中Core。
通过图形界面删除 Core 时,其本质只是卸载。
如图:点击后确认删除
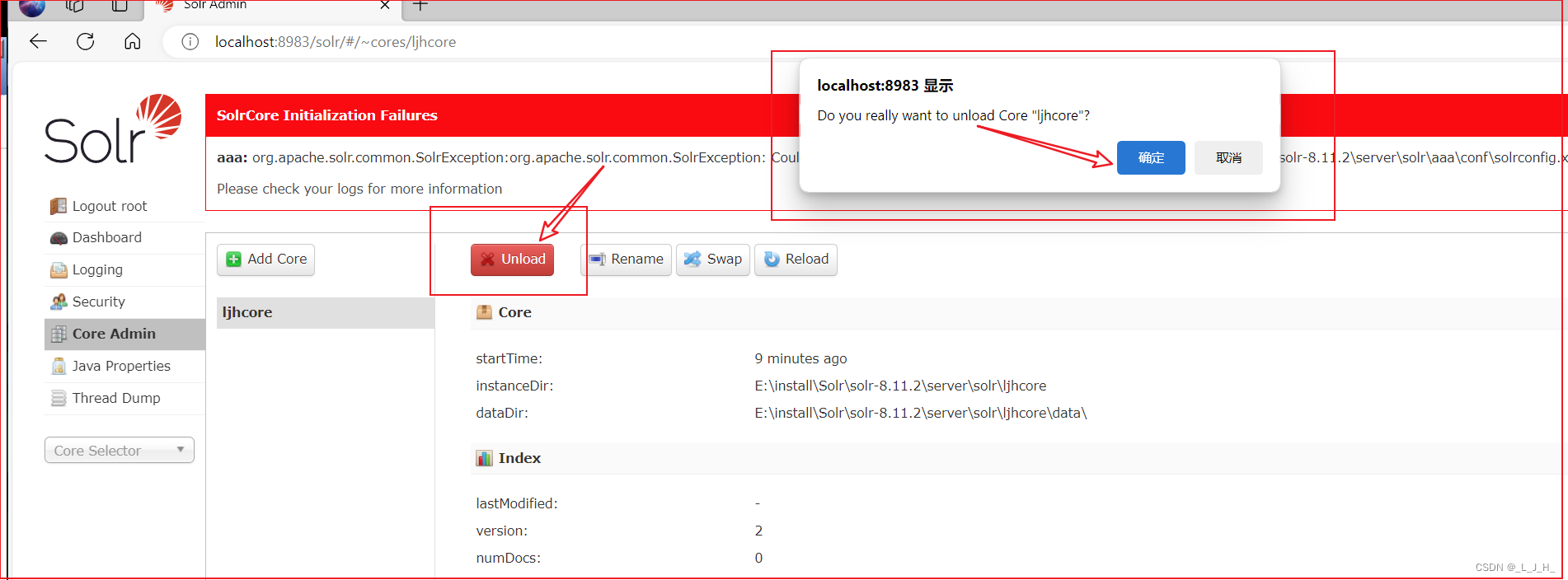
可以看到 core 被成功删除
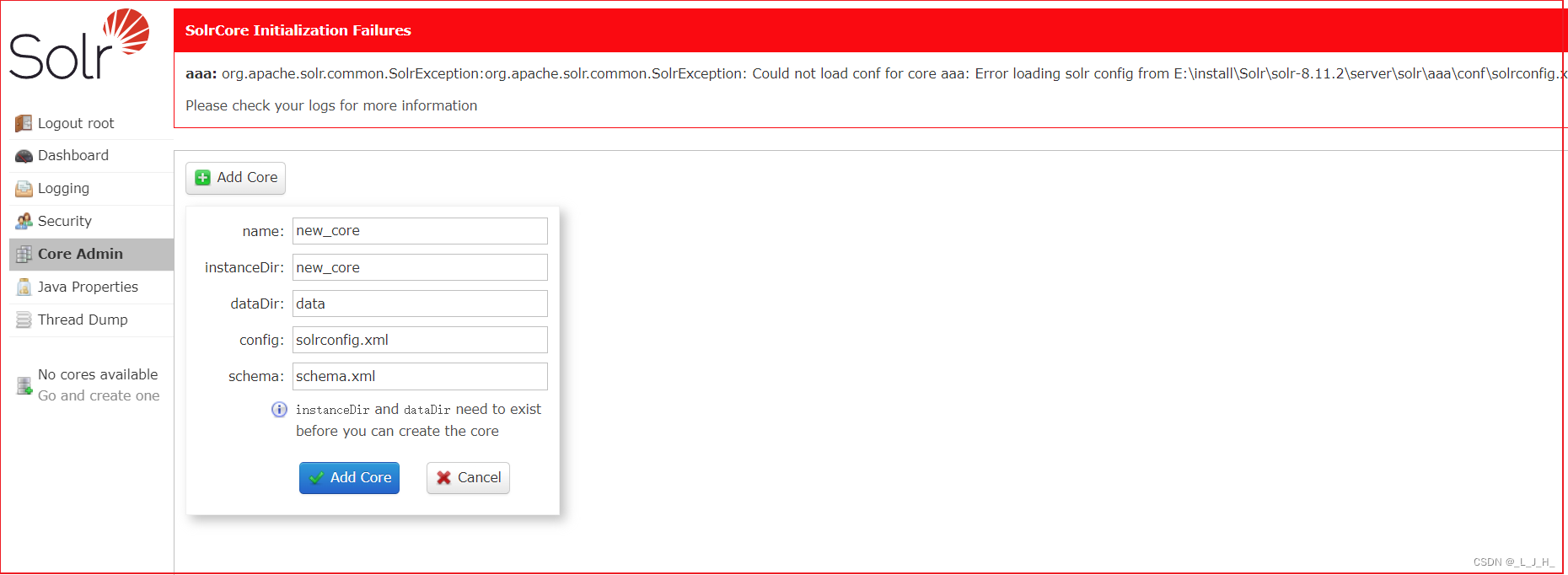
如图:在图形界面删除的core,其实并未彻底删除,一些配置文件还在。
data 文件夹里面是空的。
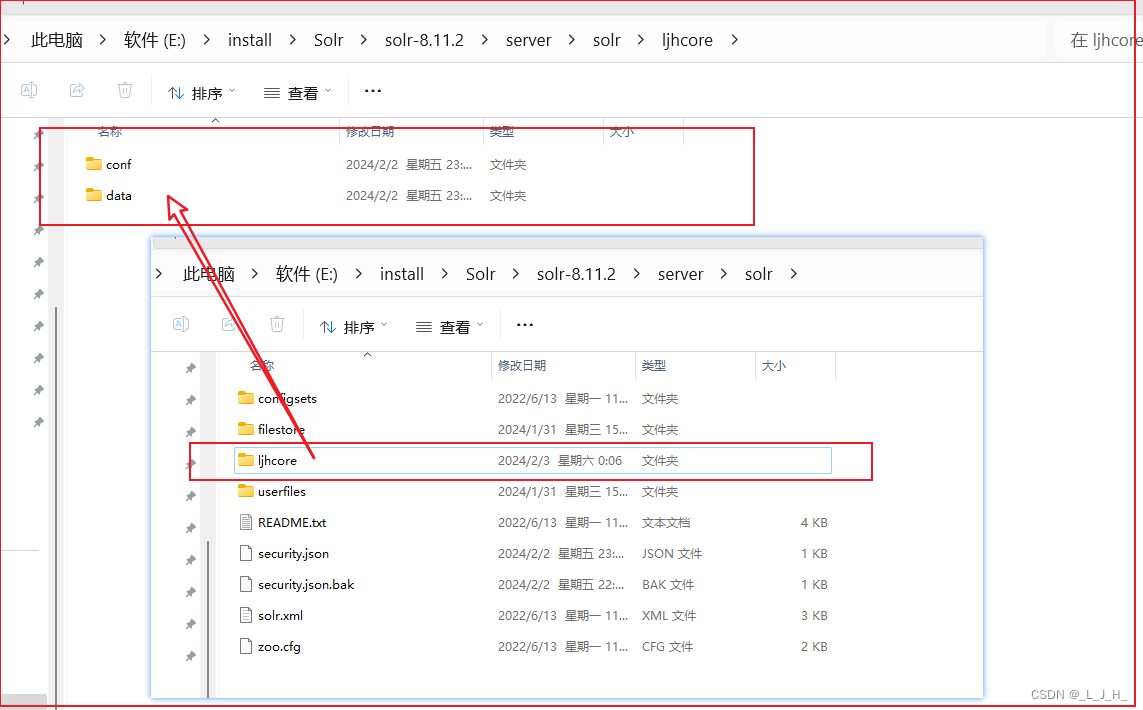
Web控制台删除Core 与 命令行界面 删除Core的区别:
用“solr delete”命令删除Core时,它会把整个Core对应的目录都彻底删除;
当通过图形界面删除 Core 时,它只是将该 Core 从 Solr 系统里删除,并未删除该 Core 对应的目录,因此以后还可重新添加回来。
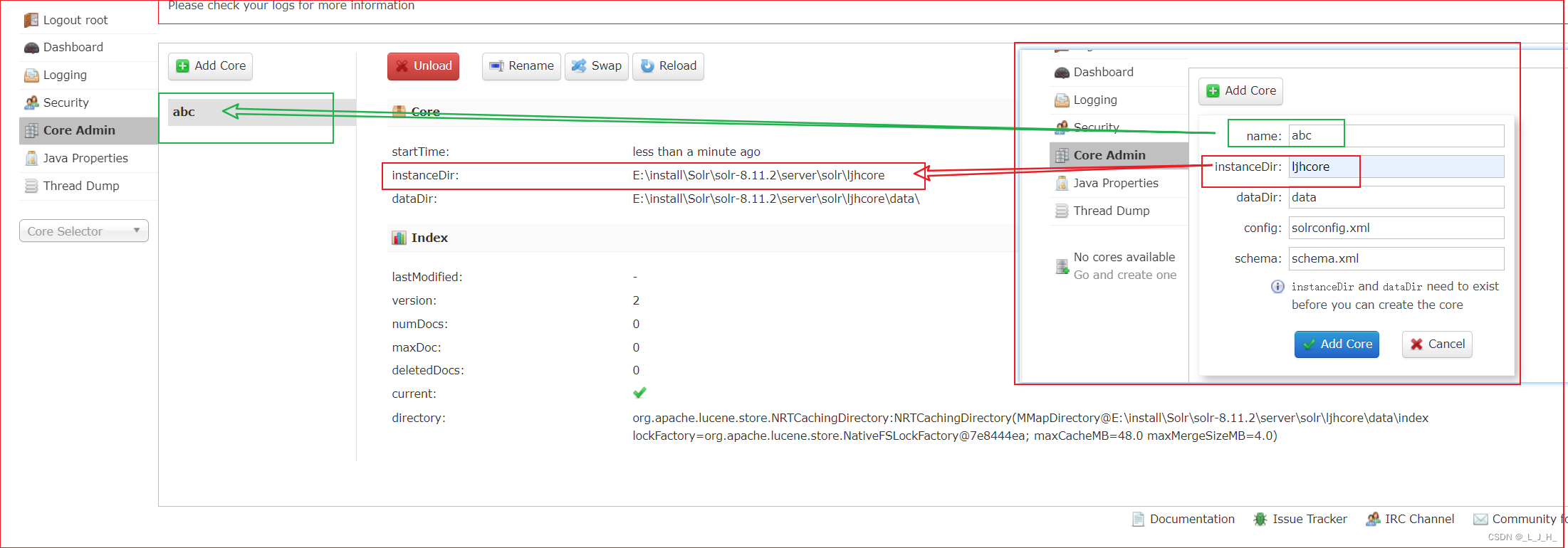
重新加回刚刚删除的core
把 data 文件删除掉
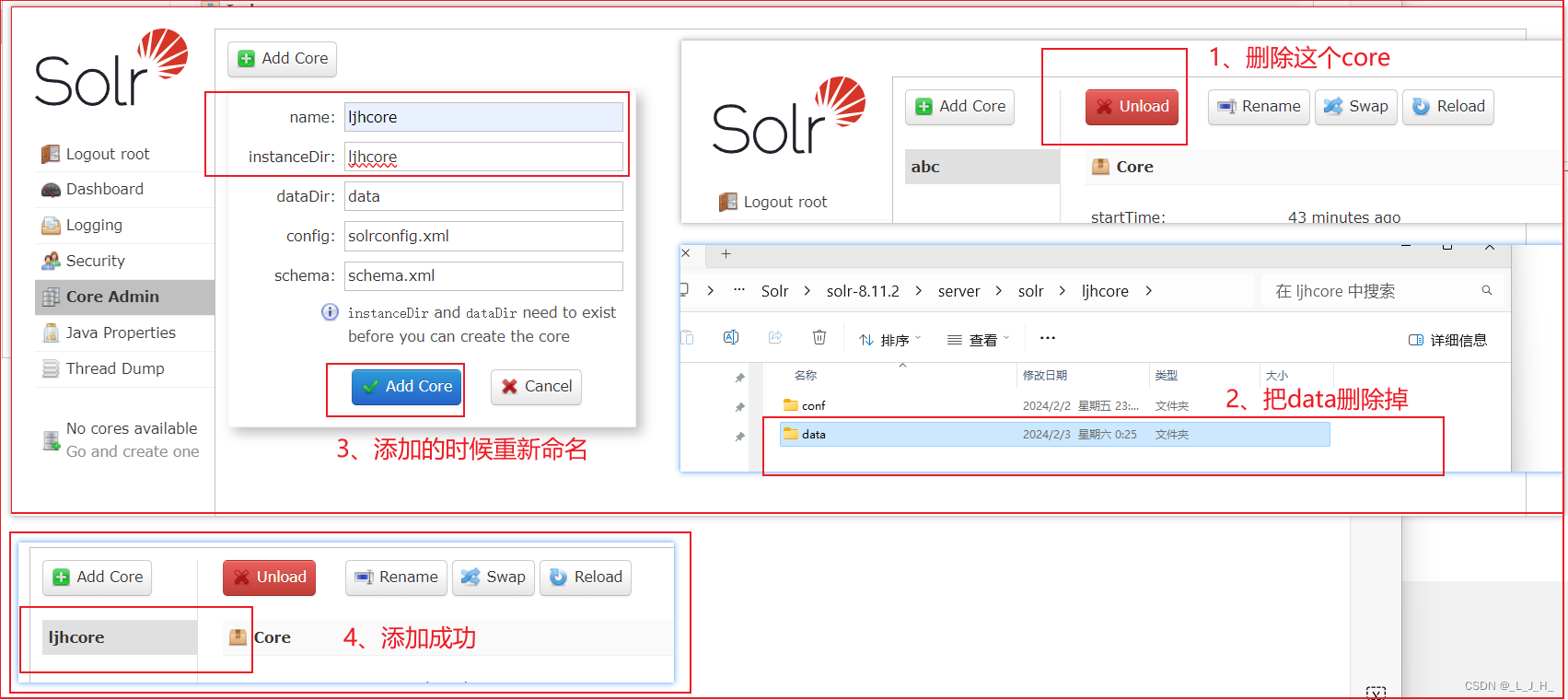
name 我这里随便写写试试看,但是实例的文件夹目录要对应好
重新加回这个core 成功
可以看到这些配置文件都重新加回来了,
删除的时候data文件夹是空的,现在加回来了

如果 abc 这个core 的名字不好听,要重新改的话,那么就在图形界面把这个core删除,重新加回来的时候改个名字就可以了
Core 目录下的文件介绍:
创建的 core 对应的目录下的文件:
- conf:该目录存储该Core的配置信息。
- data(可重命名):保存该Core的索引信息
- core.properties:保存了该Core的名称、dataDir 指定了 core 的索引数据的存储目录。还指定了该core的 schema 配置文件和 config 配置文件。

Core 目录的 conf 子目录下的文件:
在Core目录的conf子目录下可看到如下常见配置文件:
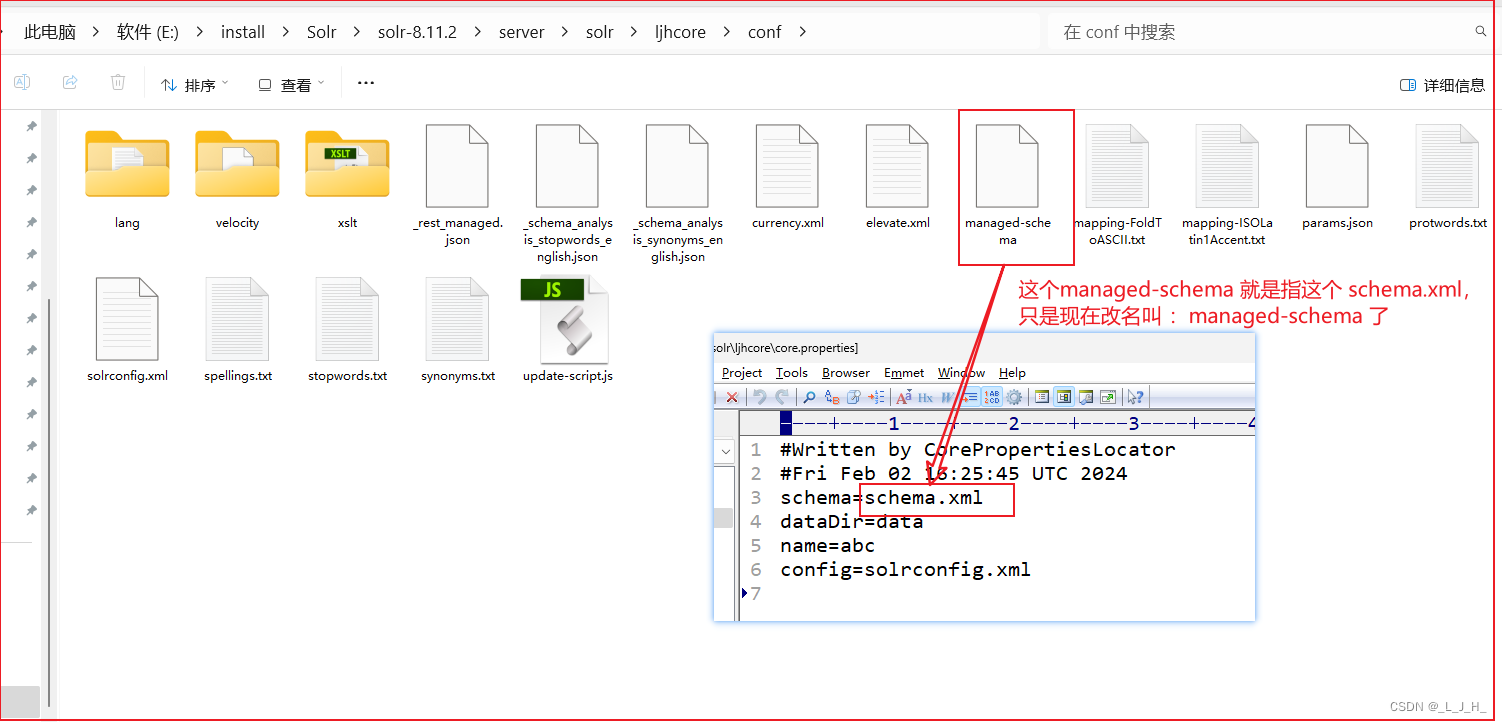
managed-schema
managed-schema(就是以前的schema.xml):定义该Core的整体Schema,包括该Core包括哪些Field类型、哪些Field约束、哪些Field、哪些动态Field、哪些Copy Field。该文件以前的文件名是schema.xml、用户可通过文本编辑器直接编辑它,现在则推荐使用图形界面编辑,这样更安全、有效。
solrconfig.xml
solrconfig.xml:该 Core 的索引库相关配置。

protwords.txt
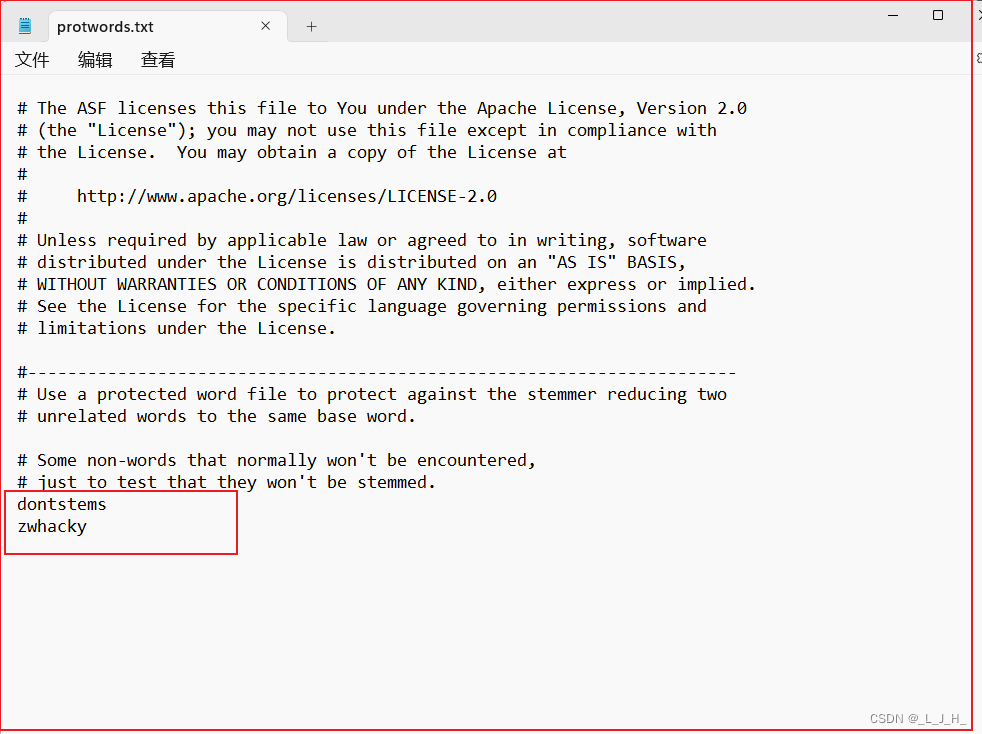
protwords.txt:配置该 Core 额外的保护词。所谓保护词就是停止对该词的 “词干化”,在正常词干化的处理方式下,managing、managed、manageable 这些单词最终都会变成 manage。如果不希望某个单词被词干化,就将该单词添加到此文件中。保存所有的保护词列表。
如图:基本上没有加任何的保护词。
stopword.txt
stopword.txt:配置该 Core 额外的停用词,Lucene 不会对停用词创建反向索引库,因此程序也不能对停用词执行搜索。保存所有的停用词列表。
停用词:比如这句 “ 好吃的鸡腿 ”,这里的 “的” 字就属于停用词,
因为我们如果进行检索的话,只会去检索“好吃”,“好吃的”,“鸡腿”,并不会单独去检索这个 “的” 字,因为没有意义 。
所以 Lucene 不会对 停用词 创建反向索引库
如果我在这里添加 “帅气” 这个词作为停用词,那么 lucene 就不会为这个 “帅气” 创建反向索引库,那么我们在进行全文检索的时候,通过“帅气”这个词来查找时,耗费的时间就会比较长。
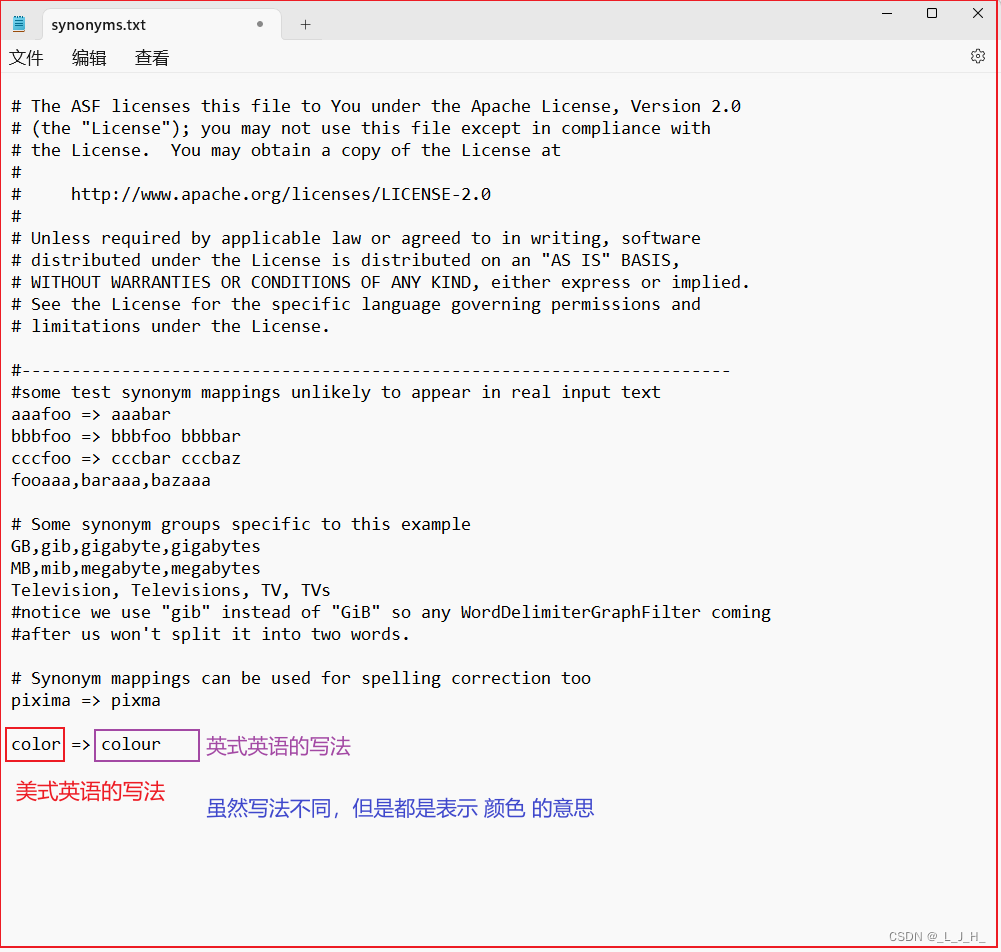
synonyms.txt
synonyms.txt:用于配置该Core的所有同义词。保存了所有的同义词列表。
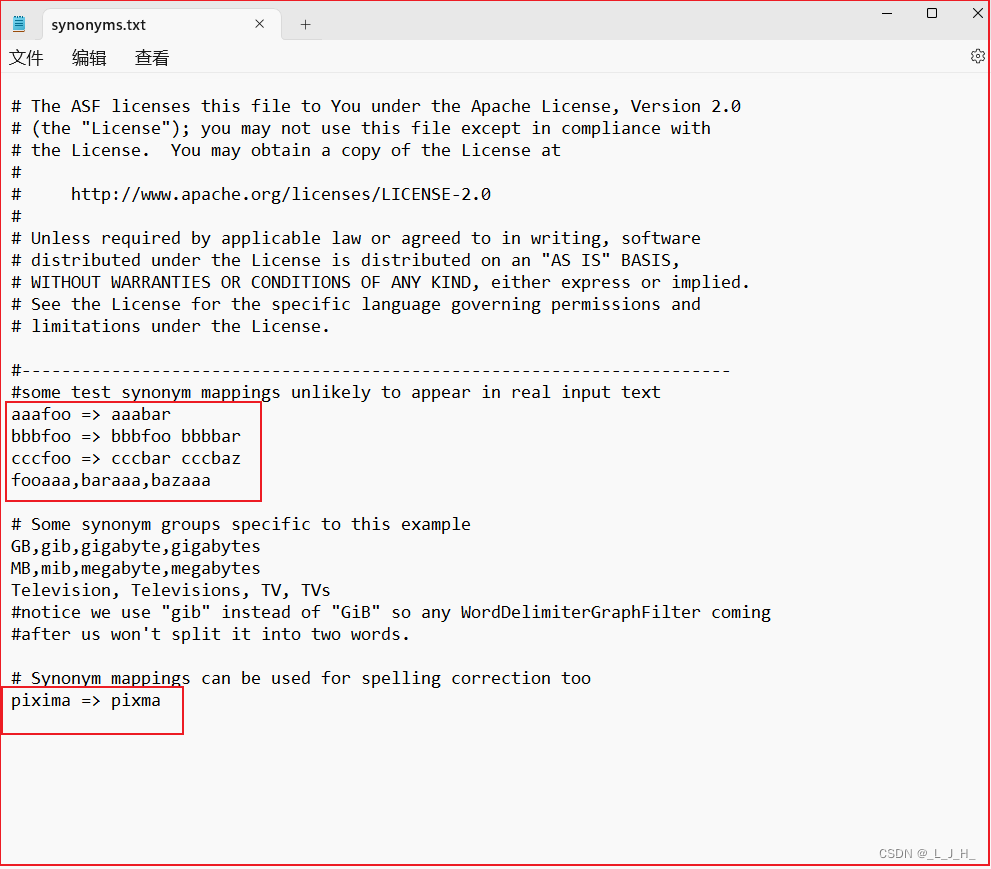
比如: color => colour
color 是美式英语的写法; colour 是英式英语的写法;
但是它们表示的意义都是 “颜色”
当我把 color => colour 添加到 synonyms.txt 这个保存同义词列表的配置文件里面,
那么如果一篇文章里面出现了color 和 colour 这两个词,当我们在查找 color 的时候,这个 colour 也应该被查找出来,反之也是。
把 color => colour 添加到 synonyms.txt,相当于把 color 和 colour 当成同一个词。