文章目录
- 一、新增方式1:实现Callable接口
- (1)介绍
- (2)案例
- (3)总结对比
- 二、新增方式2:使用线程池
- (1)问题与解决思路
- 1、现有问题
- 2、解决思路
- 3、好处
- (2)线程池相关API
- (3)案例
一、新增方式1:实现Callable接口
(1)介绍
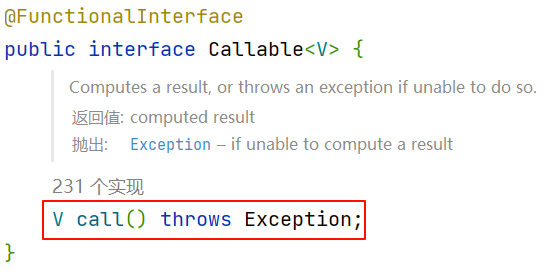
【Callable接口】
@FunctionalInterface
public interface Callable<V> {/*** Computes a result, or throws an exception if unable to do so.** @return computed result* @throws Exception if unable to compute a result*/V call() throws Exception;
}
<>是泛型的意思,V决定了call()方法返回值的类型。
- 与使用
Runnable相比,Callable功能更强大些- 相比
run()方法,可以有返回值。 - 方法可以抛出异常。
- 支持泛型的返回值(需要借助FutureTask类,获取返回结果)。
- 相比
Future接口(了解)- 可以对具体Runnable、Callable任务的执行结果进行取消、查询是否完成、获取结果等。
- FutureTask是Futrue接口的唯一的实现类。
- FutureTask 同时实现了Runnable, Future接口。它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值。
- 缺点:在获取分线程执行结果的时候,当前线程(或是主线程)受阻塞,效率较低。
(2)案例
【步骤】
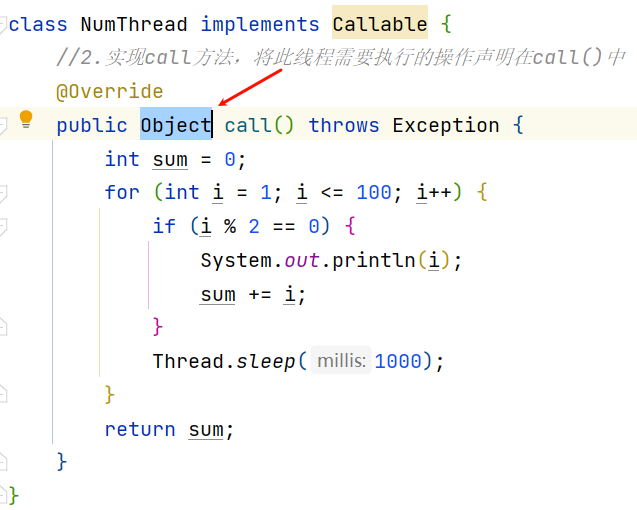
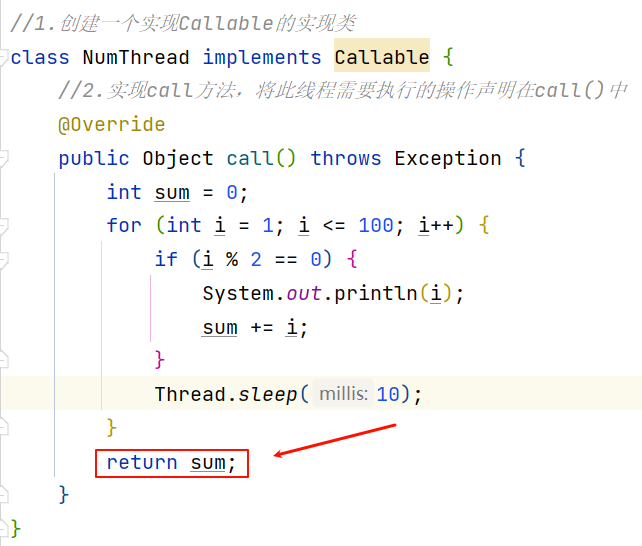
1、创建一个实现Callable的实现类。
2、实现call方法,将此线程需要执行的操作声明在call()中。
3、创建Callable接口实现类的对象。
4、将此Callable接口实现类的对象作为参数传递到FutureTask构造器中,创建FutureTask的对象。
5、将FutureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start()。
6、获取Callable中call方法的返回值。
【案例】
🌱代码
package yuyi04.callable;import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask;/*** ClassName: Callable* Package: yuyi04.callable* Description:* 创建多线程的方式三:实现Callable (jdk5.0新增的)* @Author 雨翼轻尘* @Create 2024/2/3 0003 13:59*///1.创建一个实现Callable的实现类
class NumThread implements Callable {//2.实现call方法,将此线程需要执行的操作声明在call()中@Overridepublic Object call() throws Exception {int sum = 0;for (int i = 1; i <= 100; i++) { //遍历100以内的偶数if (i % 2 == 0) {System.out.println(i);sum += i; //计算100以内偶数的和}Thread.sleep(1000);}return sum;}
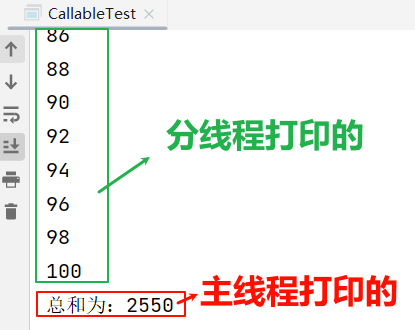
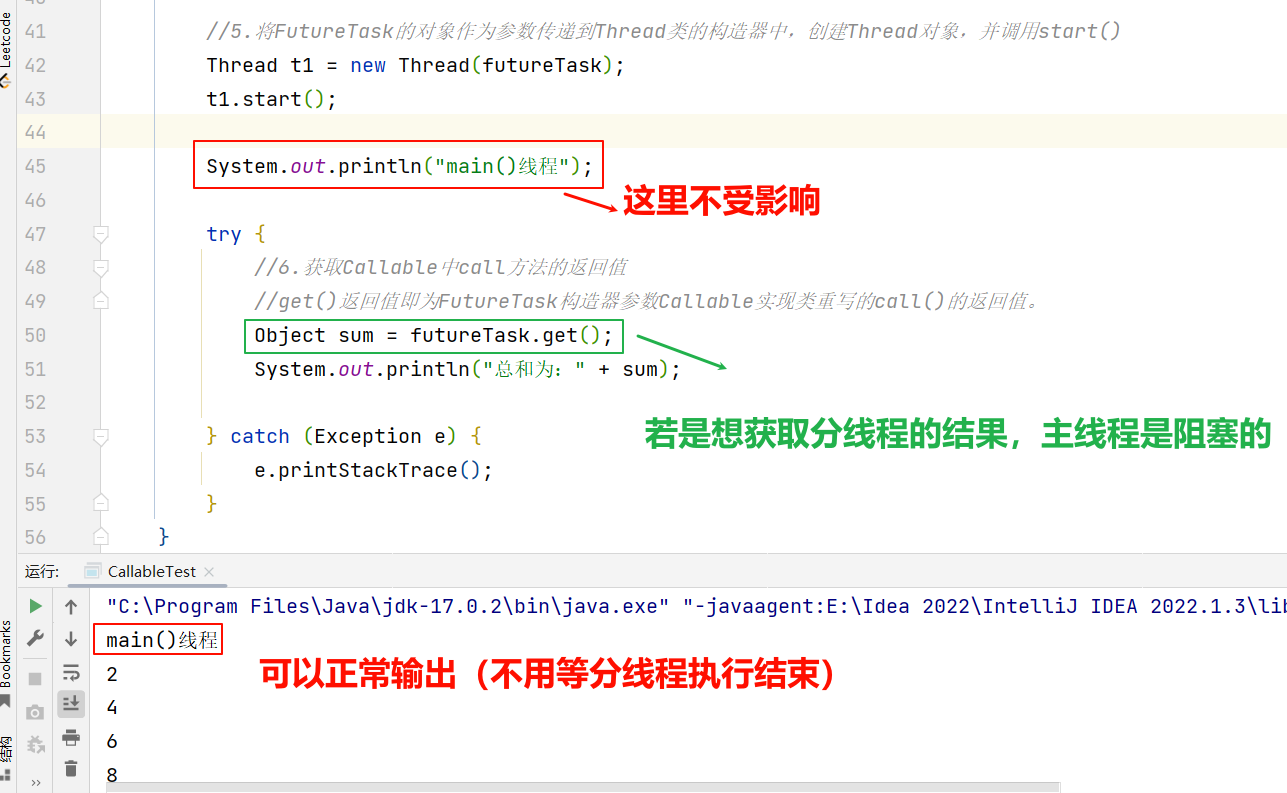
}public class CallableTest {public static void main(String[] args) {//3.创建Callable接口实现类的对象NumThread numThread = new NumThread();//4.将此Callable接口实现类的对象作为传递到FutureTask构造器中,创建FutureTask的对象FutureTask futureTask = new FutureTask(numThread);//5.将FutureTask的对象作为参数传递到Thread类的构造器中,创建Thread对象,并调用start()Thread t1 = new Thread(futureTask);t1.start();System.out.println("main()线程");try {//6.获取Callable中call方法的返回值//get()返回值即为FutureTask构造器参数Callable实现类重写的call()的返回值。Object sum = futureTask.get();System.out.println("总和为:" + sum);} catch (Exception e) {e.printStackTrace();}}}
🍺输出(部分)
☕注意
call方法就相当于之前的run方法,与run方法不一样的是,call方法可以有返回值类型。
另外,call方法可以通过throws抛出异常。也就是异常可以不在里面处理了,可以往外抛,更加灵活了。
之前在run方法里面,sleep方法有一个异常,可能会出现编译时异常InterruptedException,所以就会在同步代码块里面做try-catch操作。如下:
class PrintNumber implements Runnable{//...@Overridepublic void run() {while(true){synchronized (obj) { //obj是唯一的,线程安全//...if(number<=100){try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();}//...}else{break;}}}}
}
如果就想在外面知道方法调用可能出现了什么异常,也可以在这里throw一个运行时异常,将编译时异常InterruptedException以字符串的方式传进去,如下:
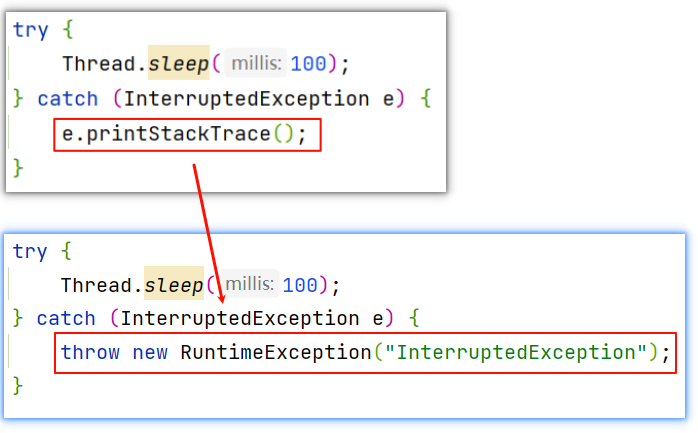
这就是一种处理方式,在外面想要知道出现了什么异常,也能抛,只不过此时抛的是一个运行时异常,运行时异常通常不处理。
就避开了在sleep的地方直接throws出去。
相当于将可能出现的编译时异常以一个运行时异常的方式给抛出。
而现在的Callable比较灵活,可以直接将异常抛出去。
而且它抛的还是Exception,也就是说,无论是编译时异常还是运行时异常都可以。如下:
call方法可以返回值,而run方法不行,比如上边案例中,run方法就只能将sum定义在外面,在里面给sum赋值,方法执行结束以后,sum的值也就变了,不能以返回的方式去体现了。
FutureTask也实现了Runnable的接口,所以第5步使用的Thread构造器还是这个:
public Thread(Runnable target) {
this(null, target, "Thread-" + nextThreadNum(), 0);
}
这个start()仍然执行的是实现类NumThread里面的call方法。
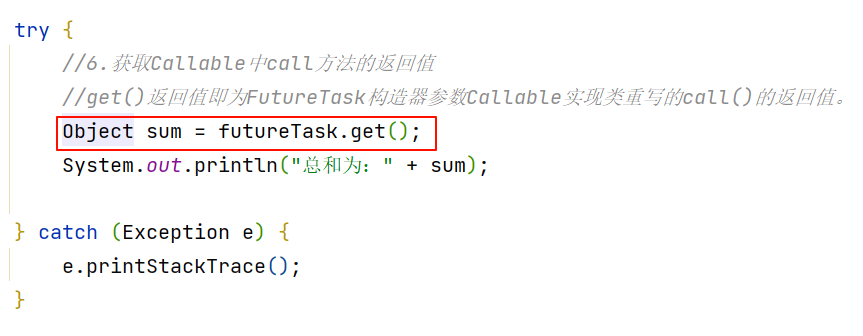
对于当前操作来说,有一个返回值Object。如果想获取这个返回值的话,就需要使用到futureTsak。
拿着futureTsak去调用get方法,就能得到总和sum,如下:
🎲说个容易混淆的事情。
Object sum = futureTask.get();这个操作是在主线程当中做的。
之前说过这样一个例子:
public class ThreadTest {public static void main(String[] args) {// 创建线程对象MyThread t = new MyThread();t.setName("线程1");t.start();// 调用sleep方法try {t.sleep(1000 * 5);} catch (InterruptedException e) {e.printStackTrace();}// 5秒之后这里才会执行。System.out.println("hello World!");}
}class MyThread extends Thread {public void run() {for (int i = 0; i < 10000; i++) {System.out.println(Thread.currentThread().getName() + "--->" + i);}}
}sleep在哪个线程里面执行,就让哪个线程sleep了。
若是将sleep写在run方法里面了,就是分线程sleep;在主线程里面,就是让主线程sleep了。
还有一种解释,sleep()是静态方法,静态方法可以用对象来调用,若对象是null的话也照样可以调。
换句话说,如果将t写成了MyThread,会更加明确。
如下:
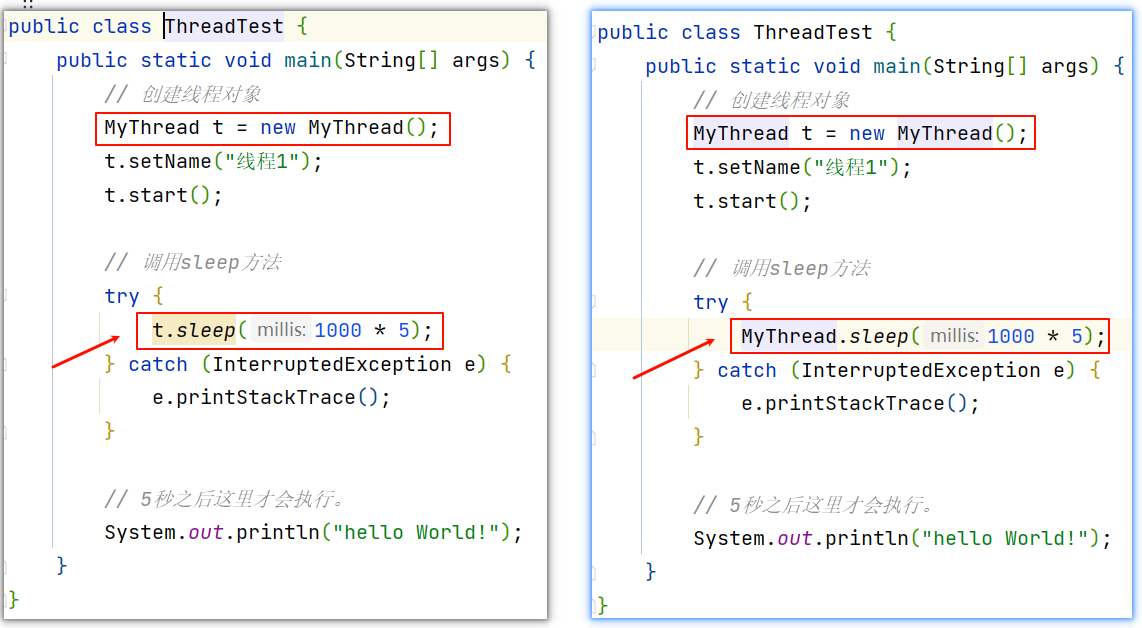
说白了,就是sleep()在哪个线程里面调用的,就让哪个线程sleep。
🚗小细节
这里t1.start(),分线程start(),就出去执行了。
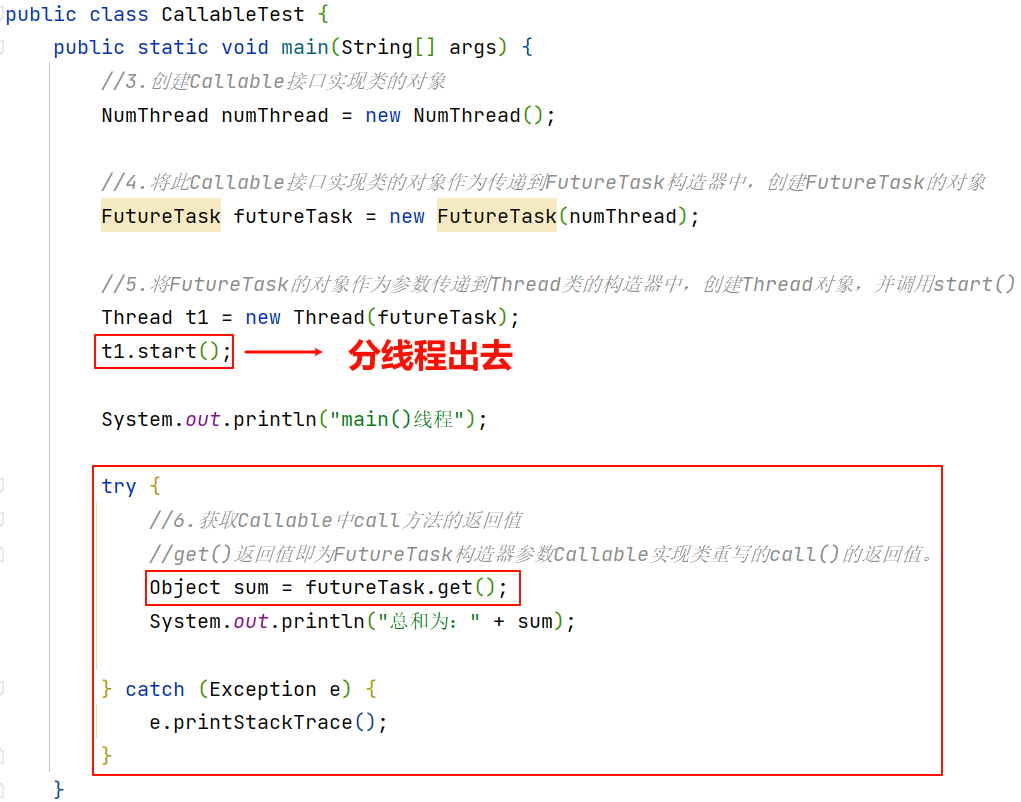
那么主线程会马上执行futureTask.get()吗?
若分线程还没有遍历完100以内的偶数,这时候要是主线程执行的话就会拿不到sum最终的值?
其实不会的。这里会有一个阻塞。这个阻塞是自然而然的。
主线程会一直等分线程return,只有分线程return了,主线程才会get。
(3)总结对比
创建多线程的方式三:实现Callable (jdk5.0新增的)
与Runnable方式的对比的好处
call()可以有返回值,更灵活。call()可以使用throws的方式处理异常,更灵活。Callable使用了泛型参数,可以指明具体的call()的返回值类型(不一定非要是Object),更灵活。
有缺点吗?
如果在主线程中需要获取分线程call()的返回值,则此时的主线程是阻塞状态的。
这种方式存在的意义,估计就是笔试题了。
在开发当中,最常使用的就是“线程池”。
二、新增方式2:使用线程池
(1)问题与解决思路
1、现有问题
如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因为频繁创建线程和销毁线程需要时间。
那么有没有一种办法使得线程可以复用,即执行完一个任务,并不被销毁,而是可以继续执行其他的任务?
2、解决思路
思路:提前创建好多个线程,放入线程池中,使用时直接获取,使用完放回池中。
可以避免频繁创建销毁、实现重复利用。
类似生活中的公共交通工具。
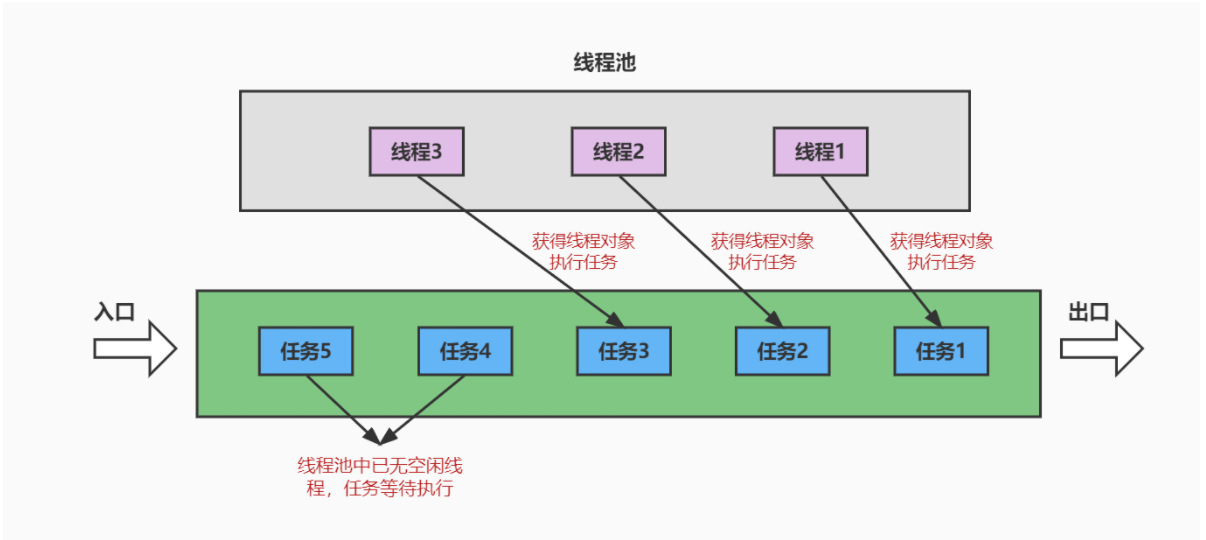
将创建好的线程都放在一个池子里面,就叫线程池。
若此时一系列的任务过来了,每一个任务需要拿一个线程去操作,那么这个任务就可以去线程池里面捞一个线程来用。
假设现在只有三个线程,对应三个任务拿着它们去执行。如果还有其他新的任务,则需要等待。
当现有的任务执行完之后,此时的线程不会因为当前任务的执行结束而销毁,而是又还回到线程池当中,这个线程就可以继续分配给其他任务去执行。
这就得到了很好的重复利用。
当然,我们还可以设置线程池的参数,比如初始化的时候有三个线程池,不够的时候再增加线程。
3、好处
创建多线程的方式四:使用线程池
此方式的好处:
- 提高了程序执行的效率,提高响应速度。(因为线程已经提前创建好了,减少了创建新线程的时间)
- 提高了资源的复用率。(因为执行完的线程并未销毁,而是可以继续执行其他的任务)
- 降低资源消耗(重复利用线程池中线程,不需要每次都创建) 。
- 可以设置相关的参数,对线程池中的线程的使用进行管理。(便于线程管理)
corePoolSize:核心池的大小maximumPoolSize:最大线程数keepAliveTime:线程没有任务时最多保持多长时间后会终止- …
(2)线程池相关API
- JDK5.0之前,我们必须手动自定义线程池。从JDK5.0开始,Java内置线程池相关的API。在java.util.concurrent包下提供了线程池相关API:
ExecutorService和Executors。 ExecutorService:真正的线程池接口。常见子类ThreadPoolExecutorvoid execute(Runnable command):执行任务/命令,没有返回值,一般用来执行Runnable<T> Future<T> submit(Callable<T> task):执行任务,有返回值,一般又来执行Callablevoid shutdown():关闭连接池
Executors:一个线程池的工厂类,通过此类的静态工厂方法可以创建多种类型的线程池对象。Executors.newCachedThreadPool():创建一个可根据需要创建新线程的线程池Executors.newFixedThreadPool(int nThreads); 创建一个可重用固定线程数的线程池Executors.newSingleThreadExecutor():创建一个只有一个线程的线程池Executors.newScheduledThreadPool(int corePoolSize):创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
(3)案例
🌱代码
package com.atguigu06.createmore.pool;import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadPoolExecutor;//创建并使用多线程的第四种方法:使用线程池class NumberThread implements Runnable{@Overridepublic void run() { //指明线程想干什么for(int i = 0;i <= 100;i++){ //打印偶数if(i % 2 == 0){System.out.println(Thread.currentThread().getName() + ": " + i);}}}
}class NumberThread1 implements Runnable{@Overridepublic void run() {for(int i = 0;i <= 100;i++){ //打印奇数if(i % 2 != 0){System.out.println(Thread.currentThread().getName() + ": " + i);}}}
}public class ThreadPool {public static void main(String[] args) {//1. 提供指定线程数量的线程池ExecutorService service = Executors.newFixedThreadPool(10);ThreadPoolExecutor service1 = (ThreadPoolExecutor) service; //强转
// //设置线程池的属性
// System.out.println(service.getClass());//ThreadPoolExecutorservice1.setMaximumPoolSize(50); //设置线程池中线程数的上限//2.执行指定的线程的操作。需要提供实现Runnable接口或Callable接口实现类的对象service.execute(new NumberThread());//适合适用于Runnableservice.execute(new NumberThread1());//适合适用于Runnable// service.submit(Callable callable);//适合使用于Callable//3.关闭连接池service.shutdown();}}
🍺输出(部分)

☕注意
造线程是通过“new Thread”来体现的,这里只是指明了要做的事情,还没有线程的概念。
如下:

然后通过Executors.newFixedThreadPool(10)造了一个线程池(细节就不用管了),池子里面初始化放了10个线程。
可以设置相关参数:

现在只需要告诉我你想干什么,就new一个Runnable的实现类的对象,其实就是帮忙调用一下run方法。

这里没有看到new Thread的代码,因为第1步造线程池的时候已经做好了。
所以就可以将要做的事情的run方法封装在对象里面,往这里的小括号一放,就可以自动执行上面的run方法了。
如下:

最后,若是这个池子不用了,就可以将它删了。

线程池也可以适配Callable,Callable如果想要有返回值的话,可以使用submit方法。
在开发当中,如果线程多次使用,其实选择的都是“线程池”的方式。
而这种池子通常要么是直接封装好了,要是用的话,可以像上面案例一样去使用。
具体线程池的使用,在JUC里面说,Java基础阶段不做深入。