1 背景介绍
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
Flink CDC 是 Apache Flink 的一组源连接器,基于数据库日志的 Change Data Caputre 技术,实现了全量和增量的一体化读取能力,并借助 Flink 优秀的管道能力和丰富的上下游生态,支持捕获多种数据库的变更,并将这些变更实时同步到下游存储。目前,Flink CDC 的上游已经支持了MySQL,MariaDB, RDS MySQL,Aurora MySQL,PolarDB MySQL,PostgreSQL,Oracle,MongoDB,SqlServer,OceanBase,PolarDB-X,TiDB 等丰富的数据源。Flink CDC 的下游则更加丰富,支持写入 Kafka、Pulsar 消息队列,也支持写入 Hudi、Iceberg 等数据湖,还支持写入各种数据仓库。同时,通过 Flink SQL 原生支持的 Changelog 机制,可以让 CDC 数据的加工变得非常简单。用户可以通过 SQL 便能实现数据库全量和增量数据的清洗、打宽、聚合等操作,极大地降低了用户门槛。 此外, Flink DataStream API 支持用户编写代码实现自定义逻辑,给用户提供了深度定制业务的自由度。
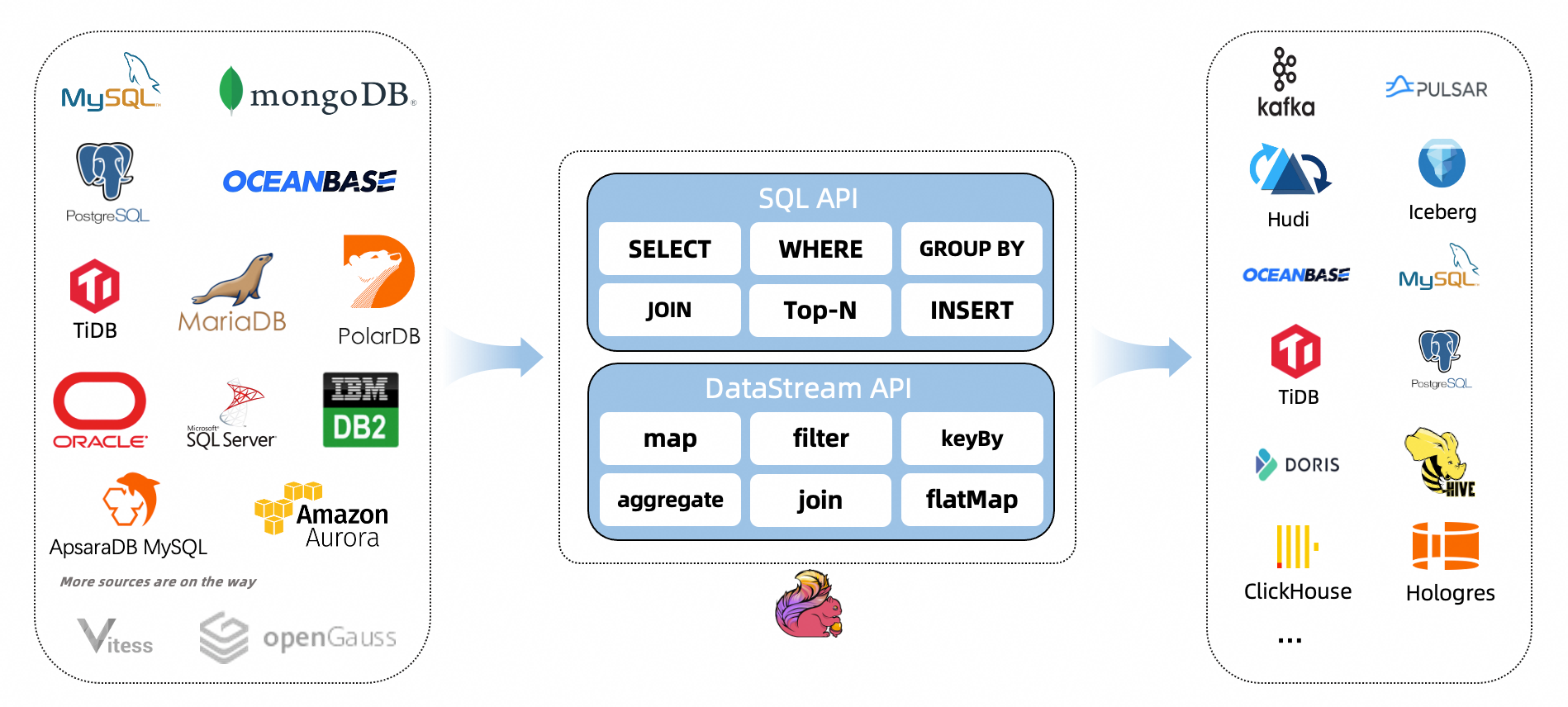
本文以Flink+FlinkCDC同步MySQL数据、数据入仓,数据入湖等测试为例,为日后云桥数据集成产品做准备。
框架软件版本如下:
| 软件 | 版本 |
| Java | 1.8.0_361 |
| Mysql | 8.0.32 |
| Flink | 1.16.2 |
| Flink CDC | 2.3.0 |
| Hadoop | 3.1.5.0 |
| Hive | 3.1.0.3.1.5.0-152 |
| kafka | 2.0.0.3.1.5.0-152 |
| Hudi | 0.13.0 |
环境部署
2 环境部署
2.1 Flink部署
本次部署以Flink单机版为例
2.1.1 下载Flink部署包并解压
# 下载Flink安装包(这里测试使用Flink16.2版本)
wget https://archive.apache.org/dist/flink/flink-1.16.2/flink-1.16.2-bin-scala_2.12.tgz# 解压
tar -xzvf flink-1.16.2-bin-scala_2.12.tgz2.1.2 修改配置文件
修改flink-conf.yaml
在flink目录的conf下
jobmanager.rpc.address: localhost# The RPC port where the JobManager is reachable.jobmanager.rpc.port: 6123jobmanager.bind-host: localhostjobmanager.memory.process.size: 6800mtaskmanager.bind-host: 192.168.1.1taskmanager.host: 192.168.1.1# The total process memory size for the TaskManager.
#
# Note this accounts for all memory usage within the TaskManager process, including JVM metaspace and other overhead.taskmanager.memory.process.size: 6800m# To exclude JVM metaspace and overhead, please, use total Flink memory size instead of 'taskmanager.memory.process.size'.
# It is not recommended to set both 'taskmanager.memory.process.size' and Flink memory.
#
taskmanager.memory.flink.size: 6280m# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.taskmanager.numberOfTaskSlots: 4# The parallelism used for programs that did not specify and other parallelism.parallelism.default: 1jobmanager.execution.failover-strategy: region# The port to which the REST client connects to. If rest.bind-port has
# not been specified, then the server will bind to this port as well.
#
rest.port: 8787# The address to which the REST client will connect to
#
rest.address: 192.168.1.1rest.bind-address: 192.168.1.1#设置checkpoint周期时间
execution.checkpointing.interval: 30000
#设置有且仅有一次模式 目前支持 EXACTLY_ONCE、AT_LEAST_ONCE
execution.checkpointing.mode: EXACTLY_ONCE
#设置checkpoint的存储方式
state.backend: filesystem
#设置checkpoint的存储位置
state.checkpoints.dir: file:///opt/data/flink/checkpoint
#设置savepoint的存储位置
state.savepoints.dir: file:///opt/data/flink/checkpoint
#设置checkpoint的超时时间 即一次checkpoint必须在该时间内完成 不然就丢弃
execution.checkpointing.timeout: 600000
#设置两次checkpoint之间的最小时间间隔
execution.checkpointing.min-pause: 500
#设置并发checkpoint的数目
execution.checkpointing.max-concurrent-checkpoints: 1
#开启checkpoints的外部持久化这里设置了清除job时保留checkpoint,默认值时保留一个 假如要保留3个
state.checkpoints.num-retained: 3
#默认情况下,checkpoint不是持久化的,只用于从故障中恢复作业。当程序被取消时,它们会被删除。但是你可以配置checkpoint被周期性持久化到外部,类似于savepoints。这些外部的checkpoints将它们的元数据输出到外#部持久化存储并且当作业失败时不会自动清除。这样,如果你的工作失败了,你就会有一个checkpoint来恢复。
#ExternalizedCheckpointCleanup模式配置当你取消作业时外部checkpoint会产生什么行为:
#RETAIN_ON_CANCELLATION: 当作业被取消时,保留外部的checkpoint。注意,在此情况下,您必须手动清理checkpoint状态。
#DELETE_ON_CANCELLATION: 当作业被取消时,删除外部化的checkpoint。只有当作业失败时,检查点状态才可用。
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
# 该配置用于客户端 client 连接 Flink, 将此设置为 JobManager 运行的主机名(该配置决定WEB的地址)
rest.address: 192.168.1.1
# 客户端提供对外访问的地址和端口是rest.port和rest.address
# 如果没有配置rest.bind-port, 那么其他服务也使用rest.port端口,所以只要使用其中一个启动模式,其他模式在启动时就会报错端口无法启动
# 因此配置该项后, 其他 Job 启动后,就会在 rest.bind-address 和 rest.bind-port 随机选择并占用.
rest.bind-address: 192.168.1.1
classloader.check-leaked-classloader: false2.1.3 启动服务
进入bin目录
# 启动Flink集群
./start-cluster.sh# 停止Flink集群
#./stop-cluster.sh

会启动
StandaloneSessionClusterEntrypoint
TaskManagerRunner
- 如果StandaloneSessionClusterEntrypoint 没有启动,则检查flink-conf.yaml有地址和端口有没有填写好,
- TaskManagerRunner没有启动则检查
flink/comf/masters
192.168.1.1:8787
taskmanager.sh
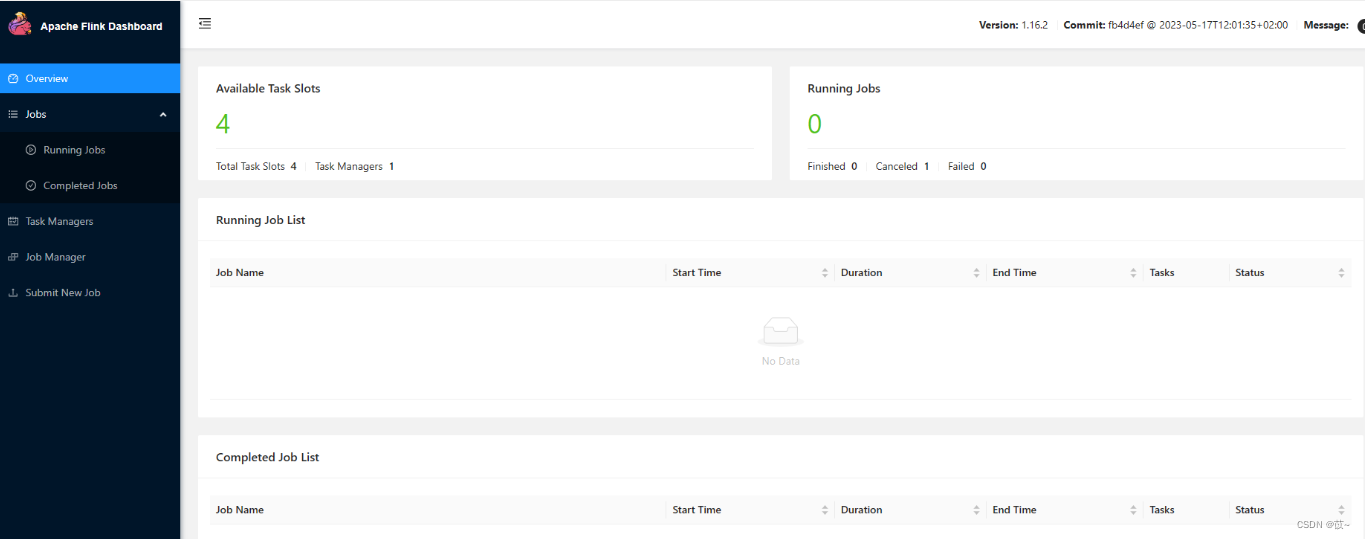
2.1.4 访问Flink UI
http://x.x.x.x:8787/#/overview
2.2 FlinkCDC
Flink CDC是Flink的一组连接器,需要连接哪个组件,则需要将对应的连接jar包放在flink安装目录下的lib即可,
以下几种情况需要进行源码编译:
- 用户对 Flink CDC 源码进行了修改
- Flink CDC 某依赖项的版本与运行环境不一致
- 官方未提供最新版本 Flink CDC 二进制安装包
FlinkCDC源码地址:
GitHub - ververica/flink-cdc-connectors: CDC Connectors for Apache Flink®
如果不需要编译,选择对应的连接器和版本,可以直接下载打包好的jar
Central Repository: com/ververica
将jar包放到flink安装目录下的lib即可。
FlinkCDC 与Flink 对应关系:
| Flink® CDC Version | Flink® Version |
| 1.0.0 | 1.11.* |
| 1.1.0 | 1.11.* |
| 1.2.0 | 1.12.* |
| 1.3.0 | 1.12.* |
| 1.4.0 | 1.13.* |
| 2.0.* | 1.13.* |
| 2.1.* | 1.13.* |
| 2.2.* | 1.13.*, 1.14.* |
| 2.3.* | 1.13.*, 1.14.*, 1.15.*, 1.16.0 |
| 2.4.* | 1.13.*, 1.14.*, 1.15.*, 1.16.*, 1.17.0 |

![[官方精简母盘WIM]_Windows10_22H2_19045.3930](https://img-blog.csdnimg.cn/direct/63a551a19ef64b03b1e06066c4e31e40.png)