LLM(5) | Encoder 和 Decoder 架构
文章目录
- LLM(5) | Encoder 和 Decoder 架构
- 0. 目的
- 1. 概要
- 2. encoder 和 decoder 风格的 transformer (Encoder- And Decoder-Style Transformers)
- 原始的 transformer (The original transformer)
- 编码器 (Encoders)
- 解码器 (Decoders)
- 编码器和解码器的混合 (encoder-decoder hybrids)
- 术语、 黑话 (Terminology and jargon)
- 结论
- References
0. 目的
LLM 模型都是 transformer 结构的, 先前已经粗略翻阅了提出 transformer 模型的论文 “Attention Is All You Need”, 了解到了 transformer 结构是第一个完全基于 attention 的模型。
而在一些资料中, 看到有人对 LLM 进行分类, 分成 encoder-only, decoder-only, encode-decode 三类, 感觉很晕, 有必要了解下什么是 encoder 和 decoder。
本文主要是对 Understanding Encoder And Decoder LLMs 的翻译。
老规矩, 中文翻译后的括号里, 是个人粗浅的笔记和想法。
1. 概要
Several people asked me to dive a bit deeper into large language model (LLM) jargon and explain some of the more technical terms we nowadays take for granted. This includes references to “encoder-style” and “decoder-style” LLMs. What do these terms mean?
我被人问了好几次, 让我更深入的说说 LLM 术语, 并解释我们现在认为理所当然的一些更技术性的术语。 这包括对 encode-style 和 decoder-style 的 LLM。 这些术语是什么意思?
( LLM 火起来后, 经常发现一些缩写,术语, 让不了解它的人很晕。 有些老铁让作者讲讲。 作者 sebastianraschka 以前是 University of Wisconsin-Madison 的 Assistant Professor, 后来全职加入 lighting ai。)
To explain the difference between encoder- and decoder-style LLMs, I wanted to share an excerpt from my new book, Machine Learning Q and AI, that I completed last week.
为了解释 encoder-style 和 decoder-style LLM 的区别, 我想分享一段我上周完成的新书 “Machine Learning Q and AI” 的摘录。
(作者写了一本书, 看来在讲授 AI 方面有经验.)
This book is aimed at people who are already familiar with machine learning and deep learning (“AI”) and are interested in diving into more advanced topics. There are 30 chapters in total, covering various topics, including
这本书是针对那些已经熟悉机器学习和深度学习(AI), 并对深入更高级话题感兴趣的人, 总共有30章, 涵盖了各种主题,包括:
- 多GPU训练范式的解释 (Explanations of multi-GPU training paradigms)
- 微调 transformer (Finetuning transformers)
- encoder 和 decoder 风格的 LLM 之前的区别 (Differences between encoder- and decoder-style LLMs)
- 更多其他主题 (And many more!)
(看了下电子书需要购买,20+美元)
2. encoder 和 decoder 风格的 transformer (Encoder- And Decoder-Style Transformers)
Fundamentally, both encoder- and decoder-style architectures use the same self-attention layers to encode word tokens. However, the main difference is that encoders are designed to learn embeddings that can be used for various predictive modeling tasks such as classification. In contrast, decoders are designed to generate new texts, for example, answering user queries.
基本上, endoder- 和 decoder- 风格的架构, 都使用相同的 self-attention 层来编码单词标记 (word tokens). 然而, 主要区别在于 encoder 的设计,是为了学习可以用于各种预测建模任务的嵌入。 相反, decoder 的设计初衷是生成新的文本, 比如回答用户的查询。
(encoder 是为了学习一个 embedding, 这个 embedding 能用于预测性的任务比如分类; decoder 是为了生成新的文本, 比如回答问题.)
原始的 transformer (The original transformer)
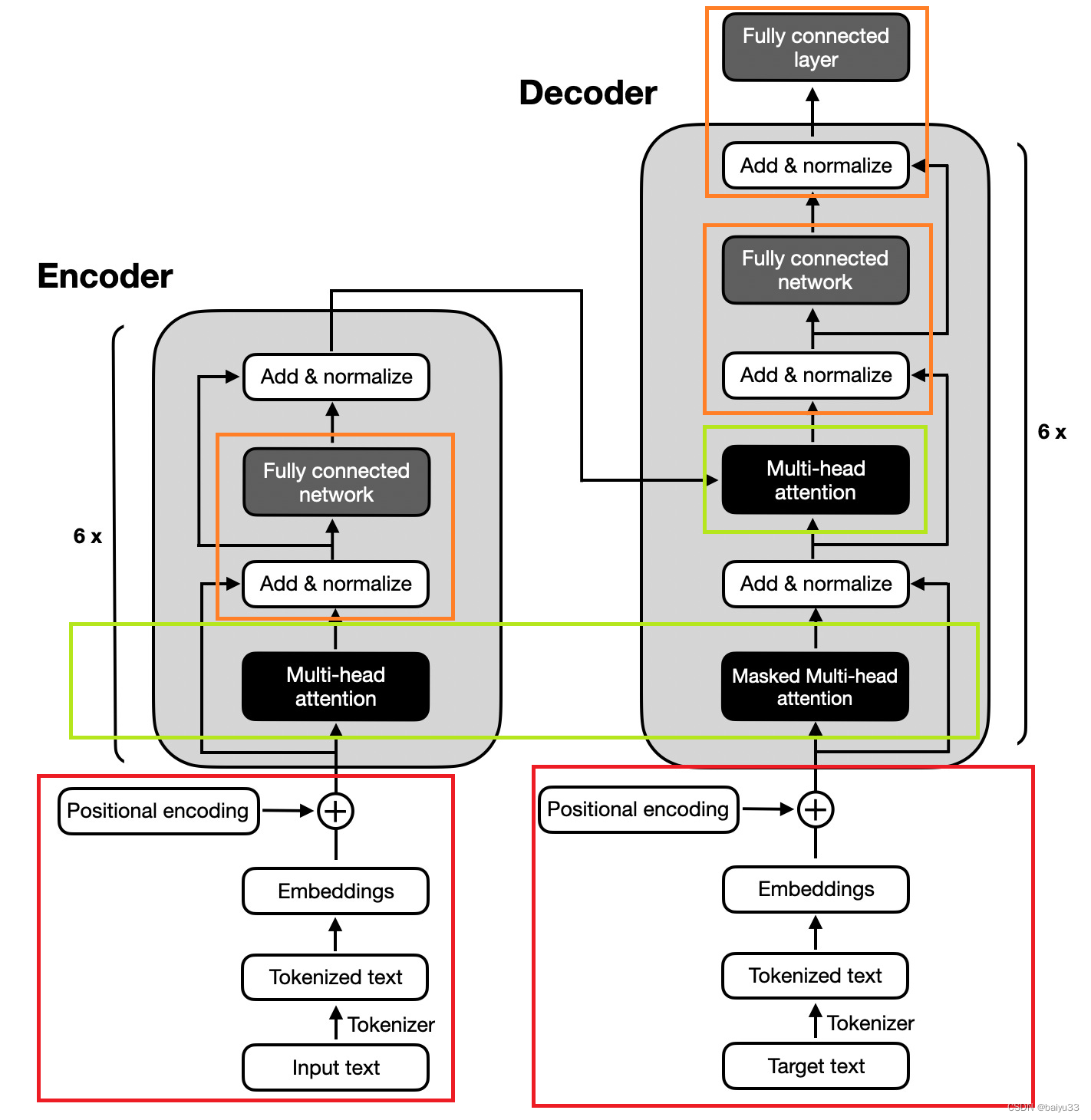
The original transformer architecture (Attention Is All You Need, 2017), which was developed for English-to-French and English-to-German language translation, utilized both an encoder and a decoder, as illustrated in the figure below.
原始的 transformer 架构是在2017年的论文 “Attention Is All You Need” 里提出的, 左图是 encoder, 右图是 decoder:
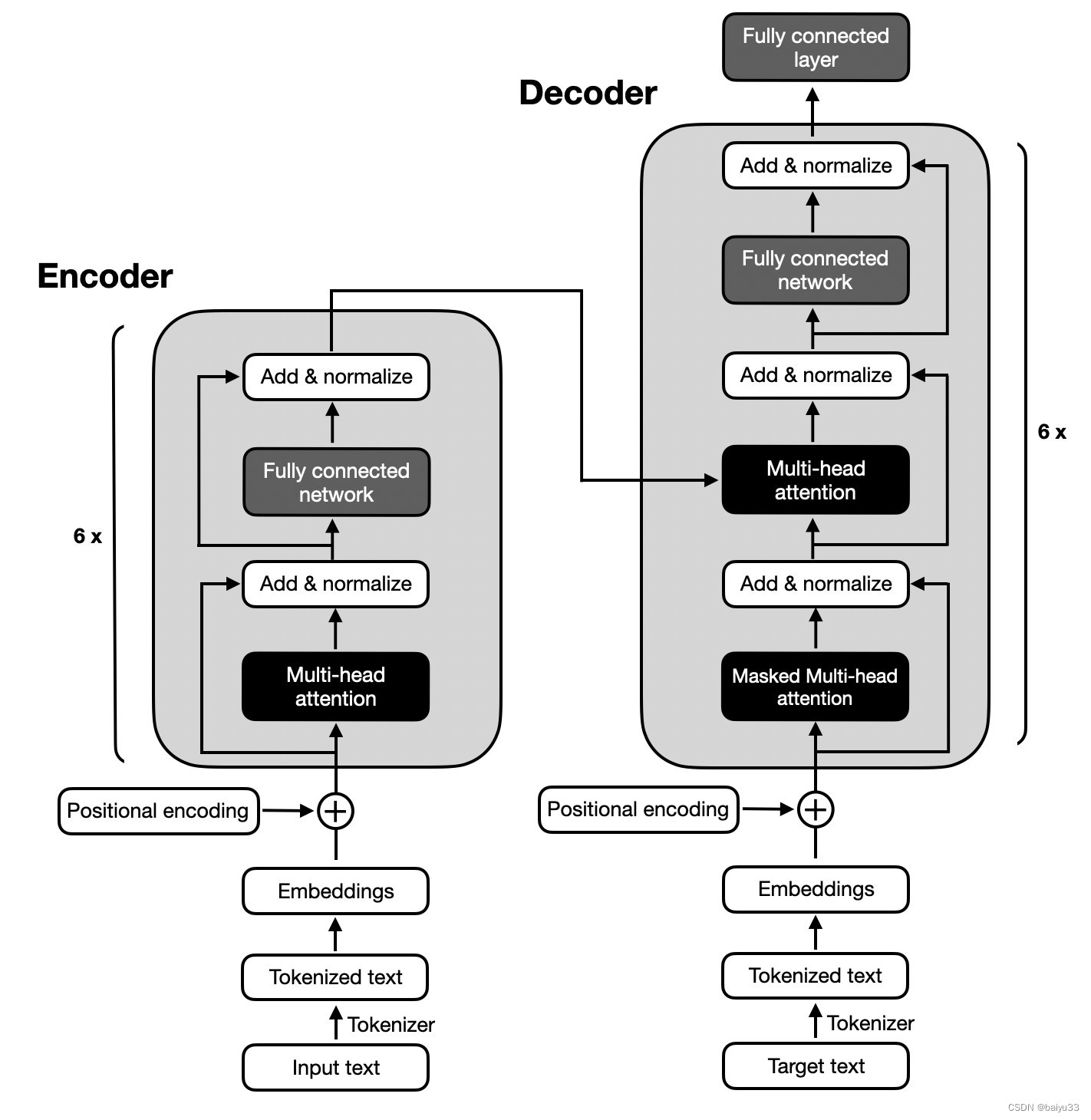
In the figure above, the input text (that is, the sentences of the text that is to be translated) is first tokenized into individual word tokens, which are then encoded via an embedding layer before it enters the encoder part.
在上图中, 输入文本(即要翻译的文本的句子)首先被分词成单个词元(token), 然后通过 embedding 层进行编码, 然后进入编码器部分。
Then, after adding a positional encoding vector to each embedded word, the embeddings go through a multi-head self-attention layer.
然后, 在为每个嵌入的单词添加位置编码向量后, 嵌入 multi-head self-attention 层。
The multi-head attention layer is followed by an “Add & normalize” step, which performs a layer normalization and adds the original embeddings via a skip connection (also known as a residual or shortcut connection).
multi-head attention 层之后是 “Add & Normalize” 步骤, 它执行 layer normalization, 并通过 skip connection (也叫做残差 或 快捷连接)添加原始嵌入。
Finally, after entering a “fully connected layer,” which is a small multilayer perceptron consisting of two fully connected layers with a nonlinear activation function in between, the outputs are again added and normalized before they are passed to a multi-head self-attention layer of the decoder part.
最后, 经过进入全连接层后, 这是一个由两个全连接层组成的小型多层感知机, 在两者之间还有非线性激活函数, 输出再次被添加和归一化, 然后传递到 decoder 部分的 multi-head self-attention 层。
The decoder part in the figure above has a similar overall structure as the encoder part. The key difference is that the inputs and outputs are different.
上图中 decoder 部分和 encoder 部分具有相似的整体结构。 主要区别在于输入和输出是不同的。
The encoder receives the input text that is to be translated, and the decoder generates the translated text.
encoder 接收要翻译的输入文本, decoder 则是生成翻译后的文本。
以下是个人理解
encoder 和 decoder 没那么神秘。 提出 transformer 的那篇论文里的第一张图, 左图是 encoder, 右图是 decoder, 并且 encoder 和 decoder 在整体上是非常相似的。 为什么这么说呢? 你看:
- 【红色】 encoder 和 decoder 的输入, 都是先经过 tokenize 后搞一个 embendding 和 positional encoding 的
- 【绿色】 进入 encoder 和 decoder 里面, 都是先经过一个 MHA 的结构 (先忽略 mask 的问题)
- 【橙色】 然后是 “Add & normalize” 和 “Fully connected” 层的组合
- 【没标记颜色】 encoder 和 decoder 内部的最后一部分, 都是 “Add & normalize”
编码器 (Encoders)
The encoder part in the original transformer, illustrated in the preceding figure, is responsible for understanding and extracting the relevant information from the input text.
在原始 transformer 中,编码器部分负责理解和提取输入文本中的相关信息。
It then outputs a continuous representation (embedding) of the input text that is passed to the decoder.
然后,它输出输入文本的连续表示(embedding),这个表示被传递给 decoder。
Finally, the decoder generates the translated text (target language) based on the continuous representation received from the encoder.
最后, decoder 基于从 encoder 接收到的连续表示生成翻译文本(目标语言)。
Over the years, various encoder-only architectures have been developed based on the encoder module of the original transformer model outlined above.
多年来,基于上述原始 transformer 模型的 encoder 模块,已经开发了各种 encoder-only 的架构。
Notable examples include BERT (Pre-training of Deep Bidirectional Transformers for Language Understanding, 2018) and RoBERTa (A Robustly Optimized BERT Pretraining Approach, 2018).
值得注意的例子包括BERT(用于语言理解的深度双向变换器的预训练,2018年)和RoBERTa(一种鲁棒优化的BERT预训练方法,2018年)
BERT (Bidirectional Encoder Representations from Transformers) is an encoder-only architecture based on the Transformer’s encoder module.
BERT(来自 transformer 的双向 encoder 表示)是一种 encoder-only 的架构, 它里面的 encoder 模块是基于 transformer 的 encoder 模块。
The BERT model is pretrained on a large text corpus using masked language modeling (illustrated in the figure below) and next-sentence prediction tasks.
BERT模型使用遮蔽语言建模(完形填空)(如下图所示)和下一句预测任务在大型文本语料库上进行预训练.

The main idea behind masked language modeling is to mask (or replace) random word tokens in the input sequence and then train the model to predict the original masked tokens based on the surrounding context.
遮蔽语言建模背后的主要思想是在输入序列中遮蔽(或替换)随机词语标记,然后训练模型根据周围的上下文预测原始遮蔽的标记。
Next to the masked language modeling pretraining task illustrated in the figure above, the next-sentence prediction task asks the model to predict whether the original document’s sentence order of two randomly shuffled sentences is correct. For example, two sentences, in random order, are separated by the [SEP] token:
除了上图所示的遮蔽语言建模预训练任务之外,下一句预测任务要求模型预测两个随机打乱顺序的句子是否保持了原始文档的句子顺序。例如,两个随机顺序的句子由[SEP]标记分隔:
[CLS] Toast is a simple yet delicious food [SEP] It’s often served with butter, jam, or honey.
[CLS] 吐司是一种简单却美味的食物 [SEP] 它通常搭配黄油、果酱或蜂蜜食用。
[CLS] It’s often served with butter, jam, or honey. [SEP] Toast is a simple yet delicious food.
[CLS] 它通常搭配黄油、果酱或蜂蜜食用。[SEP] 吐司是一种简单却美味的食物。
The [CLS] token is a placeholder token for the model, prompting the model to return a True or False label indicating whether the sentences are in the correct order or not.
其中 [CLS] 标记是模型的占位符标记,提示模型返回一个真或假的标签,表明句子的顺序是否正确。
The masked language and next-sentence pretraining objectives (which are a form of self-supervised learning, as discussed in Chapter 2) allow BERT to learn rich contextual representations of the input texts, which can then be finetuned for various downstream tasks like sentiment analysis, question-answering, and named entity recognition.
遮蔽语言和下一句预训练目标(正如第二章所讨论的,这是一种自监督学习的形式)使得BERT能够学习输入文本的丰富上下文表示,然后可以针对各种下游任务进行微调,如情感分析、问答和命名实体识别。
RoBERTa (Robustly optimized BERT approach) is an optimized version of BERT. It maintains the same overall architecture as BERT but employs several training and optimization improvements, such as larger batch sizes, more training data, and eliminating the next-sentence prediction task. These changes resulted in RoBERTa achieving better performance on various natural language understanding tasks than BERT.
RoBERTa(鲁棒优化的BERT方法)是BERT的优化版本。它保持了与BERT相同的总体架构,但采用了多项训练和优化改进,如更大的批量大小、更多的训练数据,并且取消了下一句预测任务。这些变化使得RoBERTa在各种自然语言理解任务上的表现优于BERT。
解码器 (Decoders)
Coming back to the original transformer architecture outlined at the beginning of this section, the multi-head self-attention mechanism in the decoder is similar to the one in the encoder, but it is masked to prevent the model from attending to future positions, ensuring that the predictions for position i can depend only on the known outputs at positions less than i. As illustrated in the figure below, the decoder generates the output word by word.
回到本节开头概述的原始 transformer 架构, decoder 中的 multi-head self-attention 机制与 encoder 中的相似,但它被遮蔽以防止模型关注未来的位置,确保位置i的预测只能依赖于小于i的位置上已知的输出。如下图所示,decoder 逐字生成输出。
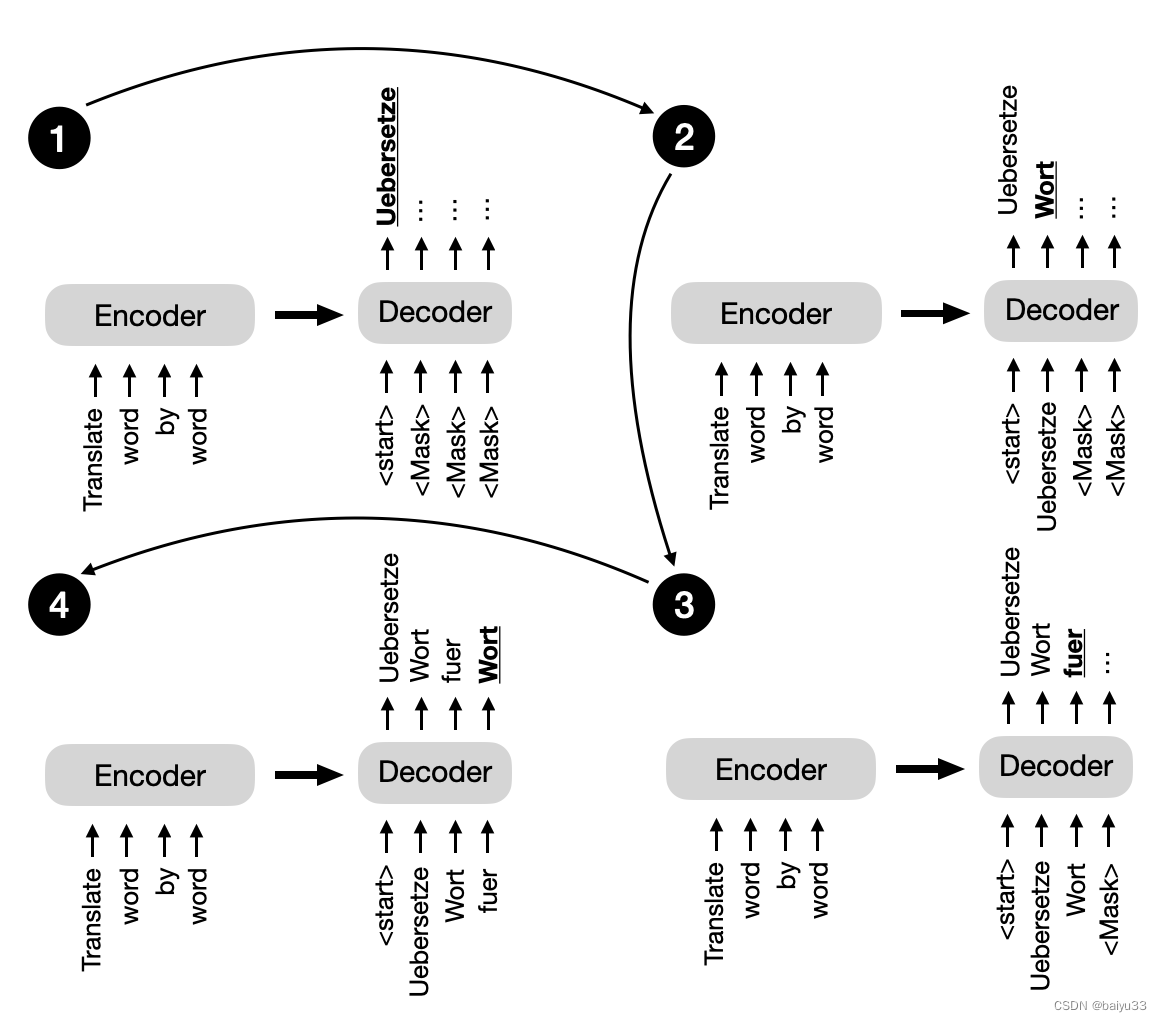
This masking (shown explicitly in the figure above, although it happens internally in the decoder’s multi-head self-attention mechanism) is essential to maintain the autoregressive property of the transformer model during training and inference.
这种遮蔽(如上图所示,尽管它在 encoder 的 MHA 中内部发生)对于在训练和推理过程中保持 transformer 的自回归特性是至关重要的。
The autoregressive property ensures that the model generates output tokens one at a time and uses previously generated tokens as context for generating the next word token.
自回归特性确保模型一次生成一个输出标记,并使用之前生成的标记作为生成下一个词标记的上下文。
Over the years, researchers have built upon the original encoder-decoder transformer architecture and developed several decoder-only models that have proven to be highly effective in various natural language processing tasks. The most notable models include the GPT family.
多年来,研究人员在原始的 encoder-decoder transformer 架构的基础上进行了发展,开发出了几种 decoder-only 模型,这些模型在各种自然语言处理任务中被证明是高度有效的。最值得注意的模型包括GPT系列。
The GPT (Generative Pre-trained Transformer) series are decoder-only models pretrained on large-scale unsupervised text data and finetuned for specific tasks such as text classification, sentiment analysis, question-answering, and summarization.
GPT(生成式预训练变换器)系列是 decoder-only 模型,它们在大规模无监督文本数据上进行预训练,并针对特定任务如文本分类、情感分析、问答和摘要生成进行微调。
The GPT models, including GPT-2, (GPT-3 Language Models are Few-Shot Learners, 2020), and the more recent GPT-4, have shown remarkable performance in various benchmarks and are currently the most popular architecture for natural language processing.
GPT模型,包括GPT-2、(GPT-3语言模型是少数次学习者,2020年)和更近期的GPT-4,在各种基准测试中展现了卓越的性能,目前是自然语言处理中最受欢迎的架构。
One of the most notable aspects of GPT models is their emergent properties.
GPT模型最引人注目的方面之一是它们的涌现属性 (emergent properties)。
Emergent properties refer to the abilities and skills that a model develops due to its next-word prediction pretraining. Even though these models were only taught to predict the next word, the pretrained models are capable of text summarization, translation, question answering, classification, and more. Furthermore, these models can perform new tasks without updating the model parameters via in-context learning, which is discussed in more detail in Chapter 18.
涌现属性指的是模型由于下一个词预测预训练而发展出的能力和技能。尽管这些模型只被教导预测下一个词,但预训练模型能够进行文本摘要、翻译、问答、分类等。此外,这些模型可以通过上下文学习在不更新模型参数的情况下执行新任务,第18章将更详细地讨论这一点。
编码器和解码器的混合 (encoder-decoder hybrids)
Next to the traditional encoder and decoder architectures, there have been advancements in the development of new encoder-decoder models that leverage the strengths of both components.
在传统的 encoder 和 decoder 架构之外,新型 encoder-decoder 模型的开发也取得了进展,这些模型利用了两个组件的优势。
These models often incorporate novel techniques, pre-training objectives, or architectural modifications to enhance their performance in various natural language processing tasks. Some notable examples of these new encoder-decoder models include
这些模型通常融入了新颖的技术、预训练目标或架构修改,以提高它们在各种自然语言处理任务中的表现。一些值得注意的新型编码器-解码器模型包括:
BART (Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension, 2019)
BART(自然语言生成、翻译和理解的序列到序列预训练的去噪,2019)
and T5 (Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, 2019).
和T5(利用统一的文本到文本变换器探索迁移学习的极限,2019)。
Encoder-decoder models are typically used for natural language processing tasks that involve understanding input sequences and generating output sequences, often with different lengths and structures.
encoder-decoder 模型通常用于自然语言处理任务,这些任务涉及理解输入序列并生成输出序列,输出序列的长度和结构往往与输入不同。
They are particularly good at tasks where there is a complex mapping between the input and output sequences and where it is crucial to capture the relationships between the elements in both sequences. Some common use cases for encoder-decoder models include text translation and summarization.
它们在输入与输出序列之间存在复杂映射关系的任务中表现尤为出色,捕捉两个序列中元素之间的关系至关重要。 encoder-decoder 模型的一些常见用例包括文本翻译和摘要。
术语、 黑话 (Terminology and jargon)
All of these methods, encoder-only, decoder-only, and encoder-decoder models, are sequence-to-sequence models (often abbreviated as seq2seq).
所有这些方法,包括 encoder-only、 decoder-only 和 encoder-decoder 模型,都是序列到序列模型(通常缩写为seq2seq)。
Note that while we refer to BERT-style methods as encoder-only, the description encoder-only may be misleading since these methods also decode the embeddings into output tokens or text during pretraining.
请注意,虽然我们将BERT风格的方法称为 encoder-only,但“encoder-only”这一描述可能会引起误解,因为这些方法在预训练期间也会将嵌入decoding成输出 token 或文本。
In other words, both encoder-only and decoder-only architectures are “decoding.”
换句话说,encoder-only 和 decoder-only 架构都在进行“解码”。
However, the encoder-only architectures, in contrast to decoder-only and encoder-decoder architectures, are not decoding in an autoregressive fashion.
然而,与 decoder-only 和 encoder-decoder 架构不同的是,encoder-only 架构不是以自回归方式进行解码。
Autoregressive decoding refers to generating output sequences one token at a time, conditioning each token on the previously generated tokens.
自回归解码是指一次生成一个token的输出序列,每个token都依赖于之前生成的token。
Encoder-only models do not generate coherent output sequences in this manner. Instead, they focus on understanding the input text and producing task-specific outputs, such as labels or token predictions.
encoder-only 模型不以这种方式生成连贯的输出序列。相反,它们专注于理解输入文本并产生特定于任务的输出,如标签或 token 预测。
结论
In brief, encoder-style models are popular for learning embeddings used in classification tasks, encoder-decoder-style models are used in generative tasks where the output heavily relies on the input (for example, translation and summarization), and decoder-only models are used for other types of generative tasks including Q&A. Since the first transformer architecture emerged, hundreds of encoder-only, decoder-only, and encoder-decoder hybrids have been developed, as summarized in the figure below.
简而言之,encoder-style 的模型在用于分类任务的嵌入学习中很受欢迎, encoder-decoder-style 的模型被用于输出严重依赖于输入的生成性任务(例如,翻译和摘要),而 decoder-only 模型被用于包括问答在内的其他类型的生成性任务。自第一个 transformer 架构出现以来,已经开发了数百种 encoder-only, decoder-only, and encoder-decoder hybrids 的模型结构,如下图所示。
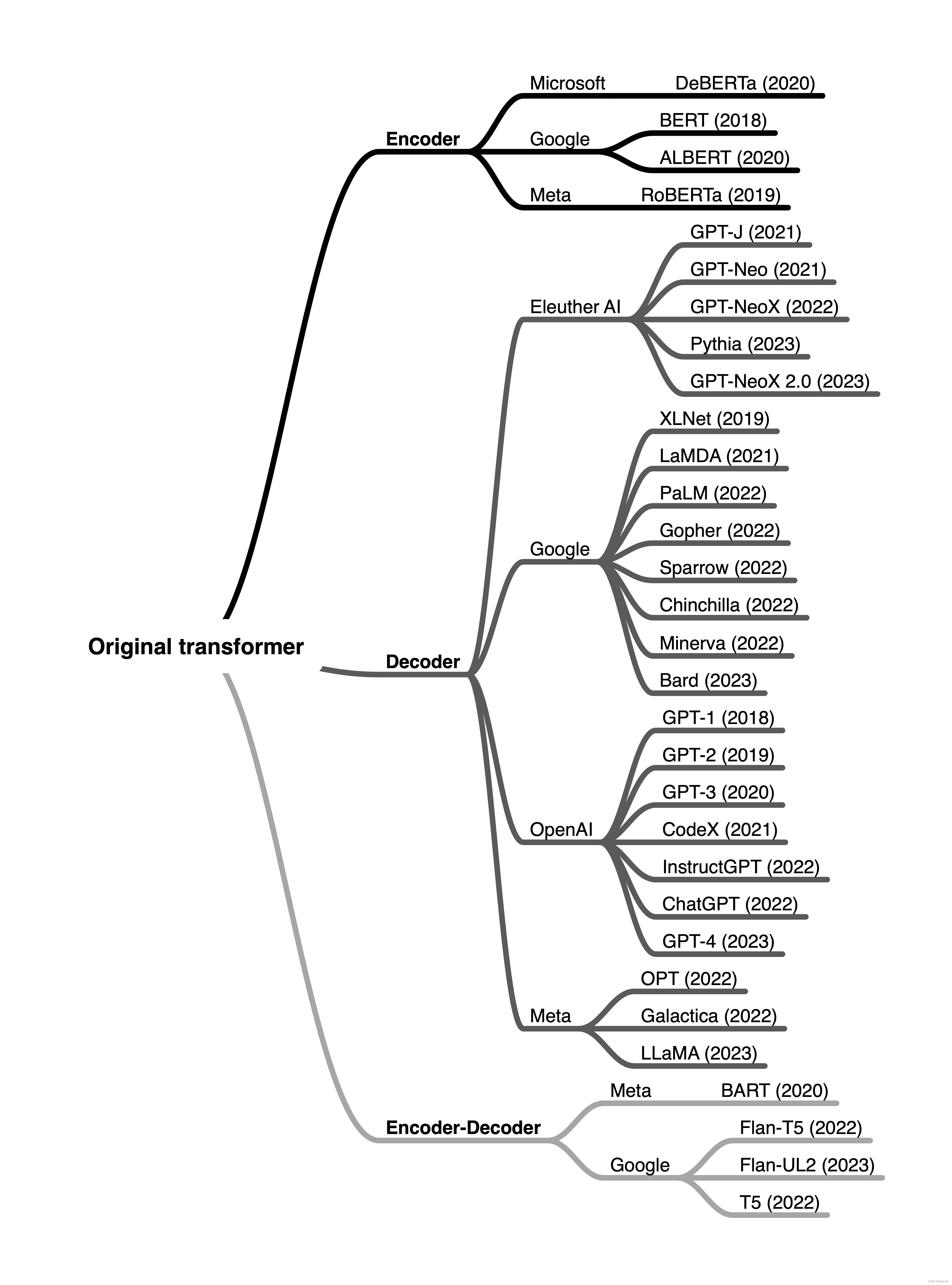
While encoder-only models gradually lost in popularity, decoder-only models like GPT exploded in popularity thanks to breakthrough in text generation via GPT-3, ChatGPT, and GPT-4. However, encoder-only models are still very useful for training predictive models based on text embeddings versus generating texts.
虽然 encoder-only 模型逐渐失去了人气,但像GPT这样的 decoder-only 模型因GPT-3、ChatGPT和GPT-4在文本生成方面的突破而爆炸性增长。然而,encoder-only 模型在基于文本嵌入的预测模型训练方面仍然非常有用,与生成文本相比。
References
- Understanding Encoder And Decoder LLMs
- LLM的3种架构:Encoder-only、Decoder-only、encode-decode


![[SWPUCTF 2021 新生赛]include](https://img-blog.csdnimg.cn/direct/5e36a8c8426a408d97af45254267aca2.png)