需要提前部署好 Zookeeper/Hadoop/Hive 环境
1 Local模式
1.1 上传压缩包
下载链接
链接:https://pan.baidu.com/s/1rLq39ddxh7np7JKiuRAhDA?pwd=e20h
提取码:e20h
将spark-3.1.2-bin-hadoop3.2.tar.gz压缩包到node1下的/export/server目录
1.2 解压压缩包
tar -zxvf /export/server/spark-3.1.2-bin-hadoop3.2.tgz -C /export/server/
1.3 修改权限
如果有权限问题,可以修改为root,方便学习时操作,实际中使用运维分配的用户和权限即可
chown -R root /export/server/spark-3.1.2-bin-hadoop3.2
chgrp -R root /export/server/spark-3.1.2-bin-hadoop3.2
1.4 修改文件名
mv /export/server/spark-3.1.2-bin-hadoop3.2 /export/server/spark
1.5 将spark添加到环境变量
echo 'export SPARK_HOME=/export/server/spark' >> /etc/profile
echo 'export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin' >> /etc/profile
source /etc/profile
1.6 启动测试
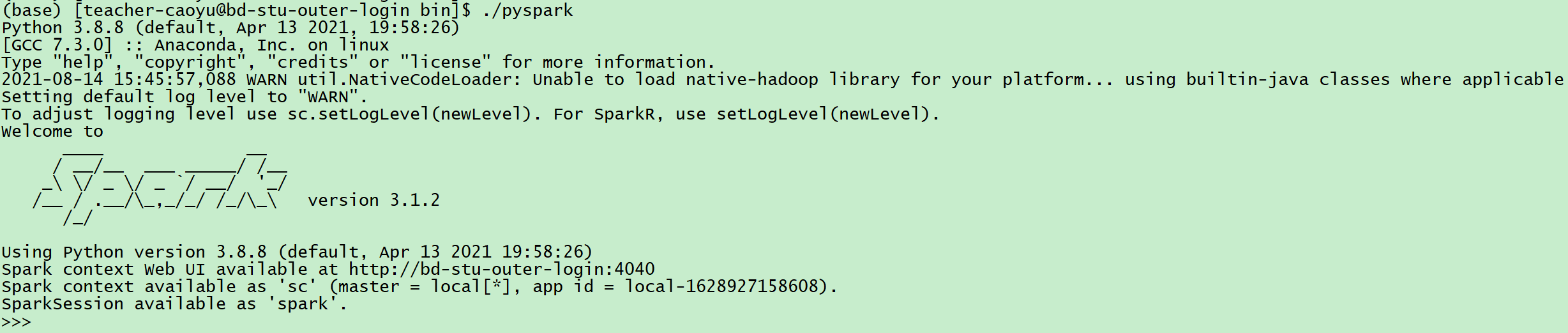
spark-shell
2 Standalone模式
2.1 配置node1中的workers服务
# 进入配置目录
cd /export/server/spark/conf
# 修改配置文件名称
mv workers.template workers
# 将三台机器写入workers
echo 'node1' > workers
echo 'node2' >> workers
echo 'node3' >> workers
2.2 配置spark中的环境变量
cd /export/server/spark/conf
## 修改配置文件名称
mv spark-env.sh.template spark-env.sh
## 修改配置文件
## 设置JAVA安装目录,jdk1.8.0_65 看自己的java目录和版本填写
echo 'JAVA_HOME=/export/server/jdk1.8.0_65' >> spark-env.sh
## 设置python安装目录
echo 'PYSPARK_PYTHON=/export/server/python3/bin/python3' >> spark-env.sh
## HADOOP软件配置文件目录,读取HDFS上文件
echo 'HADOOP_CONF_DIR=/export/server/hadoop-3.3.0/etc/hadoop' >> spark-env.sh
## 指定spark老大Master的IP和提交任务的通信端口
echo 'SPARK_MASTER_HOST=node1' >> spark-env.sh
echo 'SPARK_MASTER_PORT=7077' >> spark-env.sh
echo 'SPARK_MASTER_WEBUI_PORT=8080' >> spark-env.sh
echo 'SPARK_WORKER_CORES=1' >> spark-env.sh
echo 'SPARK_WORKER_MEMORY=1g' >> spark-env.sh
echo 'SPARK_WORKER_PORT=7078' >> spark-env.sh
echo 'SPARK_WORKER_WEBUI_PORT=8081' >> spark-env.sh
## 历史日志服务器
echo 'SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"' >> spark-env.sh
2.3 创建EventLogs存储目录
启动HDFS服务,创建应用运行事件日志目录
hdfs dfs -mkdir -p /sparklog/
hdfs dfs -chown hadoop:root /sparklog
hdfs dfs -chmod 775 /sparklog
2.4 配置Spark应用保存EventLogs
## 进入配置目录
cd /export/server/spark/conf
## 修改配置文件名称
mv spark-defaults.conf.template spark-defaults.conf
## 添加内容如下:
echo 'spark.eventLog.enabled true' >> spark-defaults.conf
echo 'spark.eventLog.dir hdfs://node1:8020/sparklog/' >> spark-defaults.conf
echo 'spark.eventLog.compress true' >> spark-defaults.conf
2.5 设置日志级别
## 进入目录
cd /export/server/spark/conf
## 修改日志属性配置文件名称
mv log4j.properties.template log4j.properties
## 改变日志级别
sed -i "1,25s/INFO/WARN/" /export/server/spark/conf/log4j.properties
2.6 修改启动文件
避免和hadopp的启动文件名字冲突
mv /export/server/spark/sbin/stop-all.sh /export/server/spark/sbin/stop-all-spark.sh
mv /export/server/spark/sbin/start-all.sh /export/server/spark/sbin/start-all-spark.sh
2.7 拷贝spark到node2和node3
scp -r /export/server/spark node2:/export/server/
scp -r /export/server/spark node3:/export/server/
2.8 拷贝python到node2和node3
scp -r /export/server/python3 node2:/export/server/
scp -r /export/server/python3 node3:/export/server/
2.9 拷贝环境变量文件到node2和node3
scp /etc/profile node2:/etc/
scp /etc/profile node3:/etc/
2.10 服务启动
- 集群启动,在node1上执行
# 启动spark
start-all-spark.sh
# 启动历史服务
start-history-server.sh
2.11 测试
- 使用pyspark连接
spark-shell --master spark://node1:7077
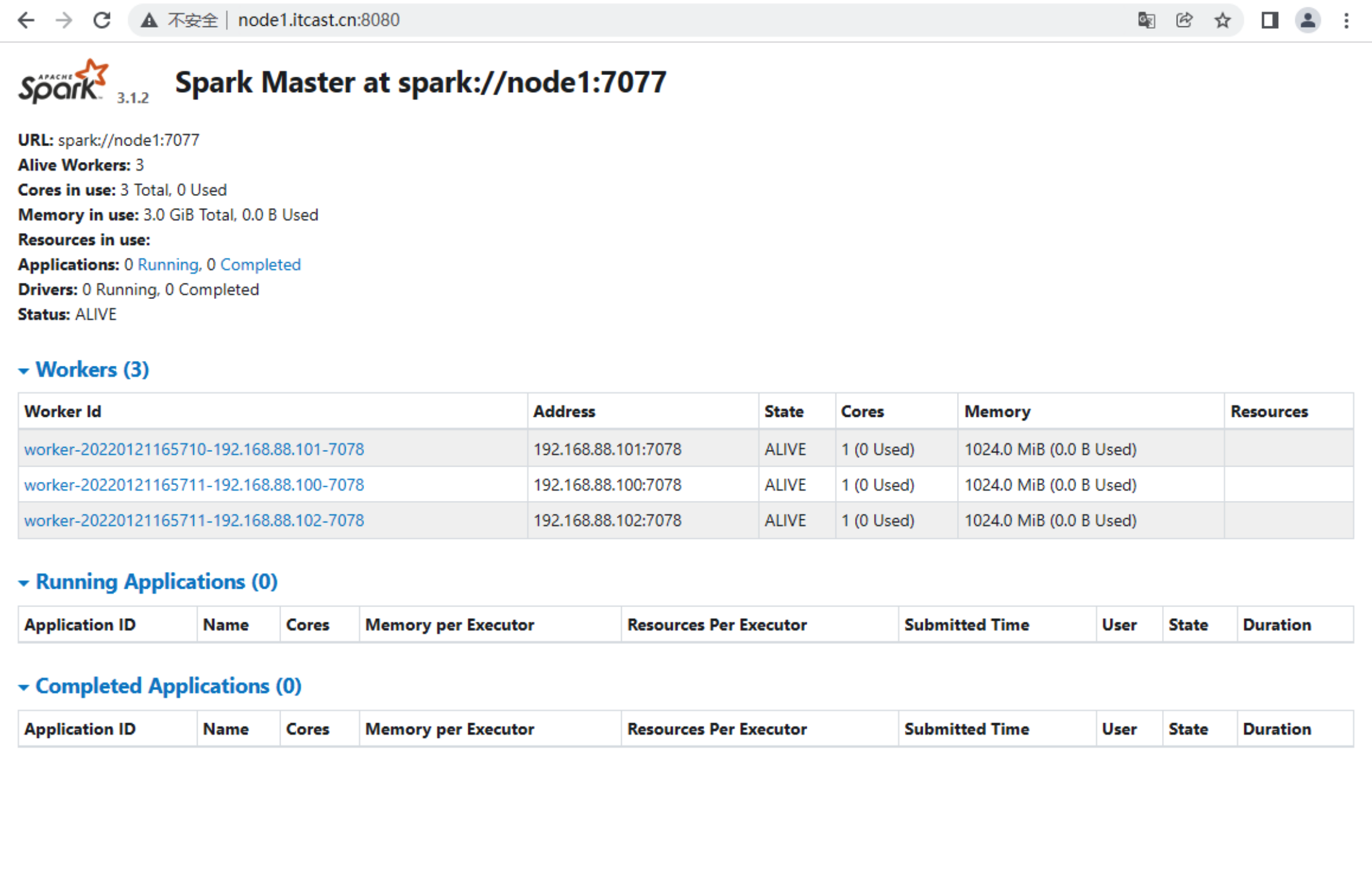
2.12 Web访问
http://node1:8080
3 Standalone高可用
3.1 关闭集群服务
stop-all-spark.sh
3.2 在node1上进行配置
将/export/server/spark/conf/spark-env.sh文件中的SPARK_MASTER_HOST注释
# SPARK_MASTER_HOST=node1echo 'SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"' >> /export/server/spark/conf/spark-env.sh
3.3 将node1的配置文件进行分发
cd /export/server/spark/conf
scp -r spark-env.sh node2:$PWD
scp -r spark-env.sh node3:$PWD
3.4 三台机器启动集群上的zk服务
zkServer.sh start
3.5 在HDFS上创建高可用日志目录
hadoop fs -mkdir /spark-ha
3.6 node1上启动spark集群
start-all-spark.sh
3.7 在node2上启动master
start-master.sh
3.8 web验证
http://node1:8080
node2:8080
4 Python安装
4.1 上传安装包
链接:https://pan.baidu.com/s/1LkpjREnLXLzebki4VTz1Ag?pwd=6bs5
提取码:6bs5
将python3.tar.gz压缩包到node1下的/export/server目录
4.2 解压安装包
tar -zxvf /export/server/python3.tar.gz -C /export/server
4.3 将Python添加到环境变量
echo 'export PYTHON_HOME=/export/server/python3' >> /etc/profile
echo 'export PATH=$PATH:$PYTHON_HOME/bin' >> /etc/profile
source /etc/profile
4.4 拷贝python到node2和node3
scp -r /export/server/python3 node2:/export/server/
scp -r /export/server/python3 node3:/export/server/
4.5 启动测试
pyspark
5 Pysaprk的安装
当前spark依赖的版本为3.1.2
5.1 在线安装
pip3 install pyspark==3.1.2 -i https://pypi.tuna.tsinghua.edu.cn/simple/
5.2 离线安装
链接:https://pan.baidu.com/s/1bZD0KbpXlUYb4UZBtCodAw?pwd=zcsx
提取码:zcsx
上传
spark_packages到root目录下
cd /root/spark_packages
pip3 install --no-index --find-links=spark_packages -r requirements.txt
5.2.1 三台机器环境变量调整
echo 'export ZOOKEEPER_HOME=/export/server/zookeeper' >> /etc/bashrc
echo 'export PATH=$PATH:$ZOOKEEPER_HOME/bin' >> /etc/bashrc
echo 'export JAVA_HOME=/export/server/jdk1.8.0_241' >> /etc/bashrc
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/bashrc
echo 'export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar' >> /etc/bashrc
echo 'export HADOOP_HOME=/export/server/hadoop-3.3.0' >> /etc/bashrc
echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin' >> /etc/bashrc
echo 'export HIVE_HOME=/export/server/hive3.1.2' >> /etc/bashrc
echo 'export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/sbin' >> /etc/bashrc
echo 'export PYTHON_HOME=/export/server/python3' >> /etc/bashrc
echo 'export PATH=$PATH:$PYTHON_HOME/bin' >> /etc/bashrc
echo 'export PYSPARK_PYTHON=/export/server/python3/bin/python3' >> /etc/bashrc
echo 'export PYSPARK_DRIVER_PYTHON=/export/server/python3/bin/python3' >> /etc/bashrc
echo 'export SPARK_HOME=/export/server/spark' >> /etc/bashrc
echo 'export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin' >> /etc/bashrcsource /etc/bashrc
6 Spark on Yarn模式
6.1 修改spark-env.sh
cd /export/server/spark/conf
echo 'YARN_CONF_DIR=/export/server/hadoop-3.3.0/etc/hadoop' >> spark-env.sh
6.2 同步到node2和node3
scp -r spark-env.sh node2:/export/server/spark/conf
scp -r spark-env.sh node3:/export/server/spark/conf
6.3 整合历史服务器MRHistoryServer并关闭资源检查
需要修改Hadoop的yarn-site.xml文件
- 进入Hadoop配置目录
cd /export/server/hadoop-3.3.0/etc/hadoop
- 修改yarn-site.xml配置文件
<configuration><!-- 配置yarn主节点的位置 --><property><name>yarn.resourcemanager.hostname</name><value>node1</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 设置yarn集群的内存分配方案 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>20480</value></property><property><name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value></property><property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value></property><!-- 开启日志聚合功能 --><property><name>yarn.log-aggregation-enable</name><value>true</value></property><!-- 设置聚合日志在hdfs上的保存时间 --><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property><!-- 设置yarn历史服务器地址 --><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value></property><!-- 关闭yarn内存检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
</configuration>
- 拷贝到node2和node3
cd /export/server/hadoop-3.3.0/etc/hadoop
scp -r yarn-site.xml node2:/export/server/hadoop-3.3.0/etc/hadoop
scp -r yarn-site.xml node3:/export/server/hadoop-3.3.0/etc/hadoop
6.4 修改spark配置文件
cd /export/server/spark/conf
echo 'spark.yarn.historyServer.address node1:18080' >> spark-defaults.conf
- 复制到node2和node3
cd /export/server/spark/conf
scp -r spark-defaults.conf node2:/export/server/spark/conf
scp -r spark-defaults.conf node3:/export/server/spark/conf
6.5 启动服务
start-all.sh
mapred --daemon start historyserver
start-history-server.sh
spark-submit --master yarn --deploy-mode client 文件


![[SWPUCTF 2021 新生赛]include](https://img-blog.csdnimg.cn/direct/5e36a8c8426a408d97af45254267aca2.png)