Faster-RCNN ,Mask-RCNN原理
- 一、摘要
- 1.1 图像分割
- 1.2 语义分割与实例分割
- 二、Faster-RCNN
- 2.1 Faster-RCNN模型架构
- 2.2 🍊深度卷积网络(backbone)
- 2.3 🍎RPN(Region Proposal Network)
- 2.4 🍉RoI Pooling
- 2.5 🍈分类与回归
- 2.6 Faster-RCNN总结
- 三、Mask-RCNN
一、摘要
1.1 图像分割
图像分割:图像分割是对图像中属于特定类别的像素进行分类的过程叫图像分割,属于pixel-wise即像素级别的下游任务。简单来说,图像分割就是按像素进行分类的问题。
传统的图像分割算法是基于灰度值的不连续性和相似的性质来进行分割,而深度学习则是利用卷积神经网络,来理解图像中的每个像素所代表的含义。
基于深度学习的图像分割技术主要分为这两类:语义分割及实例分割。
1.2 语义分割与实例分割
语义分割:语义分割会为图像中的每个像素分配一个类别,但是同一个类别之间的对象不会进行区分。具体来说,语义分割的目的是为了从像素级别理解图像的内容,并为图像中的每个像素分配一个类。
实例分割:实例分割只对特定的物体进行分类,这看起来和目标检测类似,不同的是目标检测输出目标的最小外界矩阵和类别,而实例分割输出的目标的Mask和类别。
概括来说,语义分割只能划分类别,而同类无法划分,因此部分场景在语义分割之后还需要进一步用实例分割来划分同类别的不同实例,如fig.1中的b与c所示。

二、Faster-RCNN
2.1 Faster-RCNN模型架构
Faster-RCNN可以大致分成四个模块,如Fig.2所示,细节如图Fig.3所示:
🍊深度卷积网络(backbone):即特征提取网络,用于特征提取。通过若干卷积+池化+激活层等组成来提取图像的feature maps,用于后续的RPN层和提取proposal。
🍎RPN(Region Proposal Network):即区域候选网络,该部分代替了RCNN与Fast RCNN的SS算法来生成候选框,该部分有两个任务,一个是分类,判断所有预设anchor是属于positive还是negative(即anchor内是否有目标,二分类),还有一个任务就是边界框回归,修正anchors来得到较为准确的proposals。
🍉RoI Pooling :即兴趣域池化,用于收集RPN生成的Proposals(每个框的坐标),并从1中提取出来,生成Proposals feature maps送入全连接层来判断类别和回归。
🍈分类与回归 :利用Proposals feature maps计算出具体类别,同时再做一次边界框回归获得最终的检测位置。
下面将围绕这四块分别展开:


2.2 🍊深度卷积网络(backbone)
需要注意的是,这里我们以VGG为骨干网络作为例子来讲解(如Fig.4所示),实际情况中我们可以根据需要选择Resnet50,101或者mobilenet来作为特征提取网络。
输入:先将图像resize成M*N的输入尺寸,一般在VGG中,输入图像的尺寸为224×224。
特征提取网络:可以从图中看到,特征提取网络包含了13个conv层,13个relu激活层,以及4个池化层(原VGG网络中包含了5个池化层,这里舍弃了最后一层池化层)。在VGG网络中,采用的是3×3的卷积核,以及2×2的池化核,池化后的特征图尺寸减半。因此,经过特征提取网络之后,输处特征图的尺寸为输入的1/16,即M/16×N/16。

2.3 🍎RPN(Region Proposal Network)
首先,在讲RPN之前,我们需要明确的一点是,RPN的作用是提取候选框,RPN结构如Fig.5所示。
经过上一步,我们已经得到了M/16×N/16大小的特征图,可以看到我们将会对我们得到的特征图并行的进行两步操作,分别是沿着路径1的RPN操作以及沿着路径2的ROI Pooling操作。这一部分我们讲RPN操作。
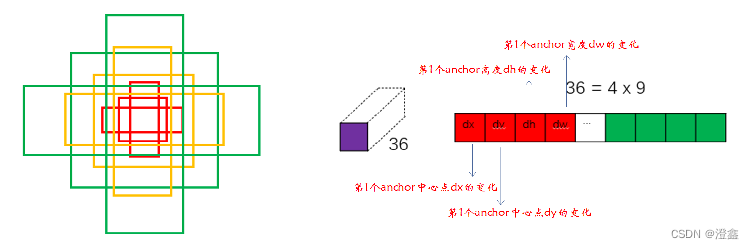
我们会使用一个3×3的滑动窗口来遍历刚刚得到的特征图,然后计算出滑动窗口中心点坐标对应的原始图像上的中心点坐标,最后在原始图像上的每个中心点或者叫像素点绘制9中不同尺度的anchor boxes。
上一部分讲到了在得到的特征图上使用一个3×3的模板遍历特征图,这对应了图中的3×3的卷积操作,其中padding=1,stride=1。那么问题来了,如何将特征图的中心点坐标对应原图的中心点呢,前面我们讲到了VGG网络输入图像与输出特征图的尺寸关系是1/16,因此我们只需要将特征图上的中心点坐标乘以16即可。下一步就是在原图上画出基于中心点的9个锚框了,论文中给出的是三种尺度(128,256,512),每种尺度对应的比例是(1:1,1:2,2:1),这个尺度其实是一种经验设计,可以根据实际项目的需求来调整大小,如图Fig.6。
在3×3的卷积核遍历完特征图之后,原图会产生许多许多的anchor,其中大部分的anchor都是我们不需要的,后面的操作会对这些anchor进行取舍,如Fig.7。
接下来我们来看一下3×3的卷积后,特征图的变化,由于我们采用的是3×3尺寸的卷积核,padding=1,stride=1的卷积,因此卷积后的特征图尺寸并没有变化(scale+2×padding-kernelsize/stride + 1 = 14),因此可以看出,卷积后的特征图尺寸没有变化。512则是指VGG网络的最后一层的通道数为512(由卷积核的个数决定),如Fig.8所示。




首先,来讲路径3,路径3设置了一个11的卷积核,卷积核个数为18,经过这一层的卷积之后,得到的特征图尺寸没变,但是通道数变成了18,这18个通道的作用就是用于区分每个中心点对应的9个anchor是前景还是背景,对每一个anchor进行一个二分类,即29=18。
我们以特征图上的一个位置为例,将其展开,可以将18个通道分为两两一组,每一组的第一个值为第一个anchor的前景概率,第二个值为第一个anchor的背景概率,以此类推,如Fig.10所示。


了解了前面的正负样本匹配的问题,现在我们来看路径4,同样是一个1×1的卷积核,卷积核个数为36,这里的36=4×9,即对应了9种不同尺度anchor的对应的坐标调整参数(dx,dy,dh,dw)。

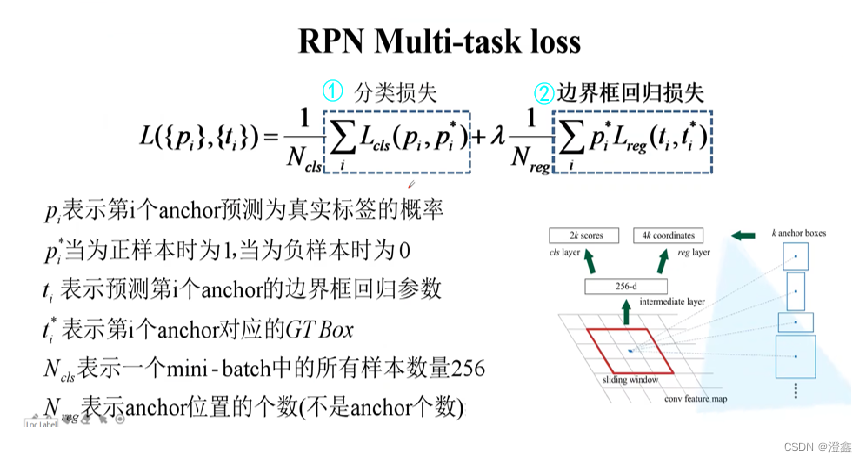
最后,便是RPN部分的损失函数:
分类损失用的是softmax损失函数。
位置误差损失需要强调的是对先验框与GT box的回归值和预测框与GT box的回归值之间的L1范数构建损失函数。

2.4 🍉RoI Pooling
ROI Pooling层的输入由两个:原始的feature maps和RPN输出的Proposals。
需要说明的是,我们传入ROI Pooling层的输入为原始特征图和RPN输出的的候选框对应到原始特征图的不同部分,然后将这些部分裁剪下来传入到ROI Pooling层中。
每一块ROI区域都将被采用池化的方式resize成同样的尺寸(7*7),最后送入softmax进行分类以及box的预测。

2.5 🍈分类与回归
通过两层relu激活函数和全连接层,将我们的ROI Pooling后的区域展平,送入到Softmax分类器中分类,以及box_pred中微调预测框的位置,其中损失函数如下图所示,分为分类损失和回归框损失:



2.6 Faster-RCNN总结
-
将完整的图像输入特征提取网络得到特征图
-
使用RPN结构生成候选框信息,将RPN生成的候选框位置投影到原始的特征图的对应位置,得到对应的特征矩阵。
-
使用ROI Pooling层将输入的候选区域通过池化的方式resize成一个尺寸,并将特征图送入全连接层中展平进行预测框的微调以及分类。
(Mask-RCNN未完待续,今天先休息了)。