使用 PyTorch C++ 前端
原文:
pytorch.org/tutorials/advanced/cpp_frontend.html译者:飞龙
协议:CC BY-NC-SA 4.0
PyTorch C++ 前端是 PyTorch 机器学习框架的纯 C++ 接口。虽然 PyTorch 的主要接口自然是 Python,但这个 Python API 坐落在一个庞大的 C++ 代码库之上,提供了基础数据结构和功能,如张量和自动微分。C++ 前端暴露了一个纯 C++11 API,扩展了这个底层 C++ 代码库,提供了用于机器学习训练和推断所需的工具。这包括一个内置的常见神经网络建模组件集合;一个 API 用于扩展此集合以添加自定义模块;一个流行的优化算法库,如随机梯度下降;一个并行数据加载器,具有定义和加载数据集的 API;序列化例程等。
本教程将带您完成一个使用 C++ 前端训练模型的端到端示例。具体来说,我们将训练一个DCGAN - 一种生成模型 - 生成 MNIST 数字的图像。虽然在概念上是一个简单的例子,但应该足以让您快速了解 PyTorch C++ 前端,并激发您对训练更复杂模型的兴趣。我们将从一些激励性的话语开始,解释为什么您首先要使用 C++ 前端,然后直接进入定义和训练我们的模型。
提示
观看来自 CppCon 2018 的这个闪电演讲,了解有关 C++ 前端的快速(而幽默)介绍。
提示
这个注释提供了对 C++ 前端组件和设计理念的概述。
提示
PyTorch C++ 生态系统的文档可在pytorch.org/cppdocs找到。在那里,您可以找到高级描述以及 API 级文档。
动机
在我们激动人心的 GAN 和 MNIST 数字之旅开始之前,让我们退后一步,讨论为什么您首选使用 C++ 前端而不是 Python 前端。我们(PyTorch 团队)创建了 C++ 前端,以便在无法使用 Python 或简单不适合工作的环境中进行研究。这种环境的示例包括:
-
低延迟系统:您可能希望在具有高每秒帧数和低延迟要求的纯 C++ 游戏引擎中进行强化学习研究。在这种环境中,使用纯 C++ 库比使用 Python 库更合适。由于 Python 解释器的速度慢,Python 可能根本无法胜任。
-
高度多线程环境:由于全局解释器锁(GIL),Python 无法同时运行多个系统线程。多进程是一种替代方法,但不如可扩展且存在重大缺陷。C++ 没有这样的约束,线程易于使用和创建。需要大量并行化的模型,如深度神经进化中使用的模型,可以从中受益。
-
现有的 C++ 代码库:您可能是一个现有的 C++ 应用程序的所有者,从在后端服务器中提供网页到在照片编辑软件中渲染 3D 图形,希望将机器学习方法集成到您的系统中。C++ 前端允许您保持在 C++ 中,避免在 Python 和 C++ 之间来回绑定的麻烦,同时保留传统 PyTorch(Python)体验的灵活性和直观性的大部分。
C++前端并不打算与 Python 前端竞争。它旨在补充它。我们知道研究人员和工程师都喜欢 PyTorch 的简单性、灵活性和直观的 API。我们的目标是确保您可以在包括上述环境在内的每一个可能的环境中利用这些核心设计原则。如果其中一个场景很好地描述了您的用例,或者您只是感兴趣或好奇,请跟随我们在接下来的段落中详细探讨 C++前端。
提示
C++前端试图提供尽可能接近 Python 前端的 API。如果您熟悉 Python 前端,并且有时会问自己“如何在 C++前端中做 X?”,请像在 Python 中一样编写代码,很多时候相同的函数和方法将在 C++中和 Python 中都可用(只需记住用双冒号替换点)。
编写一个基本应用程序
让我们从编写一个最小的 C++应用程序开始,以验证我们在设置和构建环境方面是否一致。首先,您需要获取LibTorch分发 - 我们准备好的 zip 存档,其中包含所有相关的头文件、库和 CMake 构建文件,以便使用 C++前端所需。LibTorch 分发可在PyTorch 网站上下载,适用于 Linux、MacOS 和 Windows。本教程的其余部分将假定一个基本的 Ubuntu Linux 环境,但您也可以在 MacOS 或 Windows 上跟随操作。
提示
安装 PyTorch 的 C++分发上的说明更详细地描述了以下步骤。
提示
在 Windows 上,调试版本和发布版本不兼容。如果您计划以调试模式构建项目,请尝试 LibTorch 的调试版本。此外,请确保在下面的cmake --build .行中指定正确的配置。
第一步是通过从 PyTorch 网站检索的链接在本地下载 LibTorch 分发。对于一个普通的 Ubuntu Linux 环境,这意味着运行:
# If you need e.g. CUDA 9.0 support, please replace "cpu" with "cu90" in the URL below.
wget https://download.pytorch.org/libtorch/nightly/cpu/libtorch-shared-with-deps-latest.zip
unzip libtorch-shared-with-deps-latest.zip
接下来,让我们编写一个名为dcgan.cpp的小型 C++文件,其中包含torch/torch.h,目前只是简单地打印出一个三乘三的单位矩阵:
#include <torch/torch.h>
#include <iostream>int main() {torch::Tensor tensor = torch::eye(3);std::cout << tensor << std::endl;
}
为了构建这个小应用程序以及稍后我们的完整训练脚本,我们将使用这个CMakeLists.txt文件:
cmake_minimum_required(VERSION 3.0 FATAL_ERROR)
project(dcgan)find_package(Torch REQUIRED)add_executable(dcgan dcgan.cpp)
target_link_libraries(dcgan "${TORCH_LIBRARIES}")
set_property(TARGET dcgan PROPERTY CXX_STANDARD 14)
注意
虽然 CMake 是 LibTorch 的推荐构建系统,但这不是硬性要求。您也可以使用 Visual Studio 项目文件、QMake、普通的 Makefiles 或任何您感觉舒适的其他构建环境。但是,我们不提供这方面的开箱即用支持。
在上面的 CMake 文件中注意第 4 行:find_package(Torch REQUIRED)。这指示 CMake 查找 LibTorch 库的构建配置。为了让 CMake 知道在哪里找到这些文件,我们在调用cmake时必须设置CMAKE_PREFIX_PATH。在这之前,让我们就我们的dcgan应用程序达成以下目录结构的一致意见:
dcgan/CMakeLists.txtdcgan.cpp
此外,我将把解压后的 LibTorch 分发的路径称为/path/to/libtorch。请注意这必须是绝对路径。特别是,将CMAKE_PREFIX_PATH设置为类似../../libtorch的内容会以意想不到的方式中断。相反,请写$PWD/../../libtorch以获得相应的绝对路径。现在,我们已经准备好构建我们的应用程序:
root@fa350df05ecf:/home# mkdir build
root@fa350df05ecf:/home# cd build
root@fa350df05ecf:/home/build# cmake -DCMAKE_PREFIX_PATH=/path/to/libtorch ..
-- The C compiler identification is GNU 5.4.0
-- The CXX compiler identification is GNU 5.4.0
-- Check for working C compiler: /usr/bin/cc
-- Check for working C compiler: /usr/bin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Detecting C compile features
-- Detecting C compile features - done
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Looking for pthread.h
-- Looking for pthread.h - found
-- Looking for pthread_create
-- Looking for pthread_create - not found
-- Looking for pthread_create in pthreads
-- Looking for pthread_create in pthreads - not found
-- Looking for pthread_create in pthread
-- Looking for pthread_create in pthread - found
-- Found Threads: TRUE
-- Found torch: /path/to/libtorch/lib/libtorch.so
-- Configuring done
-- Generating done
-- Build files have been written to: /home/build
root@fa350df05ecf:/home/build# cmake --build . --config Release
Scanning dependencies of target dcgan
[ 50%] Building CXX object CMakeFiles/dcgan.dir/dcgan.cpp.o
[100%] Linking CXX executable dcgan
[100%] Built target dcgan
在上面,我们首先在我们的dcgan目录中创建了一个build文件夹,进入这个文件夹,运行cmake命令生成必要的构建(Make)文件,最后通过运行cmake --build . --config Release成功编译了项目。现在我们已经准备好执行我们的最小二进制文件,并完成这一部分关于基本项目配置的内容:
root@fa350df05ecf:/home/build# ./dcgan
1 0 0
0 1 0
0 0 1
[ Variable[CPUFloatType]{3,3} ]
对我来说看起来像一个单位矩阵!
定义神经网络模型
现在我们已经配置好基本环境,我们可以深入到本教程的更有趣的部分。首先,我们将讨论如何在 C++前端定义和交互模块。我们将从基本的小规模示例模块开始,然后使用 C++前端提供的大量内置模块库实现一个完整的 GAN。
模块 API 基础
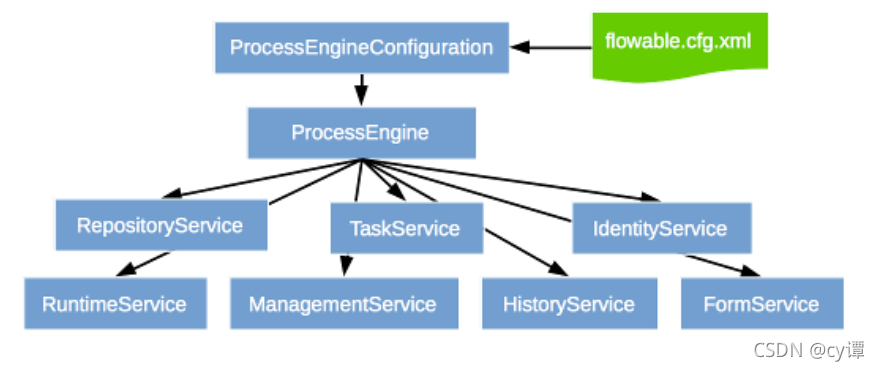
与 Python 接口一致,基于 C++前端的神经网络由可重用的构建块称为模块组成。有一个基本模块类,所有其他模块都是从这个类派生的。在 Python 中,这个类是torch.nn.Module,在 C++中是torch::nn::Module。除了实现模块封装的算法的forward()方法外,模块通常包含三种类型的子对象:参数、缓冲区和子模块。
参数和缓冲区以张量形式存储状态。参数记录梯度,而缓冲区不记录。参数通常是神经网络的可训练权重。缓冲区的示例包括批量归一化的均值和方差。为了重复使用特定的逻辑块和状态,PyTorch API 允许模块嵌套。嵌套模块称为子模块。
参数、缓冲区和子模块必须显式注册。一旦注册,就可以使用parameters()或buffers()等方法来检索整个(嵌套的)模块层次结构中的所有参数的容器。类似的方法,比如to(...),例如to(torch::kCUDA)将所有参数和缓冲区从 CPU 移动到 CUDA 内存,适用于整个模块层次结构。
定义模块和注册参数
为了将这些话语转化为代码,让我们考虑这个简单的模块在 Python 接口中编写:
import torchclass Net(torch.nn.Module):def __init__(self, N, M):super(Net, self).__init__()self.W = torch.nn.Parameter(torch.randn(N, M))self.b = torch.nn.Parameter(torch.randn(M))def forward(self, input):return torch.addmm(self.b, input, self.W)
在 C++中,它看起来像这样:
#include <torch/torch.h>struct Net : torch::nn::Module {Net(int64_t N, int64_t M) {W = register_parameter("W", torch::randn({N, M}));b = register_parameter("b", torch::randn(M));}torch::Tensor forward(torch::Tensor input) {return torch::addmm(b, input, W);}torch::Tensor W, b;
};
就像在 Python 中一样,我们定义了一个名为Net的类(这里简单起见使用struct而不是class),并将其派生自模块基类。在构造函数内部,我们使用torch::randn创建张量,就像我们在 Python 中使用torch.randn一样。一个有趣的区别是我们如何注册参数。在 Python 中,我们用torch.nn.Parameter类包装张量,而在 C++中,我们必须通过register_parameter方法传递张量。这样做的原因是 Python API 可以检测到属性的类型是torch.nn.Parameter并自动注册这样的张量。在 C++中,反射非常有限,因此提供了一种更传统(也更少神奇)的方法。
注册子模块和遍历模块层次结构
我们可以像注册参数一样注册子模块。在 Python 中,当将子模块分配为模块的属性时,子模块会自动检测并注册:
class Net(torch.nn.Module):def __init__(self, N, M):super(Net, self).__init__()# Registered as a submodule behind the scenesself.linear = torch.nn.Linear(N, M)self.another_bias = torch.nn.Parameter(torch.rand(M))def forward(self, input):return self.linear(input) + self.another_bias
例如,可以使用parameters()方法递归访问我们模块层次结构中的所有参数:
>>> net = Net(4, 5)
>>> print(list(net.parameters()))
[Parameter containing:
tensor([0.0808, 0.8613, 0.2017, 0.5206, 0.5353], requires_grad=True), Parameter containing:
tensor([[-0.3740, -0.0976, -0.4786, -0.4928],[-0.1434, 0.4713, 0.1735, -0.3293],[-0.3467, -0.3858, 0.1980, 0.1986],[-0.1975, 0.4278, -0.1831, -0.2709],[ 0.3730, 0.4307, 0.3236, -0.0629]], requires_grad=True), Parameter containing:
tensor([ 0.2038, 0.4638, -0.2023, 0.1230, -0.0516], requires_grad=True)]
在 C++中注册子模块,使用名为register_module()的方法注册一个模块,如torch::nn::Linear:
struct Net : torch::nn::Module {Net(int64_t N, int64_t M): linear(register_module("linear", torch::nn::Linear(N, M))) {another_bias = register_parameter("b", torch::randn(M));}torch::Tensor forward(torch::Tensor input) {return linear(input) + another_bias;}torch::nn::Linear linear;torch::Tensor another_bias;
};
提示
您可以在torch::nn命名空间的文档中找到所有可用的内置模块列表,如torch::nn::Linear、torch::nn::Dropout或torch::nn::Conv2d。
关于上面代码的一个微妙之处是为什么子模块在构造函数的初始化列表中创建,而参数在构造函数体内创建。这有一个很好的原因,我们将在下面关于 C++前端所有权模型部分详细介绍。然而,最终结果是我们可以像在 Python 中一样递归访问我们的模块树的参数。调用parameters()返回一个std::vector<torch::Tensor>,我们可以对其进行迭代:
int main() {Net net(4, 5);for (const auto& p : net.parameters()) {std::cout << p << std::endl;}
}
它打印:
root@fa350df05ecf:/home/build# ./dcgan
0.0345
1.4456
-0.6313
-0.3585
-0.4008
[ Variable[CPUFloatType]{5} ]
-0.1647 0.2891 0.0527 -0.0354
0.3084 0.2025 0.0343 0.1824
-0.4630 -0.2862 0.2500 -0.0420
0.3679 -0.1482 -0.0460 0.1967
0.2132 -0.1992 0.4257 0.0739
[ Variable[CPUFloatType]{5,4} ]
0.01 *
3.6861
-10.1166
-45.0333
7.9983
-20.0705
[ Variable[CPUFloatType]{5} ]
就像在 Python 中一样有三个参数。为了查看这些参数的名称,C++ API 提供了一个named_parameters()方法,返回一个OrderedDict,就像在 Python 中一样:
Net net(4, 5);
for (const auto& pair : net.named_parameters()) {std::cout << pair.key() << ": " << pair.value() << std::endl;
}
我们可以再次执行以查看输出:
root@fa350df05ecf:/home/build# make && ./dcgan 11:13:48
Scanning dependencies of target dcgan
[ 50%] Building CXX object CMakeFiles/dcgan.dir/dcgan.cpp.o
[100%] Linking CXX executable dcgan
[100%] Built target dcgan
b: -0.1863
-0.8611
-0.1228
1.3269
0.9858
[ Variable[CPUFloatType]{5} ]
linear.weight: 0.0339 0.2484 0.2035 -0.2103
-0.0715 -0.2975 -0.4350 -0.1878
-0.3616 0.1050 -0.4982 0.0335
-0.1605 0.4963 0.4099 -0.2883
0.1818 -0.3447 -0.1501 -0.0215
[ Variable[CPUFloatType]{5,4} ]
linear.bias: -0.0250
0.0408
0.3756
-0.2149
-0.3636
[ Variable[CPUFloatType]{5} ]
注意
torch::nn::Module 的文档包含了在模块层次结构上操作的完整方法列表。
在前向模式下运行网络
要在 C++ 中执行网络,我们只需调用我们自己定义的 forward() 方法:
int main() {Net net(4, 5);std::cout << net.forward(torch::ones({2, 4})) << std::endl;
}
打印出类似于以下内容:
root@fa350df05ecf:/home/build# ./dcgan
0.8559 1.1572 2.1069 -0.1247 0.8060
0.8559 1.1572 2.1069 -0.1247 0.8060
[ Variable[CPUFloatType]{2,5} ]
模块所有权
在这一点上,我们知道如何在 C++ 中定义模块,注册参数,注册子模块,通过 parameters() 等方法遍历模块层次结构,最后运行模块的 forward() 方法。虽然在 C++ API 中还有许多方法、类和主题需要掌握,但我会引导您查看文档以获取完整的菜单。我们还将在实现 DCGAN 模型和端到端训练流水线时涉及一些更多的概念。在我们这样做之前,让我简要谈一下 C++ 前端为 torch::nn::Module 的子类提供的 所有权模型。
在这个讨论中,所有权模型指的是模块是如何存储和传递的 - 这决定了谁或什么 拥有 特定模块实例。在 Python 中,对象总是动态分配(在堆上)并具有引用语义。这非常容易使用和理解。事实上,在 Python 中,您可以基本上忘记对象位于何处以及它们如何被引用,而专注于完成任务。
C++ 作为一种较低级别的语言,在这个领域提供了更多选项。这增加了复杂性,并且严重影响了 C++ 前端的设计和人机工程学。特别是,在 C++ 前端的模块中,我们可以选择 要么 使用值语义 要么 使用引用语义。第一种情况是最简单的,迄今为止的示例中已经展示过:模块对象在堆栈上分配,当传递给函数时,可以被复制、移动(使用 std::move)或通过引用或指针传递:
struct Net : torch::nn::Module { };void a(Net net) { }
void b(Net& net) { }
void c(Net* net) { }int main() {Net net;a(net);a(std::move(net));b(net);c(&net);
}
对于第二种情况 - 引用语义 - 我们可以使用 std::shared_ptr。引用语义的优点是,就像在 Python 中一样,它减少了思考模块如何传递给函数以及如何声明参数的认知负担(假设您在所有地方都使用 shared_ptr)。
struct Net : torch::nn::Module {};void a(std::shared_ptr<Net> net) { }int main() {auto net = std::make_shared<Net>();a(net);
}
根据我们的经验,来自动态语言的研究人员更喜欢引用语义而不是值语义,尽管后者更“本地”于 C++。还要注意,torch::nn::Module 的设计为了保持与 Python API 的人机工程学接近,依赖于共享所有权。例如,考虑我们之前(这里缩短了)对 Net 的定义:
struct Net : torch::nn::Module {Net(int64_t N, int64_t M): linear(register_module("linear", torch::nn::Linear(N, M))){ }torch::nn::Linear linear;
};
为了使用 linear 子模块,我们希望直接将其存储在我们的类中。但是,我们也希望模块基类知道并能够访问这个子模块。为此,它必须存储对这个子模块的引用。在这一点上,我们已经到达了需要共享所有权的地步。torch::nn::Module 类和具体的 Net 类都需要对子模块的引用。因此,基类将模块存储为 shared_ptr,因此具体类也必须如此。
但等等!我在上面的代码中没有看到 shared_ptr 的提及!为什么呢?那是因为 std::shared_ptr<MyModule> 是一个很长的类型。为了保持我们的研究人员高效,我们想出了一个复杂的方案来隐藏 shared_ptr 的提及 - 这通常是保留给值语义的好处 - 同时保留引用语义。要了解这是如何工作的,我们可以看一下核心库中 torch::nn::Linear 模块的简化定义(完整定义在这里):
struct LinearImpl : torch::nn::Module {LinearImpl(int64_t in, int64_t out);Tensor forward(const Tensor& input);Tensor weight, bias;
};TORCH_MODULE(Linear);
简而言之:模块不叫Linear,而是LinearImpl。一个宏,TORCH_MODULE然后定义了实际的Linear类。这个“生成”的类实际上是std::shared_ptr<LinearImpl>的包装器。它是一个包装器而不是一个简单的 typedef,这样,构造函数仍然按预期工作,即你仍然可以写torch::nn::Linear(3, 4)而不是std::make_shared<LinearImpl>(3, 4)。我们称宏创建的类为模块持有者。就像(共享)指针一样,你可以使用箭头运算符访问底层对象(比如model->forward(...))。最终结果是一个所有权模型,与 Python API 非常接近。引用语义成为默认,但不需要额外输入std::shared_ptr或std::make_shared。对于我们的Net,使用模块持有者 API 看起来像这样:
struct NetImpl : torch::nn::Module {};
TORCH_MODULE(Net);void a(Net net) { }int main() {Net net;a(net);
}
这里有一个值得一提的微妙问题。一个默认构造的std::shared_ptr是“空的”,即包含一个空指针。一个默认构造的Linear或Net是什么?嗯,这是一个棘手的选择。我们可以说它应该是一个空(null)的std::shared_ptr<LinearImpl>。然而,请记住,Linear(3, 4)等同于std::make_shared<LinearImpl>(3, 4)。这意味着如果我们决定Linear linear;应该是一个空指针,那么就没有办法构造一个不带任何构造函数参数或默认所有参数的模块。因此,在当前的 API 中,一个默认构造的模块持有者(比如Linear())会调用底层模块的默认构造函数(LinearImpl())。如果底层模块没有默认构造函数,你会得到一个编译错误。要代替构造空的持有者,你可以将nullptr传递给持有者的构造函数。
在实践中,这意味着你可以像之前展示的那样使用子模块,其中模块在初始化列表中注册和构造:
struct Net : torch::nn::Module {Net(int64_t N, int64_t M): linear(register_module("linear", torch::nn::Linear(N, M))){ }torch::nn::Linear linear;
};
或者你可以首先用空指针构造持有者,然后在构造函数中分配给它(对 Python 程序员来说更熟悉):
struct Net : torch::nn::Module {Net(int64_t N, int64_t M) {linear = register_module("linear", torch::nn::Linear(N, M));}torch::nn::Linear linear{nullptr}; // construct an empty holder
};
总之:你应该使用哪种所有权模型 - 哪种语义?C++前端的 API 最好支持模块持有者提供的所有权模型。这种机制的唯一缺点是模块声明下方多了一行样板代码。也就是说,最简单的模型仍然是介绍 C++模块时展示的值语义模型。对于小型、简单的脚本,你也许可以使用它。但你迟早会发现,出于技术原因,它并不总是被支持。例如,序列化 API(torch::save和torch::load)只支持模块持有者(或普通的shared_ptr)。因此,模块持有者 API 是在 C++前端定义模块的推荐方式,我们将在本教程中继续使用这个 API。
定义 DCGAN 模块
现在我们已经有了必要的背景和介绍,来定义我们想要在这篇文章中解决的机器学习任务的模块。回顾一下:我们的任务是从MNIST 数据集生成数字图像。我们想要使用生成对抗网络(GAN)来解决这个任务。特别是,我们将使用DCGAN 架构 - 这是一种最早和最简单的架构之一,但完全足够解决这个任务。
提示
你可以在本教程中提供的完整源代码中找到:在这个存储库中。
什么是 GAN aGAN?
GAN 由两个不同的神经网络模型组成:一个生成器和一个鉴别器。生成器接收来自噪声分布的样本,其目的是将每个噪声样本转换为类似目标分布(在我们的情况下是 MNIST 数据集)的图像。鉴别器依次接收来自 MNIST 数据集的真实图像或来自生成器的假图像。它被要求发出一个概率,判断特定图像是多么真实(接近1)或假(接近0)。鉴别器对生成器生成的图像的真实程度的反馈用于训练生成器。对鉴别器对真实性的眼光有多好的反馈用于优化鉴别器。理论上,生成器和鉴别器之间的微妙平衡使它们共同改进,导致生成器生成的图像与目标分布中无法区分,欺骗鉴别器(那时)优秀的眼睛为真实和假图像都发出概率0.5。对我们来说,最终结果是一台机器,接收噪声作为输入,并生成逼真的数字图像作为输出。
生成器模块
我们首先定义生成器模块,它由一系列转置的 2D 卷积、批量归一化和 ReLU 激活单元组成。我们在自己定义的模块的forward()方法中以功能性的方式明确地在模块之间传递输入:
struct DCGANGeneratorImpl : nn::Module {DCGANGeneratorImpl(int kNoiseSize): conv1(nn::ConvTranspose2dOptions(kNoiseSize, 256, 4).bias(false)),batch_norm1(256),conv2(nn::ConvTranspose2dOptions(256, 128, 3).stride(2).padding(1).bias(false)),batch_norm2(128),conv3(nn::ConvTranspose2dOptions(128, 64, 4).stride(2).padding(1).bias(false)),batch_norm3(64),conv4(nn::ConvTranspose2dOptions(64, 1, 4).stride(2).padding(1).bias(false)){// register_module() is needed if we want to use the parameters() method later onregister_module("conv1", conv1);register_module("conv2", conv2);register_module("conv3", conv3);register_module("conv4", conv4);register_module("batch_norm1", batch_norm1);register_module("batch_norm2", batch_norm2);register_module("batch_norm3", batch_norm3);}torch::Tensor forward(torch::Tensor x) {x = torch::relu(batch_norm1(conv1(x)));x = torch::relu(batch_norm2(conv2(x)));x = torch::relu(batch_norm3(conv3(x)));x = torch::tanh(conv4(x));return x;}nn::ConvTranspose2d conv1, conv2, conv3, conv4;nn::BatchNorm2d batch_norm1, batch_norm2, batch_norm3;
};
TORCH_MODULE(DCGANGenerator);DCGANGenerator generator(kNoiseSize);
我们现在可以在DCGANGenerator上调用forward(),将噪声样本映射到图像上。
所选的特定模块,如nn::ConvTranspose2d和nn::BatchNorm2d,遵循了前面概述的结构。kNoiseSize常量确定了输入噪声向量的大小,设置为100。超参数当然是通过研究生下降法找到的。
注意
在发现超参数的过程中没有伤害到研究生。他们定期喂养 Soylent。
注意
关于在 C++前端将选项传递给内置模块如Conv2d的简短说明:每个模块都有一些必需的选项,比如BatchNorm2d的特征数量。如果您只需要配置必需的选项,您可以直接将它们传递给模块的构造函数,比如BatchNorm2d(128)或Dropout(0.5)或Conv2d(8, 4, 2)(用于输入通道数、输出通道数和核大小)。然而,如果您需要修改其他通常默认的选项,比如Conv2d的bias,您需要构造并传递一个options对象。C++前端中的每个模块都有一个相关的选项结构,称为ModuleOptions,其中Module是模块的名称,如Linear的LinearOptions。这就是我们上面对Conv2d模块所做的事情。
鉴别器模块
鉴别器同样是一系列卷积、批量归一化和激活函数。然而,这些卷积现在是常规的而不是转置的,我们使用带有 alpha 值 0.2 的 leaky ReLU 而不是普通的 ReLU。此外,最终激活函数变为 Sigmoid,将值压缩到 0 到 1 的范围内。然后,我们可以将这些压缩后的值解释为鉴别器分配给图像真实性的概率。
为了构建鉴别器,我们将尝试一些不同的方法:一个 Sequential 模块。就像在 Python 中一样,PyTorch 在这里提供了两种模型定义的 API:一种是功能性的,其中输入通过连续的函数传递(例如生成器模块示例),另一种是更面向对象的,我们构建一个包含整个模型的子模块的 Sequential 模块。使用 Sequential,鉴别器将如下所示:
nn::Sequential discriminator(// Layer 1nn::Conv2d(nn::Conv2dOptions(1, 64, 4).stride(2).padding(1).bias(false)),nn::LeakyReLU(nn::LeakyReLUOptions().negative_slope(0.2)),// Layer 2nn::Conv2d(nn::Conv2dOptions(64, 128, 4).stride(2).padding(1).bias(false)),nn::BatchNorm2d(128),nn::LeakyReLU(nn::LeakyReLUOptions().negative_slope(0.2)),// Layer 3nn::Conv2d(nn::Conv2dOptions(128, 256, 4).stride(2).padding(1).bias(false)),nn::BatchNorm2d(256),nn::LeakyReLU(nn::LeakyReLUOptions().negative_slope(0.2)),// Layer 4nn::Conv2d(nn::Conv2dOptions(256, 1, 3).stride(1).padding(0).bias(false)),nn::Sigmoid());
提示
Sequential模块简单地执行函数组合。第一个子模块的输出成为第二个的输入,第三个的输出成为第四个的输入,依此类推。
加载数据
现在我们已经定义了生成器和鉴别器模型,我们需要一些数据来训练这些模型。与 Python 一样,C++前端也配备了一个强大的并行数据加载器。这个数据加载器可以从数据集中读取数据批次(您可以自己定义),并提供许多配置选项。
注意
虽然 Python 数据加载器使用多进程,但 C++数据加载器是真正多线程的,不会启动任何新进程。
数据加载器是 C++前端的data api 的一部分,包含在torch::data::命名空间中。这个 API 由几个不同的组件组成:
-
数据加载器类,
-
用于定义数据集的 API,
-
用于定义变换的 API,可以应用于数据集,
-
用于定义采样器的 API,用于生成数据集的索引,
-
现有数据集、转换和采样器的库。
对于本教程,我们可以使用 C++前端提供的MNIST数据集。让我们为此实例化一个torch::data::datasets::MNIST,并应用两个转换:首先,我们将图像归一化,使其范围在-1到+1之间(从原始范围0到1)。其次,我们应用Stack整理,将一批张量堆叠成一个沿第一维的单个张量:
auto dataset = torch::data::datasets::MNIST("./mnist").map(torch::data::transforms::Normalize<>(0.5, 0.5)).map(torch::data::transforms::Stack<>());
请注意,MNIST 数据集应该位于您执行训练二进制文件的位置的./mnist目录中。您可以使用此脚本下载 MNIST 数据集。
接下来,我们创建一个数据加载器,并将其传递给这个数据集。要创建一个新的数据加载器,我们使用torch::data::make_data_loader,它返回正确类型的std::unique_ptr(这取决于数据集的类型、采样器的类型和一些其他实现细节):
auto data_loader = torch::data::make_data_loader(std::move(dataset));
数据加载器确实带有许多选项。您可以在这里查看完整的设置。例如,为了加快数据加载速度,我们可以增加工作线程的数量。默认数量为零,这意味着将使用主线程。如果我们将workers设置为2,将会生成两个线程同时加载数据。我们还应该将批量大小从默认值1增加到更合理的值,比如64(kBatchSize的值)。因此,让我们创建一个DataLoaderOptions对象并设置适当的属性:
auto data_loader = torch::data::make_data_loader(std::move(dataset),torch::data::DataLoaderOptions().batch_size(kBatchSize).workers(2));
现在我们可以编写一个循环来加载数据批次,目前我们只会将其打印到控制台:
for (torch::data::Example<>& batch : *data_loader) {std::cout << "Batch size: " << batch.data.size(0) << " | Labels: ";for (int64_t i = 0; i < batch.data.size(0); ++i) {std::cout << batch.target[i].item<int64_t>() << " ";}std::cout << std::endl;
}
在这种情况下,数据加载器返回的类型是torch::data::Example。这种类型是一个简单的结构体,有一个data字段用于数据,一个target字段用于标签。因为我们之前应用了Stack整理,数据加载器只返回一个这样的示例。如果我们没有应用整理,数据加载器将返回std::vector<torch::data::Example<>>,每个示例在批次中有一个元素。
如果您重新构建并运行此代码,您应该会看到类似以下的内容:
root@fa350df05ecf:/home/build# make
Scanning dependencies of target dcgan
[ 50%] Building CXX object CMakeFiles/dcgan.dir/dcgan.cpp.o
[100%] Linking CXX executable dcgan
[100%] Built target dcgan
root@fa350df05ecf:/home/build# make
[100%] Built target dcgan
root@fa350df05ecf:/home/build# ./dcgan
Batch size: 64 | Labels: 5 2 6 7 2 1 6 7 0 1 6 2 3 6 9 1 8 4 0 6 5 3 3 0 4 6 6 6 4 0 8 6 0 6 9 2 4 0 2 8 6 3 3 2 9 2 0 1 4 2 3 4 8 2 9 9 3 5 8 0 0 7 9 9
Batch size: 64 | Labels: 2 2 4 7 1 2 8 8 6 9 0 2 2 9 3 6 1 3 8 0 4 4 8 8 8 9 2 6 4 7 1 5 0 9 7 5 4 3 5 4 1 2 8 0 7 1 9 6 1 6 5 3 4 4 1 2 3 2 3 5 0 1 6 2
Batch size: 64 | Labels: 4 5 4 2 1 4 8 3 8 3 6 1 5 4 3 6 2 2 5 1 3 1 5 0 8 2 1 5 3 2 4 4 5 9 7 2 8 9 2 0 6 7 4 3 8 3 5 8 8 3 0 5 8 0 8 7 8 5 5 6 1 7 8 0
Batch size: 64 | Labels: 3 3 7 1 4 1 6 1 0 3 6 4 0 2 5 4 0 4 2 8 1 9 6 5 1 6 3 2 8 9 2 3 8 7 4 5 9 6 0 8 3 0 0 6 4 8 2 5 4 1 8 3 7 8 0 0 8 9 6 7 2 1 4 7
Batch size: 64 | Labels: 3 0 5 5 9 8 3 9 8 9 5 9 5 0 4 1 2 7 7 2 0 0 5 4 8 7 7 6 1 0 7 9 3 0 6 3 2 6 2 7 6 3 3 4 0 5 8 8 9 1 9 2 1 9 4 4 9 2 4 6 2 9 4 0
Batch size: 64 | Labels: 9 6 7 5 3 5 9 0 8 6 6 7 8 2 1 9 8 8 1 1 8 2 0 7 1 4 1 6 7 5 1 7 7 4 0 3 2 9 0 6 6 3 4 4 8 1 2 8 6 9 2 0 3 1 2 8 5 6 4 8 5 8 6 2
Batch size: 64 | Labels: 9 3 0 3 6 5 1 8 6 0 1 9 9 1 6 1 7 7 4 4 4 7 8 8 6 7 8 2 6 0 4 6 8 2 5 3 9 8 4 0 9 9 3 7 0 5 8 2 4 5 6 2 8 2 5 3 7 1 9 1 8 2 2 7
Batch size: 64 | Labels: 9 1 9 2 7 2 6 0 8 6 8 7 7 4 8 6 1 1 6 8 5 7 9 1 3 2 0 5 1 7 3 1 6 1 0 8 6 0 8 1 0 5 4 9 3 8 5 8 4 8 0 1 2 6 2 4 2 7 7 3 7 4 5 3
Batch size: 64 | Labels: 8 8 3 1 8 6 4 2 9 5 8 0 2 8 6 6 7 0 9 8 3 8 7 1 6 6 2 7 7 4 5 5 2 1 7 9 5 4 9 1 0 3 1 9 3 9 8 8 5 3 7 5 3 6 8 9 4 2 0 1 2 5 4 7
Batch size: 64 | Labels: 9 2 7 0 8 4 4 2 7 5 0 0 6 2 0 5 9 5 9 8 8 9 3 5 7 5 4 7 3 0 5 7 6 5 7 1 6 2 8 7 6 3 2 6 5 6 1 2 7 7 0 0 5 9 0 0 9 1 7 8 3 2 9 4
Batch size: 64 | Labels: 7 6 5 7 7 5 2 2 4 9 9 4 8 7 4 8 9 4 5 7 1 2 6 9 8 5 1 2 3 6 7 8 1 1 3 9 8 7 9 5 0 8 5 1 8 7 2 6 5 1 2 0 9 7 4 0 9 0 4 6 0 0 8 6
...
这意味着我们成功地能够从 MNIST 数据集中加载数据。
编写训练循环
现在让我们完成示例的算法部分,并实现生成器和鉴别器之间的微妙协作。首先,我们将创建两个优化器,一个用于生成器,一个用于鉴别器。我们使用的优化器实现了Adam算法:
torch::optim::Adam generator_optimizer(generator->parameters(), torch::optim::AdamOptions(2e-4).betas(std::make_tuple(0.5, 0.5)));
torch::optim::Adam discriminator_optimizer(discriminator->parameters(), torch::optim::AdamOptions(5e-4).betas(std::make_tuple(0.5, 0.5)));
注意
截至目前,C++前端提供了实现 Adagrad、Adam、LBFGS、RMSprop 和 SGD 的优化器。文档中有最新的列表。
接下来,我们需要更新我们的训练循环。我们将添加一个外部循环来在每个时期耗尽数据加载器,然后编写 GAN 训练代码:
for (int64_t epoch = 1; epoch <= kNumberOfEpochs; ++epoch) {int64_t batch_index = 0;for (torch::data::Example<>& batch : *data_loader) {// Train discriminator with real images.discriminator->zero_grad();torch::Tensor real_images = batch.data;torch::Tensor real_labels = torch::empty(batch.data.size(0)).uniform_(0.8, 1.0);torch::Tensor real_output = discriminator->forward(real_images);torch::Tensor d_loss_real = torch::binary_cross_entropy(real_output, real_labels);d_loss_real.backward();// Train discriminator with fake images.torch::Tensor noise = torch::randn({batch.data.size(0), kNoiseSize, 1, 1});torch::Tensor fake_images = generator->forward(noise);torch::Tensor fake_labels = torch::zeros(batch.data.size(0));torch::Tensor fake_output = discriminator->forward(fake_images.detach());torch::Tensor d_loss_fake = torch::binary_cross_entropy(fake_output, fake_labels);d_loss_fake.backward();torch::Tensor d_loss = d_loss_real + d_loss_fake;discriminator_optimizer.step();// Train generator.generator->zero_grad();fake_labels.fill_(1);fake_output = discriminator->forward(fake_images);torch::Tensor g_loss = torch::binary_cross_entropy(fake_output, fake_labels);g_loss.backward();generator_optimizer.step();std::printf("\r[%2ld/%2ld][%3ld/%3ld] D_loss: %.4f | G_loss: %.4f",epoch,kNumberOfEpochs,++batch_index,batches_per_epoch,d_loss.item<float>(),g_loss.item<float>());}
}
在上面的代码中,我们首先评估真实图像上的鉴别器,对于这些图像,它应该分配一个高概率。为此,我们使用torch::empty(batch.data.size(0)).uniform_(0.8, 1.0)作为目标概率。
注意
我们选择在 0.8 和 1.0 之间均匀分布的随机值,而不是在所有地方都是 1.0,以使鉴别器训练更加稳健。这个技巧被称为标签平滑。
在评估鉴别器之前,我们将其参数的梯度清零。计算损失后,我们通过调用d_loss.backward()来通过网络进行反向传播以计算新的梯度。我们对假图像重复这个过程。我们不使用数据集中的图像,而是让生成器通过提供一批随机噪声来创建这些假图像。然后我们将这些假图像传递给鉴别器。这一次,我们希望鉴别器发出低概率,理想情况下全为零。一旦我们计算了真实图像批次和假图像批次的鉴别器损失,我们就可以通过一步来推进鉴别器的优化器,以更新其参数。
为了训练生成器,我们再次首先将其梯度清零,然后重新评估鉴别器对假图像的情况。然而,这一次我们希望鉴别器分配非常接近于 1 的概率,这将表明生成器可以生成欺骗鉴别器认为它们实际上是真实的(来自数据集)的图像。为此,我们将fake_labels张量填充为全 1。最后,我们还要更新生成器的优化器以更新其参数。
我们现在应该准备在 CPU 上训练我们的模型。我们还没有任何代码来捕获状态或样本输出,但我们将在片刻之后添加这些内容。现在,让我们只观察我们的模型正在做某些事情 - 我们稍后将根据生成的图像验证这些事情是否有意义。重新构建和运行应该打印出类似以下的内容:
root@3c0711f20896:/home/build# make && ./dcgan
Scanning dependencies of target dcgan
[ 50%] Building CXX object CMakeFiles/dcgan.dir/dcgan.cpp.o
[100%] Linking CXX executable dcgan
[100%] Built target dcga
[ 1/10][100/938] D_loss: 0.6876 | G_loss: 4.1304
[ 1/10][200/938] D_loss: 0.3776 | G_loss: 4.3101
[ 1/10][300/938] D_loss: 0.3652 | G_loss: 4.6626
[ 1/10][400/938] D_loss: 0.8057 | G_loss: 2.2795
[ 1/10][500/938] D_loss: 0.3531 | G_loss: 4.4452
[ 1/10][600/938] D_loss: 0.3501 | G_loss: 5.0811
[ 1/10][700/938] D_loss: 0.3581 | G_loss: 4.5623
[ 1/10][800/938] D_loss: 0.6423 | G_loss: 1.7385
[ 1/10][900/938] D_loss: 0.3592 | G_loss: 4.7333
[ 2/10][100/938] D_loss: 0.4660 | G_loss: 2.5242
[ 2/10][200/938] D_loss: 0.6364 | G_loss: 2.0886
[ 2/10][300/938] D_loss: 0.3717 | G_loss: 3.8103
[ 2/10][400/938] D_loss: 1.0201 | G_loss: 1.3544
[ 2/10][500/938] D_loss: 0.4522 | G_loss: 2.6545
...
迁移到 GPU
虽然我们当前的脚本可以在 CPU 上正常运行,但我们都知道卷积在 GPU 上运行得更快。让我们快速讨论一下如何将训练迁移到 GPU 上。为此,我们需要做两件事:为我们分配的张量传递 GPU 设备规范,并通过to()方法将任何其他张量显式复制到 GPU 上,C++前端中的所有张量和模块都有这个方法。实现这两个目标的最简单方法是在我们的训练脚本的顶层创建一个torch::Device实例,然后将该设备传递给张量工厂函数,如torch::zeros以及to()方法。我们可以从 CPU 设备开始做这个:
// Place this somewhere at the top of your training script.
torch::Device device(torch::kCPU);
新的张量分配,如
torch::Tensor fake_labels = torch::zeros(batch.data.size(0));
应该更新为将device作为最后一个参数传递:
torch::Tensor fake_labels = torch::zeros(batch.data.size(0), device);
对于那些不在我们手中创建的张量,比如来自 MNIST 数据集的张量,我们必须插入显式的to()调用。这意味着
torch::Tensor real_images = batch.data;
变成
torch::Tensor real_images = batch.data.to(device);
还有我们的模型参数应该移动到正确的设备上:
generator->to(device);
discriminator->to(device);
注意
如果张量已经存在于传递给to()的设备上,调用将不起作用。不会进行额外的复制。
在这一点上,我们刚刚将之前的 CPU 代码更加明确。但是,现在也很容易将设备更改为 CUDA 设备:
torch::Device device(torch::kCUDA)
现在所有的张量都将存在于 GPU 上,调用快速的 CUDA 核心进行所有操作,而无需更改任何下游代码。如果我们想要指定特定的设备索引,可以将其作为第二个参数传递给Device构造函数。如果我们希望不同的张量存在于不同的设备上,我们可以传递单独的设备实例(例如一个在 CUDA 设备 0 上,另一个在 CUDA 设备 1 上)。我们甚至可以动态地进行这种配置,这通常对使我们的训练脚本更具可移植性很有用:
torch::Device device = torch::kCPU;
if (torch::cuda::is_available()) {std::cout << "CUDA is available! Training on GPU." << std::endl;device = torch::kCUDA;
}
甚至
torch::Device device(torch::cuda::is_available() ? torch::kCUDA : torch::kCPU);
检查点和恢复训练状态
我们应该对训练脚本进行的最后一个增强是定期保存模型参数的状态,优化器的状态以及一些生成的图像样本。如果我们的计算机在训练过程中崩溃,前两者将允许我们恢复训练状态。对于持续时间较长的训练会话,这是绝对必要的。幸运的是,C++前端提供了一个 API 来序列化和反序列化模型和优化器状态,以及单个张量。
这个核心 API 是torch::save(thing,filename)和torch::load(thing,filename),其中thing可以是torch::nn::Module子类或像我们在训练脚本中拥有的Adam对象这样的优化器实例。让我们更新我们的训练循环,以在一定间隔内检查点模型和优化器状态:
if (batch_index % kCheckpointEvery == 0) {// Checkpoint the model and optimizer state.torch::save(generator, "generator-checkpoint.pt");torch::save(generator_optimizer, "generator-optimizer-checkpoint.pt");torch::save(discriminator, "discriminator-checkpoint.pt");torch::save(discriminator_optimizer, "discriminator-optimizer-checkpoint.pt");// Sample the generator and save the images.torch::Tensor samples = generator->forward(torch::randn({8, kNoiseSize, 1, 1}, device));torch::save((samples + 1.0) / 2.0, torch::str("dcgan-sample-", checkpoint_counter, ".pt"));std::cout << "\n-> checkpoint " << ++checkpoint_counter << '\n';
}
其中kCheckpointEvery是一个整数,设置为类似100这样的值,以便每100批次进行检查点,并且checkpoint_counter是一个计数器,每次进行检查点时都会增加。
要恢复训练状态,您可以在创建所有模型和优化器之后,但在训练循环之前添加类似以下行:
torch::optim::Adam generator_optimizer(generator->parameters(), torch::optim::AdamOptions(2e-4).beta1(0.5));
torch::optim::Adam discriminator_optimizer(discriminator->parameters(), torch::optim::AdamOptions(2e-4).beta1(0.5));if (kRestoreFromCheckpoint) {torch::load(generator, "generator-checkpoint.pt");torch::load(generator_optimizer, "generator-optimizer-checkpoint.pt");torch::load(discriminator, "discriminator-checkpoint.pt");torch::load(discriminator_optimizer, "discriminator-optimizer-checkpoint.pt");
}int64_t checkpoint_counter = 0;
for (int64_t epoch = 1; epoch <= kNumberOfEpochs; ++epoch) {int64_t batch_index = 0;for (torch::data::Example<>& batch : *data_loader) {
检查生成的图像
我们的训练脚本现在已经完成。我们准备在 CPU 或 GPU 上训练我们的 GAN。要检查我们训练过程的中间输出,我们添加了代码以定期将图像样本保存到"dcgan-sample-xxx.pt"文件中,我们可以编写一个小的 Python 脚本来加载张量并使用 matplotlib 显示它们:
import argparseimport matplotlib.pyplot as plt
import torchparser = argparse.ArgumentParser()
parser.add_argument("-i", "--sample-file", required=True)
parser.add_argument("-o", "--out-file", default="out.png")
parser.add_argument("-d", "--dimension", type=int, default=3)
options = parser.parse_args()module = torch.jit.load(options.sample_file)
images = list(module.parameters())[0]for index in range(options.dimension * options.dimension):image = images[index].detach().cpu().reshape(28, 28).mul(255).to(torch.uint8)array = image.numpy()axis = plt.subplot(options.dimension, options.dimension, 1 + index)plt.imshow(array, cmap="gray")axis.get_xaxis().set_visible(False)axis.get_yaxis().set_visible(False)plt.savefig(options.out_file)
print("Saved ", options.out_file)
现在让我们训练我们的模型大约 30 个时期:
root@3c0711f20896:/home/build# make && ./dcgan 10:17:57
Scanning dependencies of target dcgan
[ 50%] Building CXX object CMakeFiles/dcgan.dir/dcgan.cpp.o
[100%] Linking CXX executable dcgan
[100%] Built target dcgan
CUDA is available! Training on GPU.
[ 1/30][200/938] D_loss: 0.4953 | G_loss: 4.0195
-> checkpoint 1
[ 1/30][400/938] D_loss: 0.3610 | G_loss: 4.8148
-> checkpoint 2
[ 1/30][600/938] D_loss: 0.4072 | G_loss: 4.36760
-> checkpoint 3
[ 1/30][800/938] D_loss: 0.4444 | G_loss: 4.0250
-> checkpoint 4
[ 2/30][200/938] D_loss: 0.3761 | G_loss: 3.8790
-> checkpoint 5
[ 2/30][400/938] D_loss: 0.3977 | G_loss: 3.3315
...
-> checkpoint 120
[30/30][938/938] D_loss: 0.3610 | G_loss: 3.8084
并在图中显示图像:
root@3c0711f20896:/home/build# python display.py -i dcgan-sample-100.pt
Saved out.png
应该看起来像这样:

数字!万岁!现在轮到你了:你能改进模型,使数字看起来更好吗?
结论
本教程希望为您提供了一个易于理解的 PyTorch C++前端摘要。像 PyTorch 这样的机器学习库必然具有非常广泛和广泛的 API。因此,有许多概念我们在这里没有时间或空间讨论。但是,我鼓励您尝试 API,并在遇到困难时参考我们的文档,特别是库 API部分。还要记住,每当可能时,您可以期望 C++前端遵循 Python 前端的设计和语义,因此您可以利用这一事实来提高学习速度。
提示
您可以在本教程中提供的完整源代码中找到此存储库。
如往常一样,如果遇到任何问题或有疑问,您可以使用我们的论坛或GitHub 问题与我们联系。
TorchScript 中的动态并行性
原文:
pytorch.org/tutorials/advanced/torch-script-parallelism.html译者:飞龙
协议:CC BY-NC-SA 4.0
在本教程中,我们介绍了在 TorchScript 中进行动态跨操作并行性的语法。这种并行性具有以下特性:
-
动态 - 并行任务的数量和它们的工作量可以取决于程序的控制流。
-
跨操作 - 并行性涉及并行运行 TorchScript 程序片段。这与内部操作并行性不同,内部操作并行性涉及将单个运算符拆分并并行运行运算符工作的子集。
基本语法
动态并行性的两个重要 API 是:
-
torch.jit.fork(fn: Callable[..., T], *args, **kwargs) -> torch.jit.Future[T] -
torch.jit.wait(fut: torch.jit.Future[T]) -> T
通过一个例子演示这些工作的好方法是:
import torchdef foo(x):return torch.neg(x)@torch.jit.script
def example(x):# Call `foo` using parallelism:# First, we "fork" off a task. This task will run `foo` with argument `x`future = torch.jit.fork(foo, x)# Call `foo` normallyx_normal = foo(x)# Second, we "wait" on the task. Since the task may be running in# parallel, we have to "wait" for its result to become available.# Notice that by having lines of code between the "fork()" and "wait()"# call for a given Future, we can overlap computations so that they# run in parallel.x_parallel = torch.jit.wait(future)return x_normal, x_parallelprint(example(torch.ones(1))) # (-1., -1.)
fork()接受可调用的fn以及该可调用的参数args和kwargs,并为fn的执行创建一个异步任务。fn可以是一个函数、方法或模块实例。fork()返回对此执行结果值的引用,称为Future。由于fork在创建异步任务后立即返回,所以在fork()调用后的代码行执行时,fn可能尚未被执行。因此,使用wait()来等待异步任务完成并返回值。
这些结构可以用来重叠函数内语句的执行(在示例部分中显示),或者与其他语言结构如循环组合:
import torch
from typing import Listdef foo(x):return torch.neg(x)@torch.jit.script
def example(x):futures : List[torch.jit.Future[torch.Tensor]] = []for _ in range(100):futures.append(torch.jit.fork(foo, x))results = []for future in futures:results.append(torch.jit.wait(future))return torch.sum(torch.stack(results))print(example(torch.ones([])))
注意
当我们初始化一个空的 Future 列表时,我们需要为futures添加显式类型注释。在 TorchScript 中,空容器默认假定它们包含 Tensor 值,因此我们将列表构造函数的注释标记为List[torch.jit.Future[torch.Tensor]]
这个例子使用fork()启动 100 个foo函数的实例,等待这 100 个任务完成,然后对结果求和,返回-100.0。
应用示例:双向 LSTM 集合
让我们尝试将并行性应用于一个更现实的例子,看看我们能从中获得什么样的性能。首先,让我们定义基线模型:双向 LSTM 层的集合。
import torch, time# In RNN parlance, the dimensions we care about are:
# # of time-steps (T)
# Batch size (B)
# Hidden size/number of "channels" (C)
T, B, C = 50, 50, 1024# A module that defines a single "bidirectional LSTM". This is simply two
# LSTMs applied to the same sequence, but one in reverse
class BidirectionalRecurrentLSTM(torch.nn.Module):def __init__(self):super().__init__()self.cell_f = torch.nn.LSTM(input_size=C, hidden_size=C)self.cell_b = torch.nn.LSTM(input_size=C, hidden_size=C)def forward(self, x : torch.Tensor) -> torch.Tensor:# Forward layeroutput_f, _ = self.cell_f(x)# Backward layer. Flip input in the time dimension (dim 0), apply the# layer, then flip the outputs in the time dimensionx_rev = torch.flip(x, dims=[0])output_b, _ = self.cell_b(torch.flip(x, dims=[0]))output_b_rev = torch.flip(output_b, dims=[0])return torch.cat((output_f, output_b_rev), dim=2)# An "ensemble" of `BidirectionalRecurrentLSTM` modules. The modules in the
# ensemble are run one-by-one on the same input then their results are
# stacked and summed together, returning the combined result.
class LSTMEnsemble(torch.nn.Module):def __init__(self, n_models):super().__init__()self.n_models = n_modelsself.models = torch.nn.ModuleList([BidirectionalRecurrentLSTM() for _ in range(self.n_models)])def forward(self, x : torch.Tensor) -> torch.Tensor:results = []for model in self.models:results.append(model(x))return torch.stack(results).sum(dim=0)# For a head-to-head comparison to what we're going to do with fork/wait, let's
# instantiate the model and compile it with TorchScript
ens = torch.jit.script(LSTMEnsemble(n_models=4))# Normally you would pull this input out of an embedding table, but for the
# purpose of this demo let's just use random data.
x = torch.rand(T, B, C)# Let's run the model once to warm up things like the memory allocator
ens(x)x = torch.rand(T, B, C)# Let's see how fast it runs!
s = time.time()
ens(x)
print('Inference took', time.time() - s, ' seconds')
在我的机器上,这个网络运行需要2.05秒。我们可以做得更好!
并行化前向和后向层
我们可以做的一个非常简单的事情是并行化BidirectionalRecurrentLSTM中的前向和后向层。对于这个结构的计算是静态的,所以我们实际上甚至不需要任何循环。让我们像这样重写BidirectionalRecurrentLSTM的forward方法:
def forward(self, x : torch.Tensor) -> torch.Tensor:# Forward layer - fork() so this can run in parallel to the backward# layerfuture_f = torch.jit.fork(self.cell_f, x)# Backward layer. Flip input in the time dimension (dim 0), apply the# layer, then flip the outputs in the time dimensionx_rev = torch.flip(x, dims=[0])output_b, _ = self.cell_b(torch.flip(x, dims=[0]))output_b_rev = torch.flip(output_b, dims=[0])# Retrieve the output from the forward layer. Note this needs to happen# *after* the stuff we want to parallelize withoutput_f, _ = torch.jit.wait(future_f)return torch.cat((output_f, output_b_rev), dim=2)
在这个例子中,forward()将cell_f的执行委托给另一个线程,同时继续执行cell_b。这导致两个单元的执行互相重叠。
使用这个简单修改再次运行脚本,运行时间为1.71秒,提高了17%!
附注:可视化并行性
我们还没有优化完我们的模型,但值得介绍一下我们用于可视化性能的工具。一个重要的工具是PyTorch 分析器。
让我们使用分析器以及 Chrome 跟踪导出功能来可视化我们并行化模型的性能:
with torch.autograd.profiler.profile() as prof:ens(x)
prof.export_chrome_trace('parallel.json')
这段代码将写出一个名为parallel.json的文件。如果你将 Google Chrome 导航到chrome://tracing,点击Load按钮,然后加载该 JSON 文件,你应该会看到如下时间线:
 )
)
时间线的水平轴表示时间,垂直轴表示执行线程。正如我们所看到的,我们同时运行两个lstm实例。这是我们并行化双向层的努力的结果!
在集成模型中并行化模型
您可能已经注意到我们的代码中还有进一步的并行化机会:我们也可以让包含在LSTMEnsemble中的模型相互并行运行。要做到这一点很简单,我们应该改变LSTMEnsemble的forward方法:
def forward(self, x : torch.Tensor) -> torch.Tensor:# Launch tasks for each modelfutures : List[torch.jit.Future[torch.Tensor]] = []for model in self.models:futures.append(torch.jit.fork(model, x))# Collect the results from the launched tasksresults : List[torch.Tensor] = []for future in futures:results.append(torch.jit.wait(future))return torch.stack(results).sum(dim=0)
或者,如果您更看重简洁性,我们可以使用列表推导:
def forward(self, x : torch.Tensor) -> torch.Tensor:futures = [torch.jit.fork(model, x) for model in self.models]results = [torch.jit.wait(fut) for fut in futures]return torch.stack(results).sum(dim=0)
就像在介绍中描述的那样,我们使用循环为集成模型中的每个模型启动任务。然后我们使用另一个循环等待所有任务完成。这提供了更多的计算重叠。
通过这个小更新,脚本运行时间缩短至1.4秒,总体加速达到32%!两行代码的效果相当不错。
我们还可以再次使用 Chrome 跟踪器来查看发生了什么:
 )
)
现在我们可以看到所有的LSTM实例都在完全并行运行。
结论
在本教程中,我们学习了fork()和wait(),这是 TorchScript 中进行动态、跨操作并行处理的基本 API。我们看到了一些使用这些函数来并行执行函数、方法或Modules的典型用法。最后,我们通过一个优化模型的示例来探讨了这种技术,并探索了 PyTorch 中可用的性能测量和可视化工具。
C++前端的 Autograd
原文:
pytorch.org/tutorials/advanced/cpp_autograd.html译者:飞龙
协议:CC BY-NC-SA 4.0
autograd包对于在 PyTorch 中构建高度灵活和动态的神经网络至关重要。PyTorch Python 前端中的大多数 autograd API 在 C++前端中也是可用的,允许将 autograd 代码从 Python 轻松翻译为 C++。
在本教程中,探索了在 PyTorch C++前端中进行 autograd 的几个示例。请注意,本教程假定您已经对 Python 前端中的 autograd 有基本的了解。如果不是这样,请先阅读Autograd:自动微分。
基本的 autograd 操作
(改编自此教程)
创建一个张量并设置torch::requires_grad()以跟踪计算
auto x = torch::ones({2, 2}, torch::requires_grad());
std::cout << x << std::endl;
输出:
1 1
1 1
[ CPUFloatType{2,2} ]
进行张量操作:
auto y = x + 2;
std::cout << y << std::endl;
输出:
3 33 3
[ CPUFloatType{2,2} ]
y是作为操作的结果创建的,因此它有一个grad_fn。
std::cout << y.grad_fn()->name() << std::endl;
输出:
AddBackward1
在y上执行更多操作
auto z = y * y * 3;
auto out = z.mean();std::cout << z << std::endl;
std::cout << z.grad_fn()->name() << std::endl;
std::cout << out << std::endl;
std::cout << out.grad_fn()->name() << std::endl;
输出:
27 2727 27
[ CPUFloatType{2,2} ]
MulBackward1
27
[ CPUFloatType{} ]
MeanBackward0
.requires_grad_( ... )会就地更改现有张量的requires_grad标志。
auto a = torch::randn({2, 2});
a = ((a * 3) / (a - 1));
std::cout << a.requires_grad() << std::endl;a.requires_grad_(true);
std::cout << a.requires_grad() << std::endl;auto b = (a * a).sum();
std::cout << b.grad_fn()->name() << std::endl;
输出:
false
true
SumBackward0
现在进行反向传播。因为out包含一个标量,out.backward()等同于out.backward(torch::tensor(1.))。
out.backward();
打印梯度 d(out)/dx
std::cout << x.grad() << std::endl;
输出:
4.5000 4.50004.5000 4.5000
[ CPUFloatType{2,2} ]
您应该得到一个4.5的矩阵。有关我们如何得到这个值的解释,请参阅此教程中的相应部分。
现在让我们看一个矢量-Jacobian 乘积的例子:
x = torch::randn(3, torch::requires_grad());y = x * 2;
while (y.norm().item<double>() < 1000) {y = y * 2;
}std::cout << y << std::endl;
std::cout << y.grad_fn()->name() << std::endl;
输出:
-1021.4020314.6695-613.4944
[ CPUFloatType{3} ]
MulBackward1
如果我们想要矢量-Jacobian 乘积,请将矢量作为参数传递给backward:
auto v = torch::tensor({0.1, 1.0, 0.0001}, torch::kFloat);
y.backward(v);std::cout << x.grad() << std::endl;
输出:
102.40001024.00000.1024
[ CPUFloatType{3} ]
您还可以通过在代码块中放置torch::NoGradGuard来停止自动梯度跟踪需要梯度的张量的历史记录
std::cout << x.requires_grad() << std::endl;
std::cout << x.pow(2).requires_grad() << std::endl;{torch::NoGradGuard no_grad;std::cout << x.pow(2).requires_grad() << std::endl;
}
输出:
true
true
false
或者通过使用.detach()来获得一个具有相同内容但不需要梯度的新张量:
std::cout << x.requires_grad() << std::endl;
y = x.detach();
std::cout << y.requires_grad() << std::endl;
std::cout << x.eq(y).all().item<bool>() << std::endl;
输出:
true
false
true
有关 C++张量 autograd API 的更多信息,如grad / requires_grad / is_leaf / backward / detach / detach_ / register_hook / retain_grad,请参阅相应的 C++ API 文档。
在 C++中计算高阶梯度
高阶梯度的一个应用是计算梯度惩罚。让我们看一个使用torch::autograd::grad的例子:
#include <torch/torch.h>auto model = torch::nn::Linear(4, 3);auto input = torch::randn({3, 4}).requires_grad_(true);
auto output = model(input);// Calculate loss
auto target = torch::randn({3, 3});
auto loss = torch::nn::MSELoss()(output, target);// Use norm of gradients as penalty
auto grad_output = torch::ones_like(output);
auto gradient = torch::autograd::grad({output}, {input}, /*grad_outputs=*/{grad_output}, /*create_graph=*/true)[0];
auto gradient_penalty = torch::pow((gradient.norm(2, /*dim=*/1) - 1), 2).mean();// Add gradient penalty to loss
auto combined_loss = loss + gradient_penalty;
combined_loss.backward();std::cout << input.grad() << std::endl;
输出:
-0.1042 -0.0638 0.0103 0.0723
-0.2543 -0.1222 0.0071 0.0814
-0.1683 -0.1052 0.0355 0.1024
[ CPUFloatType{3,4} ]
有关如何使用torch::autograd::backward(链接)和torch::autograd::grad(链接)的更多信息,请参阅文档。
在 C++中使用自定义 autograd 函数
(改编自此教程)
向torch::autograd添加一个新的基本操作需要为每个操作实现一个新的torch::autograd::Function子类。torch::autograd::Function是torch::autograd用于计算结果和梯度以及编码操作历史的内容。每个新函数都需要您实现 2 个方法:forward和backward,请参阅此链接以获取详细要求。
下面是来自torch::nn的Linear函数的代码:
#include <torch/torch.h>using namespace torch::autograd;// Inherit from Function
class LinearFunction : public Function<LinearFunction> {public:// Note that both forward and backward are static functions// bias is an optional argumentstatic torch::Tensor forward(AutogradContext *ctx, torch::Tensor input, torch::Tensor weight, torch::Tensor bias = torch::Tensor()) {ctx->save_for_backward({input, weight, bias});auto output = input.mm(weight.t());if (bias.defined()) {output += bias.unsqueeze(0).expand_as(output);}return output;}static tensor_list backward(AutogradContext *ctx, tensor_list grad_outputs) {auto saved = ctx->get_saved_variables();auto input = saved[0];auto weight = saved[1];auto bias = saved[2];auto grad_output = grad_outputs[0];auto grad_input = grad_output.mm(weight);auto grad_weight = grad_output.t().mm(input);auto grad_bias = torch::Tensor();if (bias.defined()) {grad_bias = grad_output.sum(0);}return {grad_input, grad_weight, grad_bias};}
};
然后,我们可以这样使用LinearFunction:
auto x = torch::randn({2, 3}).requires_grad_();
auto weight = torch::randn({4, 3}).requires_grad_();
auto y = LinearFunction::apply(x, weight);
y.sum().backward();std::cout << x.grad() << std::endl;
std::cout << weight.grad() << std::endl;
输出:
0.5314 1.2807 1.48640.5314 1.2807 1.4864
[ CPUFloatType{2,3} ]3.7608 0.9101 0.00733.7608 0.9101 0.00733.7608 0.9101 0.00733.7608 0.9101 0.0073
[ CPUFloatType{4,3} ]
这里,我们给出一个由非张量参数参数化的函数的额外示例:
#include <torch/torch.h>using namespace torch::autograd;class MulConstant : public Function<MulConstant> {public:static torch::Tensor forward(AutogradContext *ctx, torch::Tensor tensor, double constant) {// ctx is a context object that can be used to stash information// for backward computationctx->saved_data["constant"] = constant;return tensor * constant;}static tensor_list backward(AutogradContext *ctx, tensor_list grad_outputs) {// We return as many input gradients as there were arguments.// Gradients of non-tensor arguments to forward must be `torch::Tensor()`.return {grad_outputs[0] * ctx->saved_data["constant"].toDouble(), torch::Tensor()};}
};
然后,我们可以这样使用MulConstant:
auto x = torch::randn({2}).requires_grad_();
auto y = MulConstant::apply(x, 5.5);
y.sum().backward();std::cout << x.grad() << std::endl;
输出:
5.50005.5000
[ CPUFloatType{2} ]
有关torch::autograd::Function的更多信息,请参阅其文档。
从 Python 翻译 autograd 代码到 C++
从高层次来看,在 C++中使用 autograd 的最简单方法是首先在 Python 中编写工作的 autograd 代码,然后使用以下表格将您的 autograd 代码从 Python 翻译成 C++:
| Python | C++ |
|---|---|
torch.autograd.backward | torch::autograd::backward (link) |
torch.autograd.grad | torch::autograd::grad (link) |
torch.Tensor.detach | torch::Tensor::detach (link) |
torch.Tensor.detach_ | torch::Tensor::detach_ (link) |
torch.Tensor.backward | torch::Tensor::backward (link) |
torch.Tensor.register_hook | torch::Tensor::register_hook (link) |
torch.Tensor.requires_grad | torch::Tensor::requires_grad_ (link) |
torch.Tensor.retain_grad | torch::Tensor::retain_grad (link) |
torch.Tensor.grad | torch::Tensor::grad (link) |
torch.Tensor.grad_fn | torch::Tensor::grad_fn (link) |
torch.Tensor.set_data | torch::Tensor::set_data (link) |
torch.Tensor.data | torch::Tensor::data (link) |
torch.Tensor.output_nr | torch::Tensor::output_nr (link) |
torch.Tensor.is_leaf | torch::Tensor::is_leaf (link) |
翻译后,大部分的 Python 自动求导代码应该可以在 C++中正常工作。如果不是这种情况,请在GitHub issues上报告 bug,我们会尽快修复。
结论
现在,您应该对 PyTorch 的 C++自动求导 API 有一个很好的概述。您可以在这个笔记中找到显示的代码示例这里。如常,如果遇到任何问题或有疑问,您可以使用我们的论坛或GitHub issues与我们联系。
扩展 PyTorch
使用自定义函数进行双向传播
原文:
pytorch.org/tutorials/intermediate/custom_function_double_backward_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
有时候需要通过向后图两次运行反向传播,例如计算高阶梯度。然而,要支持双向传播需要对 autograd 有一定的理解和谨慎。支持单次向后传播的函数不一定能够支持双向传播。在本教程中,我们展示了如何编写支持双向传播的自定义 autograd 函数,并指出一些需要注意的事项。
当编写自定义 autograd 函数以进行两次向后传播时,重要的是要知道自定义函数中的操作何时被 autograd 记录,何时不被记录,以及最重要的是,save_for_backward 如何与所有这些操作一起使用。
自定义函数隐式影响梯度模式的两种方式:
-
在向前传播期间,autograd 不会记录任何在前向函数内执行的操作的图形。当前向完成时,自定义函数的向后函数将成为每个前向输出的 grad_fn
-
在向后传播期间,如果指定了 create_graph 参数,autograd 会记录用于计算向后传播的计算图
接下来,为了了解 save_for_backward 如何与上述交互,我们可以探索一些示例:
保存输入
考虑这个简单的平方函数。它保存一个输入张量以备向后传播使用。当 autograd 能够记录向后传播中的操作时,双向传播会自动工作,因此当我们保存一个输入以备向后传播时,通常不需要担心,因为如果输入是任何需要梯度的张量的函数,它应该有 grad_fn。这样可以正确传播梯度。
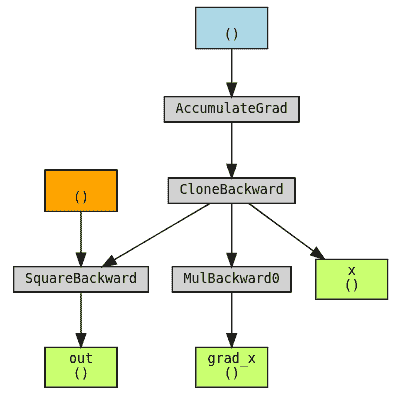
import torchclass Square(torch.autograd.Function):@staticmethoddef forward(ctx, x):# Because we are saving one of the inputs use `save_for_backward`# Save non-tensors and non-inputs/non-outputs directly on ctxctx.save_for_backward(x)return x**2@staticmethoddef backward(ctx, grad_out):# A function support double backward automatically if autograd# is able to record the computations performed in backwardx, = ctx.saved_tensorsreturn grad_out * 2 * x# Use double precision because finite differencing method magnifies errors
x = torch.rand(3, 3, requires_grad=True, dtype=torch.double)
torch.autograd.gradcheck(Square.apply, x)
# Use gradcheck to verify second-order derivatives
torch.autograd.gradgradcheck(Square.apply, x)
我们可以使用 torchviz 来可视化图形以查看为什么这样可以工作
import torchvizx = torch.tensor(1., requires_grad=True).clone()
out = Square.apply(x)
grad_x, = torch.autograd.grad(out, x, create_graph=True)
torchviz.make_dot((grad_x, x, out), {"grad_x": grad_x, "x": x, "out": out})
我们可以看到对于 x 的梯度本身是 x 的函数(dout/dx = 2x),并且这个函数的图形已经正确构建
保存输出
在前一个示例的轻微变化是保存输出而不是输入。机制类似,因为输出也与 grad_fn 相关联。
class Exp(torch.autograd.Function):# Simple case where everything goes well@staticmethoddef forward(ctx, x):# This time we save the outputresult = torch.exp(x)# Note that we should use `save_for_backward` here when# the tensor saved is an ouptut (or an input).ctx.save_for_backward(result)return result@staticmethoddef backward(ctx, grad_out):result, = ctx.saved_tensorsreturn result * grad_outx = torch.tensor(1., requires_grad=True, dtype=torch.double).clone()
# Validate our gradients using gradcheck
torch.autograd.gradcheck(Exp.apply, x)
torch.autograd.gradgradcheck(Exp.apply, x)
使用 torchviz 来可视化图形:
out = Exp.apply(x)
grad_x, = torch.autograd.grad(out, x, create_graph=True)
torchviz.make_dot((grad_x, x, out), {"grad_x": grad_x, "x": x, "out": out})
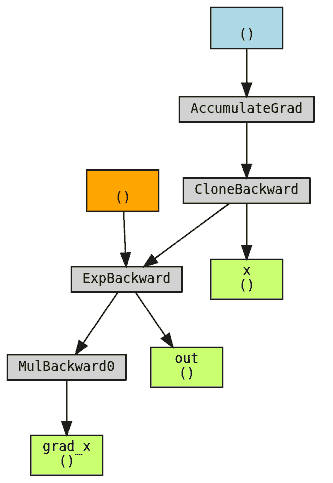
保存中间结果
更棘手的情况是当我们需要保存一个中间结果时。我们通过实现以下情况来演示这种情况:
s i n h ( x ) : = e x − e − x 2 sinh(x) := \frac{e^x - e^{-x}}{2} sinh(x):=2ex−e−x
由于 sinh 的导数是 cosh,因此在向后计算中重复使用 exp(x)和 exp(-x)这两个中间结果可能很有用。
尽管如此,中间结果不应直接保存并在向后传播中使用。因为前向是在无梯度模式下执行的,如果前向传递的中间结果用于计算向后传递中的梯度,则梯度的向后图将不包括计算中间结果的操作。这会导致梯度不正确。
class Sinh(torch.autograd.Function):@staticmethoddef forward(ctx, x):expx = torch.exp(x)expnegx = torch.exp(-x)ctx.save_for_backward(expx, expnegx)# In order to be able to save the intermediate results, a trick is to# include them as our outputs, so that the backward graph is constructedreturn (expx - expnegx) / 2, expx, expnegx@staticmethoddef backward(ctx, grad_out, _grad_out_exp, _grad_out_negexp):expx, expnegx = ctx.saved_tensorsgrad_input = grad_out * (expx + expnegx) / 2# We cannot skip accumulating these even though we won't use the outputs# directly. They will be used later in the second backward.grad_input += _grad_out_exp * expxgrad_input -= _grad_out_negexp * expnegxreturn grad_inputdef sinh(x):# Create a wrapper that only returns the first outputreturn Sinh.apply(x)[0]x = torch.rand(3, 3, requires_grad=True, dtype=torch.double)
torch.autograd.gradcheck(sinh, x)
torch.autograd.gradgradcheck(sinh, x)
使用 torchviz 来可视化图形:
out = sinh(x)
grad_x, = torch.autograd.grad(out.sum(), x, create_graph=True)
torchviz.make_dot((grad_x, x, out), params={"grad_x": grad_x, "x": x, "out": out})
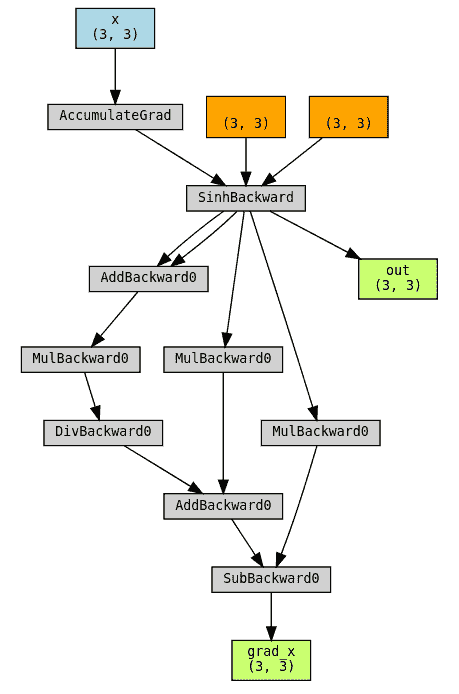
保存中间结果:不要这样做
现在我们展示当我们不返回中间结果作为输出时会发生什么:grad_x 甚至不会有一个反向图,因为它纯粹是一个函数 exp 和 expnegx,它们不需要 grad。
class SinhBad(torch.autograd.Function):# This is an example of what NOT to do!@staticmethoddef forward(ctx, x):expx = torch.exp(x)expnegx = torch.exp(-x)ctx.expx = expxctx.expnegx = expnegxreturn (expx - expnegx) / 2@staticmethoddef backward(ctx, grad_out):expx = ctx.expxexpnegx = ctx.expnegxgrad_input = grad_out * (expx + expnegx) / 2return grad_input
使用 torchviz 来可视化图形。请注意,grad_x 不是图形的一部分!
out = SinhBad.apply(x)
grad_x, = torch.autograd.grad(out.sum(), x, create_graph=True)
torchviz.make_dot((grad_x, x, out), params={"grad_x": grad_x, "x": x, "out": out})
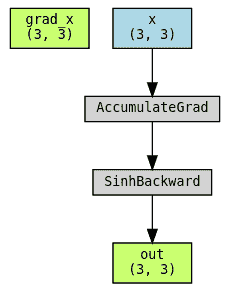
当不跟踪反向传播时
最后,让我们考虑一个例子,即 autograd 可能根本无法跟踪函数的反向梯度。我们可以想象 cube_backward 是一个可能需要非 PyTorch 库(如 SciPy 或 NumPy)或编写为 C++扩展的函数。这里演示的解决方法是创建另一个自定义函数 CubeBackward,在其中手动指定 cube_backward 的反向传播!
def cube_forward(x):return x**3def cube_backward(grad_out, x):return grad_out * 3 * x**2def cube_backward_backward(grad_out, sav_grad_out, x):return grad_out * sav_grad_out * 6 * xdef cube_backward_backward_grad_out(grad_out, x):return grad_out * 3 * x**2class Cube(torch.autograd.Function):@staticmethoddef forward(ctx, x):ctx.save_for_backward(x)return cube_forward(x)@staticmethoddef backward(ctx, grad_out):x, = ctx.saved_tensorsreturn CubeBackward.apply(grad_out, x)class CubeBackward(torch.autograd.Function):@staticmethoddef forward(ctx, grad_out, x):ctx.save_for_backward(x, grad_out)return cube_backward(grad_out, x)@staticmethoddef backward(ctx, grad_out):x, sav_grad_out = ctx.saved_tensorsdx = cube_backward_backward(grad_out, sav_grad_out, x)dgrad_out = cube_backward_backward_grad_out(grad_out, x)return dgrad_out, dxx = torch.tensor(2., requires_grad=True, dtype=torch.double)torch.autograd.gradcheck(Cube.apply, x)
torch.autograd.gradgradcheck(Cube.apply, x)
使用 torchviz 来可视化图形:
out = Cube.apply(x)
grad_x, = torch.autograd.grad(out, x, create_graph=True)
torchviz.make_dot((grad_x, x, out), params={"grad_x": grad_x, "x": x, "out": out})
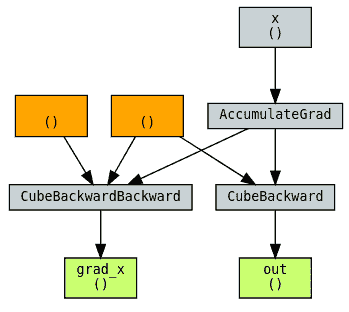
总之,双向传播是否适用于您的自定义函数取决于反向传播是否可以被 autograd 跟踪。通过前两个示例,我们展示了双向传播可以直接使用的情况。通过第三和第四个示例,我们展示了使反向函数可以被跟踪的技术,否则它们将无法被跟踪。
使用自定义函数融合卷积和批量归一化
原文:
pytorch.org/tutorials/intermediate/custom_function_conv_bn_tutorial.html译者:飞龙
协议:CC BY-NC-SA 4.0
注意
点击这里下载完整示例代码
将相邻的卷积和批量归一化层融合在一起通常是一种推理时间的优化,以提高运行时性能。通常通过完全消除批量归一化层并更新前面卷积的权重和偏置来实现[0]。然而,这种技术不适用于训练模型。
在本教程中,我们将展示一种不同的技术来融合这两个层,可以在训练期间应用。与改进运行时性能不同,这种优化的目标是减少内存使用。
这种优化的理念是看到卷积和批量归一化(以及许多其他操作)都需要在前向传播期间保存其输入的副本以供反向传播使用。对于大批量大小,这些保存的输入占用了大部分内存,因此能够避免为每个卷积批量归一化对分配另一个输入张量可以显著减少内存使用量。
在本教程中,我们通过将卷积和批量归一化合并为单个层(作为自定义函数)来避免这种额外的分配。在这个组合层的前向传播中,我们执行正常的卷积和批量归一化,唯一的区别是我们只保存卷积的输入。为了获得批量归一化的输入,这对于反向传播是必要的,我们在反向传播期间再次重新计算卷积的前向传播。
重要的是要注意,这种优化的使用是情境性的。虽然(通过避免保存一个缓冲区)我们总是在前向传播结束时减少分配的内存,但在某些情况下,峰值内存分配实际上可能并未减少。请查看最后一节以获取更多详细信息。
为简单起见,在本教程中,我们将 Conv2D 的 bias=False,stride=1,padding=0,dilation=1 和 groups=1 硬编码。对于 BatchNorm2D,我们将 eps=1e-3,momentum=0.1,affine=False 和 track_running_statistics=False 硬编码。另一个小的区别是在计算批量归一化时,在平方根的分母外部添加了 epsilon。
[0] nenadmarkus.com/p/fusing-batchnorm-and-conv/
卷积的反向传播公式实现
实现自定义函数需要我们自己实现反向传播。在这种情况下,我们需要为 Conv2D 和 BatchNorm2D 分别实现反向传播公式。最终,我们会将它们链接在一起形成统一的反向传播函数,但在下面,我们首先将它们实现为各自的自定义函数,以便验证它们的正确性
import torch
from torch.autograd.function import once_differentiable
import torch.nn.functional as Fdef convolution_backward(grad_out, X, weight):grad_input = F.conv2d(X.transpose(0, 1), grad_out.transpose(0, 1)).transpose(0, 1)grad_X = F.conv_transpose2d(grad_out, weight)return grad_X, grad_inputclass Conv2D(torch.autograd.Function):@staticmethoddef forward(ctx, X, weight):ctx.save_for_backward(X, weight)return F.conv2d(X, weight)# Use @once_differentiable by default unless we intend to double backward@staticmethod@once_differentiabledef backward(ctx, grad_out):X, weight = ctx.saved_tensorsreturn convolution_backward(grad_out, X, weight)
在使用gradcheck进行测试时,重要的是使用双精度
weight = torch.rand(5, 3, 3, 3, requires_grad=True, dtype=torch.double)
X = torch.rand(10, 3, 7, 7, requires_grad=True, dtype=torch.double)
torch.autograd.gradcheck(Conv2D.apply, (X, weight))
True
批量归一化的反向传播公式实现
Batch Norm 有两种模式:训练模式和eval模式。在训练模式下,样本统计量是输入的函数。在eval模式下,我们使用保存的运行统计量,这些统计量不是输入的函数。这使得非训练模式的反向传播显著简化。下面我们只实现和测试训练模式的情况。
def unsqueeze_all(t):# Helper function to ``unsqueeze`` all the dimensions that we reduce overreturn t[None, :, None, None]def batch_norm_backward(grad_out, X, sum, sqrt_var, N, eps):# We use the formula: ``out = (X - mean(X)) / (sqrt(var(X)) + eps)``# in batch norm 2D forward. To simplify our derivation, we follow the# chain rule and compute the gradients as follows before accumulating# them all into a final grad_input.# 1) ``grad of out wrt var(X)`` * ``grad of var(X) wrt X``# 2) ``grad of out wrt mean(X)`` * ``grad of mean(X) wrt X``# 3) ``grad of out wrt X in the numerator`` * ``grad of X wrt X``# We then rewrite the formulas to use as few extra buffers as possibletmp = ((X - unsqueeze_all(sum) / N) * grad_out).sum(dim=(0, 2, 3))tmp *= -1d_denom = tmp / (sqrt_var + eps)**2 # ``d_denom = -num / denom**2``# It is useful to delete tensors when you no longer need them with ``del``# For example, we could've done ``del tmp`` here because we won't use it later# In this case, it's not a big difference because ``tmp`` only has size of (C,)# The important thing is avoid allocating NCHW-sized tensors unnecessarilyd_var = d_denom / (2 * sqrt_var) # ``denom = torch.sqrt(var) + eps``# Compute ``d_mean_dx`` before allocating the final NCHW-sized grad_input bufferd_mean_dx = grad_out / unsqueeze_all(sqrt_var + eps)d_mean_dx = unsqueeze_all(-d_mean_dx.sum(dim=(0, 2, 3)) / N)# ``d_mean_dx`` has already been reassigned to a C-sized buffer so no need to worry# ``(1) unbiased_var(x) = ((X - unsqueeze_all(mean))**2).sum(dim=(0, 2, 3)) / (N - 1)``grad_input = X * unsqueeze_all(d_var * N)grad_input += unsqueeze_all(-d_var * sum)grad_input *= 2 / ((N - 1) * N)# (2) mean (see above)grad_input += d_mean_dx# (3) Add 'grad_out / <factor>' without allocating an extra buffergrad_input *= unsqueeze_all(sqrt_var + eps)grad_input += grad_outgrad_input /= unsqueeze_all(sqrt_var + eps) # ``sqrt_var + eps > 0!``return grad_inputclass BatchNorm(torch.autograd.Function):@staticmethoddef forward(ctx, X, eps=1e-3):# Don't save ``keepdim`` values for backwardsum = X.sum(dim=(0, 2, 3))var = X.var(unbiased=True, dim=(0, 2, 3))N = X.numel() / X.size(1)sqrt_var = torch.sqrt(var)ctx.save_for_backward(X)ctx.eps = epsctx.sum = sumctx.N = Nctx.sqrt_var = sqrt_varmean = sum / Ndenom = sqrt_var + epsout = X - unsqueeze_all(mean)out /= unsqueeze_all(denom)return out@staticmethod@once_differentiabledef backward(ctx, grad_out):X, = ctx.saved_tensorsreturn batch_norm_backward(grad_out, X, ctx.sum, ctx.sqrt_var, ctx.N, ctx.eps)
使用gradcheck进行测试
a = torch.rand(1, 2, 3, 4, requires_grad=True, dtype=torch.double)
torch.autograd.gradcheck(BatchNorm.apply, (a,), fast_mode=False)
True
融合卷积和批量归一化
现在大部分工作已经完成,我们可以将它们组合在一起。请注意,在(1)中我们只保存一个用于反向传播的缓冲区,但这也意味着我们在(5)中重新计算卷积的前向传播。还请注意,在(2)、(3)、(4)和(6)中,代码与上面的示例完全相同。
class FusedConvBN2DFunction(torch.autograd.Function):@staticmethoddef forward(ctx, X, conv_weight, eps=1e-3):assert X.ndim == 4 # N, C, H, W# (1) Only need to save this single buffer for backward!ctx.save_for_backward(X, conv_weight)# (2) Exact same Conv2D forward from example aboveX = F.conv2d(X, conv_weight)# (3) Exact same BatchNorm2D forward from example abovesum = X.sum(dim=(0, 2, 3))var = X.var(unbiased=True, dim=(0, 2, 3))N = X.numel() / X.size(1)sqrt_var = torch.sqrt(var)ctx.eps = epsctx.sum = sumctx.N = Nctx.sqrt_var = sqrt_varmean = sum / Ndenom = sqrt_var + eps# Try to do as many things in-place as possible# Instead of `out = (X - a) / b`, doing `out = X - a; out /= b`# avoids allocating one extra NCHW-sized buffer hereout = X - unsqueeze_all(mean)out /= unsqueeze_all(denom)return out@staticmethoddef backward(ctx, grad_out):X, conv_weight, = ctx.saved_tensors# (4) Batch norm backward# (5) We need to recompute convX_conv_out = F.conv2d(X, conv_weight)grad_out = batch_norm_backward(grad_out, X_conv_out, ctx.sum, ctx.sqrt_var,ctx.N, ctx.eps)# (6) Conv2d backwardgrad_X, grad_input = convolution_backward(grad_out, X, conv_weight)return grad_X, grad_input, None, None, None, None, None
下一步是将我们的功能变体包装在一个有状态的 nn.Module 中
import torch.nn as nn
import mathclass FusedConvBN(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, exp_avg_factor=0.1,eps=1e-3, device=None, dtype=None):super(FusedConvBN, self).__init__()factory_kwargs = {'device': device, 'dtype': dtype}# Conv parametersweight_shape = (out_channels, in_channels, kernel_size, kernel_size)self.conv_weight = nn.Parameter(torch.empty(*weight_shape, **factory_kwargs))# Batch norm parametersnum_features = out_channelsself.num_features = num_featuresself.eps = eps# Initializeself.reset_parameters()def forward(self, X):return FusedConvBN2DFunction.apply(X, self.conv_weight, self.eps)def reset_parameters(self) -> None:nn.init.kaiming_uniform_(self.conv_weight, a=math.sqrt(5))
使用gradcheck验证我们的反向传播公式的正确性
weight = torch.rand(5, 3, 3, 3, requires_grad=True, dtype=torch.double)
X = torch.rand(2, 3, 4, 4, requires_grad=True, dtype=torch.double)
torch.autograd.gradcheck(FusedConvBN2DFunction.apply, (X, weight))
True
测试我们的新层
使用FusedConvBN来训练一个基本网络。下面的代码经过了对这里示例的一些轻微修改:github.com/pytorch/examples/tree/master/mnist
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR# Record memory allocated at the end of the forward pass
memory_allocated = [[],[]]class Net(nn.Module):def __init__(self, fused=True):super(Net, self).__init__()self.fused = fusedif fused:self.convbn1 = FusedConvBN(1, 32, 3)self.convbn2 = FusedConvBN(32, 64, 3)else:self.conv1 = nn.Conv2d(1, 32, 3, 1, bias=False)self.bn1 = nn.BatchNorm2d(32, affine=False, track_running_stats=False)self.conv2 = nn.Conv2d(32, 64, 3, 1, bias=False)self.bn2 = nn.BatchNorm2d(64, affine=False, track_running_stats=False)self.fc1 = nn.Linear(9216, 128)self.dropout = nn.Dropout(0.5)self.fc2 = nn.Linear(128, 10)def forward(self, x):if self.fused:x = self.convbn1(x)else:x = self.conv1(x)x = self.bn1(x)F.relu_(x)if self.fused:x = self.convbn2(x)else:x = self.conv2(x)x = self.bn2(x)F.relu_(x)x = F.max_pool2d(x, 2)F.relu_(x)x = x.flatten(1)x = self.fc1(x)x = self.dropout(x)F.relu_(x)x = self.fc2(x)output = F.log_softmax(x, dim=1)if fused:memory_allocated[0].append(torch.cuda.memory_allocated())else:memory_allocated[1].append(torch.cuda.memory_allocated())return outputdef train(model, device, train_loader, optimizer, epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % 2 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))def test(model, device, test_loader):model.eval()test_loss = 0correct = 0# Use inference mode instead of no_grad, for free improved test-time performancewith torch.inference_mode():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)# sum up batch losstest_loss += F.nll_loss(output, target, reduction='sum').item()# get the index of the max log-probabilitypred = output.argmax(dim=1, keepdim=True)correct += pred.eq(target.view_as(pred)).sum().item()test_loss /= len(test_loader.dataset)print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))use_cuda = torch.cuda.is_available()
device = torch.device("cuda" if use_cuda else "cpu")
train_kwargs = {'batch_size': 2048}
test_kwargs = {'batch_size': 2048}if use_cuda:cuda_kwargs = {'num_workers': 1,'pin_memory': True,'shuffle': True}train_kwargs.update(cuda_kwargs)test_kwargs.update(cuda_kwargs)transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('../data', train=True, download=True,transform=transform)
dataset2 = datasets.MNIST('../data', train=False,transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1, **train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ../data/MNIST/raw/train-images-idx3-ubyte.gz0%| | 0/9912422 [00:00<?, ?it/s]
100%|##########| 9912422/9912422 [00:00<00:00, 503661080.89it/s]
Extracting ../data/MNIST/raw/train-images-idx3-ubyte.gz to ../data/MNIST/rawDownloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ../data/MNIST/raw/train-labels-idx1-ubyte.gz0%| | 0/28881 [00:00<?, ?it/s]
100%|##########| 28881/28881 [00:00<00:00, 115697892.86it/s]
Extracting ../data/MNIST/raw/train-labels-idx1-ubyte.gz to ../data/MNIST/rawDownloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ../data/MNIST/raw/t10k-images-idx3-ubyte.gz0%| | 0/1648877 [00:00<?, ?it/s]
100%|##########| 1648877/1648877 [00:00<00:00, 346140710.54it/s]
Extracting ../data/MNIST/raw/t10k-images-idx3-ubyte.gz to ../data/MNIST/rawDownloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ../data/MNIST/raw/t10k-labels-idx1-ubyte.gz0%| | 0/4542 [00:00<?, ?it/s]
100%|##########| 4542/4542 [00:00<00:00, 33421980.29it/s]
Extracting ../data/MNIST/raw/t10k-labels-idx1-ubyte.gz to ../data/MNIST/raw
内存使用比较
如果启用了 CUDA,则打印出融合为 True 和融合为 False 的内存使用情况。例如,在 NVIDIA GeForce RTX 3070 上运行,NVIDIA CUDA®深度神经网络库(cuDNN)8.0.5:融合峰值内存:1.56GB,未融合峰值内存:2.68GB
重要的是要注意,对于这个模型,峰值内存使用量可能会因使用的特定 cuDNN 卷积算法而异。对于较浅的模型,融合模型的峰值内存分配可能会超过未融合模型!这是因为为计算某些 cuDNN 卷积算法分配的内存可能足够高,以至于“隐藏”您期望在反向传递开始附近的典型峰值。
因此,我们还记录并显示在前向传递结束时分配的内存,以便近似,并展示我们确实为每个融合的conv-bn对分配了一个更少的缓冲区。
from statistics import meantorch.backends.cudnn.enabled = Trueif use_cuda:peak_memory_allocated = []for fused in (True, False):torch.manual_seed(123456)model = Net(fused=fused).to(device)optimizer = optim.Adadelta(model.parameters(), lr=1.0)scheduler = StepLR(optimizer, step_size=1, gamma=0.7)for epoch in range(1):train(model, device, train_loader, optimizer, epoch)test(model, device, test_loader)scheduler.step()peak_memory_allocated.append(torch.cuda.max_memory_allocated())torch.cuda.reset_peak_memory_stats()print("cuDNN version:", torch.backends.cudnn.version())print()print("Peak memory allocated:")print(f"fused: {peak_memory_allocated[0]/1024**3:.2f}GB, unfused: {peak_memory_allocated[1]/1024**3:.2f}GB")print("Memory allocated at end of forward pass:")print(f"fused: {mean(memory_allocated[0])/1024**3:.2f}GB, unfused: {mean(memory_allocated[1])/1024**3:.2f}GB")
Train Epoch: 0 [0/60000 (0%)] Loss: 2.348735
Train Epoch: 0 [4096/60000 (7%)] Loss: 7.435781
Train Epoch: 0 [8192/60000 (13%)] Loss: 5.540894
Train Epoch: 0 [12288/60000 (20%)] Loss: 2.274223
Train Epoch: 0 [16384/60000 (27%)] Loss: 1.618885
Train Epoch: 0 [20480/60000 (33%)] Loss: 1.515203
Train Epoch: 0 [24576/60000 (40%)] Loss: 1.329276
Train Epoch: 0 [28672/60000 (47%)] Loss: 1.184942
Train Epoch: 0 [32768/60000 (53%)] Loss: 1.140154
Train Epoch: 0 [36864/60000 (60%)] Loss: 1.174118
Train Epoch: 0 [40960/60000 (67%)] Loss: 1.057965
Train Epoch: 0 [45056/60000 (73%)] Loss: 0.976334
Train Epoch: 0 [49152/60000 (80%)] Loss: 0.842555
Train Epoch: 0 [53248/60000 (87%)] Loss: 0.690169
Train Epoch: 0 [57344/60000 (93%)] Loss: 0.656998Test set: Average loss: 0.4197, Accuracy: 8681/10000 (87%)Train Epoch: 0 [0/60000 (0%)] Loss: 2.349030
Train Epoch: 0 [4096/60000 (7%)] Loss: 7.435157
Train Epoch: 0 [8192/60000 (13%)] Loss: 5.443537
Train Epoch: 0 [12288/60000 (20%)] Loss: 2.457860
Train Epoch: 0 [16384/60000 (27%)] Loss: 1.739216
Train Epoch: 0 [20480/60000 (33%)] Loss: 1.448296
Train Epoch: 0 [24576/60000 (40%)] Loss: 1.312144
Train Epoch: 0 [28672/60000 (47%)] Loss: 1.145347
Train Epoch: 0 [32768/60000 (53%)] Loss: 1.495082
Train Epoch: 0 [36864/60000 (60%)] Loss: 1.251163
Train Epoch: 0 [40960/60000 (67%)] Loss: 1.066768
Train Epoch: 0 [45056/60000 (73%)] Loss: 0.883593
Train Epoch: 0 [49152/60000 (80%)] Loss: 0.830817
Train Epoch: 0 [53248/60000 (87%)] Loss: 0.727264
Train Epoch: 0 [57344/60000 (93%)] Loss: 0.774158Test set: Average loss: 0.4437, Accuracy: 8710/10000 (87%)cuDNN version: 8902Peak memory allocated:
fused: 3.08GB, unfused: 1.77GB
Memory allocated at end of forward pass:
fused: 0.59GB, unfused: 0.96GB
脚本的总运行时间:(0 分钟 37.014 秒)
下载 Python 源代码:custom_function_conv_bn_tutorial.py
下载 Jupyter 笔记本:custom_function_conv_bn_tutorial.ipynb
Sphinx-Gallery 生成的图库