Kafka系列
- 发送消息到 Kafka 主题
- 了解异步模式
- 了解同步模式
- 线程发送消息的步骤
- 生产者用单线程发送消息
- 生产者用多线程发送消息
- 配置生产者属性
- 保存对象的各个属性一序列化
- 序列化一个对象
- 序列化对象的存储格式
- 自己实现 序列化的步骤
- 1. 创建序列化对象
- 2. 编写序列化工具类
- 3. 编写自定义序列化逻辑代码
- 4. 编写生产者应用程序
- 自定义主题分区
- 编写自定义主题分区算法
- 演示自定义分区的作用
转自 《Kafka并不难学!入门、进阶、商业实战》
发送消息到 Kafka 主题
Kafka 0.10.0.0 及以后的版本,对生产者代码的底层实现进行了重构。kafka.producer.Producer类被 org.apache.kafka.clients.producer.KafkaProducer 类替换
Kafka 系统支持两种不同的发送方式–同步模式(Sync)和异步模式(ASync)。
了解异步模式
在 Kafka 0.10.0.0 及以后的版本中,客户端应用程序调用生产者应用接口,默认使用异步的方式发送消息。
生产者客户端在通过异步模式发送消息时,通常会调用回调函数的 send()方法发送消息。生产者端收到 Kafka 代理节点的响应后会触发回调函数。
- 什么场景下需要使用异步模式
假如生产者客户端与 Kafka 集群节点间存在网络延时(100ms),此时发送 10 条消息记录,则延时将达到 1s。而大数据场景下有着海量的消息记录,发送的消息记录是远不止 10条,延时将非常严重。
大数据场景下,如果采用异步模式发送消息记录,几乎没有任何耗时,通过回调函数可以知道消息发送的结果。 - 异步模式数据写入流程
例如,一个业务主题(ip login)有6个分区。生产者客户端写入一条消息记录时,消息记录会先写入某个缓冲区,生产者客户端直接得到结果(这时,缓冲区里的数据并没有写到 Kafka代理节点中主题的某个分区)。之后,缓冲区中的数据会通过异步模式发送到 Kafka 代理节点中主题的某个分区中。
//实例化一个消息记录对象,用来保存主题名、分区索引、键、值和时间戳ProducerRecord<byte[],byte[]> record =new ProducerRecord<byte[],byte[]>("ip login", key, value);//调用 send()方法和回调函数producer.send(myRecord,new Callback() {public void onCompletion (RecordMetadata metadata, Exception e){if (e != null) {e.printStackTrace();} else {System.out.println("The offset of the record we just sent is:" + metadata.offset());}}};
消息记录提交给 send()方法后,实际上该消息记录被放入一个缓冲区的发送队列,然后通过后台线程将其从缓冲区队列中取出并进行发送;发送成功后会触发send方法的回调函数-Callback.
了解同步模式
生产者客户端通过 send()方法实现同步模式发送消息,并返回一个 Future 对象,同时调用get()方法等待 Future 对象,看 send()方法是否发送成功。
- 什么场景下使用同步模式
如果要收集用户访问网页的数据,在写数据到 Kafka 集群代理节点时需要立即知道消息是否写入成功,此时应使用同步模式。
// 将字符串转换成字节数组
byte[] key = "key".getBytes();
byte[] value ="value".getBytes();
// 实例化一个消息记录对象,用来保存主题名、分区索引、键、值和时间戳
ProducerRecord<byte[],byte[]> record = new ProducerRecord<byte[],byte[]>("ip_login",key, value);
//调用 send()函数后,再通过 get()方法等待返回结果
producer.send(record).get();
这里通过调用 Future 接口中的 get()方法等待 Kafka 集群代理节点(Broker)的状态返回如果 Producer 发送消息记录成功了,则返回 RecordMetadata 对象,该对象可用来查看消息记录的偏移量(Offset)。
线程发送消息的步骤
在 Kafka 系统中,为了保证生产者客户端应用程序的独立运行,通常使用线程的方式发送消息。
创建一个简单的生产者应用程序的步骤如下。
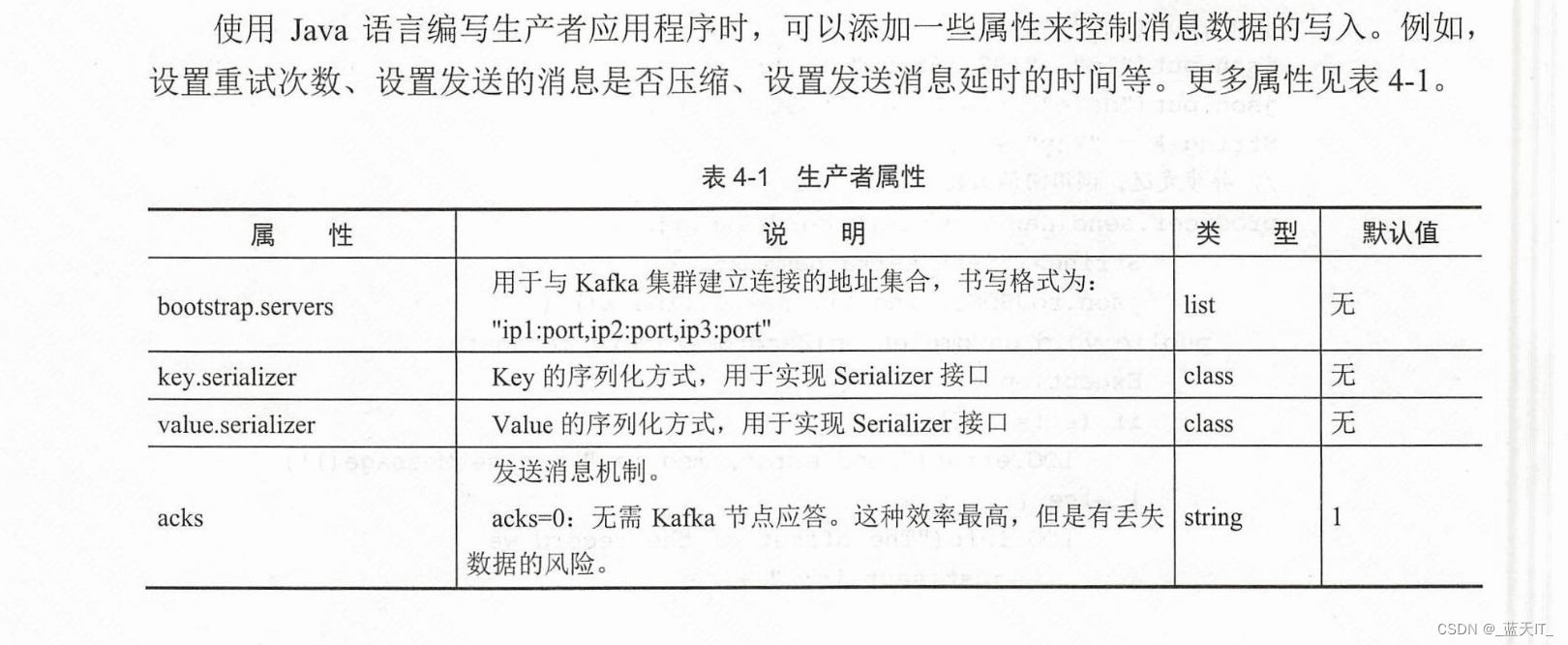
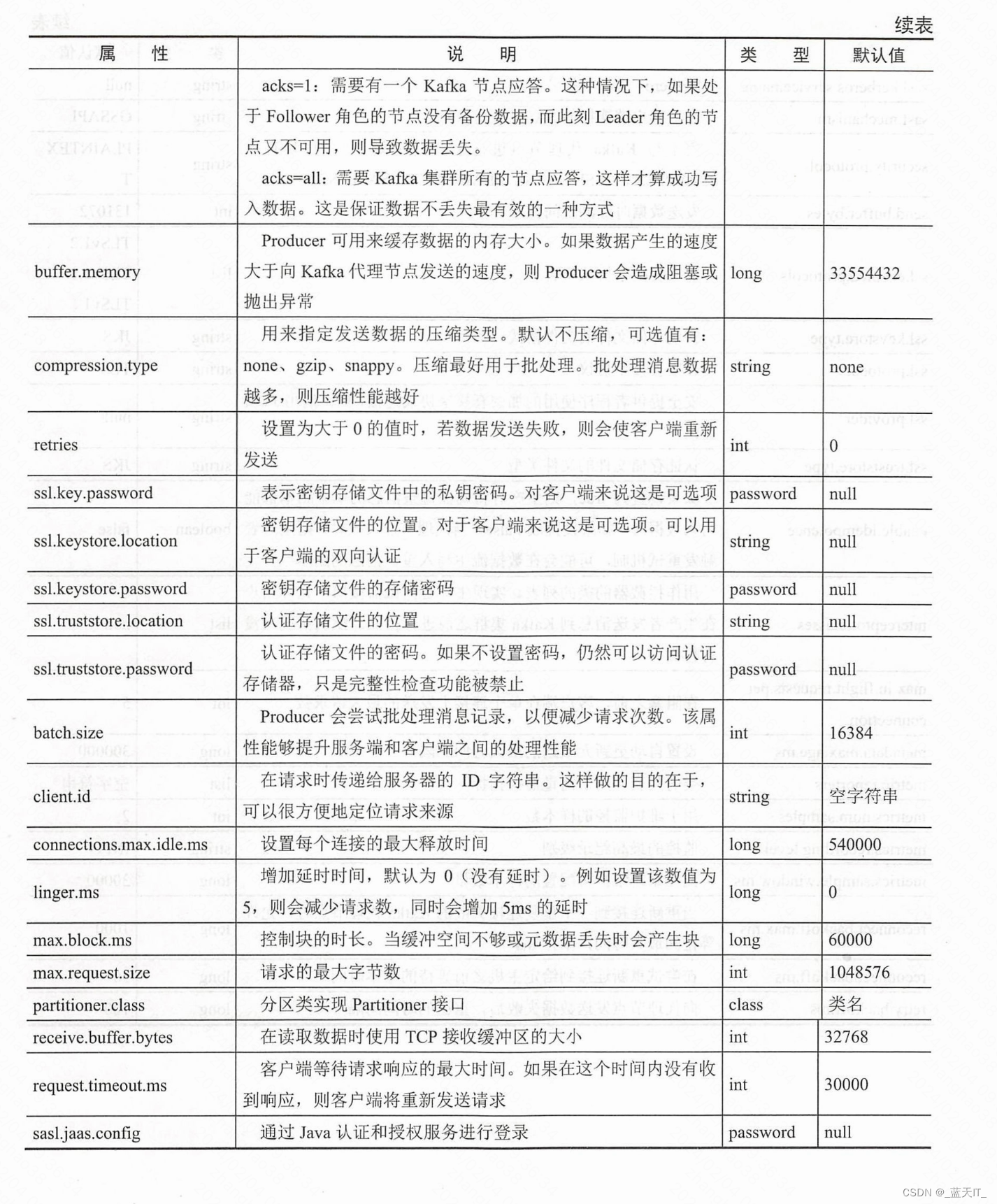
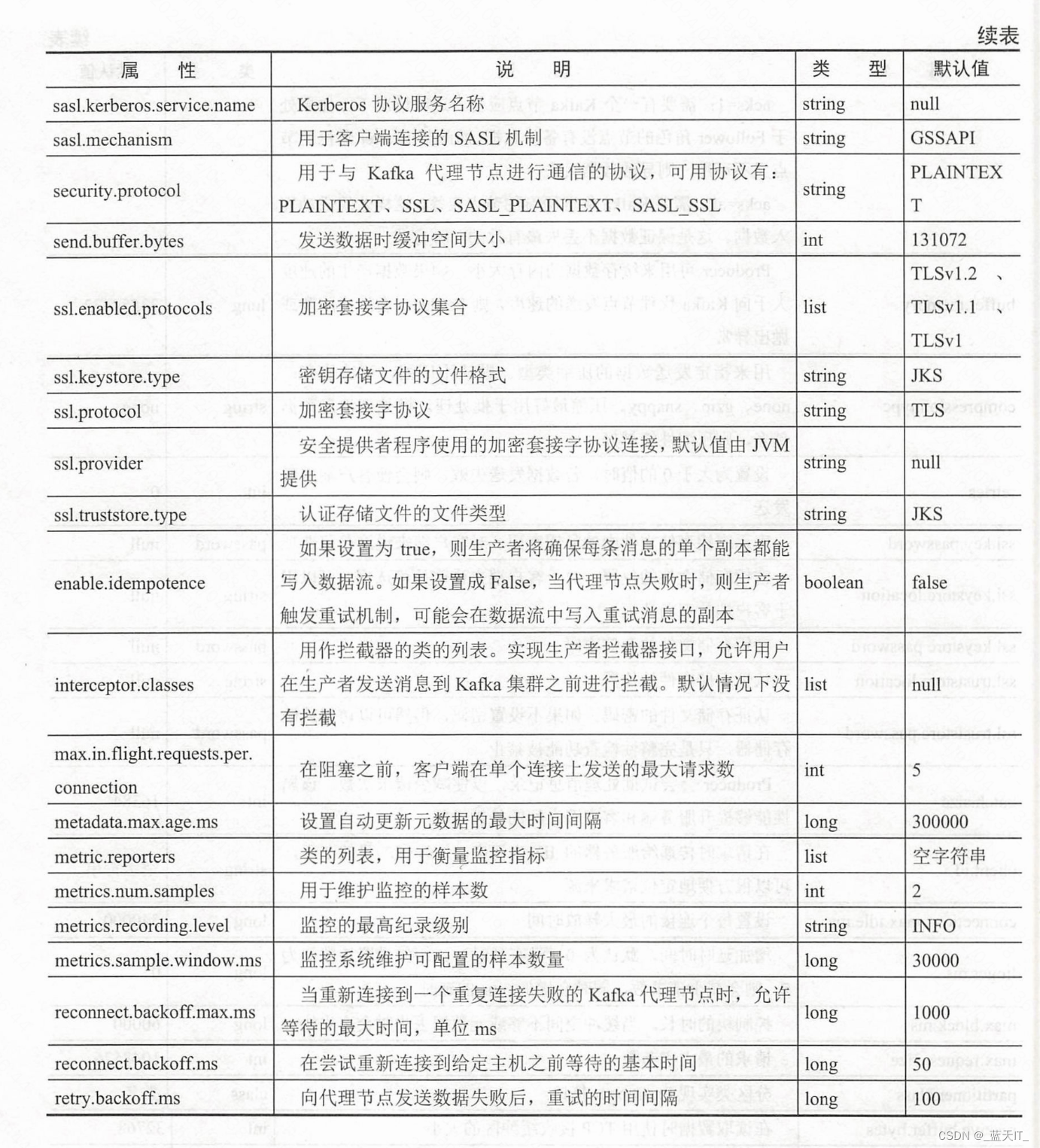
(1)实例化 Properties 类对象,配置生产者应答机制。有以下三个属性是必须设置的。其他属性一般都会有默认值,可以按需添加设置。
- bootstrap.servers:配置Kafka集群代理节点地址;
- key.serializer:序列化消息主键;
- value.serializer:序列化消息数据内容,
(2)根据属性对象实例化一个 KafkaProducer.
(3)通过实例化一个ProducerRecord 对象,将消息记录以“键-值”对的形式进行封装。
(4)通过调用 KafkaProducer 对象中带有回调函数的 send方法发送消息给 Kafka 集群。
(5)关闭KafkaProducer 对象,释放连接资源,
生产者用单线程发送消息
/*** 实现一个生产者客户端应用程序.*/
public class JProducer extends Thread {private final Logger LOG = LoggerFactory.getLogger(JProducer.class);/** 配置Kafka连接信息. */public Properties configure() {Properties props = new Properties();props.put("bootstrap.servers", "dn1:9092,dn2:9092,dn3:9092");// 指定Kafka集群地址props.put("acks", "1"); // 设置应答模式, 1表示有一个Kafka代理节点返回结果props.put("retries", 0); // 重试次数props.put("batch.size", 16384); // 批量提交大小props.put("linger.ms", 1); // 延时提交props.put("buffer.memory", 33554432); // 缓冲大小props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 序列化主键props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 序列化值return props;}public static void main(String[] args) {JProducer producer = new JProducer();producer.start();}/** 实现一个单线程生产者客户端. */public void run() {Producer<String, String> producer = new KafkaProducer<>(configure());// 发送100条JSON格式的数据for (int i = 0; i < 100; i++) {// 封装JSON格式JSONObject json = new JSONObject();json.put("id", i);json.put("ip", "192.168.0." + i);json.put("date", new Date().toString());String k = "key" + i;// 异步发送producer.send(new ProducerRecord<String, String>("test_kafka_game_x", k, json.toJSONString()), new Callback() {public void onCompletion(RecordMetadata metadata, Exception e) {if (e != null) {LOG.error("Send error, msg is " + e.getMessage());} else {LOG.info("The offset of the record we just sent is: " + metadata.offset());}}});}try {sleep(3000);// 间隔3秒} catch (InterruptedException e) {LOG.error("Interrupted thread error, msg is " + e.getMessage());}producer.close();// 关闭生产者对象}
}
这里的主题只有一个分区和一个副本,所以,发送的所有消息会写入同一个分区中
如果希望发送完消息后获取一些返回信息(比如获取消息的偏移量、分区索引值、提交的时间戳等),则可以通过回调函数 CallBack 返回的 RecordMetadata 对象来实现。
由于 Kafka 系统的生产者对象是线程安全的,所以,可通过增加生产者对象的线程数来提高 Kafka 系统的吞吐量。
生产者用多线程发送消息
public class JProducerThread extends Thread {// 创建一个日志对象private final Logger LOG = LoggerFactory.getLogger(JProducerThread.class);// 声明最大线程数private final static int MAX_THREAD_SIZE = 6;/** 配置Kafka连接信息. */public Properties configure() {Properties props = new Properties();props.put("bootstrap.servers", "dn1:9092,dn2:9092,dn3:9092");// 指定Kafka集群地址props.put("acks", "1"); // 设置应答模式, 1表示有一个Kafka代理节点返回结果props.put("retries", 0); // 重试次数props.put("batch.size", 16384); // 批量提交大小props.put("linger.ms", 1); // 延时提交props.put("buffer.memory", 33554432); // 缓冲大小props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 序列化主键props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 序列化值props.put("partitioner.class", "org.smartloli.kafka.game.x.book_4.JPartitioner");// 指定自定义分区类return props;}public static void main(String[] args) {// 创建一个固定线程数量的线程池ExecutorService executorService = Executors.newFixedThreadPool(MAX_THREAD_SIZE);// 提交任务executorService.submit(new JProducerThread());// 关闭线程池executorService.shutdown();}/** 实现一个单线程生产者客户端. */public void run() {Producer<String, String> producer = new KafkaProducer<>(configure());// 发送100条JSON格式的数据for (int i = 0; i < 10; i++) {// 封装JSON格式JSONObject json = new JSONObject();json.put("id", i);json.put("ip", "192.168.0." + i);json.put("date", new Date().toString());String k = "key" + i;// 异步发送producer.send(new ProducerRecord<String, String>("ip_login_rt", k, json.toJSONString()), new Callback() {public void onCompletion(RecordMetadata metadata, Exception e) {if (e != null) {LOG.error("Send error, msg is " + e.getMessage());} else {LOG.info("The offset of the record we just sent is: " + metadata.offset());}}});}try {sleep(3000);// 间隔3秒} catch (InterruptedException e) {LOG.error("Interrupted thread error, msg is " + e.getMessage());}producer.close();// 关闭生产者对象}}配置生产者属性
保存对象的各个属性一序列化
序列化一个对象
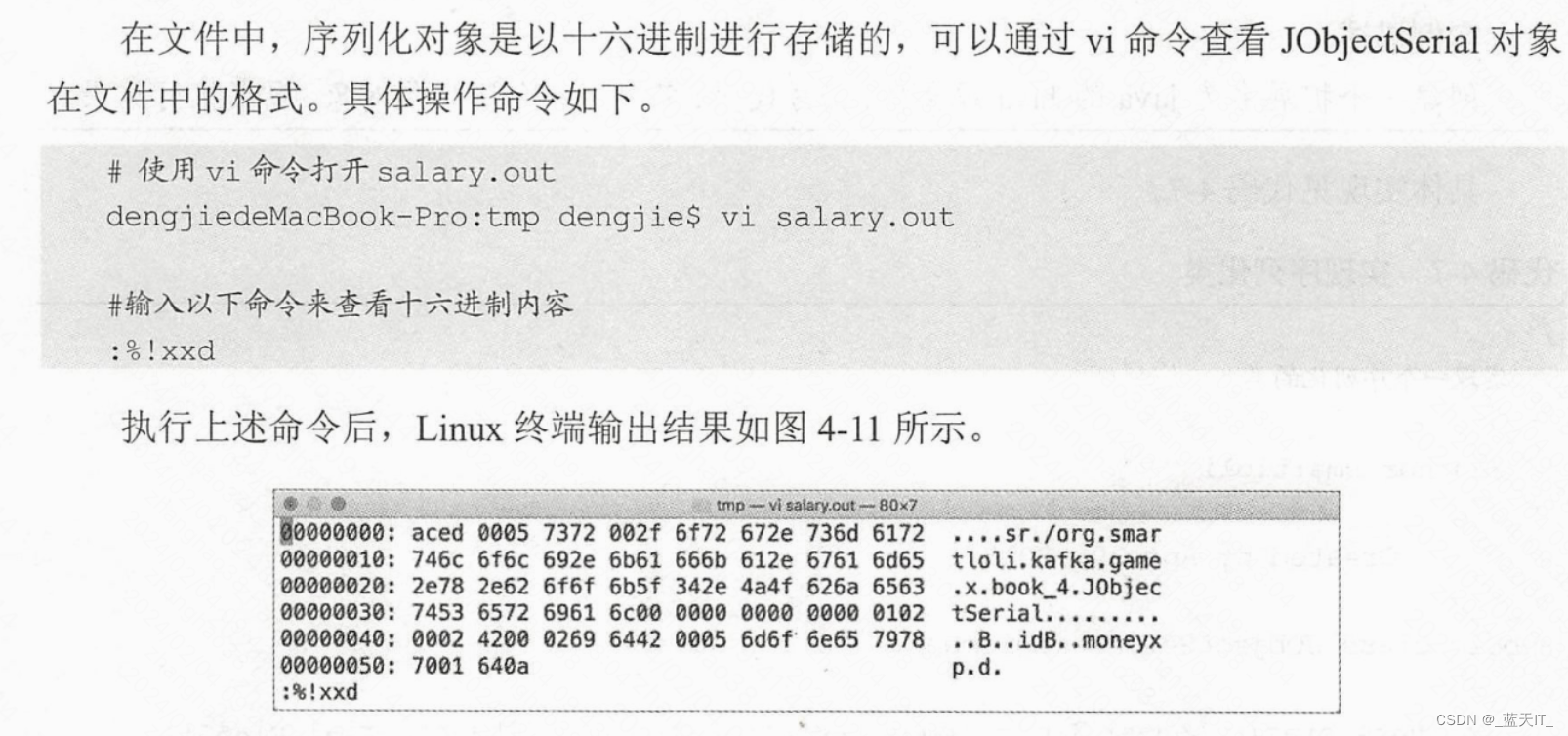
在分布式环境下,无论哪种格式的数据都会被分解成二进制,以便存储在文件中或者在网络上传输。
序列化就是,将对象以一连串的字节进行描述,用来解决对象在进行读写操作时所引发的问题。
序列化可以将对象的状态写成数据流,并进行网络传输或者保存在文件或数据库中,在需要时再把该数据流读取出来,重新构造一个相同的对象。
- 为什么需要序列化
在传统的企业应用中,不同的组件分布在不同的系统和网络中。如果两个组件之间想要进行通信,那么它们之间必须有数据转换机制。实现这个过程需要遵照一个协议来传输对象,这意味着,接收端需要知道发送端所使用的协议才能重新构建对象,以此来保证两个组件之间的通信是安全的。
public class JObjectSerial implements Serializable {private static Logger LOG = LoggerFactory.getLogger(JObjectSerial.class);/*** 序列化版本ID.*/private static final long serialVersionUID = 1L;public byte id = 1; // 用户IDpublic byte money = 100; // 充值金额/** 实例化入口函数. */public static void main(String[] args) {try {FileOutputStream fos = new FileOutputStream("/tmp/salary.out"); // 实例化一个输出流对象ObjectOutputStream oos = new ObjectOutputStream(fos);// 实例化一个对象输出流JObjectSerial jos = new JObjectSerial(); // 实例化序列化类oos.writeObject(jos); // 写入对象oos.flush(); // 刷新数据流oos.close();// 关闭连接} catch (Exception e) {LOG.error("Serial has error, msg is " + e.getMessage());// 打印异常信息}}
}
序列化对象的存储格式
自己实现 序列化的步骤

如果使用原生的序列化方式,则需要将传输的内容拼接成字符串或转成字符数组,抑或是其他类型,这样在实现代码时就会比较麻烦。而 Kafka 为了解决这种问题,提供了序列化的接口,让用户可以自定义对象的序列化方式,来完成对象的传输。
以下实例将演示生产者客户端应用程序中序列化的用法,利用 Serializable 接口来序列化对象。
1. 创建序列化对象
/*** 声明一个序列化类.* * @author smartloli.** Created by Apr 30, 2018*/
public class JSalarySerial implements Serializable {/*** 序列化版本ID.*/private static final long serialVersionUID = 1L;private String id;// 用户IDprivate String salary;// 金额public String getId() {return id;}public void setId(String id) {this.id = id;}public String getSalary() {return salary;}public void setSalary(String salary) {this.salary = salary;}// 打印对象属性值@Overridepublic String toString() {return "JSalarySerial [id=" + id + ", salary=" + salary + "]";}}2. 编写序列化工具类
/*** 封装一个序列化的工具类.* * @author smartloli.** Created by Apr 30, 2018*/
public class SerializeUtils {/** 实现序列化. */public static byte[] serialize(Object object) {try {return object.toString().getBytes("UTF8");// 返回字节数组} catch (Exception e) {e.printStackTrace(); // 抛出异常信息}return null;}/** 实现反序列化. */public static <T> Object deserialize(byte[] bytes) {try {return new String(bytes, "UTF8");// 反序列化} catch (Exception e) {e.printStackTrace();}return null;}}
3. 编写自定义序列化逻辑代码
/*** 自定义序列化实现.* * @author smartloli.** Created by Apr 30, 2018*/
public class JSalarySeralizer implements Serializer<JSalarySerial> {@Overridepublic void configure(Map<String, ?> configs, boolean isKey) {}/** 实现自定义序列化. */@Overridepublic byte[] serialize(String topic, JSalarySerial data) {return SerializeUtils.serialize(data);}@Overridepublic void close() {}}4. 编写生产者应用程序
/*** 自定义序列化, 发送消息给Kafka.* * @author smartloli.** Created by Apr 30, 2018*/
public class JProducerSerial extends Thread {private static Logger LOG = LoggerFactory.getLogger(JProducerSerial.class);/** 配置Kafka连接信息. */public Properties configure() {Properties props = new Properties();props.put("bootstrap.servers", "dn1:9092,dn2:9092,dn3:9092");// 指定Kafka集群地址props.put("acks", "1"); // 设置应答模式, 1表示有一个Kafka代理节点返回结果props.put("retries", 0); // 重试次数props.put("batch.size", 16384); // 批量提交大小props.put("linger.ms", 1); // 延时提交props.put("buffer.memory", 33554432); // 缓冲大小props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 序列化主键props.put("value.serializer", "org.smartloli.kafka.game.x.book_4.serialization.JSalarySeralizer");// 自定义序列化值return props;}public static void main(String[] args) {JProducerSerial producer = new JProducerSerial();producer.start();}/** 实现一个单线程生产者客户端. */public void run() {Producer<String, JSalarySerial> producer = new KafkaProducer<>(configure());JSalarySerial jss = new JSalarySerial();jss.setId("2018");jss.setSalary("100");producer.send(new ProducerRecord<String, JSalarySerial>("test_topic_ser_des", "key", jss), new Callback() {public void onCompletion(RecordMetadata metadata, Exception e) {if (e != null) {LOG.error("Send error, msg is " + e.getMessage());} else {LOG.info("The offset of the record we just sent is: " + metadata.offset());}}});try {sleep(3000);// 间隔3秒} catch (InterruptedException e) {LOG.error("Interrupted thread error, msg is " + e.getMessage());}producer.close();// 关闭生产者对象}
}
自定义主题分区

编写自定义主题分区算法
/*** 实现一个自定义分区类.** @author smartloli.** Created by Apr 30, 2018*/
public class JPartitioner implements Partitioner {@Overridepublic void configure(Map<String, ?> configs) {}/** 实现Kafka主题分区索引算法. */@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {int partition = 0;String k = (String) key;partition = Math.abs(k.hashCode()) % cluster.partitionCountForTopic(topic);return partition;}@Overridepublic void close() {}}演示自定义分区的作用
/*** 实现一个生产者客户端应用程序.* * @author smartloli.** Created by Apr 27, 2018*/
public class JProducerThread extends Thread {// 创建一个日志对象private final Logger LOG = LoggerFactory.getLogger(JProducerThread.class);// 声明最大线程数private final static int MAX_THREAD_SIZE = 6;/** 配置Kafka连接信息. */public Properties configure() {Properties props = new Properties();props.put("bootstrap.servers", "dn1:9092,dn2:9092,dn3:9092");// 指定Kafka集群地址props.put("acks", "1"); // 设置应答模式, 1表示有一个Kafka代理节点返回结果props.put("retries", 0); // 重试次数props.put("batch.size", 16384); // 批量提交大小props.put("linger.ms", 1); // 延时提交props.put("buffer.memory", 33554432); // 缓冲大小props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 序列化主键props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");// 序列化值props.put("partitioner.class", "org.smartloli.kafka.game.x.book_4.JPartitioner");// 指定自定义分区类return props;}public static void main(String[] args) {// 创建一个固定线程数量的线程池ExecutorService executorService = Executors.newFixedThreadPool(MAX_THREAD_SIZE);// 提交任务executorService.submit(new JProducerThread());// 关闭线程池executorService.shutdown();}/** 实现一个单线程生产者客户端. */public void run() {Producer<String, String> producer = new KafkaProducer<>(configure());// 发送100条JSON格式的数据for (int i = 0; i < 10; i++) {// 封装JSON格式JSONObject json = new JSONObject();json.put("id", i);json.put("ip", "192.168.0." + i);json.put("date", new Date().toString());String k = "key" + i;// 异步发送producer.send(new ProducerRecord<String, String>("ip_login_rt", k, json.toJSONString()), new Callback() {public void onCompletion(RecordMetadata metadata, Exception e) {if (e != null) {LOG.error("Send error, msg is " + e.getMessage());} else {LOG.info("The offset of the record we just sent is: " + metadata.offset());}}});}try {sleep(3000);// 间隔3秒} catch (InterruptedException e) {LOG.error("Interrupted thread error, msg is " + e.getMessage());}producer.close();// 关闭生产者对象}}
![[技术杂谈]如何下载vscode历史版本](https://img-blog.csdnimg.cn/direct/18e927e78e82496e80649940eb70a716.png)