文献速递:肿瘤分割---- ALA-Net:用于3D结直肠肿瘤分割的自适应病变感知注意力网络
01
文献速递介绍
结直肠癌(CRC)在全球范围内与高发病率和死亡率相关,。肿瘤的预后高度依赖于诊断时疾病的阶段。准确检测和分割肿瘤及其周围的结直肠组织对于促进病理分期的预测和指导适当治疗至关重要。在临床常规中,癌变区域是在磁共振(MR)图像上手动识别和描绘的。然而,在大量MR图像上进行手动标记和描绘是一项繁琐、易出错且依赖操作者的任务。因此,开发一种准确和自动的结直肠肿瘤分割技术是非常必要的。尽管以前对这一主题进行了大量研究,但这项任务仍然困难,原因在于对比度差、各向异性空间分辨率、强度不均匀、缺乏先验信息和类别不平衡等因素。此外,结直肠肿瘤具有特征性的模糊边界,并在形状、大小和结构上表现出显著变化,这进一步增加了它们完全自动分割的难度。基于信心连接区域生长算法或超体素聚类的传统结直肠肿瘤分割方法在需要精确肿瘤边界的情况下是不足够的。这些算法容易受到噪声的影响,通常需要手动干预。目前,深度卷积神经网络(DCNNs)在医学图像分割任务中取得了显著成功。这是因为它们能够直接从数据中学习逐渐复杂的特征表示层次。然而,重复组合的池化和下采样层,使模型获得对空间变换的不变性,本质上导致了细节和位置信息的丢失,从而限制了定位的准确性。
Title
题目
ALA-Net: Adaptive Lesion-Aware Attention Network for 3D Colorectal Tumor Segmentation
ALA-Net:用于3D结直肠肿瘤分割的自适应病变感知注意力网络
Abstract
摘要
Accurate and reliable segmentation of colorectal tumors and surrounding colorectal tissues on 3D magnetic resonance images has critical importance in preoperative prediction, staging, and radiotherapy. Previous works simply combine multilevel features without aggregating representative semantic information and without compensating for the loss of spatial information caused by down-sampling. Therefore, they are vulnerable to noise from complex backgrounds and suffer from misclassification and target incompleteness-related failures. In this paper, we address these limitations with a novel adaptive lesion-aware attention network (ALA-Net) which explicitly integrates useful contextual information with spatial details and captures richer feature dependencies based on 3D attention mechanisms. The model comprises two parallel encoding paths. One of these is designed to explore global contextual features and enlarge the receptive field using a recurrent strategy. The other captures sharper object boundaries and the details of small objects that are lost in repeated down-sampling layers. Our lesion-aware attention module adaptively captures long-range semantic dependencies and highlights the most discriminative features, improving semantic consistency and completeness. Furthermore, we introduce a prediction aggregation module to combine multiscale feature maps and to further filter out irrelevant information for precise voxel-wise prediction.
精确可靠地在3D磁共振图像上分割结直肠肿瘤及其周围结直肠组织对于术前预测、分期和放疗至关重要。之前的研究仅简单地结合多层次特征,没有聚合有代表性的语义信息,也没有补偿下采样造成的空间信息损失。因此,它们容易受到复杂背景噪声的影响,并遭受误分类和目标不完整性相关的失败。在本文中,我们通过一个新颖的自适应病变感知注意力网络(ALA-Net)来解决这些限制,该网络明确地将有用的上下文信息与空间细节整合,并基于3D注意力机制捕获更丰富的特征依赖性。该模型包括两个并行的编码路径。其中一个旨在通过循环策略探索全局上下文特征并扩大感受野。另一个捕获更清晰的对象边界和在重复下采样层中丢失的小对象细节。我们的病变感知注意力模块能够自适应地捕获长范围语义依赖性,并突出最具辨别性的特征,提高语义一致性和完整性。此外,我们引入了一个预测聚合模块,用于组合多尺度特征图,并进一步过滤掉不相关信息,以实现精确的体素级预测。
Methods
方法
The architecture of our ALA-Net is illustrated in Fig. 1. We first feed input into a GCE, which captures rich context information at four different resolution stages. To compensate for the inevitable loss of spatial information caused by down-sampling operations in the GCE, we also feed input into a DSRP which probes spatial features to recover details of local features. We concatenate feature maps from GCE and DSRP at each resolution stage and perform trilinear interpolation followed by convolution operations to accomplish feature refinement. This refinement processing is conducive to enhancing the network’s ability to handle small objects and reconstruct lost boundary details. We denote up-sampled features at multiple scales as Fs, where s indicates the resolution stage in the architecture. Subsequently, Fs from all scales are concatenated to form FM L , which encodes low-level fine-grained features from shallow layers and high-level semantics fromdeeper layers. We combine FM L with each Fs and feed them into the proposed LAMs to generate attentive features. Finally, we fuse the multiple attentive feature maps by a PAM to obtain segmentation results. The following subsections present the details of each network component and elaborate on the motivations behind them.
我们的ALA-Net架构如图1所示。我们首先将输入送入GCE,该GCE在四个不同的分辨率阶段捕获丰富的上下文信息。为了弥补GCE中下采样操作不可避免地造成的空间信息丢失,我们还将输入送入DSRP,该DSRP探测空间特征以恢复局部特征的细节。我们在每个分辨率阶段将GCE和DSRP的特征图进行串联,并执行三线性插值,随后进行卷积操作以完成特征细化。这种细化处理有助于增强网络处理小物体和重构丢失边界细节的能力。我们将架构中各分辨率阶段的上采样特征表示为Fs,其中s表示分辨率阶段。随后,所有尺度的Fs被串联形成FM L ,它从浅层编码低级细腻特征和从深层编码高级语义。我们将FM L 与每个Fs结合,并将它们送入所提出的LAMs以生成注意力特征。最后,我们通过PAM融合多个注意力特征图以获得分割结果。以下小节将介绍每个网络组件的细节,并阐述其背后的动机。
Conclusions
结论
We proposed ALA-Net, a novel architecture based on the attention mechanism for fully automatic, whole volume colorectal tumor segmentation. Our approach yields an effective and efficient scheme which leverages multiscale contextual information and recovers fine-grained spatial information lost in down-sampling layers in order to refine the learned feature representation. Our key idea is to allow the network to concentrate on semantically salient regions and to select features beneficial to the recovery of lesions by using the attention mechanism. Experimental results on a large quantity of challenging pelvic volumes show that ALA-Net outperforms 2D, 3D, and hybrid 2D-3D state-of-the-art methods. We also conducted extensive ablation experiments to evaluate the impact of the individual network components and further motivate our design choices. Our results demonstrate the effectiveness of our approach in providing precise and reliable automatic segmentation of colorectal tumors and surrounding normal tissues. The segmentation results of tumors and of surrounding colorectal tissues reveal how deeply the primary tumor has grown into the bowel lining, providing oncologists with accurate information to help determine the tumor stage. In our future work, we will work on reliable, efficient, weakly supervised deep learning models for colorectal tumor segmentation, as the delineation procedure is laborious and timeconsuming. Furthermore, we will explore the postprocessing module using GANs to refine the outputs.
我们提出了ALA-Net,这是一种基于注意力机制的全新架构,用于结直肠肿瘤的全自动、全体积分割。我们的方法提供了一个有效且高效的方案,它利用多尺度上下文信息并恢复在下采样层中丢失的细腻空间信息,以精炼学习到的特征表示。我们的核心思想是让网络集中注意力于语义上显著的区域,并选择对恢复病变有益的特征,通过使用注意力机制实现这一点。在大量具有挑战性的盆腔体积上的实验结果显示,ALA-Net优于2D、3D和混合2D-3D的最先进方法。我们还进行了广泛的消融实验,以评估各个网络组件的影响,并进一步激励我们的设计选择。我们的结果展示了我们的方法在提供精确可靠的结直肠肿瘤及其周围正常组织的自动分割方面的有效性。肿瘤及其周围结直肠组织的分割结果揭示了原发性肿瘤在肠道内膜中的深度生长情况,为肿瘤分期提供了精确信息,以帮助肿瘤学家确定肿瘤阶段。在未来的工作中,我们将致力于可靠、高效的弱监督深度学习模型,用于结直肠肿瘤分割,因为勾画程序是费时且繁琐的。此外,我们还将探索使用GANs来细化输出的后处理模块。
Figure
图

Fig. 1. Schematic of ALA-Net. GCE: global context encoder; WRRB: wide recurrent residual block; RM: reduction module; DSRP: dense spatial refinement path; WSB: weighted dense block; TL: transition layer; H3DC: hybrid 3D dilated convolution; Fs: up-sampled features from multiple resolution stages; FML: combined features from multiple layers; LAM: lesion-aware attention module; PAM: prediction aggregation module. AFs: attentive features from four LAMs. 2×up and 4×up denote trilinear up-sampling by a factor of two and four, respectively.
图1。ALA-Net示意图。GCE:全局上下文编码器;WRRB:宽循环残差块;RM:降维模块;DSRP:密集空间细化路径;WSB:加权密集块;TL:过渡层;H3DC:混合3D膨胀卷积;Fs:来自多个分辨率阶段的上采样特征;FML:来自多层的组合特征;LAM:病变感知注意力模块;PAM:预测聚合模块。AFs:来自四个LAM的注意力特征。2×up和4×up分别表示通过两倍和四倍的因子进行三线性上采样。
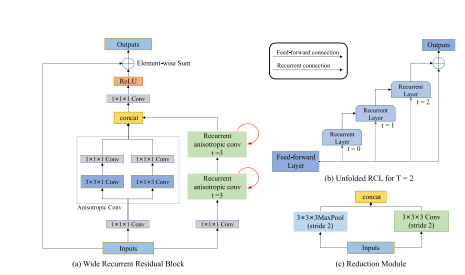
Fig. 2. Structure of WRRB and reduction module. (a) Components in a WRRB, consisting of three branches. (b) Unfolded RCL for T = 2. The effective receptive field of an RCL unit expands when the iteration number t increases. © Components in a reduction module
图2。WRRB和降维模块的结构。(a) WRRB中的组件,由三个分支组成。(b) 当T = 2时展开的RCL。当迭代次数t增加时,RCL单元的有效接收场会扩大。© 降维模块中的组件。
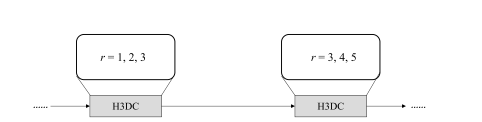
Fig. 3. Illustration of hybrid 3D dilated convolution strategy. r denotes the dilatedrate, representing inserting r − 1 zeros between two consecutive filter values along each spatial dimension. The first H3DC adopts r = 1, 2, 3, whereas the second adopts r = 3, 4, 5. In each H3DC, the applied dilation rates do not have a common factor relationship according to [25]
图3。混合3D膨胀卷积策略的示意图。r表示膨胀率,代表在每个空间维度上两个连续滤波器值之间插入r − 1个零。第一个H3DC采用r = 1, 2, 3,而第二个采用r = 3, 4, 5。在每个H3DC中,根据[25]的说法,应用的膨胀率没有公因数关系。
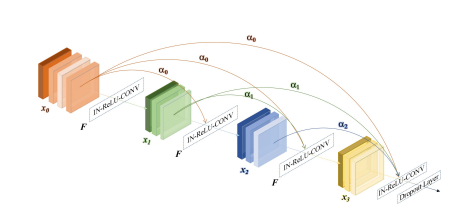
Fig. 4. Weighted dense block. αl denotes the attention score for each direct connection starting from lth layer. F · denotes the combination of instance normalization (IN), rectified linear units (ReLU) and 3D convolution. At the end of each WSB, we apply a dropout layer with the dropout rate of 0.2 to avoid overfitting.
图4。加权密集块。αl表示从第l层开始的每个直接连接的注意力得分。F · 代表实例归一化(IN)、整流线性单元(ReLU)和3D卷积的组合。在每个WSB的末端,我们应用一个dropout率为0.2的dropout层以避免过拟合。
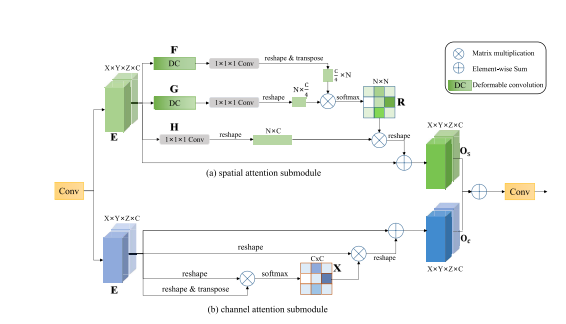
Fig. 5. Lesion-aware attention module. E: input feature maps; O: output feature maps; R: spatial attention map; X: channel attention map.
图5。病变感知注意力模块。E:输入特征图;O:输出特征图;R:空间注意力图;X:通道注意力图。
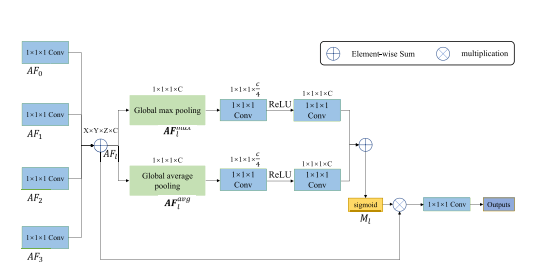
Fig. 6. Prediction aggregation module. AF0, AF1, AF2, and AF3 are the multilevel attentive features from four LAMs. After 1 × 1 × 1 convolution, these feature maps are combined by element-wise sum operation, generating AFl . AFmax l and AFavg l denote average-pooled features and max-pooled features, respectively. To reduce parameter overhead, we reduce the channel numbers of Fmax l and F avg l to a quarter of the original size. Ml denotes the attention map that generates the weights along the channel dimension.
图6。预测聚合模块。AF0,AF1,AF2和AF3是来自四个LAM的多级注意力特征。经过1×1×1卷积后,这些特征图通过元素级求和操作结合起来,生成AFl。AFmax l 和AFavg l分别表示平均池化特征和最大池化特征。为了减少参数开销,我们将Fmax l 和Favg l的通道数减少到原来大小的四分之一。Ml表示沿通道维度生成权重的注意力图。

Fig. 7. Qualitative results. Colorectal tumor (red); Surrounding normal colorectal tissues (green)
图7。定性结果。结直肠肿瘤(红色);周围正常结直肠组织(绿色)
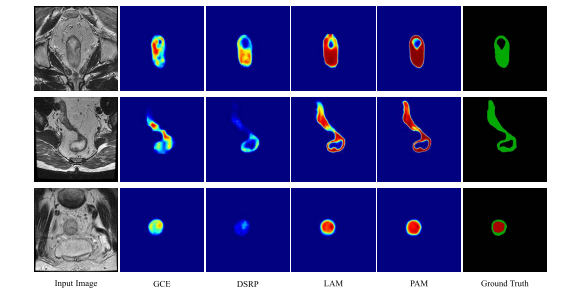
Fig. 8. Visualization results of the feature maps. For each row, we show an input image, the corresponding feature maps from the outputs of GCE, DSRP, and LAM at the fourth resolution stage, and feature maps from the outputs of PAM and the ground truth.
图8。特征图的可视化结果。对于每一行,我们展示了一张输入图像,以及来自第四分辨率阶段的GCE、DSRP和LAM输出的相应特征图,以及来自PAM输出的特征图和真实标签。
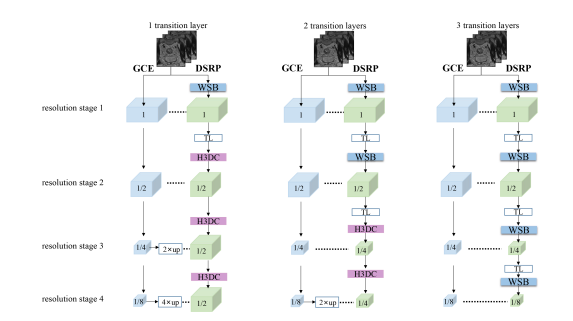
Fig. 9. Variants of DSRP. The difference between these three options is the number of transition layers (TL) and the ratio of the final output feature map size to the original input size
图9。DSRP的变体。这三种选项之间的区别在于过渡层(TL)的数量以及最终输出特征图尺寸与原始输入尺寸的比率。

Fig. 10. Qualitative results on public datasets. The first and second rows show results on the lung segmentation dataset. The third to fifth rows show results on the LiTS challenge, where the liver is depicted in green and the tumors are depicted in red. Our method consistently performs well on the two public datasets.
图10。公共数据集上的定性结果。第一行和第二行展示了肺部分割数据集的结果。第三行到第五行展示了LiTS挑战的结果,其中肝脏以绿色表示,肿瘤以红色表示。我们的方法在这两个公共数据集上表现一致良好。
Table
表
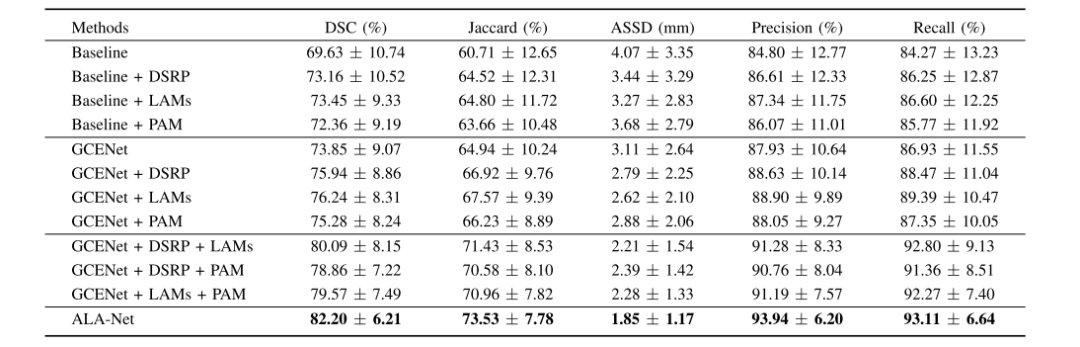
table 1 ablation study on indixidual contribution of different modules in the ten-foldcross-validation process(MEAN ± S.D.)
表I 十折交叉验证过程中不同模块单独贡献的消融研究(均值 ± 标准差)
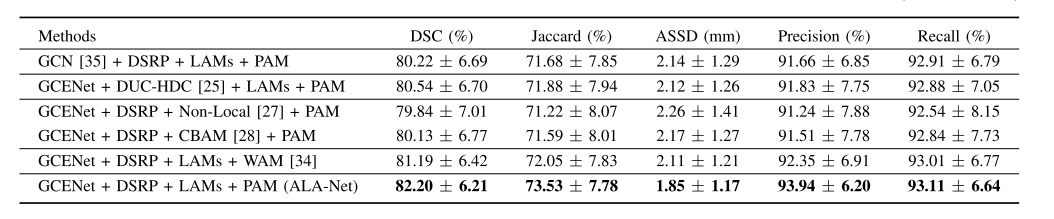
TABLE II comparison between modules and their close alterna tives in the ten-fold cross-validation process(MEAN ± S.D.)
表II 十折交叉验证过程中模块及其近似替代品的比较(均值 ± 标准差)
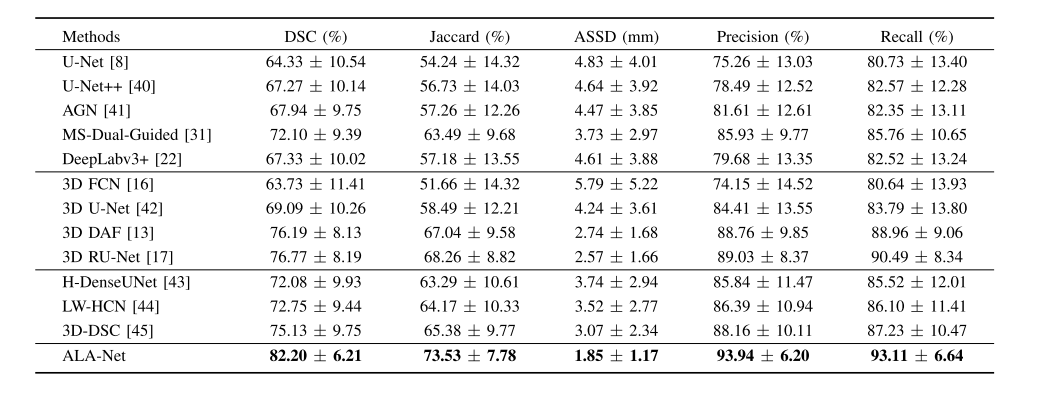
TABLE III comparison to other state-of-the-art architectures(MEAN ± S.D.)
表III 与其他最先进架构的比较(均值 ± 标准差)
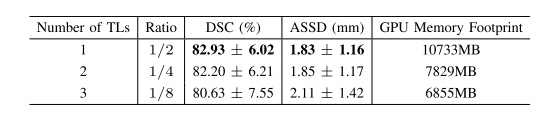
TABLE IVevaluations of using different numbers of transition layers(TL).we use 2 transition layers in dsrp throughout all experiments forementioned in the paper because this turns out to be the best compromise between accuracy and efficiency.note that the configuration of none transition layer is ignored due to the memory limitation.ratio=(OUTPUT SIZE / ORIGINAL INPUT)
表IV 使用不同数量过渡层(TL)的评估。在本文中提到的所有实验中,我们在DSRP中使用2个过渡层,因为这被证明是在准确性和效率之间的最佳折衷。请注意,由于内存限制,没有过渡层的配置被忽略。比率 =(输出尺寸 / 原始输入)
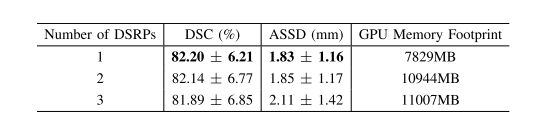
TABLE V evaluations of using different numbers of dense spatial refinent paths (DSRPS). we use 1 dsrp throughout all experiments forementioned in the paper because this turns out to be the best choice
表V 使用不同数量密集空间细化路径(DSRPs)的评估。在本文中提到的所有实验中,我们使用1个DSRP,因为这被证明是最佳选择。
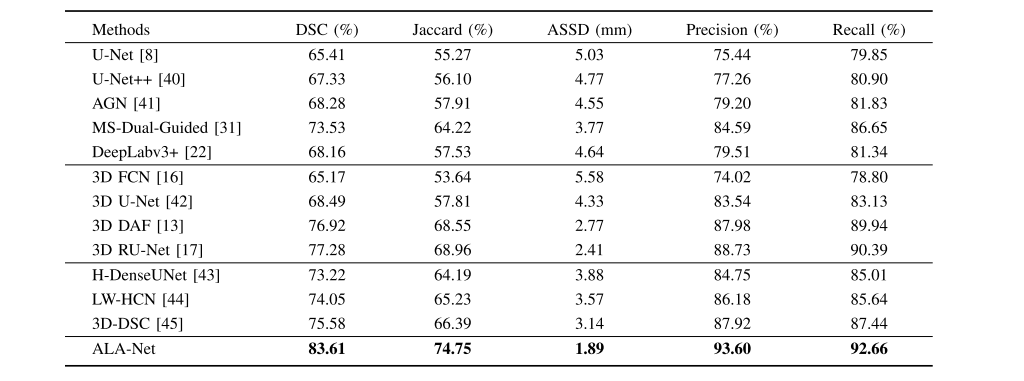
TABLE VI comparison to other state-of-the-art Architectures on independent test set
表VI 在独立测试集上与其他最先进架构的比较
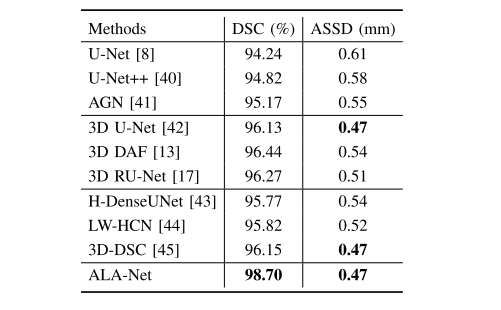
TABLE VII segmentation results on lung segmentation dataset
表VII 肺部分割数据集上的分割结果
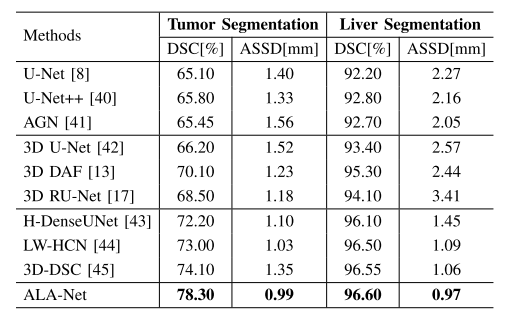
TABLE VIII segmentation results on lits dataset
表VIII LiTS数据集上的分割结果
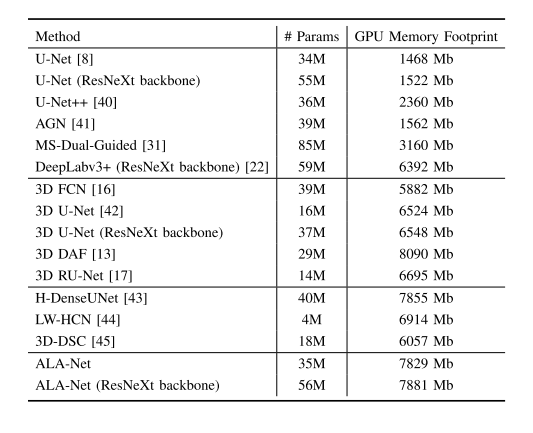
TABLE IX evaluations of model complexity,showing the parameters of different models
表IX 模型复杂度评估,展示了不同模型的参数情况