在当今数据驱动的世界中,高效、快速地处理和搜索大量数据成为了许多应用的核心需求。Elasticsearch,作为一款功能强大的开源搜索和分析引擎,通过其独特的内存架构和管理策略,实现了对大规模数据集的快速索引和查询。本文将深入解析Elasticsearch的内存架构,并探讨如何优化其内存使用以获得最佳性能。
一、Elasticsearch的内存架构概述
Elasticsearch的内存架构主要分为两大部分:堆内存(On-Heap)和堆外内存(Off-Heap)。这两部分内存各有其用途和管理策略,共同支撑着Elasticsearch的高性能和可扩展性。
二、堆内存(On-Heap)详解
堆内存是Elasticsearch JVM进程分配的内存空间,用于存储Java对象。
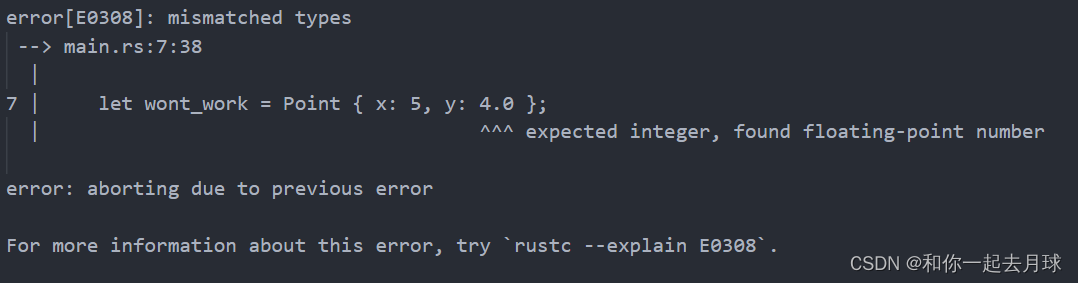
es使用Lucene作为其底层搜索引擎,但Lucene的某些数据结构并不直接存储在堆内存中,而是存储在堆外内存中。堆内存是垃圾回收(GC)的主要目标,GC会清除不再使用的对象以释放内存空间。

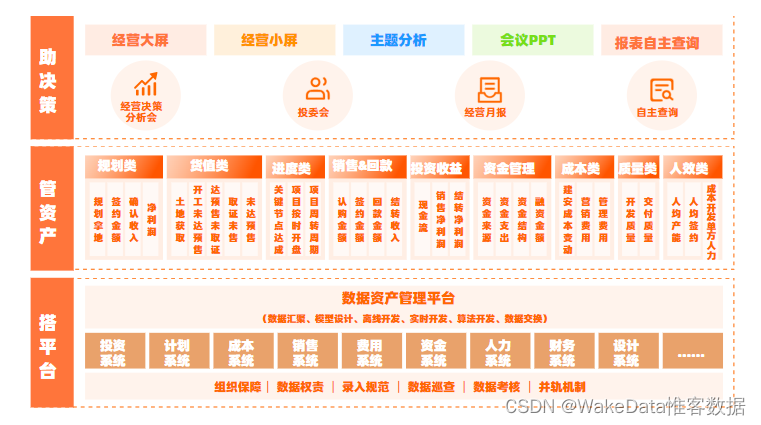
Elasticsearch在堆内存中维护了多个内存池,用于不同类型的数据结构。这些内存池包括索引缓冲区、节点查询缓存、分片请求缓存、字段数据缓存和段缓存等。每个内存池都有其特定的用途和管理策略。
例如,索引缓冲区用于新文档的写入缓冲,当缓冲满时,内容会被刷新到磁盘上的Lucene段中。而字段数据缓存则用于聚合和排序操作,当执行这些操作时,字段数据会被加载到堆内存中。Elasticsearch通过LRU(最近最少使用)算法和其他策略来管理这些内存池的使用,确保重要的操作能够得到足够的内存资源。

内存池:
Elasticsearch在堆内存中维护了多个内存池,用于不同类型的数据结构。这些内存池包括:
- Indexing Buffer:用于新文档的写入缓冲,当缓冲满时,内容会被刷新到磁盘上的Lucene段中。
- Node Query Cache:节点级别的查询缓存,用于存储频繁查询的结果。
Shard Request Cache:分片级别的请求缓存,用于缓存分片级别的搜索结果。 - Field Data Cache:字段数据缓存,用于聚合和排序操作。当执行这些操作时,字段数据会被加载到堆内存中。
- Segments Cache:Lucene段的缓存,用于存储已经加载到内存中的Lucene段信息。
内存管理: Elasticsearch通过LRU(最近最少使用)算法和其他策略来管理内存池的使用。当内存不足时,Elasticsearch会根据需要清除缓存中的数据,以确保重要的操作能够得到足够的内存资源。
三、堆外内存(Off-Heap)探秘
与堆内存不同,堆外内存不由JVM直接管理,而是由Lucene管理。Lucene使用堆外内存来存储其倒排索引和其他数据结构,这些数据结构对于搜索性能至关重要。将部分内存管理交给Lucene处理可以减少垃圾回收对搜索性能的影响,因为Lucene的数据结构通常不需要进行频繁的GC。
此外,堆外内存的使用还可以避免JVM的内存限制,使Elasticsearch能够处理更大的数据集。虽然堆外内存不由JVM直接管理,但Elasticsearch仍然提供了一些工具和设置来监控和调整堆外内存的使用。例如,可以通过配置文件设置Lucene的内存限制,以避免使用过多的系统资源。
四、优化Elasticsearch的内存使用
为了充分发挥Elasticsearch的性能,需要合理配置和优化其内存使用。以下是一些建议:
-
合理配置JVM堆大小:根据服务器的物理内存和Elasticsearch的工作负载来合理配置JVM堆的大小。过小的堆可能导致内存不足,而过大的堆可能会增加垃圾回收的开销。建议将JVM堆大小设置为服务器物理内存的一半左右,并留下足够的内存供操作系统和其他进程使用。
-
使用合适的缓存策略:根据实际需求调整Elasticsearch的缓存设置。对于频繁查询的数据,可以将其缓存在节点查询缓存或分片请求缓存中,以加快查询速度。对于不常查询的数据,可以将其从缓存中清除,以节省内存空间。
-
监控和调整:定期监控Elasticsearch的内存使用情况,并根据实际情况进行调整。可以使用Elasticsearch提供的监控工具或第三方监控解决方案来实现。通过监控,可以及时发现内存泄漏、内存溢出等问题,并采取相应的措施进行解决。
五、总结
Elasticsearch的内存架构是其高性能和可扩展性的重要基础。通过合理配置和优化内存使用,可以确保Elasticsearch在各种工作负载下都能提供稳定、高效的搜索和分析服务。对于Elasticsearch的用户和开发者来说,深入了解其内存架构和管理策略是释放其全部潜能的关键一步。希望本文的内容能为大家提供一些有益的参考和启示。


![[leetcode] 29. 两数相除](https://img-blog.csdnimg.cn/direct/a36c1b59f2eb48eebd27dc7ba26116ca.png)