前提情要:各位小伙伴是否已经熟练掌握前半部分知识点,各位可以找一下相关练习,或者等待我下面会发布的代码实践进行练习,如果一切ok,那我们将开始下半部分学习(good)。
如果还没有看,请点击链接前去学习:最详细PE文件格式讲解!!!!!__image_file_header的characteristics第六位表示啥-CSDN博客
回忆:在上半部分我们还有一个知识点木有讲解----> IMAGE_OPTIONAL_HEARDER32中的最后一个成员DataDirectory,虽然它是一个结构体数组,但是它却是PE文件中最重要的成员,涵盖了我们整个下半部分内容,PE装载器通过查看它才能准确的找到某个函数或者资源。
需要重要掌握:
(1) 0x01 IMAGE_EXPORT_DIRECTORY----->导出表
(2)0x03 IMAGE_BASE_RELOCATION--->重定位表
(3) 0x05 IMAGE_IMPORT_DESCRIPTION--->导入表
(4)0x07 IMAGE_BOUND_IMPORT_DESCRIPTION--->绑定导入表
(5)0x09 IMAGE_RESOURCE_DIRECTORY--->资源表
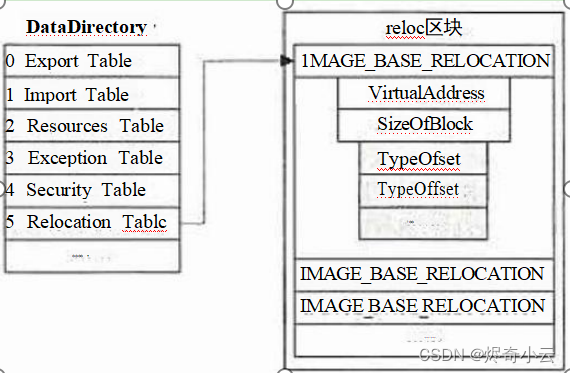
一:数据目录结构-----IMAGE_DATA_DIRECTORY

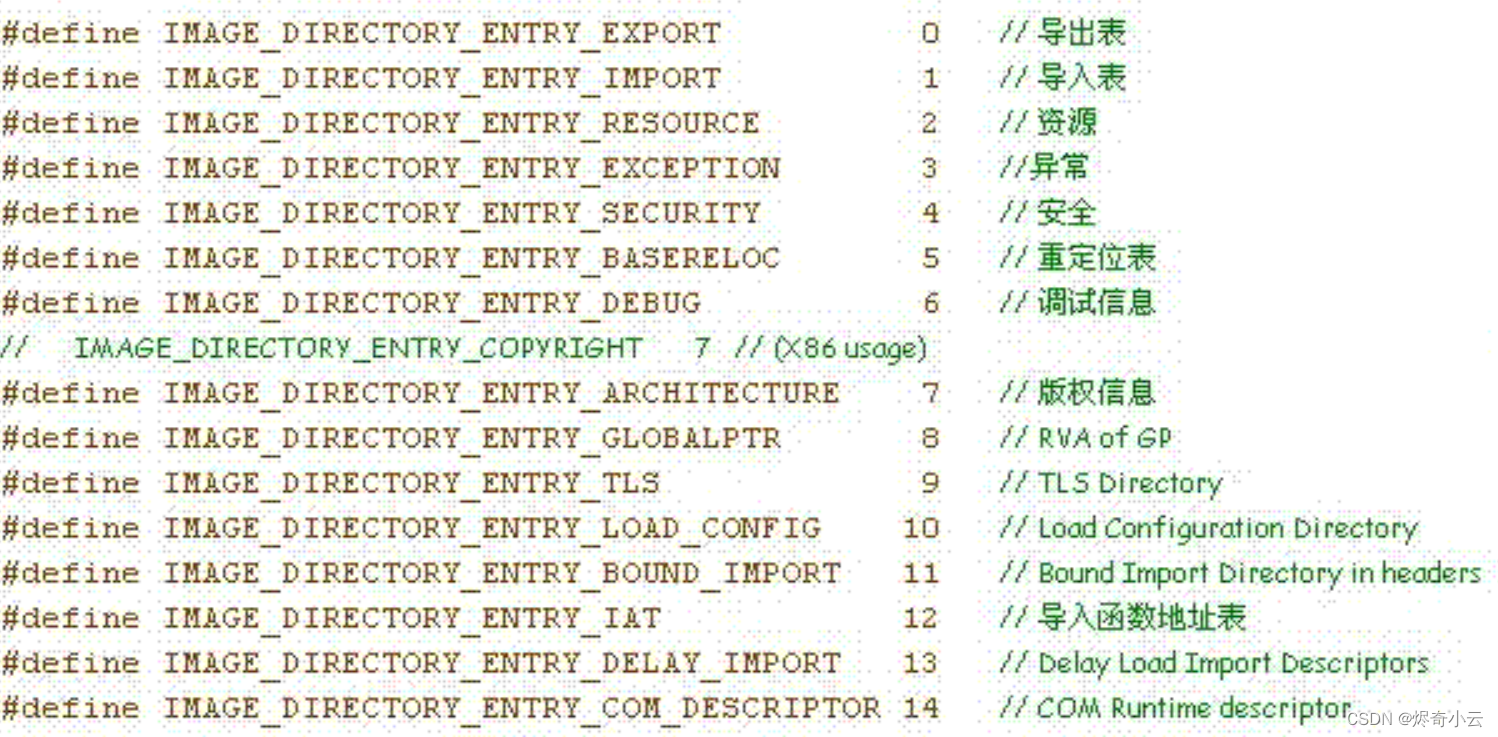
IMAGE_DATA_DIRECTORY的结构体定义如下:
typedef struct _IMAGE_DATA_DIRECTORY {DWORD VirtualAddress; /**指向某个数据的相对虚拟地址 RAV 偏移0x00**/DWORD Size; /**某个数据块的大小 偏移0x04**/
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;在这个数据目录结构体中只有俩个成员VirtualAddress和Size,这俩个成员含义比较简单,VirtualAddress指定了数据块的相对虚拟地址(RVA),Size则指定了该数据块的大小。需要注意有时并不是该类型的总大小,可能只是该类型一个数据项的大小,这俩成员成为了定位各种表的关键,所以一定要知道每个数组元素指向的数据块类型。
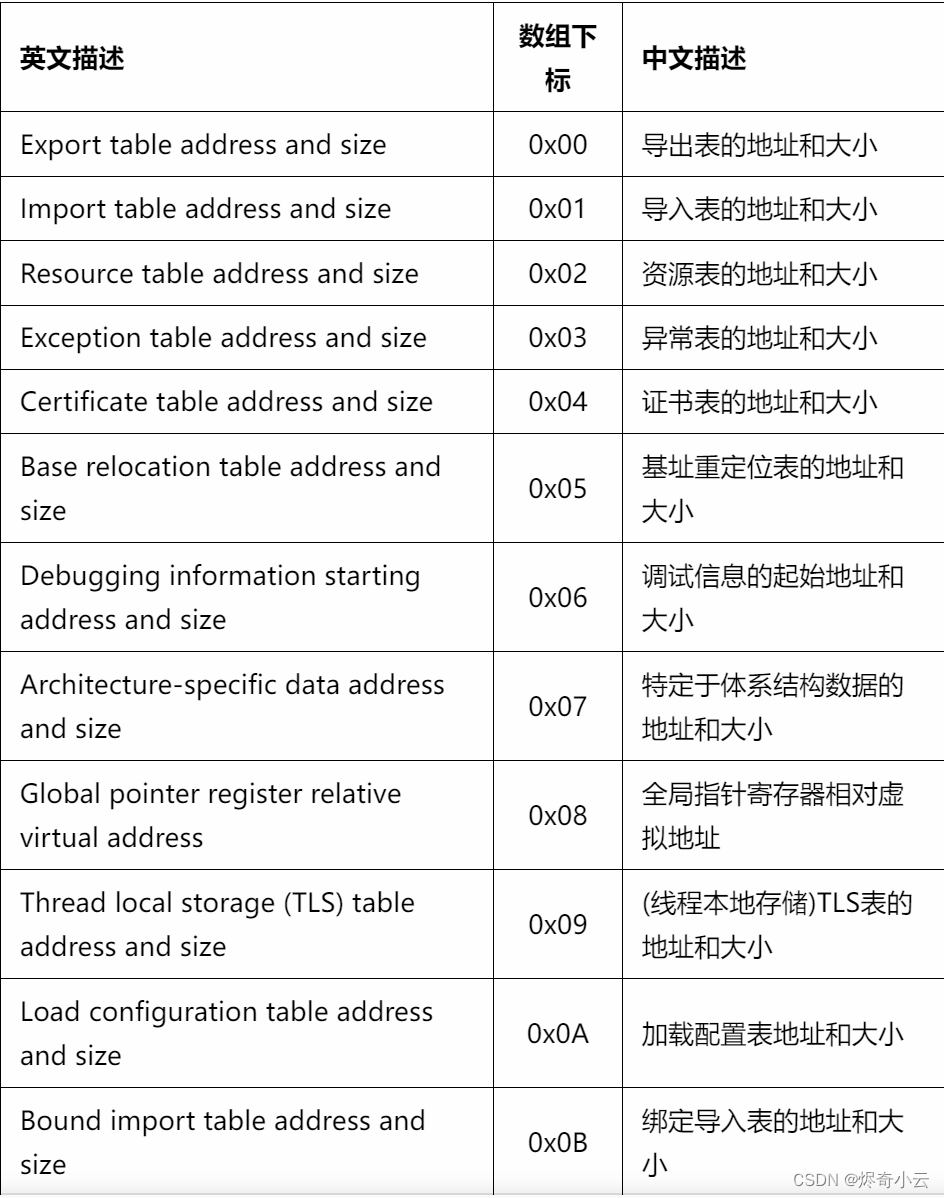

//定位目录项的方法(以导出表为例):
所有操作都在FileBuffer状态下完成//1、指向相关内容
PIMAGE_DOS_HEADER pDosHeader = (PIMAGE_DOS_HEADER)(FileAddress);PIMAGE_FILE_HEADER pFileHeader = (PIMAGE_FILE_HEADER)((DWORD)pDosHeader + pDosHeader->e_lfanew + 4);
//知道为什么加4嘛,因为有一个标准成员大小为四。
PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileHeader + sizeof(IMAGE_FILE_HEADER));//2、获取导出表的地址(目录项的第0个成员)
DWORD ExportDirectory_RAVAdd = pOptionalHeader->DataDirectory[0].VirtualAddress;
DWORD ExportDirectory_FOAAdd = 0;// (1)、判断导出表是否存在
if (ExportDirectory_RAVAdd == 0)
{printf("ExportDirectory 不存在!\n");return ret;
}
// (2)、获取导出表的FOA地址
ret = RVA_TO_FOA(FileAddress, ExportDirectory_RAVAdd, &ExportDirectory_FOAAdd);
if (ret != 0)
{printf("func RVA_TO_FOA() Error!\n");return ret;
}//3、指向导出表
PIMAGE_EXPORT_DIRECTORY ExportDirectory = (PIMAGE_EXPORT_DIRECTORY)((DWORD)FileAddress + ExportDirectory_FOAAdd);int RVA_TO_FOA(PVOID FileAddress, DWORD RVA, PDWORD pFOA)
{int ret = 0;PIMAGE_DOS_HEADER pDosHeader = (PIMAGE_DOS_HEADER)(FileAddress);PIMAGE_FILE_HEADER pFileHeader = (PIMAGE_FILE_HEADER)((DWORD)pDosHeader + pDosHeader->e_lfanew + 4);PIMAGE_OPTIONAL_HEADER32 pOptionalHeader = (PIMAGE_OPTIONAL_HEADER32)((DWORD)pFileHeader + sizeof(IMAGE_FILE_HEADER));PIMAGE_SECTION_HEADER pSectionGroup = (PIMAGE_SECTION_HEADER)((DWORD)pOptionalHeader + pFileHeader->SizeOfOptionalHeader);//RVA在文件头中 或 SectionAlignment 等于 FileAlignment 时RVA等于FOAif (RVA < pOptionalHeader->SizeOfHeaders || pOptionalHeader->SectionAlignment == pOptionalHeader->FileAlignment){*pFOA = RVA;return ret;}//RVA在节区中for (int i = 0; i < pFileHeader->NumberOfSections; i++){if (RVA >= pSectionGroup[i].VirtualAddress && RVA < pSectionGroup[i].VirtualAddress + pSectionGroup[i].Misc.VirtualSize){*pFOA = pSectionGroup[i].PointerToRawData + RVA - pSectionGroup[i].VirtualAddress;return ret;}}//没有找到地址ret = -4;printf("func RAV_TO_FOA() Error: %d 地址转换失败!\n", ret);return ret;
}二:导出表---IMAGE_EXPORT_DIRECTORT
创建一个DLL时,实际上创建了一组能让EXE或者其他DLL调用的函数,此时PE装载器根据DLL文件中输出的信息修正被执行文件的IAT。当第一个DLL函数能被EXE或者另外一个DLL文件使用时,它就被“输出了”。其中,输出信息被保存在导出表(输出表)中,DLL文件通过输出表向系统提供输出函数名称,序号和入口地址等信息。
EXE文件中一般不存在输出表,而大部分DLL文件中存在输出表。当然,这也不是绝对的,有些EXE也会存在。
2.1.1导出表结构定义如下:
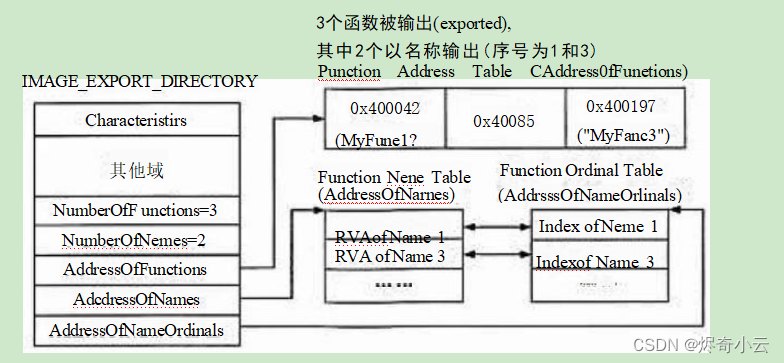
typedef struct _IMAGE_EXPORT_DIRECTORY {DWORD Characteristics; // 未使用,总为0DWORD TimeDateStamp; // 文件创建时间戳WORD MajorVersion; // 未使用,总为0WORD MinorVersion; // 未使用,总为0DWORD Name; // **重要 指向一个代表此 DLL名字的 ASCII字符串的 RVADWORD Base; // **重要 函数的起始序号DWORD NumberOfFunctions; // **重要 导出函数地址表的个数DWORD NumberOfNames; // **重要 以函数名字导出的函数个数DWORD AddressOfFunctions; // **重要 导出函数地址表RVADWORD AddressOfNames; // **重要 导出函数名称表RVADWORD AddressOfNameOrdinals; // **重要 导出函数序号表RVA
} IMAGE_EXPORT_DIRECTORY, *PIMAGE_EXPORT_DIRECTORY;输出表(Export Table) 的主要内容是一个表格,其中包括函数名称、输出序数等。序数是指定 DLL中某个函数的16位数字,在所指向的 DLL里是独一无二的。在此不提倡仅通过序数引出函数, 这会带来DLL维护上的问题。 一旦 DLL升级或被修改,调用该 DLL的程序将无法工作。
输出表是数据目录表的第1个成员,指向IMAGE_EXPORT_DIRECTORY(简称 “IED”) 结构。 IED 结构定义如上。
● Characteristics: 输出属性的旗标。目前还没有定义,总是为0。
● TimeDateStamp: 输出表创建的时间 (GMT 时间)。
● MajorVersion: 输出表的主版本号。未使用,设置为0。
● MinorVersion:输出表的次版本号。未使用,设置为0。
● Name: 指向一个ASCII字符串的 RVA。这个字符串是与这些输出函数相关联的 DLL的名字 (例如 KERNEL32.DLL)。
● Base: 这个字段包含用于这个 PE 文件输出表的起始序数值(基数)。在正常情况下这个值 是1,但并非必须如此。当通过序数来查询一个输出函数时,这个值从序数里被减去,其结 果将作为进人输出地址表(EAT) 的索引。
● NumberOfFunctions:EAT中的条目数量。注意, 一些条目可能是0,这个序数值表明没有代 码或数据被输出。
● NumberOfNames: 输出函数名称表 (ENT) 里的条目数量。NumberOfNames 的值总是小于或 等于 NumherOfFunctions 的值,小于的情况发生在符号只通过序数输出的时候。另外,当被 赋值的序数里有数字间距时也会是小于的情况,这个值也是输出序数表的长度。
● AddressOfFunctions:EAT的 RVA。EAT 是一个 RVA 数组,数组中的每一个非零的RVA都 对应于一个被输出的符号。
● AddressOINames:ENT的 RVA。ENT是一个指向ASCI 字符串的 RVA数组。每一个 ASCII 字符串对应于一个通过名字输出的符号。因为这个表是要排序的,所以ASCⅡ字符串也是按 顺序排列的。这允许加载器在查询一个被输出的符号时使用二进制查找方式,名称的排序是二进制的(就像 C++RTL中 strcmp 函数提供的一样),而不是一个环境特定的字顺序。
● AddressOfNameOrdinals: 输出序数表的 RVA。这个表是字的数组。这个表将ENT 中的数组
索引映射到相应的输出地址表条目。
设计输出表是为了方便PE 装载器工作。首先,模块必须保存所有输出函数的地址,供PE 装载 器查询。模块将这些信息保存在 AddressOfFunctions 域所指向的数组中,而数组元素数目存放在 NumberOfFunctions域中。如果模块引出了40个函数,那么在 AddressOfFunctions 指向的数组中必定 有40个元素, NumherOfFunctions 的值为40。如果有些函数是通过名字引出的,那么模块必定也在 文件中保留了这些信息。这些名字的 RVA 值存放在一个数组中,供 PE 装载器查询。该数组由 AddressOfNames 指 向 ,NumberOfNames 中包含名字数目。PE 装载器知道函数名,并想以此获取这些 函数的地址。目前已有两个模块,分别是名字数组和地址数组,但两者之间还没有联系的纽带,需要 一些联系函数名及其地址为它们建立联系。PE 文档指出,可以使用指向地址数组的索引作为连接, 因此 PE 装载器在名字数组中找到匹配名字的同时,也获取了指向地址表中对应元素的索引。这些 索引保存在由AddressOfNameOrdinals域所指向的另一个数组(最后一个)中。由于该数组起联系名 字和地址的作用,其元素数目一定与名字数组相同。例如,每个名字有且仅有1个相关地址,反过 来则不一定(一个地址可有好几个名字来对应)。因此,需要给同一个地址取“别名”。为了发挥连 接作用,名字数组和索引数组必须并行成对使用,例如索引数组的第1个元素必定含有第1个名字 的索引,依此类推。
 2.1.2输出表实例分析
2.1.2输出表实例分析
数据目录表的第1个成员指 向输出表,该指针的具体位置在 PE 文件头的78h 偏移处。该文件的 PE 文件头起始位置是100h, 输出表在整个文件的100h+78h=178h 处,因此在178h 处可以发现4字节指针“00400000”,倒过 来就是“00004000”,即输入表在内存中偏移4000h的地方。当然,4000h 是内存中的偏移量,转 换成文件偏移地址就是0C00h。 文件偏移0C00h 处是输出表的内容,如图
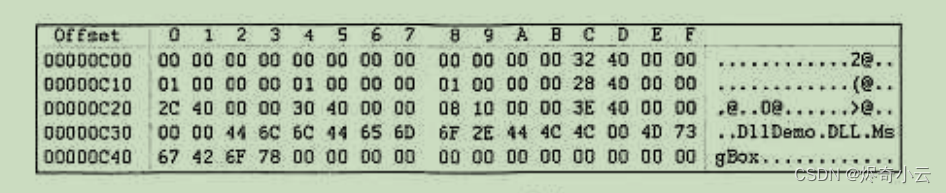
这个DLL中只有1个输出函数 MsgBox, 其 IMAGE_EXPORT_DIRECTORY 结构如表所示:

Name: 4032h-3400h=C32h, 指向 DLL的名字 DIIDemo.DLL。
● AddressOfNames:402Ch-3400h=C2Ch, 指向函数名的指针 403Eh- 3400h=C3Eh,C3Eh 再指向函数名 MsgBoxc
● AddressOfNameOrdinals:4030h-3400h=C30h, 指向输出序号数组。
再来看看输出是如何实现的。PE 装载器调用GetProcAddress 来查找 DIIDemo.DLL 里的 API 函 数 MsgBox, 系统通过定位 DIIDemo.DLL的IMAGE_EXPORT_DIRECTORY 结构开始工作。从这个结 构 中 ,PE 装载器将获得输出函数名称表(Export Names Table,ENT) 的起始地址,进而知道这个数 组里只有1个条目,它对名字进行二进制查找,直到发现字符串“MsgBox” 为止。PE 装载器发现 MsgBox 是数组的第1个条目后,加载器从输出序数表中读取相应的第1个值,这个值是 MsgBox 的输出序数。使用输出序数作为进入 EAT 的索引(也要考虑 Base 域值),得到 MsgBox 的 RVA 1008h。 用1008h 加 DIIDemo.DLL 的载入地址,得到 MsgBox 的实际地址。
2.2基址重定位
当链接器生成一个 PE 文件时,会假设这个文件在执行时被装载到默认的基地址处,并把 code 和 data 的相关地址都写入PE 文件。如果载人时将默认的值作为基地址载入,则不需要重定位。但 是,如果 PE 文件被装载到虚拟内存的另一个地址中,链接器登记的那个地址就是错误的,这时就 需要用重定位表来调整。在PE 文件中,重定位表往往单独作为一块,用“.reloc”表 示。
2.2.1基址重定位的概念
和 NE 格式的重定位方式不同, PE 格式的做法十分简单。PE 格式不参考外部 DLL或模块中的 其他区块,而是把文件中所有可能需要修改的地址放在一个数组里。如果 PE 文件不在首选的地址 载入,那么文件中的每一个定位都需要被修正。对加载器来说,它不需要知道关于地址使用的任何 细节,只要知道有一系列的数据需要以某种一致的方式来修正就可以了。下面以实例 DIIDemo.DLL 为例讲述其重定位过程。如下代码中两个加粗的地址指针就是需要重定位的数据。
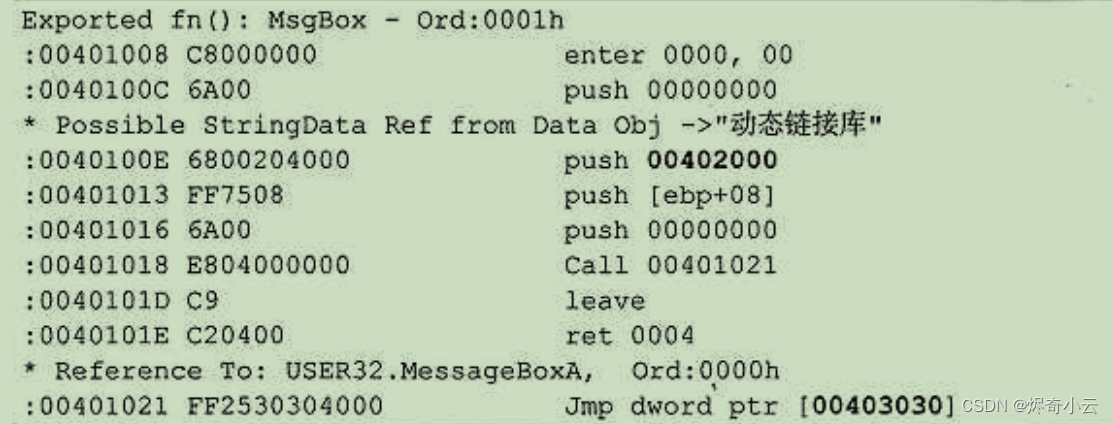
分析一下0040100Eh 处,其作用是将一个指针压入栈,00402000h 是某一字符串的指针。这句指令有5字节长,第1个字节(68h)是指令的操作码,后4个字节用来保存一个 DWORD 大小的 地址(00402000h) 。在这个例子中,指令来自一个基址为00400000h 的 DLL文件,因此这个字符串 的RVA值是2000h。如果PE 文件确实在00400000h 处载人,指令就能够按照现在的样子正确执行。 但是,当 DLL执行时, Windows加载器决定将其映射到00870000h处(映射基址由系统决定),加 载器就会比较基址和实际的载人地址,计算出一个差值。在这个例子中,差值是470000h, 这个差 值能被加载到 DWORD大小的地址里以形成新地址。在前面的例子中,地址0040100Fh 是指令中双 字的定位,对它将有一个基址重定位,实际上字符串的新地址就是00872000h 。为了让Windows 有 能力进行这样的调整,可执行文件中有多个“基址重定位数据”。本例中的 Windows 加载器应把 470000h加给00402000h, 并将结果00872000h 写回原处。
对 EXE 文件来说,每个文件总是使用独立的虚拟地址空间,所以 EXE 总是能够按照这个地址 载人,这意味着EXE文件不再需要重定位信息。对 DLL来说,因为多个DLL文件使用宿主 EXE文 件的地址空间,不能保证载人地址没有被其他 DLL 使用,所以 DLL 文件中必须包含重定位信息, 除非用一个/FIXED开关来忽略它们。在Visual Studio.NET中,链接器会为 Debug和 Release 模式的 EXE 文件省略基址重定位,因此,在不同系统中跟踪同一个 DLL 文件时,其虚拟地址是不同的,也 就是说,在读者的机器里运行DIIDemo.DLL,Windows加载器映射的基址可能不是00870000h, 而是 其他地址。
2.2.2基址重定位表的结构
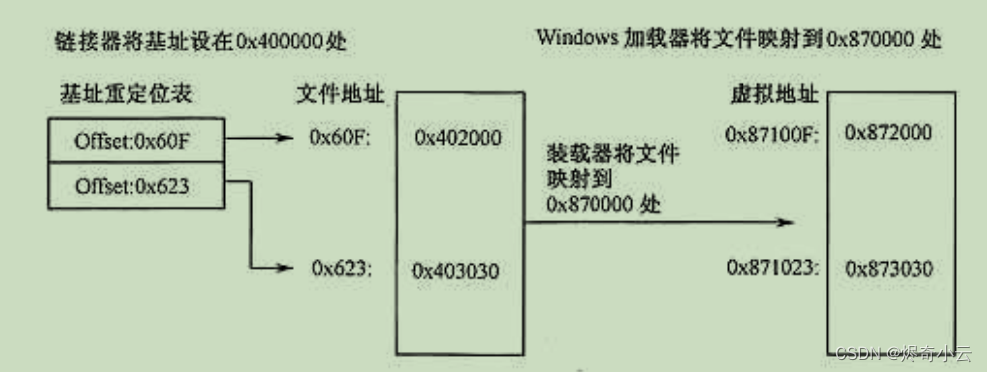
基址重定位表(Base Relocation Table)位于一个.reloc 区块内,找到它们的正确方式是通过数据 目录表的IMAGE_DIRECTORY_ENTRY_BASERELOC条目查找。基址重定位数据采用类似按页分割 的方法组织,是由许多重定位块串接成的,每个块中存放4KB(1000h) 的重定位信息,每个重定 位数据块的大小必须以DWORD(4 字节)对齐。它们以一个IMAGE_BASE_RELOCATION 结构开始, 格式如下。

● VirtualAddress: 这组重定位数据的开始 RVA 地址。各重定位项的地址加这个值才是该重定 位项的完整RVA地址。
● SizeOfBlock:当前重定位结构的大小。因为VirtualAddress 和 SizeOfBlock 的大小都是固定的
4字节,所以这个值减8就是TypeOffset 数组的大小。
● TypeOffset:一个数组。数组每项大小为2字节,共16位。这16位分为高4位和低12位。 高4位代表重定位类型;低12位是重定位地址,它与VirtualAddress 相加就是指向PE 映像 中需要修改的地址数据的指针。
常见的重定位类型如表11.14所示。虽然有多种重定位类型,但对x86 可执行文件来说,所有 的基址重定位类型都是IMAGE_REL_BASED_HIGHLOW。在一组重定位结束的地方会出现一个类型 是 IMAGE_REL_BASED_ABSOLUTE 的重定位,这些重定位什么都不做,只用于填充,以便下一个 IMAGE_BASE_RELOCATION按4字节分界线对齐。所有重定位块以一个VirtualAddress 字段为0的 IMAGE_BASE_RELOCATION 结构结束。
 重定位表的结构如图11.23所示,它由数个 IMAGE_BASE_RELOCATION 结构组成,每个结构 由 VirtualAddress 、SizeOFBlock 和 TypeOffset 3 部分组成。
重定位表的结构如图11.23所示,它由数个 IMAGE_BASE_RELOCATION 结构组成,每个结构 由 VirtualAddress 、SizeOFBlock 和 TypeOffset 3 部分组成。
对于IA-64 可执行文件,重定位类型似乎总是IMAGE_REL_BASED_DIR64。就像x86 重定位, 也用IMAGE_REL_BASED_ABSOLUTE重定位类型进行填充。有趣的是,尽管IA-64 的 EXE页大小 是 8KB, 但基址重定位仍是4KB 的块。
三:输入表(导入表)---IMAGE_IMPORT_DESCRIPTOR
可执行文件使用来自其他 DLL 的代码或数据的动作称为输入。当 PE 文件被载入时,Windows 加载器的工作之一就是定位所有被输人的函数和数据,并让正在载入的文件可以使用那些地址。这 个过程是通过PE 文件的输入表(Import Table,简称“TT”,也称导入表)完成的。输入表中保存的是 函数名和其驻留的DLL名等动态链接所需的信息。输入表在软件外壳技术中的地位非常重要,读者 在研究与外壳相关的技术时一定要彻底掌握这部分知识。
3.1.1 输入函数的调用
在代码分析或者编程中经常会遇到输入函数(Import Functions, 或称导入函数),
输入函数就是被 程序调用但其执行代码不在程序中的函数,这些函数的代码位于相关的 DLL 文件中,在调用者程序 中只保留相关的函数信息,例如函数名、DLL 文件名等。对磁盘上的 PE 文件来说,它无法得知这 些输人函数在内存中的地址。只有当PE 文件载入内存后,Windows 加载器才将相关DLL载人,并 将调用输入函数的指令和函数实际所处的地址联系起来。
当应用程序调用一个 DLL 的代码和数据时,它正在被隐式地链接到 DLL, 这个过程完全由 Windows加载器完成。另一种链接是运行期的显式链接,这意味着必须确定目标 DLL已经被加载, 然后寻找API 的地址,这几乎总是通过调用LoadLibrary和 GetProcAddress完成的。
当隐含地链接一个API时,类似LoadLibrary 和 GetProcAddress 的代码始终在执行,只不过这是 由 Windows 加载器自动完成的。Windows 加载器还保证了 PE文件所需的任何附加的DLL 都已载入。 例如, Windows 2000/XP上每个由Visual C++创建的正常程序都要链接 KERNEL32.DLL,而它又从 NTDLL.DLL 中输入函数。同样,如果链接了 CDI32.DLL, 它又依赖 USER32、ADVAPI32、NTDLL
和 KERNEL32等 DLL的函数,那么都要由Windows 加载器来保证载入并解决输入问题。
在 PE 文件内有一组数据结构,它们分别对应于被输人的 DLL。 每一个这样的结构都给出了被 输入的 DLL的名称并指向一组函数指针。这组函数指针称为输入地址表(Import Address Table,IAT)。 每一个被引人的API 在 IAT里都有保留的位置,在那里它将被 Windows加载器写人输入函数的地址。 最后一点特别重要: 一旦模块被载入, IAT中将包含所要调用输入函数的地址。
把所有输入函数放在IAT中的同一个地方是很有意义的。这样,无论在代码中调用一个输人函 数多少次,都会通过IAT中的同一个函数指针来完成。
现在看看怎样调用一个输人函数。需要考虑两种情况,即高效和低效。最好的情况是像下面这 样,直接调用00402010h处的函数,00402010h 位于IAT中。而实际上,对一个被输入的 API 的低效调用像下面这样(实例 PE.exe 中调用 LoadIconA 函数的 代码)。
Call 00401164
.
:00401164
Jmp dword ptr [00402010] ;指向USER32.LoadIconA 函数在这种情况下,CALL指令把控制权转交给一个子程序,子程序中的JMP 指令跳转到IAT中的 00402010h处。简单地说就是:使用5字节的额外代码;由于使用了额外的JMP 指令,将花费更多 的执行时间。
可能会问:为什么要采用此种低效的方法?对这个问题有一个很好的解释:编译器无法区 分输人函数调用和普通函数调用。对每个函数调用,编译器使用同样形式的CALL指令,示例如下
CALL XXXXXXXX
“XXXXXXXX” 是一个由链接器填充的实际地址。注意,这条指令不是从函数指针来的,而是 从代码中的实际地址来的。为了实现因果平衡,链接器必须产生一块代码来取代“XXXXXXXX”,
简单的方法就是像上面一样调用一个JMPstub。
JMP 指令来自为输入函数准备的输入库。如果读者检查过输入库,在输入函数名字的关联处就 会发现与上面的JMPstub 相似的指令,即在默认情况下,对被输入API的调用将使用低效的形式。
如何得到优化的形式?答案来自一个给编译器的提示形式。可以使用修饰函数的_declspec (dllimport)来告诉编译器,这个函数来自另一个 DLL, 这样编译器就会产生指令CALL DWORD PTR [XXXXXXXX]
而不是指令CALL XXXXXXXX
此外,编译器将给函数加上“_imp_ ”前缀,然后将函数送给链接器,这样就可以直接把_imp _xxx送到 IAT中,而不需要调用JMPstub 了。
如果要编写一个输出函数,并为它们提供一个头文件,不要忘了在函数的前面加上修饰符 “_declspec(dllimport)”, 在 winnt.h 等系统头文件中就是这样做的。
3.1.2输入表的结构
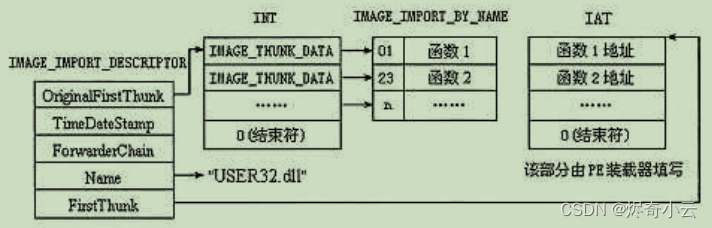
在 PE 文件头的可选映像头中,数据目录表的第2个成员指向输入表。输入表以一个 IMAGE IMPORT_DESCRIPTOR(ID) 数组开始。每个被 PE 文件隐式链接的 DLL都有一个 IID。在这个数 组中,没有字段指出该结构数组的项数,但它的最后一个单元是 “NULL”, 由此可以计算出该数组 的项数。例如,某个 PE 文件从两个 DLL文件中引人函数,因此存在两个ID 结构来描述这些 DLL文件,并在两个 IID结构的最后由一个内容全为0的ID 结构作为结束。ID 的结构如下。
typedef struct _IMAGE_IMPORT_DESCRIPTOR {union {DWORD Characteristics;DWORD OriginalFirstThunk; //导入名称表(INT)的RVA地址} DUMMYUNIONNAME;DWORD TimeDateStamp; //时间戳多数情况可忽略 如果是0xFFFFFFFF表示IAT表被绑定为函数地址DWORD ForwarderChain;DWORD Name; //导入DLL文件名的RVA地址DWORD FirstThunk; //导入地址表(IAT)的RVA地址
} IMAGE_IMPORT_DESCRIPTOR;
typedef IMAGE_IMPORT_DESCRIPTOR UNALIGNED *PIMAGE_IMPORT_DESCRIPTOR;● OriginalFirstThunk(Characteristics): 包含指向输入名称表(INT) 的 RVA 。INT是 一 个 IMAGE_ THUNK_DATA 结构的数组,数组中的每个 IMAGE_THUNK_DATA 结构都指向 IMAGE_ IMPORT_BY_NAME结构,数组以一个内容为0的IMAGE_THUNK_DATA结构结束。
● TimeDateStamp: 一个32位的时间标志,可以忽略。
● ForwarderChain:这是第1个被转向的API的索引, 一般为0,在程序引用一个DLL中的API, 而这个API又在引用其他 DLL的 API时使用(但这样的情况很少出现)。
● Name:DLL名字的指针。它是一个以“00”结尾的 ASCI字符的RVA 地址,该字符串包含 输入的DLL名,例如 “KERNEL32.DLL”“USER32.DLL”。
● FirstThunk; 包含指向输入地址表 (IAT) 的 RVA。IAT是一个IMAGE_THUNK_DATA 结构
的数组。
OriginalFirstThunk 与 FirstThunk 相似,它们分别指向两个本质上相同的数组 IMAGE_THUNK_
DATA结构。这些数组有好几种叫法,最常见的是输人名称表(Import Name Table,INT) 和输入地 址 表(Import Address Table,IAT)。如图11.13所示为一个可执行文件正在从 USER32.DLL 里输入一些 API。
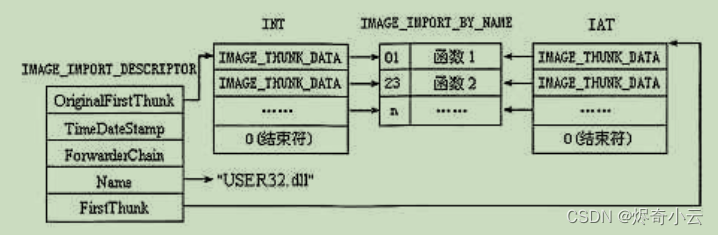
两个数组中都有IMAGE_THUNK_DATA 结构类型的元素,它是一个指针大小的联合 (union)。
每个IMAGE_THUNK_DATA元素对应于一个从可执行文件输入的函数。两个数组的结束都是由一个 值 为 0 的IMAGE_THUNK_DATA 元素表示的。IMACE_THUNK_DATA 结构实际上是一个双字,该结 构在不同时刻有不同的含义,具体如下。

当IMAGE_THUNK_DATA 值的最高位为1时,表示函数以序号方式输入,这时低31位(或者
一个64位可执行文件的低63位)被看成一个函数序号。当双字的最高位为0时,表示函数以字符 串类型的函数名方式输入,这时双字的值是一个RVA, 指向一个IMAGE_IMPORT_BY_NAME 结构。 IMAGE_IMPORT_BY_NAME结构仅有1个字大小,存储了一个输人函数的相关信息,结构如下。

● Hint: 本函数在其所驻留 DLL的输出表中的序号。该域被PE 装载器用来在DLL的输出表里 快速查询函数。该值不是必需的, 一些链接器将它设为0。
● Name: 含有输人函数的函数名。函数名是一个ASCⅡ字符串,以“NULL” 结尾。注意,这 里虽然将 Name的大小以字节为单位进行定义,但其实它是一个可变尺寸域,由于没有更好 的表示方法,只好在上面的定义中写成 “BYTE”。
3.1.3 输入表地址表
为什么会有两个并行的指针数组指向 IMAGE_IMPORT_BY_NAME 结构呢?第1 个数组(由 OriginalFirsfThunk 所指向)是单独的一项,不可改写,称为INT, 有时也称为提示名表(Hint-name Table)。第2个数组(由FirstThunk所指向)是由PE装载器重写的。PE 装载器先搜索 OriginalFirst Thunk, 如果找到,加载程序就迭代搜索数组中的每个指针,找出每个 IMAGE_IMPORT_BY_NAME
结构所指向的输入函数的地址。然后,加载器用函数真正的入口地址来替代由 FirstThunk 指向的 IMAGE_THUNK_DATA 数组里元素的值。“Jmp dword ptr [xxxxxxxx]” 语句中的“[xxxxxxxx]” 是指 FirstThunk 数组中的一个入口,因此称为输入地址表(Import Address Table,IAT)。所以,当PE 文件 装载内存后准备执行时,图11.13已转换成如图11.14所示的状态,所有函数入口地址排列在一起。 此时,输人表中的其他部分就不重要了,程序依靠IAT提供的函数地址就可以正常运行。
在某些情况下, 一些函数仅由序号引出。也就是说,不能用函数名来调用它们,只能用它们的 位置来调用它们。此时,IMACE_THUNK_DATA值的低位字指示函数序数,最高有效位 (MSB) 设 为1。微软提供了一个方便的常量 IMAGE_ORDINAL_FLAG32 来测试 DWORD 值的 MSB, 其值为 80000000h( 在PE32+ 中是IMAGE_ORDINAL_FLAG64, 其值为8000000000000000h)。
另一种情况是程序 OrignalFirstThunk 的值为0。在初始化时,系统根据 FirstThunk 的值找到指向 函数名的地址串,根据地址串找到函数名,再根据函数名得到人口地址,然后用入口地址取代 FirstThunk 指向的地址串中的原值。
ok,朋友们,到此为止,PE结构圆满结束,如果觉得此篇文章太过繁琐,请移步之前发布的简洁版观看,如果有不懂的可以私信交流。


![[leetcode] 29. 两数相除](https://img-blog.csdnimg.cn/direct/a36c1b59f2eb48eebd27dc7ba26116ca.png)