1、函数执行空间标识符
- 用__global__修饰的函数称为核函数,般由主机调用,在设备中执行。如果使用动态并行,则也可以在核函数中调用自己或其他核函数。
- 用__device__修饰的函数称为设备函数,只能被核函数或其他设备函数调用,在设备中执行。
- 用__host__修饰的函数就是主机端的普通C++函数,在主机中被调用,在主机中执行。对于主机端的函数,该修饰符可省略。之所以提供这样一个修饰符,是因为有时可以用__host__和__device__同时修饰—个函数,使得该函数既是一个C++中的普通函数,又是—个设备函数。这样做可以减少冗余代码。编译器将针对主机和设备分别编译该函数。
- 不能同时用__device__和__global__修饰—个函数,即不能将—个函数同时定义为设备函数和核函数。
- 也不能同时用__host__和__global__修饰一个函数,即不能将—个函数同时定义为主机函数和核函数。
- 编译器决定把设备函数当作内联函数(inline function)或非内联函数,但可以用修饰符__noinline__建议—个设备函数为非内联函数(编译器不一定接受),也可以用修饰符__forceinline__建议一个设备函数为内联函数。
2、网格与线程块大小的限制
CUDA 中对能够定义的网格大小和线程块大小做了限制。对任何从开普勒到安培架构 的 GPU 来说
网格大小(gridDim):
- x:
- y:65535
- z:65535
线程块大小(blockDim):
- x:1024
- y:1024
- z:64
另外,还要求线程块总的大小,即 blockDim.x、blockDim.y 和 blockDim.z 的乘积不能大于1024。也就是说,不管如何定义,一个线程块最多只能有1024个线程。这些限制是必须牢记的。如果超过1024个线程核函数是不起作用的。
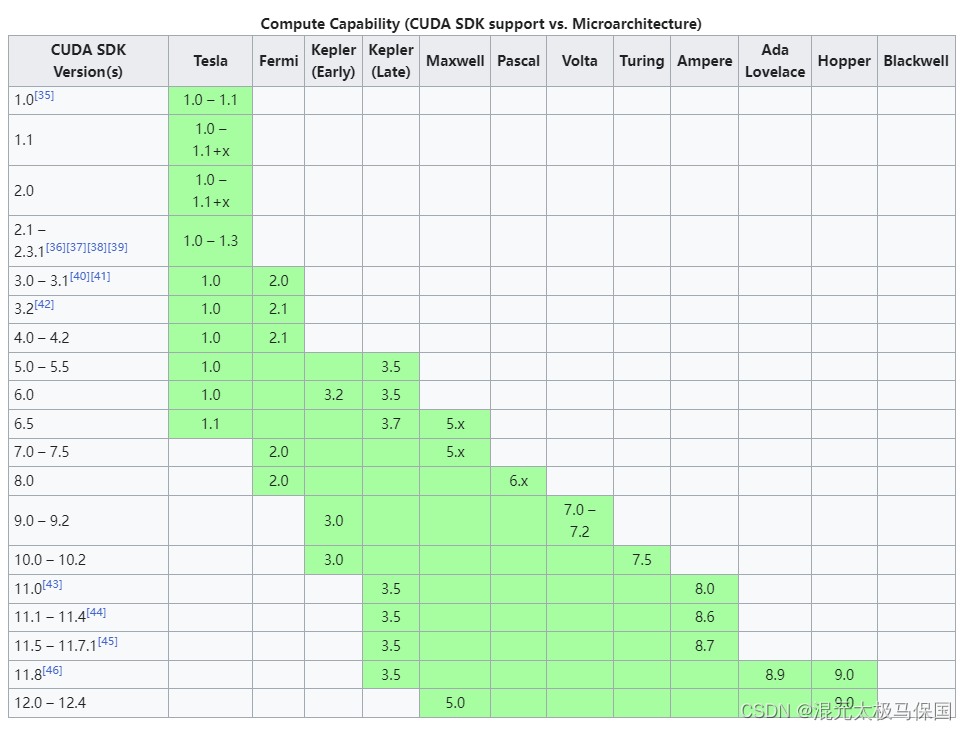
3、编译
在将源代码编译为PTX代码时,需要用选项-arch=compute_XY指定—个虚拟架构的计算能力,用以确定代码中能够使用的CUDA功能。在将PTX代码编译为cubin代码时,需要用选项-code=sm_ZW指定一个真实架构的计算能力,用以确定可执行文件能够使用的GPU。真实架构的计算能力必须等于或者大于虚拟架构的计算能力。
例如:
用选项
-gencode arch=compute_35,code=sm35
-gencode arch=compute_50,code=sm50
-gencode arch=compute_60,code=sm60
-gencode arch=compute_70,code=sm70
编译出来的可执行文件将包含4个二进制版本,分别对应开普勒架构(不包含比较老的3.0和3.2的计算能力)、麦克斯韦架构、帕斯卡架构和伏特架构。这样的可执行文件称为胖二进制文件(fatbinary)。在不同架构的GPU中运行时会自动选择对应的二进制版本。需要注意的是,上述编译选项假定所使用的CUDA版本支持7.0的计算能力,也就是说,至少是CUDA9.0。如果在编译选项中指定了不被支持的计算能力,编译器会报错。另外,需要注意的是,过多地指定计算能力,会增加编译时间和可执行文件的大小。
nvcc有一种称为即时编译(just-in_time compilation)的机制,可以在运行可执行文件时从其中保留的PTX代码临时编译出一个cubin目标代码。要在可执行 文件中保留(或者说嵌入)一个这样的PTX代码。就必须用如下方式指定所保留PTX代码的虚拟架构:
-gencode arch=compute_XY,code=compute_XY
这里的两个计算能力都是虚拟架构的计算能力,必须完全一致。
例如,假如我们处于只 有 CUDA 8.0 的年代(不支持伏特架构),但希望编译出的二进制版本适用于尽可能多 的 GPU,则可以用如下的编译选项:
-gencode arch=compute_35,code=sm_35
-gencode arch=compute_50,code=sm_50
-gencode arch=compute_60,code=sm_60
-gencode arch=compute_60,code=compute_60
其中,前三行的选项分别对应 3 个真实架构的 cubin 目标代码,第四行的选项对应保留 的 PTX 代码。这样编译出来的可执行文件可以直接在伏特架构的 GPU 中运行,只不过 不一定能充分利用伏特架构的硬件功能。在伏特架构的 GPU 中运行时,会根据虚拟架构 为 6.0 的 PTX 代码即时地编译出一个适用于当前 GPU 的目标代码。
在学习 CUDA 编程时,有一个简化的编译选项可以使用:
-arch=sm_XY
它等价于
-gencode arch=compute_XY,code=sm_XY
-gencode arch=compute_XY,code=compute_X