欢迎关注公众号(通过文章导读关注:【11来了】),及时收到 AI 前沿项目工具及新技术的推送!
在我后台回复 「资料」 可领取
编程高频电子书!
在我后台回复「面试」可领取硬核面试笔记!文章导读地址:点击查看文章导读!
感谢你的关注!

BufferPool 生产优化经验
高并发场景下如何访问 BufferPool
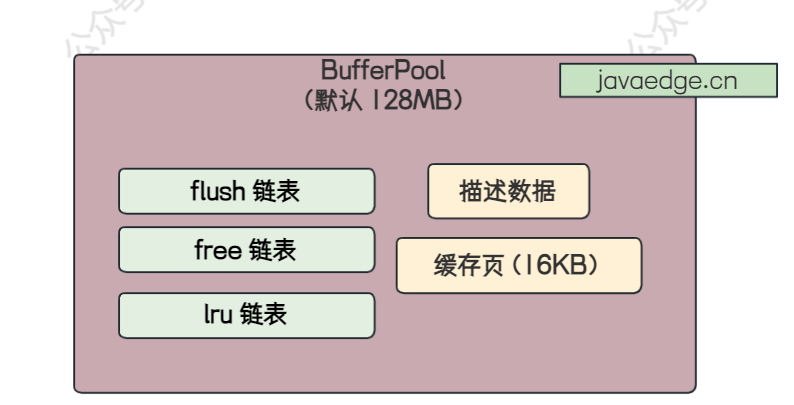
如果在高并发场景下,大量线程需要操作 MySQL,也就是大量线程对 BufferPool 进行并发操作,在 BufferPool 中对这些共享变量(flush、free、lru 链表)操作,是需要通过 加锁来保证线程同步的,虽然是在内存中对 BufferPool 进行操作,但是将多个线程并发操作给转为了串行操作,还是有些降低性能的!
通过多个 BufferPool 优化高并发性能
上边在高并发场景中,只有一个 BufferPool 的话,可能多个线程在这一个 BufferPool 中排队对共享变量进行操作比较慢,在生产环境中,可以给 MySQL 设置多个 BufferPool 来提升性能!
如果部署 MySQL 的机器配置比较好,内存比较大,可以多给 BufferPool 分配一些内存,并且设置多个 BufferPool,通过一下两个参数设置:
innodb_buffer_pool_size # BufferPool 大小
innodb_buffer_pool_instances # BufferPool 个数
比如,可以给 BufferPool 分配 8G 内存,设置 4 个 BufferPool,那么每个的内存大小为 2G
这样原来只有 1 个 BufferPool 的情况下,多个线程并发操作在这一个 BufferPool 中进行排队
现在有 4 个 BufferPool 了,多个线程可以同时在这 4 个 BufferPool 中排队进行操作,性能成倍提升
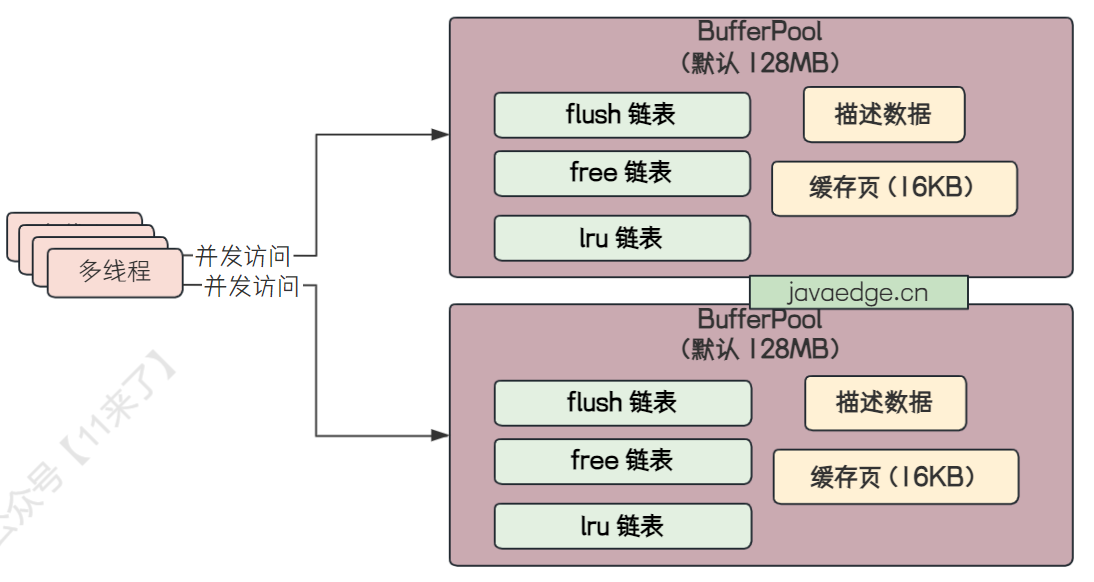
因此在生产环境中,在机器配置足够的情况下,可以通过增加 BufferPool 的数量来提升 MySQL 的性能!
BufferPool 的大小可以动态变化吗?
其实是可以的,MySQL 通过 chunk 机制 来实现 BufferPool 大小动态调整的功能
chunk 其实就是 BufferPool 中的子单元,一个 BufferPool 由许多的 chunk 组成,每个 chunk 中包含了一系列的描述数据块和缓存页
chunk 的大小由:innodb_buffer_pool_chunk_size 来控制,默认大小为 128MB
那么假设现在有一个 BufferPool 大小为 2GB,那么这个 BufferPool 就是由 16 个 chunk 组成,一个 chunk 128MB
BufferPool 与 chunk 关系如下图:
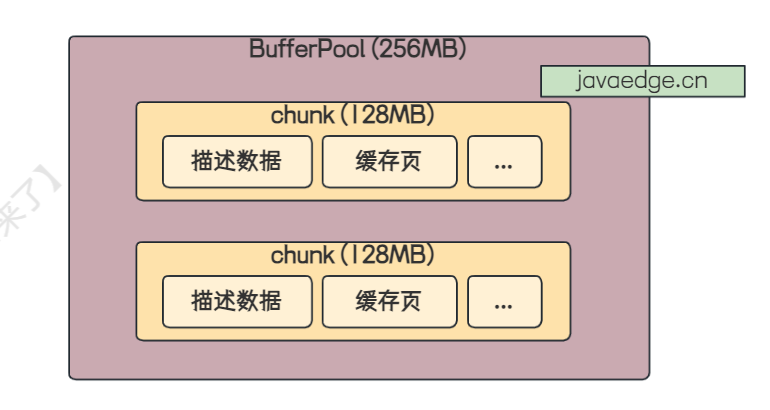
当在 MySQL 运行期间,如果需要增大 BufferPool 的内存大小,那么只需要申请对应的 chunk 块,再将申请到的 chunk 分配给 BufferPool 就可以了
通过 chunk 机制可以极大提升 BufferPool 的灵活性
BufferPool 生产环境参数配置
我们知道在 MySQL 中,是将磁盘文件中的数据读取到内存的 BufferPool 中,在 BufferPool 中对数据进行操作的,那么从理论上来讲,如果部署 MySQL 的机器内存有 32 G,那么给 BufferPool 分配 30G 的大小会不会更好呢?
其实这样是行不通的,因为机器在启动的时候,操作系统就要占用几个 G 的内存,并且机器上运行的其他应用也是需要占用内存的
因此,一般建议将 BufferPool 的大小设置为机器内存的 60%!
BufferPool 数量的确定:
在确定 BufferPool 的大小之后,接下来可以确定 BufferPool 的数量了
通过计算公式确定:
BufferPool 总大小 = (chunk 大小 * Bufferpool 数量) * 2
那么假设部署 MySQL 的机器内存为 32 GB,那么 BufferPool 的大小应该设置为 32GB * 60% ≈ 20GB,chunk 大小为 128MB,代入上边公式,得到 BufferPool 数量为 (BufferPool 总大小 / 2) / chunk 大小,也就是 20GB/2/128MB = 16 个
因此 BufferPool 的数量就设置为 16 个
根据上边的经验值对 BufferPool 的总大小以及数量进行配置,可以尽可能的保证数据库的高性能
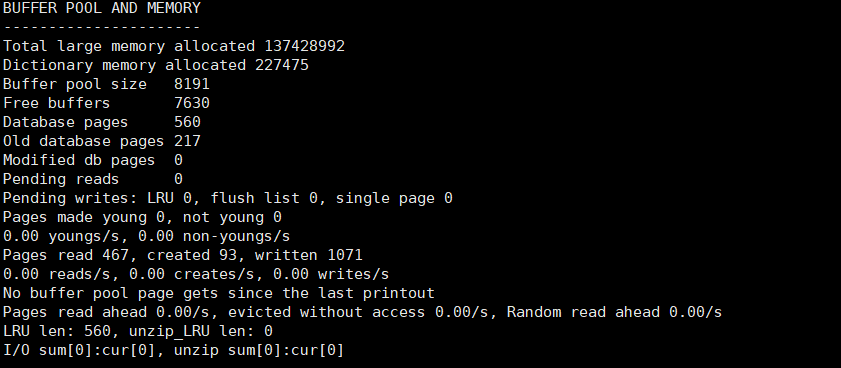
当配置过后,可以通过命令:show engine innodb status; 来查看配置是否生效!