文章目录
- 矩阵补充Matrix Completion
- 模型结构
- 模型训练
- 模型存储
矩阵补充Matrix Completion
模型结构
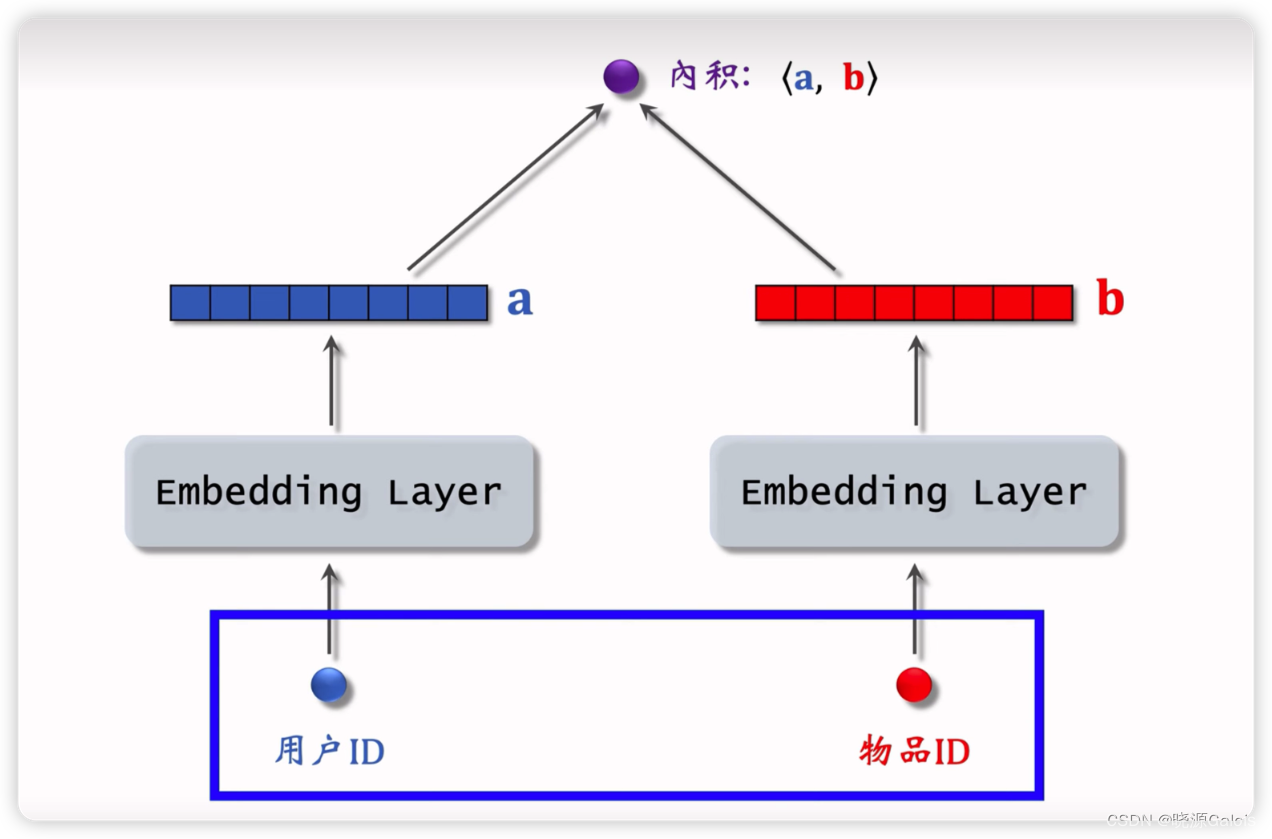
通过用户ID和物品ID分别找到对应的向量,然后去做内积,内积的数值可以去衡量匹配的程度。
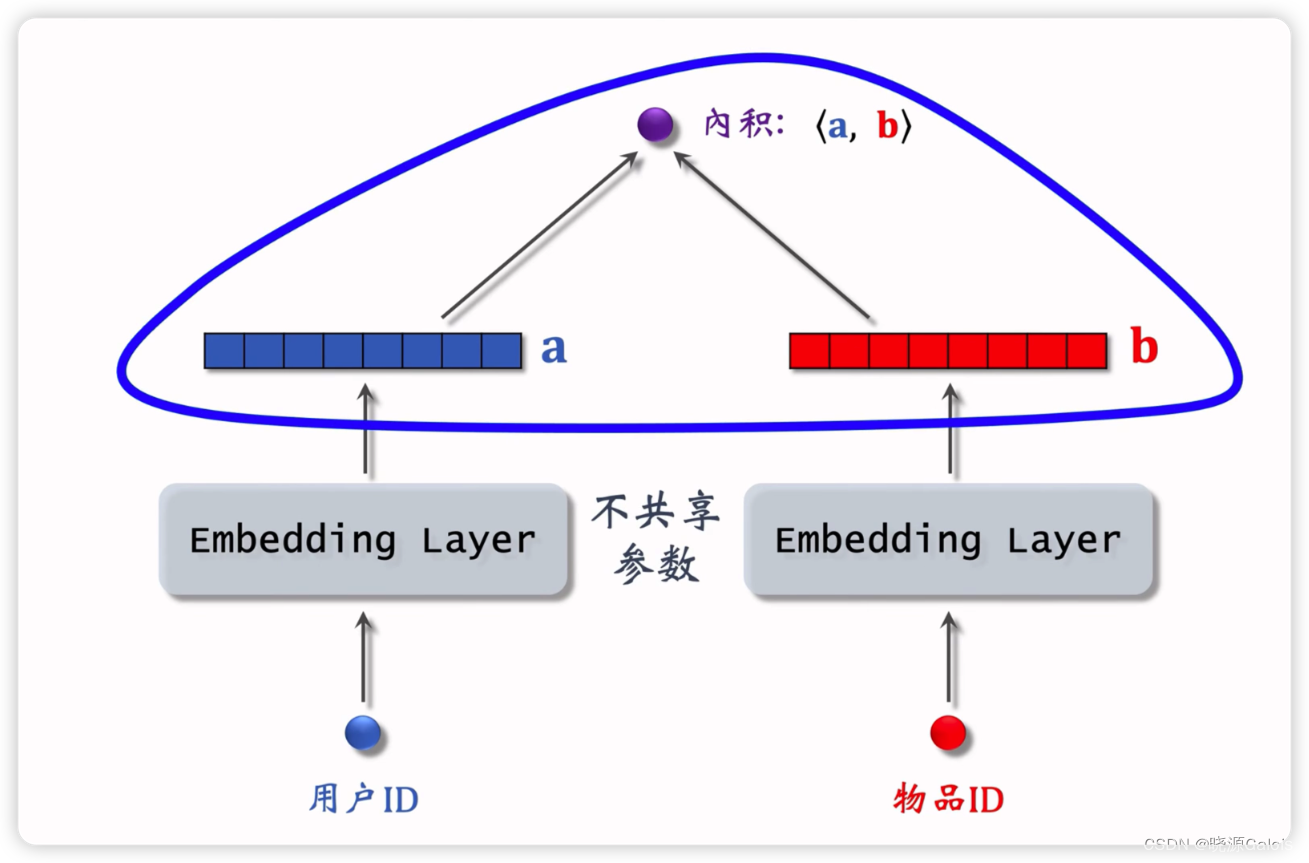
不共享参数的意思是指用户ID和物品ID使用不同的Embedding Layer。
以上的模型叫做矩阵补充模型。
模型训练

抽出用户和物品,将他们进行计算,作为预测值,并将其与y作差再平方来作为误差。
而目的是去优化A和B,使得这个误差和变得最小。
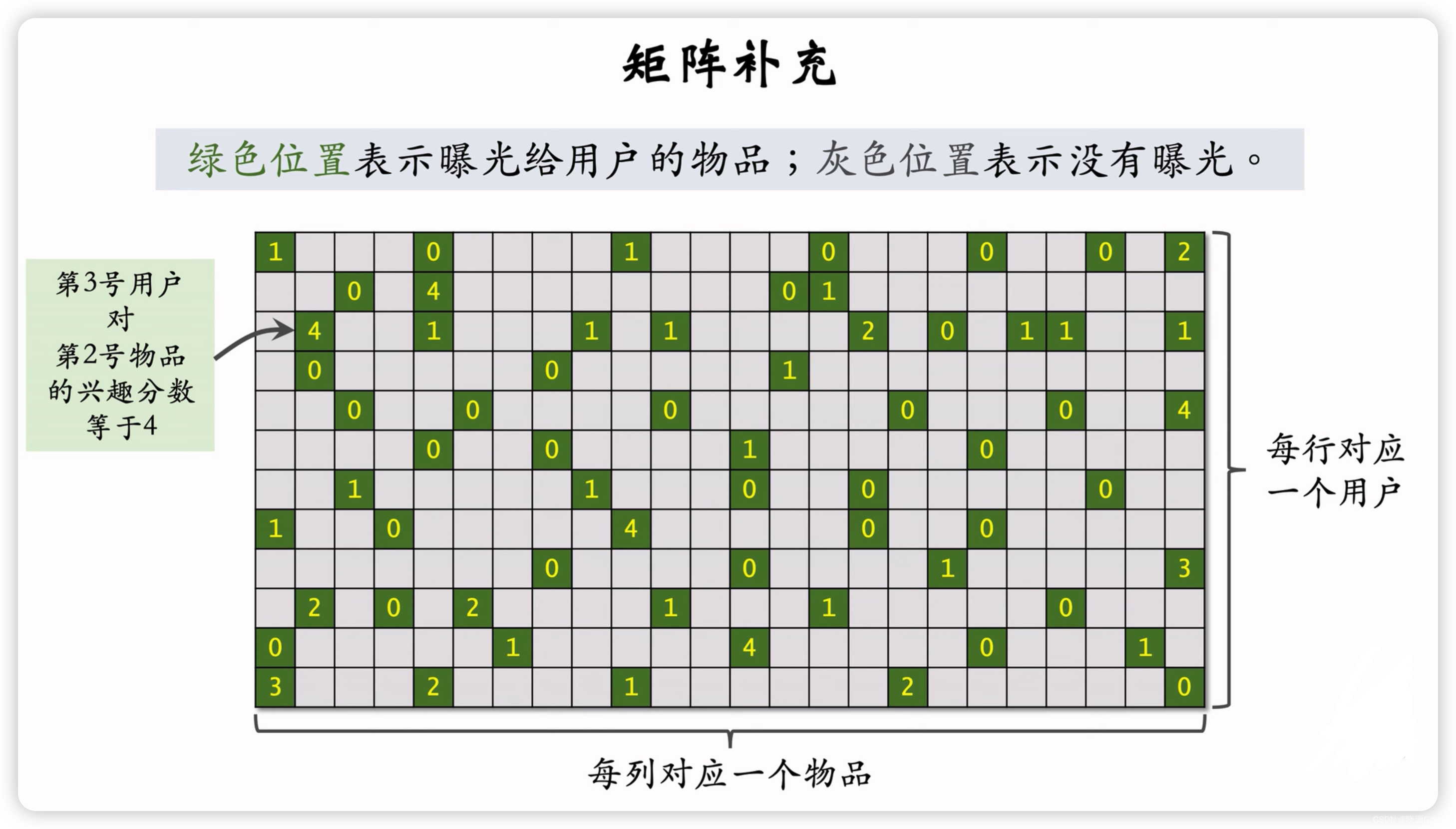
第i行第j列表示i个用户对第j个作品的评分。
若为灰色,则说明该用户尚未对该作品进行评分,这也是矩阵补充要补充的元素。



模型存储

B矩阵不能直接使用key-value进行存储。

如果数据库内存放过多的物品,所对应的内积计算次数将会很多,随之而来还有排序带来的时间消耗。


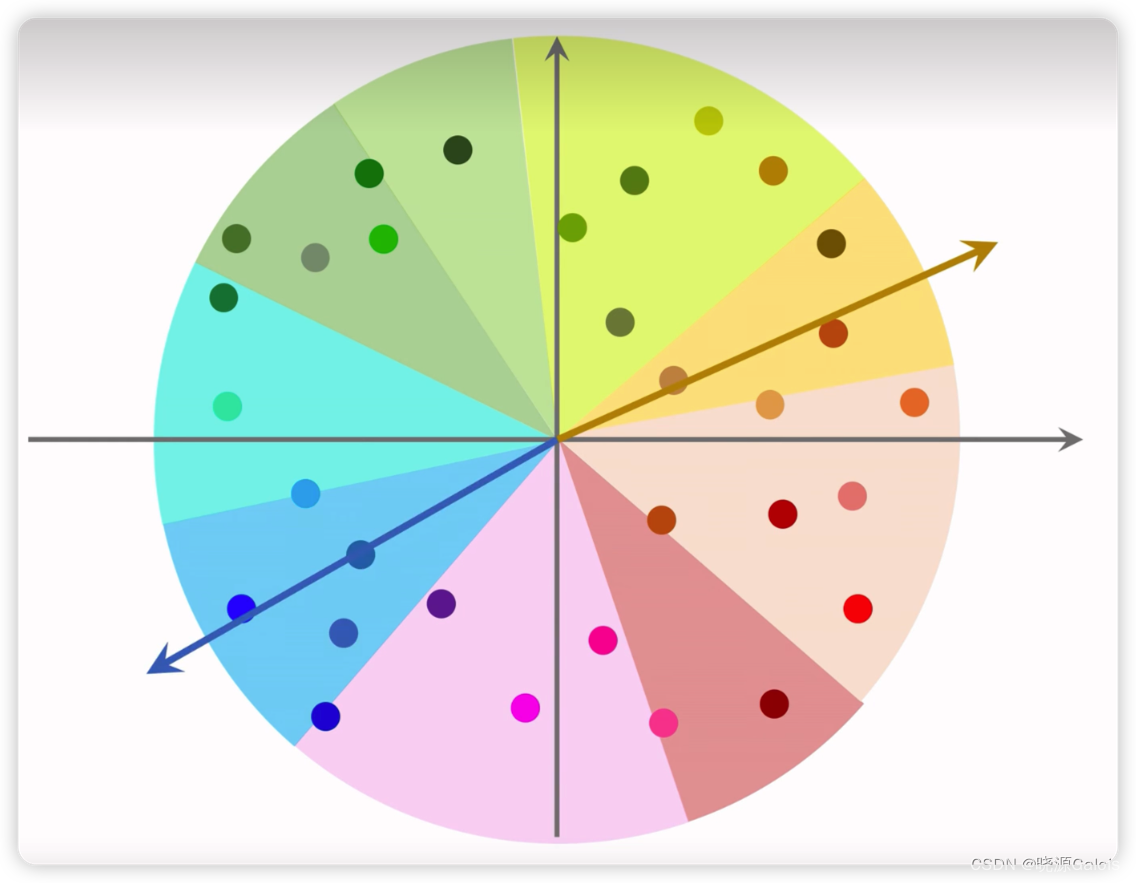
以上采用的是余弦相似度,即点的角度相似的,类型相似。
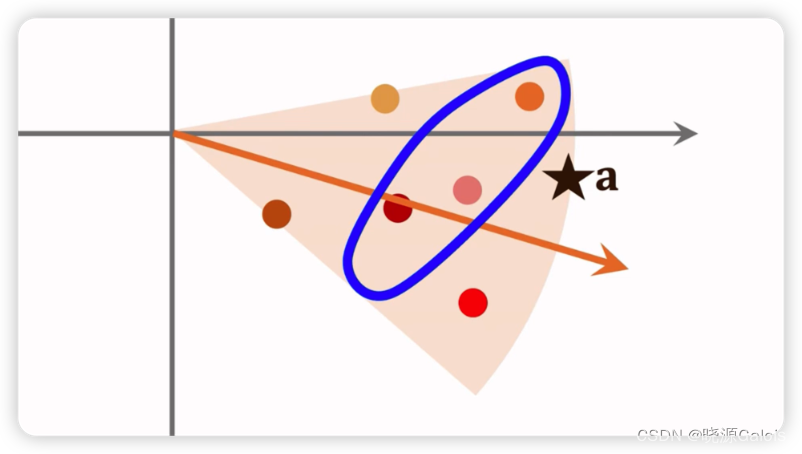
求最近邻只需要从分片中进行查找,无需在全局中进行计算。