【深度学习:语义分割】语义分割简介
- 什么是图像分割?
- 了解语义分割
- 数据采集
- 语义分割的深度学习实现
- 全卷积网络
- 上采样
- 跳跃连接
- U-Net
- DeepLab
- 多尺度物体检测
- 金字塔场景解析网络(PSPNet)
- 语义分割的应用
- 医学影像
- 自动驾驶汽车
- 农业
- 图片处理
- 语义分割的缺点
- 使用 Encord 加速细分
- 语义分割:关键要点
计算机视觉算法旨在从图像和视频中提取重要信息。其中一项任务是语义分割,它提供有关图像中各种实体的粒度信息。在继续之前,我们先简要介绍一下图像分割的总体情况。
什么是图像分割?
图像分割模型使机器能够理解图像中的视觉信息。这些模型经过训练,可以生成分割掩模,用于识别和定位图像中存在的不同实体。这些模型的工作原理与对象检测模型类似,但图像分割在像素级别上识别对象,而不是绘制边界框。
图像分割任务分为三个子类别
- Instance Segmentation 实例分割
- Semantic Segmentation 语义分割
- Panoptic Segmentation 全景分割

语义分割将所有相关像素分类到单个簇,而不考虑独立实体。实例分割识别“离散”项目,例如汽车和人,但不提供连续项目(例如天空或长草地)的信息。全景分割结合了这两种算法来呈现离散对象和背景实体的统一图片。
本文将详细解释语义分割并探讨其各种实现和用例。
了解语义分割
语义分割模型借鉴了图像分类模型的概念并对其进行了改进。分割模型不是标记整个图像,而是将每个像素标记为预定义的类别。与同一类关联的所有像素被分组在一起以创建分割掩模。这些模型在粒度级别上工作,可以准确地对对象进行分类并绘制精确的边界以进行定位。
语义模型获取输入图像并将其传递给复杂的神经网络架构。输出是图像的彩色特征图,每个像素颜色代表各种对象的不同类标签。这些空间特征使计算机能够区分项目,将焦点对象与背景分开,并允许机器人自动执行任务。
数据采集
分割问题的数据集由表示不同对象的掩模的像素值及其相应的类标签组成。与其他机器学习问题相比,分割数据集通常更加广泛和复杂。
它们由数十个不同的类和每个类的数千个注释组成。许多标签提高了数据集中的多样性,并帮助模型更好地学习。拥有多样化的数据对于分割模型很重要,因为它们对对象形状、颜色和方向敏感。
流行的分割数据集包括:
- Pascal 视觉对象类 (VOC):该数据集在 2012 年之前一直被用作 Pascal VOC 挑战赛的基准。它包含的注释包括对象类、用于检测的边界框和分割图。数据的最后一次迭代 Pascal VOC 2012 总共包含 11,540 张图像,并带有 20 个不同对象类别的注释。
- MS COCO:COCO 是一个流行的计算机视觉数据集,包含超过 330,000 张图像,以及各种任务的注释,包括对象检测、语义分割和图像字幕。基本事实包含 80 个对象类别和每张图像最多 5 个书面描述。
- Cityscapes:Cityscapes 数据集专门用于分割城市场景。它包含 5,000 个精细分割的真实世界图像和 20,000 个具有粗糙多边形边界的粗略注释。该数据集包含在不同条件下捕获的 30 个类别标签,例如几个月内的不同天气条件。
此外,训练有素的分割模型需要复杂的架构。让我们看看这些模型在幕后是如何工作的。
语义分割的深度学习实现
大多数现代、最先进的架构都由用于图像处理的卷积神经网络 (CNN) 块组成。这些神经网络架构可以从空间特征中提取重要信息,以对对象进行分类和分割。下面提到了一些流行的网络。
全卷积网络
2014 年推出了全卷积网络 (FCN),并在语义图像分割方面展示了突破性的结果。它本质上是用于分类任务的传统 CNN 架构的修改版本。传统的架构由卷积层和密集(扁平)层组成,这些层输出单个标签来对图像进行分类。
FCN 架构从用于信息提取的常用 CNN 模块开始。网络的前半部分由众所周知的架构组成,例如VGG或RESNET。然而,后半部分用 1x1 卷积块替换了密集层。附加的卷积块继续提取图像特征,同时保留位置信息。
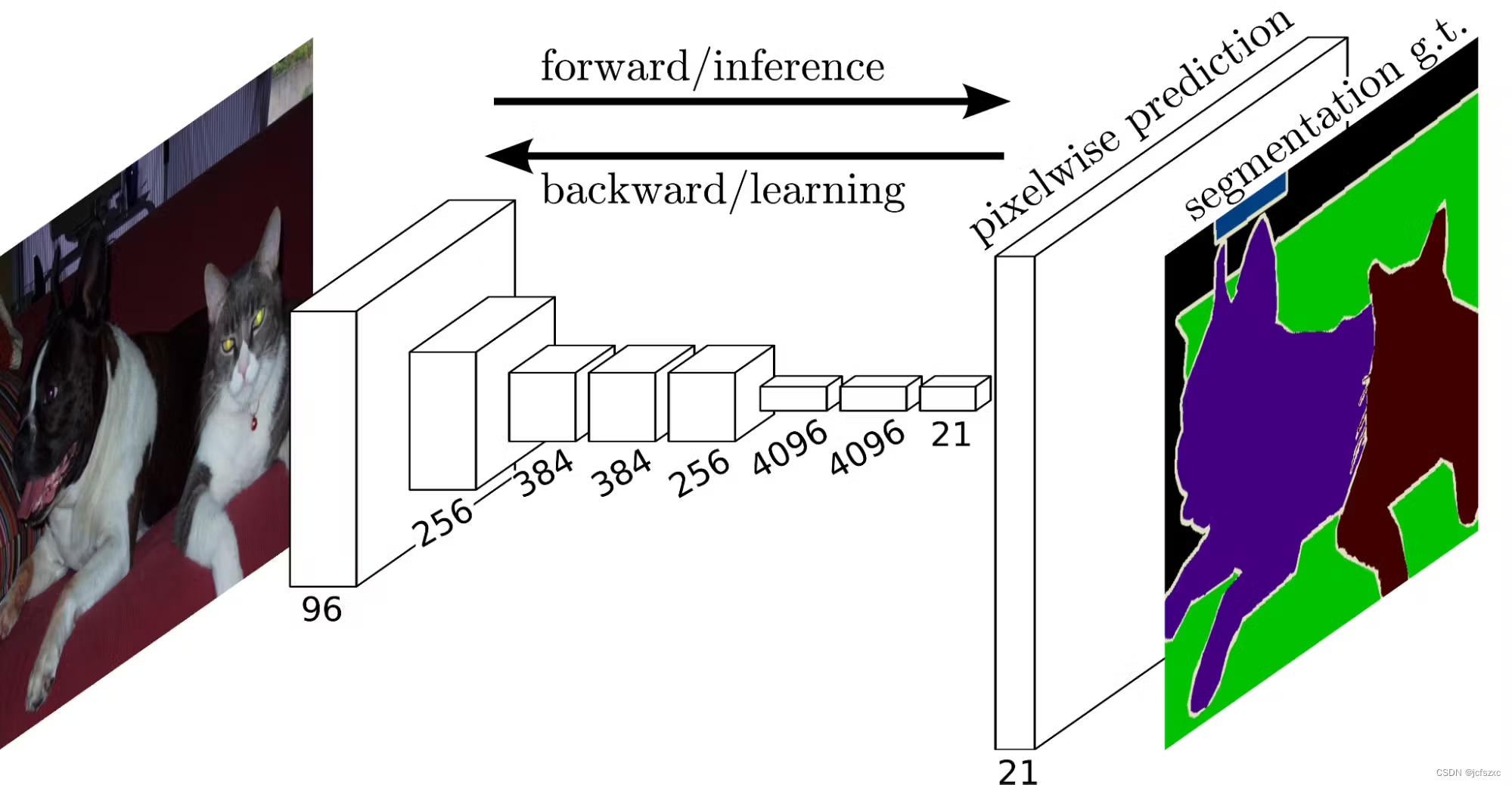
上采样
随着卷积层网络越来越深,原始图像会减少,从而导致空间信息丢失。网络越深入,我们留下的像素级信息就越少。
作者在最后实现了一个反卷积层来解决这个问题。反卷积层将特征图上采样为原始图像的形状。生成的图像是表示输入图像中各个段的特征图。
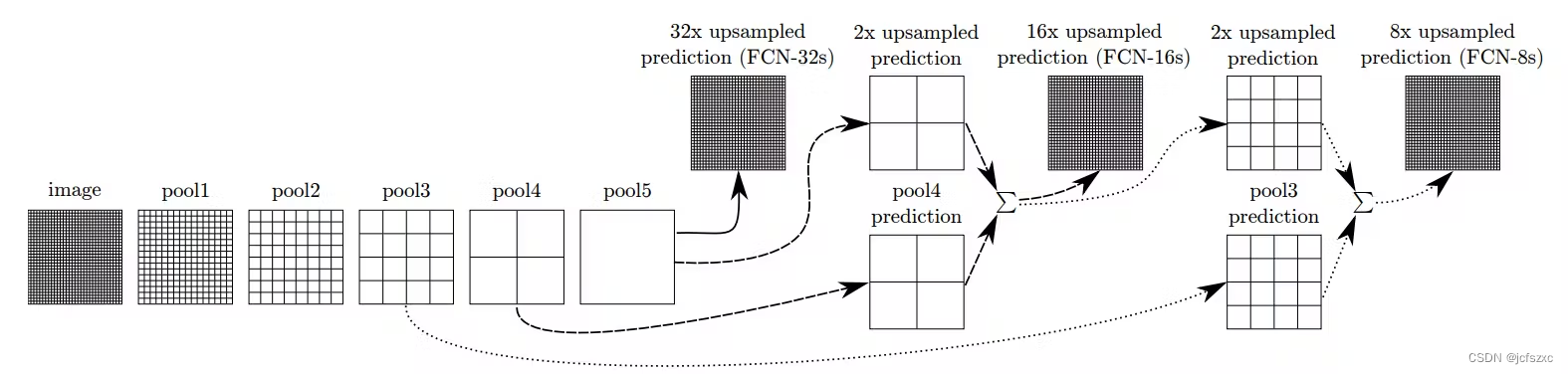
跳跃连接
该架构仍然面临一个重大缺陷。最后一层必须上采样 32 倍,导致最终层输出分割不良。通过使用跳跃连接将先前的最大池化层连接到最终输出,可以解决低分辨率问题。
每个池化层输出都经过独立的上采样,以与传递到最后一层的先前要素相结合。这样,反卷积操作是分步进行的,最终输出只需要 8 倍采样即可更好地表示图像。
U-Net
与 FCN 类似,U-Net 架构基于编码器-解码器模型。它借鉴了 FCN 中的跳跃连接等概念,并对其进行了改进以获得更好的结果。
这种流行的架构于 2015 年推出,作为医学图像分割任务的专用模型。它赢得了 2015 年 ISBI 细胞跟踪挑战赛,以更少的训练图像和更好的整体性能击败了滑动窗口技术。
U-Net架构由两部分组成;编码器(前半部分)和解码器(后半部分)。前者由堆叠的卷积层组成,对输入图像进行下采样,提取重要信息,而后者则使用反卷积重建特征。
这两层有两个不同的用途。编码器提取有关图像中实体的信息,解码器定位多个实体。该架构还包括在相应的编码器-解码器块之间传递信息的跳跃连接。
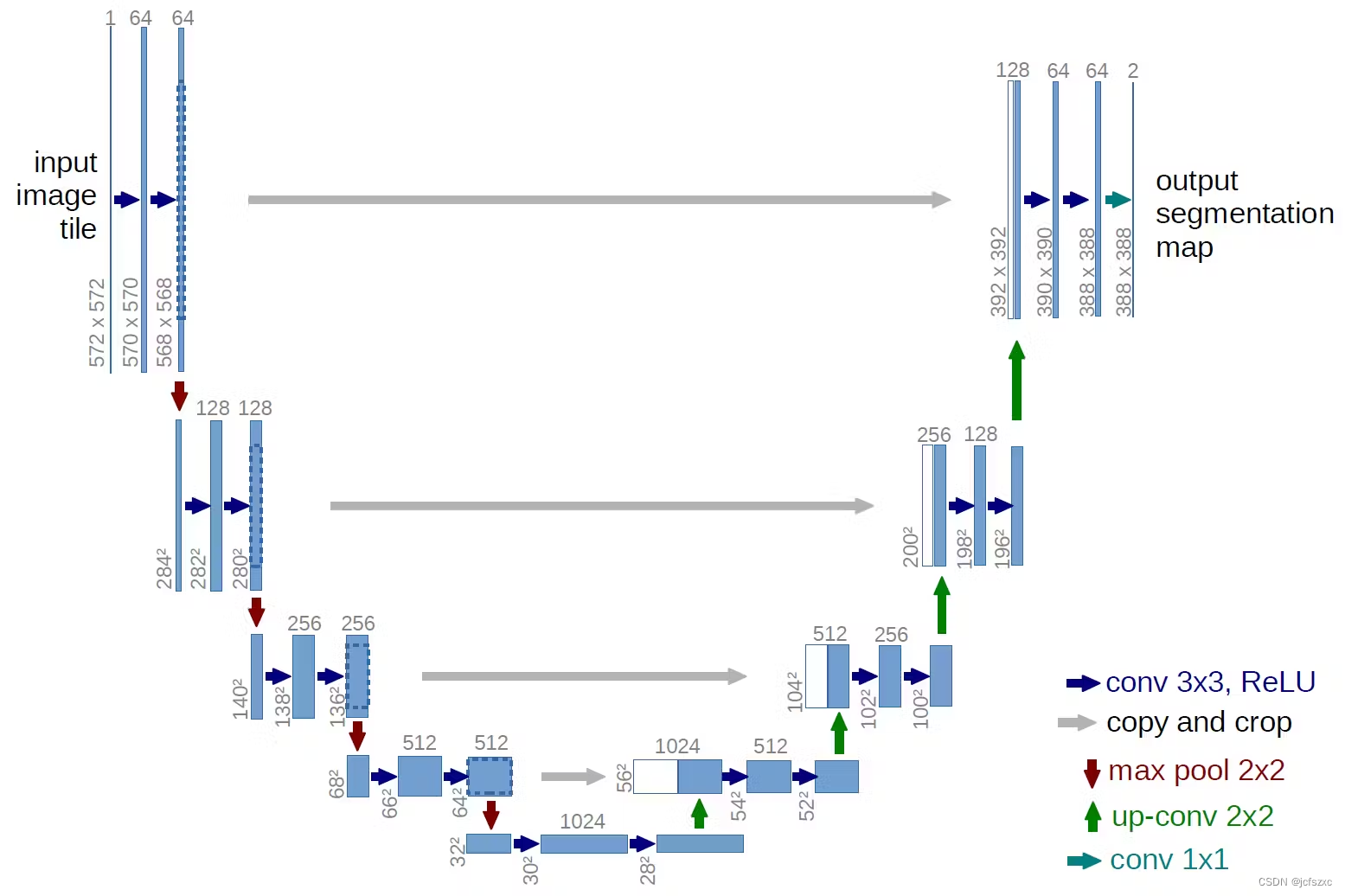
此外,U-Net架构在过去几年中进行了各种大修。许多 U-Net 变体改进了原始架构,以提高系统效率和性能。一些改进包括使用流行的 CNN 模型(如 VGG)作为下降层或后处理技术来改进结果。
DeepLab
DeepLab 是一组受原始 FCN 架构启发的分割模型,但通过变体来解决其缺点。
FCN 模型具有堆叠的 CNN 层,可显著降低图像尺寸。使用反卷积运算重构特征空间,但由于信息不足,结果不精确。
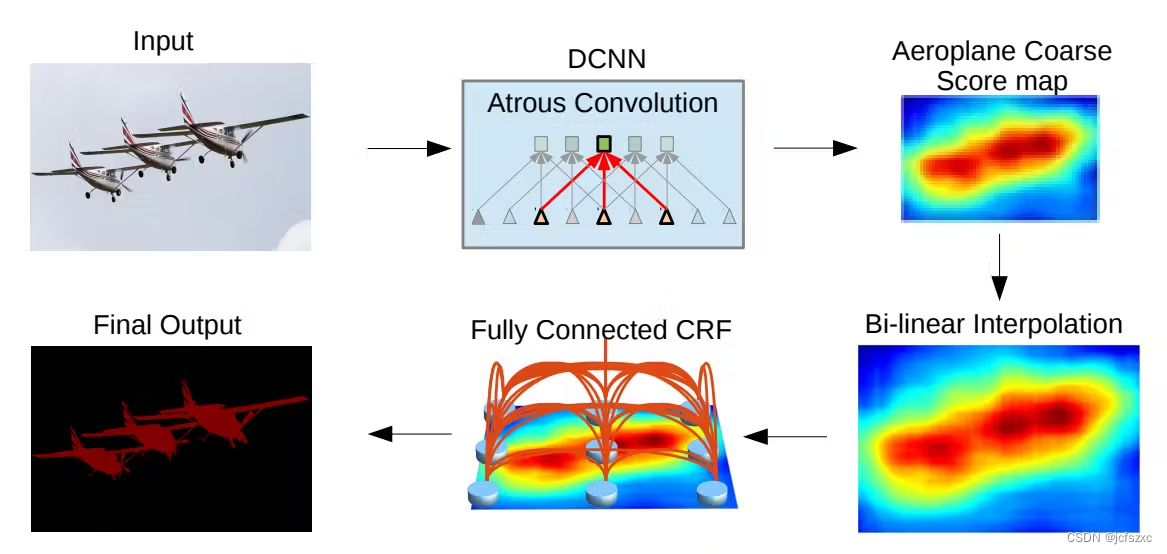
DeepLab 利用 Atrous 卷积来解决特征解析问题。Atrous 卷积内核通过在后续内核参数之间留出间隙,从图像中提取更广泛的信息。
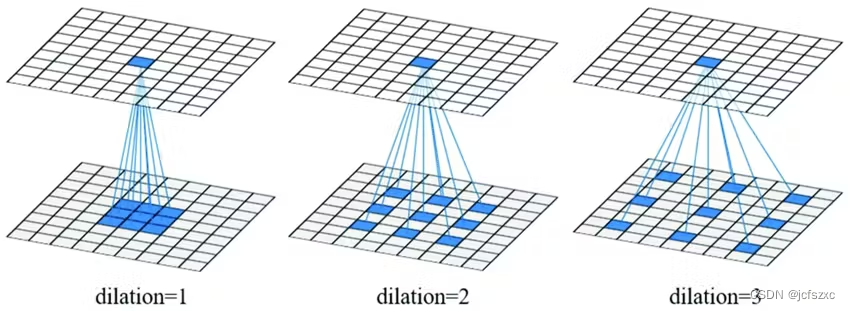
这种形式的扩张卷积可以从更大的视野中提取信息,而无需任何计算开销。
此外,拥有更大的视野可以保持特征空间分辨率,同时提取所有关键细节。
特征空间通过双线性插值和全连接条件随机场算法(CRF)。这些层捕获用于像素损失函数的精细细节,使分割掩模更清晰、更精确。
多尺度物体检测
扩张卷积技术的另一个挑战是捕获不同尺度的物体。 Atrous 卷积核的宽度定义了它最有可能捕获的尺度对象。解决方案是使用 Atrous Spatial Pyramid Pooling (ASPP)。在金字塔池化中,使用多个不同宽度的卷积核。这些变体的结果融合在一起以捕获多个尺度的细节。
金字塔场景解析网络(PSPNet)
PSPNet 是 2017 年推出的著名分割算法。它使用金字塔解析模块从图像中捕获上下文信息。该网络在 PASCAL VOC 2012 上的平均交集 (mIoU) 准确度为 85.4%,在 Cityscapes 数据集上的平均准确度为 80.2%。
该网络遵循编码器-解码器架构。前者由扩张的卷积块和金字塔池层组成,而后者则应用放大来生成像素级预测。整体架构与其他分割技术类似,添加了新的金字塔池化层。
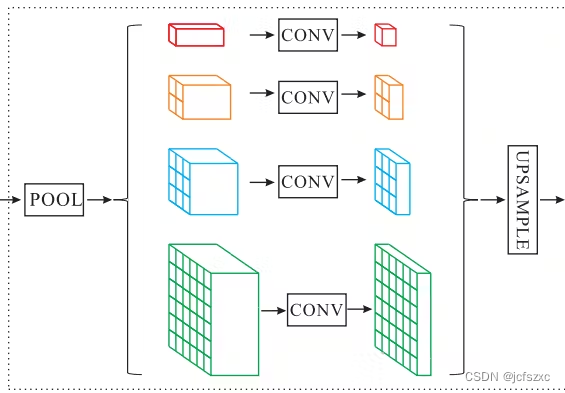
金字塔模块帮助架构从图像中捕获全局上下文信息。 CNN 编码器的输出经过池化和各种缩放,并进一步通过卷积层。卷积后的特征最终被放大到相同的大小并连接起来进行解码。多尺度池允许模型从宽窗口收集信息并聚合整体上下文。
语义分割的应用
语义分割在各行各业都有各种有价值的应用
医学影像
许多医疗程序涉及对 CT 扫描、X 射线或核磁共振成像扫描等影像数据的严格推断。传统上,医学专家会通过分析这些图像来判断是否存在异常。分割模型也能达到类似的效果。
语义分割可以在放射学扫描中的各种元素之间绘制精确的对象边界。这些边界用于检测癌细胞和肿瘤等异常。这些结果可以进一步集成到自动化管道中,用于自动诊断、处方或其他医疗建议。
然而,由于医学是一个关键领域,许多用户对机器人从业者持怀疑态度。该领域的微妙性和缺乏道德准则阻碍了人工智能在实时医疗系统中的采用。尽管如此,许多医疗保健提供者仍然使用人工智能工具来保证和第二意见。
自动驾驶汽车
自动驾驶汽车依靠计算机视觉来了解周围的世界并采取适当的行动。语义分割将汽车的视觉划分为道路、行人、树木、动物、汽车等对象。这些知识有助于车辆系统进行驾驶操作,例如转向以保持在道路上,避免撞到行人,以及在附近检测到另一辆车时制动。

农业
分割模型在农业中用于检测不良作物和害虫。基于视觉的算法学习检测农作物的侵染和疾病。自动化系统还经过编程,可以提醒农民异常现象的精确位置或触发杀虫剂以防止损坏。
图片处理
语义分割的一个常见应用是图像处理。现代智能相机具有肖像模式、增强滤镜和面部特征处理等功能。所有这些巧妙的技巧都以分割模型为核心,用于检测人脸、面部特征、图像背景和前景,以应用所有必要的处理。
语义分割的缺点
尽管语义分割有多种应用,但其缺点限制了其在现实场景中的应用。
尽管它预测每个像素的类标签,但它无法区分同一对象的不同实例。例如,如果我们使用人群图像,模型将识别与人类相关的像素,但不知道人站在哪里。
对于重叠的对象来说,这会更麻烦,因为模型创建了一个没有明确实例边界的统一掩模。因此,该模型不能在某些情况下使用,例如计算存在的物体的数量。全景分割通过结合语义和实例分割来解决这个问题,以提供有关图像的更多信息。
使用 Encord 加速细分
语义分割在计算机视觉中起着至关重要的作用,但手动注释非常耗时。 Encord 改变了标签流程,使用户能够通过可定制的工作流程和强大的质量控制来高效管理和培训注释团队。
语义分割:关键要点
- 图像分割可识别图像中的不同实体并绘制精确的边界以进行定位。
- 分割技术分为三种类型:语义分割、实例分割和全景分割。
- 语义分割预测图像中存在的每个像素的类标签,从而生成详细的分割图。
- FCN、DeepLab 和 U-Net 是流行的分割架构,它们从 CNN 和池化块的不同变体中提取信息。
- 语义分割用于日常任务,例如自动驾驶汽车、农业、医学成像和图像处理。
- 语义分割的一个缺点是它无法区分同一对象的不同出现。大多数开发人员利用全景分割来解决这个问题。