论文标题:CLIPort: What and Where Pathways for Robotic Manipulation
论文作者:Mohit Shridhar1, Lucas Manuelli, Dieter Fox1
作者单位:University of Washington, NVIDIA
论文原文:https://arxiv.org/abs/2109.12098
论文出处:CoRL 2021
论文被引:335(01/05/2024)
论文代码:https://github.com/cliport/cliport,382 star
项目主页:https://cliport.github.io/
Abstract
我们怎样才能让机器人既能精确地操作物体,又能根据抽象概念对物体进行推理?
- 最近的操作研究表明,端到端网络可以学习需要精确空间推理的灵巧技能,但这些方法往往无法泛化到新的目标或快速学习跨任务的可迁移概念。
- 与此同时,通过对大规模互联网数据进行训练,在学习视觉和语言的可泛化语义表征方面也取得了很大进展,但这些表征缺乏精细操作所需的空间理解能力。
为此,我们提出了一个结合了两方面优点的框架:一个具有语义和空间路径的双流架构,用于基于视觉的操作。具体来说,我们提出的 CLIPORT 是一种语言条件模仿学习 agent,它结合了 CLIP [1] 的广泛语义理解(what)和 Transporter [2] 的空间精度(where)。我们的端到端框架能够解决各种语言指定的桌面任务,从包装未见物体到折叠布匹,所有这些任务都不需要任何明确的物体姿态,实例分割,记忆,符号状态或句法结构表征。在模拟和真实世界环境中进行的实验表明,我们的方法在小样本的环境中数据效率很高,并能有效地泛化到已见和未见的语义概念。我们甚至为 10 项模拟任务和 9 项真实世界任务学习了一种多任务策略,其效果优于或相当于单任务策略。
1 Introduction
如果让一个人 “拿一勺咖啡豆” 或 “把布对折”,他就能很自然地把 “勺” 或 “对折” 等概念转化为具体的物理动作,精确度可达几厘米。我们人类凭直觉就能做到这一点,而不需要明确的咖啡豆或布的几何或运动模型。此外,我们还能从最基本的示例中归纳出需要实现的任务和概念。我们如何才能让机器人具备这种能力,将抽象的语义概念有效地转化为精确的空间推理?
最近,人们提出了许多基于视觉的端到端操作框架[2, 3, 4, 5]。虽然这些方法并不使用物体姿态,实例分割或符号状态的任何显式表示,但它们只能复制变化范围较小的演示,而且没有任务的语义概念。从包装红笔切换到包装蓝笔需要收集新的训练集[2],如果使用目标条件策略,则需要用户提供场景中的目标图像[5, 6]。在现实的人机交互环境中,收集额外的演示或提供目标图像往往是不可行和不可扩展的。解决这两个问题的一个自然办法就是用自然语言为策略设定条件。语言提供了一个直观的接口,可用于指定目标,也可用于跨任务的隐式概念迁移。虽然过去已经探索过以语言为基础的操作技术[7, 8, 9, 10],但这些管道受限于以物体为中心的表示法,无法处理颗粒状或可变形的物体,而且通常无法以综合方式推理感知和动作。与此同时,在学习视觉表征模型[11, 12]以及通过在大规模互联网数据上进行训练来对齐(align)视觉和语言表征[13, 14, 15]方面也取得了很大进展。然而,这些模型缺乏对如何操作物体(即物理负担能力(physical affordances))的精细理解。
为此,我们提出了第一个结合了两方面优点的框架:用于细粒度操作的端到端学习,具有视觉语言可执行系统(vision-language grounding systems)的多目标和多任务泛化能力。我们引入了一种双流架构,用于具有语义和空间路径的操作,其灵感大致来源于认知心理学中的双流假设[16, 17, 18]。具体来说,CLIPORT 是一种语言条件模仿学习Agent,它整合了 CLIP [1] 的语义理解(what)和 Transporter [2] 的空间精度(where)。Transporter 已被广泛应用于从工业包装 [2] 到操作可变形物体 [6] 等各种重排(rearragement)任务中。该方法的关键之处在于将桌面操作(tabletop manipulation)表述为一系列 pick-and-place 负担能力预测,其目标是检测动作而非检测物体,然后学习策略。这种以动作为中心的感知方法[19]数据效率高,能有效规避学习表征中明确的物体性(objectness)需求。然而,Transporter 是一个从零开始学习所有视觉表征的 tabula rasa 系统,因此每个新目标或任务都需要收集一组新的演示。为了解决这个问题,我们在学习策略时加入了强大的语义先验。我们利用预先训练好的 CLIP 模型 [1] 中的视觉和语言目标特征来调节语义流。由于 CLIP 经过预先训练,可以将来自互联网的数百万个图像-描述对中的图像和语言特征进行统一,因此它提供了一个强大的先验,可用于将类别,部件,形状,颜色,文本和其他视觉属性等任务中常见的语义概念作为基础,而无需使用需要边界框或实例分割的自顶向下管道[13, 14, 15, 20]。这使我们能够将桌面重新排列表述为一系列以语言为条件的能力预测,这是一个主要基于视觉的推理问题,从而受益于数据驱动范式的优势,如规模和泛化。

为了研究这些优势,我们在 Ravens [2] 框架中使用模拟吸力抓取机器人进行了大规模实验。我们提出了 10 个以语言为条件的任务,每个任务有 1000 个独特的实例,需要语义和空间推理(见图 1 a-j)。CLIPORT 不仅能有效地解决这些任务,而且令人惊讶的是,它甚至能为所有 10 个任务学习一个多任务模型,该模型的性能优于或媲美单任务模型。此外,我们的评估结果表明,我们的多任务模型可以有效地将 “粉色积木” 等属性跨任务迁移,而在评估任务的上下文中,我们从未见过粉色积木或 “粉色” 一词。我们还在Franka Panda操作器上演示了我们的方法,该操作器使用一个多任务模型完成了 9 个真实世界任务,仅使用 179 对图像-动作进行了训练(见图 1 k-o)。
总之,我们的贡献如下:
- Ravens [2]中操作语言基础任务的扩展基准。
- 使用互联网预训练视觉语言模型的双流架构,以语言目标为条件制定精确的操作策略。
- 通过真实机器人实验验证了包括多任务模型在内的各种操作任务的经验结果。基准,代码和预训练模型可在以下网站获取:cliport.github.io。
2 Related Work
Vision-based Manipulation.
传统的操作感知方法主要围绕物体检测器,分割器和姿态估计器 [21, 22, 23, 24, 25, 26]。这些方法无法处理可变形物体,颗粒介质,也无法在没有特定物体训练数据的情况下泛化到未见物体。另外,密集描述符 [27, 28, 29] 和关键点表示法 [30, 31, 32] 则放弃了分割和姿态表示,无法推理出连续的动作,也很难表示物体数量可变的场景。另一方面,端到端感知到行动模型可以学习精确的顺序策略[2, 4, 6, 33, 34, 35],但这些方法对语义概念的理解有限,并且依赖于目标图像作为策略的条件。相比之下,Yen-Chen 等人[36] 的研究表明,对分类和分割等语义任务进行预训练有助于提高抓取预测的效率和泛化。
Semantic Models.
随着大规模模型[37, 38, 39]的出现,人们提出了许多学习视觉和语言联合表征的方法[13, 14, 15, 20, 40]。然而,这些方法仅限于边界框或实例分割,因此不适用于检测堆放的咖啡豆或棋盘上的方块等事物。另外,对比学习方法放弃了自上而下的物体检测,而是通过对无标记数据的预训练来学习连续表征[11, 12]。最近,CLIP[1]也采用了类似的方法,通过对来自互联网的数百万图像-描述对进行训练,使视觉和语言表征相一致。
Language Grounding for Robotics.
有几项研究提出了用自然语言指导机器人的系统[7, 8, 9, 10, 41, 42, 43, 44, 45, 46, 47]。然而,这些方法使用的是感知和动作分离的管道,语言主要用于指导感知。因此,这些管道缺乏折布等任务所需的空间精度。最近,Lynch 等人[48] 提出了一种端到端系统,用于在连续控制中将语言变为可执行的(grounding),但这需要为单个模拟桌面设置提供数小时的人类远程操作数据。
Two-Stream Architectures
双流架构在动作识别网络 [49, 50, 51] 和音频识别系统 [52, 53] 中非常普遍。在机器人学领域,Zeng 等人[54] 和 Jang 等人[55] 提出了用于预测新物体负担能力的双流管道。前者需要目标图像,后者仅限于单类别目标的一步抓取。相比之下,我们的框架为连续任务提供了丰富直观的接口和可组合的语言命令。
3 CLIPORT
CLIPORT 是一种基于四个关键原则的模仿学习Agent:
(1) 通过两步基本原理进行操作,每个动作涉及起始和最终执行器姿态。
(2) 与平移和旋转等价的视觉动作表示[56, 57]。
(3) 语义和空间信息的两条独立路径。
(4) 以语言为条件的策略,用于指定目标和跨任务的概念迁移。
将 Transporter 中的(1)和(2)与(3)和(4)结合起来,我们就能实现超越模仿演示的通用策略。
第 3.1 节描述了问题的提出,概述了 Transporter [2],并介绍了我们的语言条件模型。第 3.2 节详细介绍了训练方法。
3.1 Language-Conditioned Manipulation
我们考虑的问题是学习一个目标条件策略 π π π,该策略在给定输入 γ t = ( o t , l t ) γ_t = (o_t, l_t) γt=(ot,lt) 的情况下输出行动 a t a_t at,输入 γ t = ( o t , l t ) γ_t = (o_t,l_t) γt=(ot,lt) 由视觉观察结果 o t o_t ot 和英语语言指令 l t l_t lt 组成:
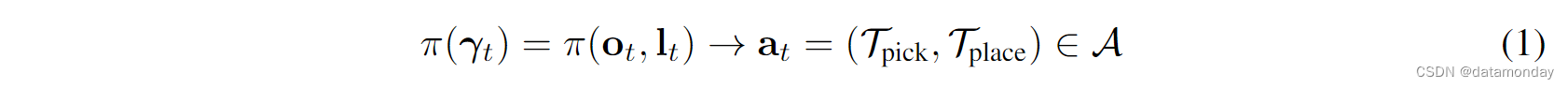
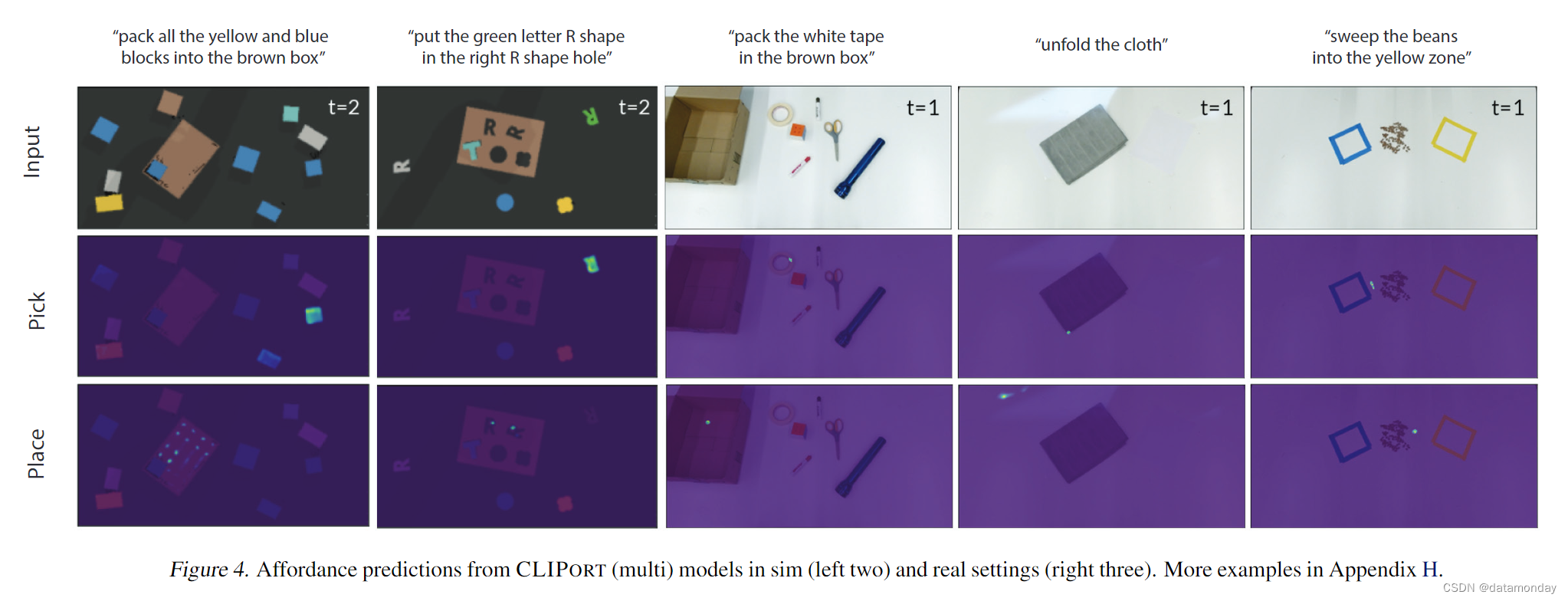
动作 a = ( T p i c k , T p l a c e ) a = (\mathcal{T}_{pick}, \mathcal{T}_{place}) a=(Tpick,Tplace) 分别指定用于拾取和放置的末端执行器姿态。我们考虑 Tpick,Tplace ∈ SE(2) 的桌面任务。视觉观察 ot 是场景的自上而下的正交 RGB-D 重建,其中每个像素对应于 3D 空间中的一个点。语言指令 lt 要么指定逐步指令,例如 "pack the scissors"→ “pack the purple tape” → 等等,要么指定整个任务的单个目标描述,例如 “pack all the blue and yellow boxes in the brown box”。具体示例见图 4。
我们假设可以访问数据集 D = {ζ1, ζ2,… , ζn} 具有相关离散时间输入-动作对 ζi = {(o1, l1, a1), (o2, l2, a2) 的 n 个专家演示。其中 at = (Tpick, Tplace) 对应于时间步 t 的专家拾取和放置坐标。这些专家演示用于监督策略 π。
Transporter for Pick-and-Place.
策略 π 使用 Transporter [2] 进行训练以执行空间操作。该模型首先 (i) 关注局部区域来决定在哪里选择,然后 (ii) 通过深度视觉特征的互相关找到最佳匹配来计算放置位置。
在 Transporter [2, 6] 之后,策略 π 由两个动作值模块(Q 函数)组成:选择模块 Qpick 决定在哪里选择,并以这个选择动作为条件,位置模块 Qplace 决定在哪里放置。这些模块实现为完全卷积网络(FCNs),在设计上平移等变。正如我们将在下面更详细地描述的那样,我们将这些网络扩展到可以处理语言输入的双流架构。选择 FCN fpick 接受输入 γt = (ot, lt),并输出动作值的密集像素级预测 Q p i c k ∈ R H × W \mathcal{Q}_{pick} ∈ \mathbb{R}^{H×W} Qpick∈RH×W,用于预测拾取动作 Tpick:
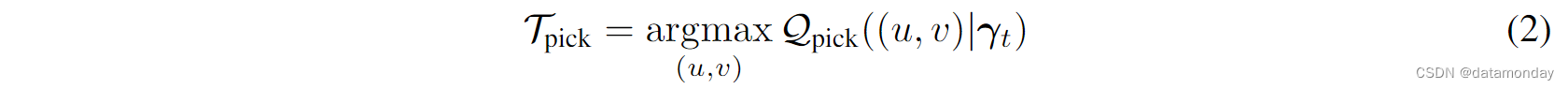
由于 ot 是一个正交高度图,因此每个像素位置 (u, v) 可以使用已知的相机校准映射到 3D 拾取位置。fpick 以有监督的方式进行训练,以预测在时间步 t 使用指定的语言指令模仿专家演示的拾取动作 Tpick。
第二个 FCN Φquery 采用 γt[Tpick],它是以 Tpick 为中心的 ot 的 c × c 裁剪以及语言指令 lt,并输出形状 R c × c × d \mathbb{R}^{c×c×d} Rc×c×d 的查询特征嵌入。第三个 FCNΦkey 使用完整的输入 γt 并输出形状 RH×W ×d 的关键特征嵌入。然后通过交叉关联查询和关键特征来计算位置动作值 Qplace:
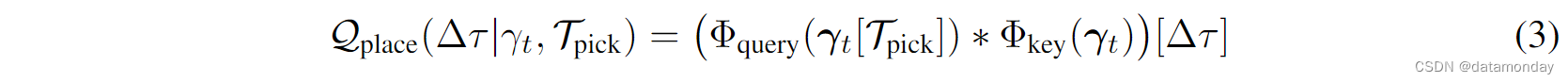
其中 Δτ ∈ SE(2) 表示潜在的放置姿态。由于 ot 是一个正交高度图,因此在通过查询网络 Φquery 之前,可以通过堆叠裁剪的 k 个离散角度旋转来捕获放置姿态 Δτ 中的旋转。然后 Tplace = argmax∆τ Qplace(Δτ |γt, Tpick),其中位置模块被训练以模仿专家演示中的位置。对于所有模型,我们使用 c = 64,k = 36 和 d = 3。与 Transporter [2, 6] 中一样,我们的框架可以扩展到处理任何运动原语(motion primitive),例如推,滑动等,这些原语可以由每个时间步的两个末端执行器姿态参数化。有关更多详细信息,请读者参阅原始论文[2]。
Two-Stream Architecture.
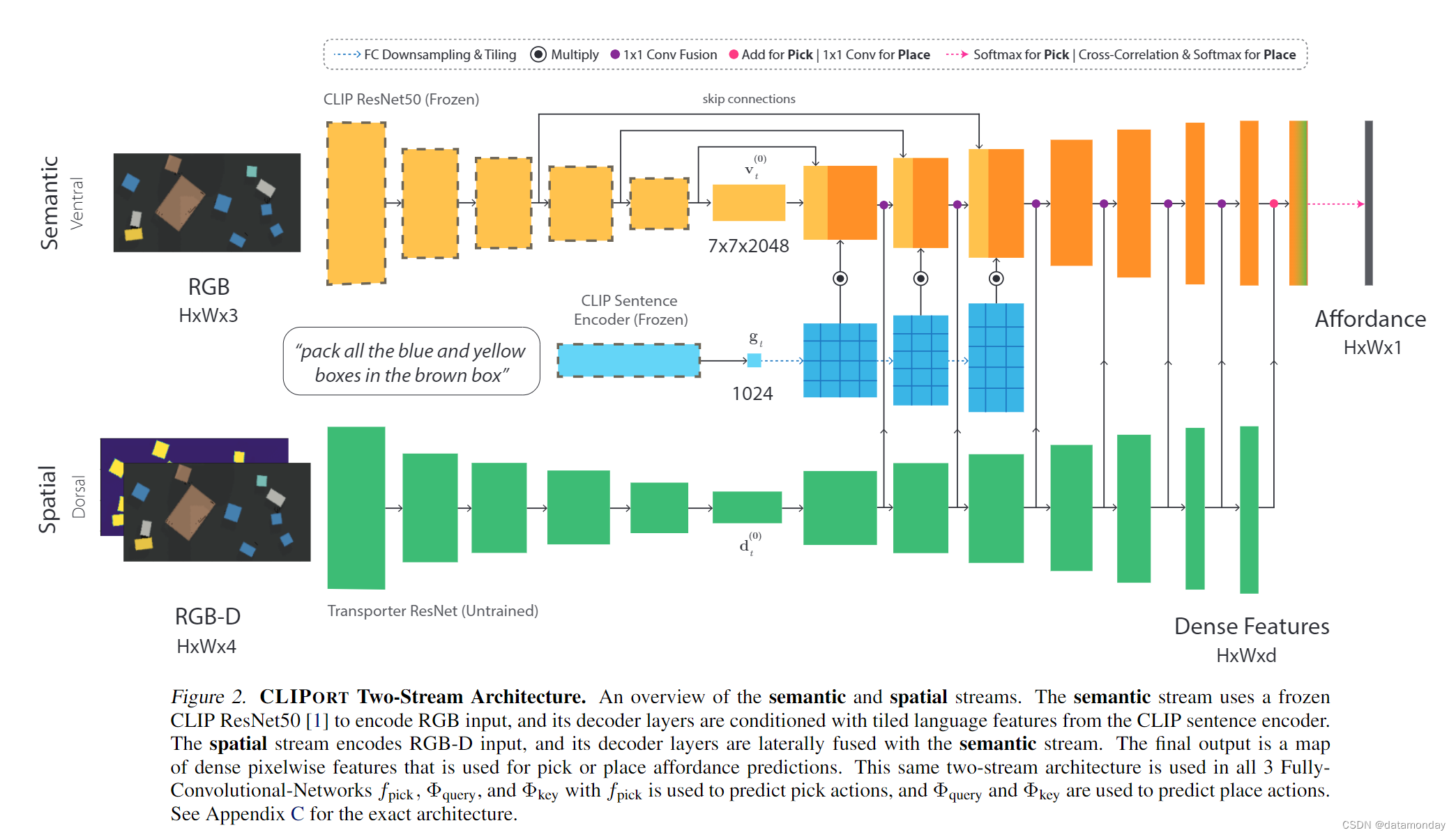
在CLIPORT中,我们扩展了Transporter[2]中所有三个FCNsfpick,Φquery和Φkey的网络架构,以允许语言输入和对高级语义概念的推理。我们将 FCN 扩展到两条路径:语义(腹侧)和空间(背侧)。语义流以瓶颈处的语言特征为条件,并与空间流的中间特征融合。有关架构的概述,请参见图 2。
空间流与 Transporter 中的 ResNet 架构相同——一种采用 RGB-D 输入 ot 的白板网络(tabula rasa network),并通过沙漏编码器-解码器模型输出密集特征。语义流使用冻结的预训练 CLIP ResNet50 [1] 对 RGB input otup 进行编码,直到倒数第二层 ot → v(0)t : R7×7×2048,然后引入对特征张量进行上采样的解码层来模拟每一层的空间流 v(l−1)t → v(l)t : Rh×w×C。
语言指令lt使用基于clip的Transformer编码器进行编码,生成目标编码lt→gt: R1024。该目标编码gt用全连接层进行下采样,以匹配通道维度C,平铺以匹配解码器特征的空间维度,使gt→g(l)t: Rh×w×C。然后,解码器特征通过元素乘积 v(l)t g(l)t (Hadamard 乘积) 以平铺的目标特征为条件。由于 CLIP 在池化图像特征和语言编码之间的点积对齐上使用对比损失进行训练,因此逐元素乘积允许我们使用这种对齐,而平铺保留了视觉特征的空间维度。在受 LingUNet [58] 启发的 backbone 之后,对三个后续层重复此过程语言条件。我们还在 CLIP ResNet50 编码器中添加了这些层跳过连接,以利用从形状到部分的不同语义信息到物体级概念 [59]。最后,遵循视频动作识别[51]中现有的双流架构,我们将空间流的横向连接添加到语义流中。这些连接涉及连接两个特征张量并应用 1 × 1 conv 来降低通道维度 [v(l)t g(l)t ; d(l)t ] : Rh×w×Cv +Cd → Rh×w×Cv ,其中 v(l)t 和 d(l)t 分别是第 l 层的语义和空间张量。对于密集特征的最终融合,对于 Φquery 和 Φkey 添加 fpick 和 1 × 1 conv 融合在经验上效果最好。有关精确架构的详细信息,请参见附录 C。
3.2 Implementation Details
Training from demonstrations.
与Transporter[2]类似,我们通过从一组专家演示 D={ζ1, ζ2,… , ζn} 模仿学习来训练CLIPORT。 由离散时间输入动作对 ζi = {(o1, l1, a1), (o2, l2, a2), …} 组成。在训练期间,我们从数据集中随机采样输入动作对,并通过演示动作 Ypick : RH×W ×k 和 Yplace : RH×W ×k 和 Yplace : RH×W ×k 与 k 个离散旋转。在吸力夹持器的模拟实验中,我们使用 k = 1 来选择动作,k = 36 表示位置动作。该模型采用交叉熵损失进行训练:L = -EYpick [log Vpick] - EYplace [logVplace] 其中 Vpick = softmax(Qpick(((u, v)|γt)) 和 Vplace = softmax(Qplace((u′, v′, ω′)|γt, Tpick))。与经过 40K 次迭代训练的原始 Transporter 模型相比,我们训练了 200K 次迭代的模型(数据增强;参见附录 E),以解释任务的额外语义变化——随机颜色,形状,物体。所有模型都在单个 GPU 上训练 2 天,批量大小为 1。
Training multi-task models.
除了训练数据的取样,多任务训练与单任务训练几乎完全相同。首先,我们随机抽样一个任务,然后从数据集中随机选择该任务的一对输入动作。采用这种策略,所有任务都有同样的可能被抽样,但时间跨度较长的任务不太可能完全覆盖数据集中的输入-动作对。为了弥补这一不足,我们将所有多任务模型的训练时间延长了 3 倍,达到 600K 次迭代或 6 个 GPU 天。
4 Results
我们进行了模拟和硬件实验,旨在回答以下问题:
1)与单流替代方案和其他更简单的基线方案相比,以语言为条件的双流架构在细粒度操作方面的效果如何?
2)是否可以针对所有任务训练多任务模型?
3)这些模型对已见和未见的语义属性(如颜色,形状和物体类别)的泛化效果如何?
4.1 Simulation Setup
Environment.
所有模拟实验均基于带有吸力抓手的通用机器人 UR5e。这种设置为评估提供了一个系统化和可重复的环境,尤其是为确定颜色和物体类别等语义概念的落地能力提供了基准。输入观测数据是由围绕矩形桌子放置的 3 个摄像头自上而下重建的 RGB-D 图像:一个在前方,一个在左肩,一个在右肩,所有摄像头都指向中心。每台摄像机的分辨率为 640 × 480,且没有噪声。
Language-Conditioned Manipulation Tasks.
我们扩展了 PyBullet [60] 中的 Ravens 基准 [2],增加了 10 个语言条件操作任务。示例见图 1,与每个任务相关的挑战见表 3。每个任务实例都是通过对一组物体和属性(姿态,颜色,大小和物体类别)进行采样而构建的。10 个任务中有 8 个任务有两个变体,分别用 seen 和 unseen 表示,这取决于任务在测试时是否有看不见的属性(如颜色)。就颜色而言 Tseen 颜色={黄色,棕色,灰色,青色}和 Tunseen 颜色={橙色,紫色,粉色,白色},其中 3 种重叠颜色 Tall = {红色,绿色,蓝色}同时用于可见和未可见任务。在包装物体方面,我们使用了 Google Scanned Objects 数据集[61] 中的 56 个桌面物体,并将其分为 37 个可见物体和 19 个未见物体。在模拟实验中,语言指令由模板构建;在真实世界实验中,语言指令由人工标注。有关个别任务的更多详情,请参阅附录 A。
Evaluation Metric.
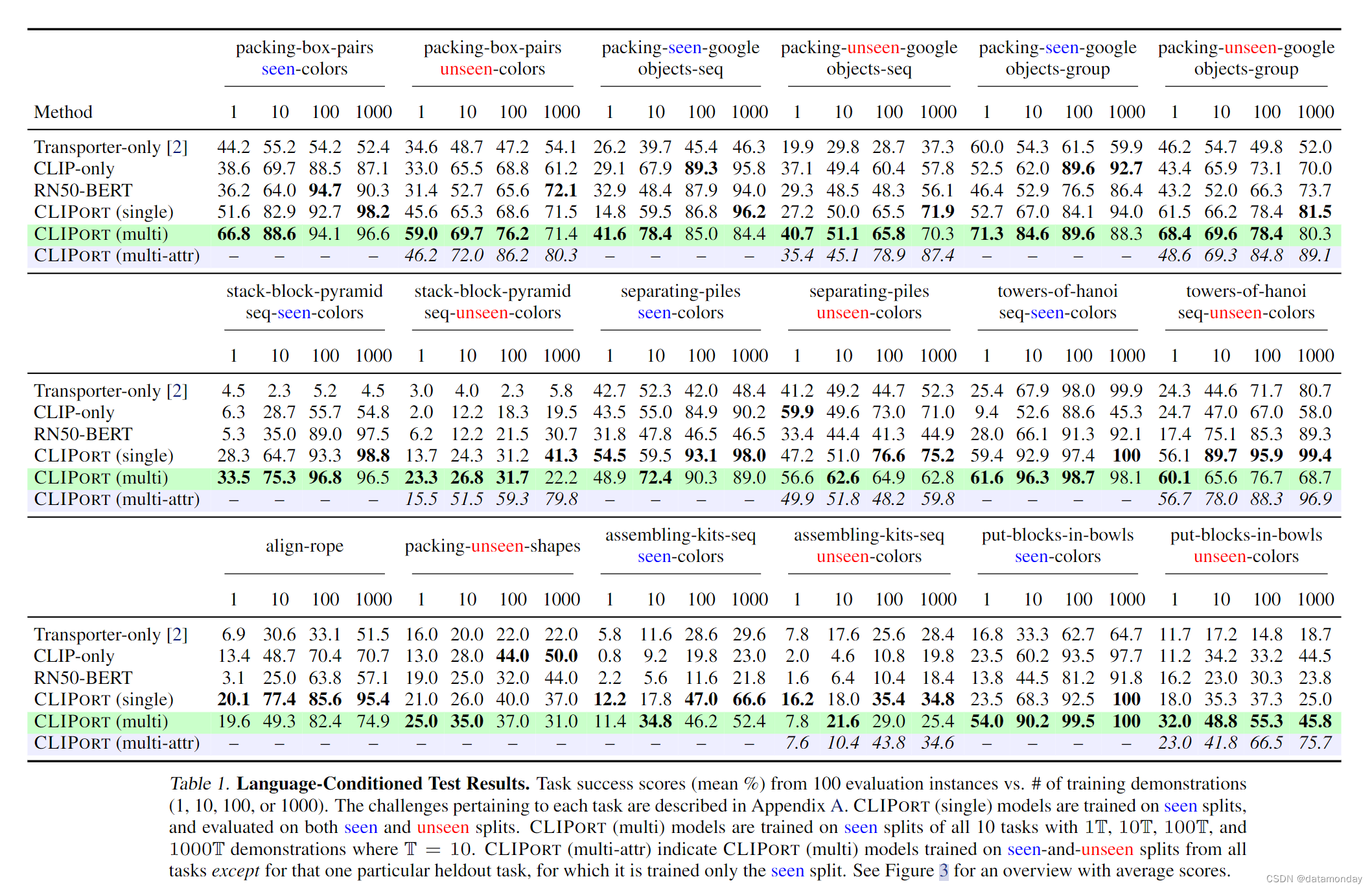
我们采用 Ravens 基准[2]中提出的 0(失败)到 100(成功)的分数。分数根据任务分配部分学分,例如,3/5 ⇒ 60.0 表示将指令中指定的 5 个物体中的 3 个打包,或 30/56 ⇒ 53.6 表示将 56 个中的 30 个推入正确区域。每项任务使用的具体评估指标见附录 A。在评估过程中,Agent会一直与场景进行交互,直到甲骨文指示任务完成。我们报告了以 n = 1,10,100,1000 次演示训练的Agent在 100 次评估运行中的得分。
4.2 Simulation Results
表 1 展示了我们在 Ravens [2] 中的大规模实验的结果,图 3 总结了这些结果,平均分数在 seen 和 unseen split 中。
Baseline Methods.
为了研究双流架构的有效性,我们将其与两个基线进行了广泛比较:Transporter-only 和 CLIP-only。Transporter-only 是最初的 Transporter [2],或者等同于带有 RGB-D 输入的 CLIPORT 空间流。虽然 Transporter-only 没有接收任何语言目标,但它展示了通过利用训练过程中最有可能出现的动作,可以通过偶然性实现什么目标。另一方面,CLIP-only 只是带有 RGB 和语言输入的 CLIPORT 语义流。CLIP-only 展示了在没有空间信息(尤其是深度信息)的情况下,通过微调预先训练好的语义模型来进行操作所能达到的效果。
Two-Stream Performance.
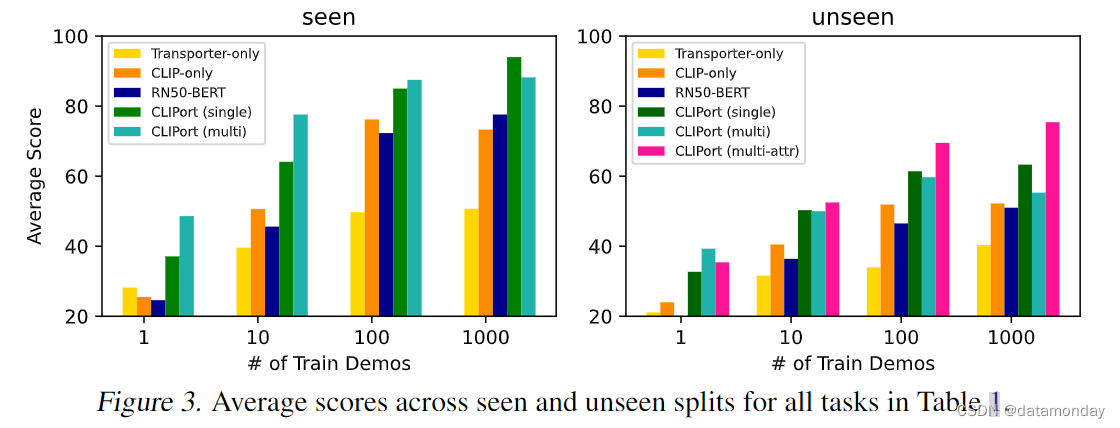
图 3(见图)捕捉到了我们主要主张的精髓。只使用 Transporter 的性能在 50% 时达到饱和,因为它没有使用语言指令来实现预期目标。CLIP-only 的确有一个目标,但缺乏空间精度来完成最后一英里,因此在 76% 时达到饱和。只有 CLIPORT(单一)达到了 90% 以上,这表明语义流和空间流对精细操作都至关重要。此外,在大多数任务中,CLIPORT(单次)只用了 100 次演示就达到了 86%,显示了它的效率。
除了这些基线外,我们还在附录 F 中介绍了各种消融和替代的单流和双流模型。简要概括这些结果,CLIP 对于小样本学习(即 n ≥ 10)是必不可少的,它取代了语义流替代方案,如采用 BERT [38] 的 ImageNet 训练的 ResNet50 [62]。图像目标模型在打包谷歌物体方面优于 CLIPORT(单一),但这只是因为它们无需解决语言可执行(grounding)问题。
Multi-Task Performance.
在现实场景中,我们希望机器人能够胜任任何任务,而不仅仅是一项任务。我们通过表 1 中的 CLIPORT (multi),用一个在所有 10 个任务上训练过的多任务模型来研究这一点。CLIPORT (multi)模型仅在任务的可见分割上进行训练,因此像 “粉红色” 这样的未知属性在单任务和多任务设置中都是一致的。令人惊讶的是,在表 1 中 41/72 = 57% 的评估中,CLIPORT(多任务)模型的表现优于单任务 CLIPORT(单任务)模型。这一趋势在图 3(可见)中也很明显,尤其是在演示数为 100 或更少的实例中。虽然 CLIPORT(多)是在来自其他任务的更多样化数据上训练出来的,但 CLIPORT(多)和 CLIPORT(单)在每个任务中都能获得相同数量的数据。这支持了我们的假设,即语言是一种强大的调节机制,可以重复使用其他任务中的概念,而无需从头开始学习。这也验证了数据驱动方法的一个特点,即通过对大量不同数据的训练,可以获得更稳健,更通用的表征[1, 63]。然而,CLIPORT(multi)在像对齐绳索这样的长周期任务中表现较差。我们假设,这是因为较长周期的任务在数据集中获得的输入-动作对的覆盖范围较小。未来的工作可以使用更好的采样方法,根据任务的平均时间跨度对其进行平衡。
Generalizing to Unseen Attributes.
如图 3(未见)所示,需要对新颜色,形状和物体进行泛化的任务难度更大,我们的所有Agent在这些任务上的表现都相对较低。不过,CLIPORT(单一)模型的表现要远远好于其他模型,即仅有运输机模型。性能较低的原因是,当Agent从未在物理环境中遇到过 “橙色”,“粉色” 或其相应的视觉特征时,就很难在 "将粉色块放在橙色碗上 "的语言指令中将 “粉色” 和 “橙色” 等未见属性作为基础。虽然经过预训练的 CLIP 已经接触过 “粉红色” 这一属性,但它在物理环境中可能对应不同的概念,这取决于照明条件等因素,因此至少需要几个例子来调节可训练的语义解码器层。此外,我们注意到 CLIPORT(单一)与 Transporter-only 相比也不易出现过度拟合。表 1 中的 “towers-of-hanoi-seq-unseen-colors” 任务表明,尽管 Tower of Hanoi 可以在不考虑颜色的情况下求解,而只需关注环的大小,但由于环上有未见的颜色, Transporter-only 会导致性能下降。我们假设,由于 CLIP 是在不同的互联网数据上训练出来的,因此它能让我们的Agent专注于与任务相关的概念,而忽略任务中无关的方面。
Transferring Attributes across Tasks.
处理未见属性的一种解决方案是从其他任务中明确学习这些属性。我们在表 1 和图 3(unseen)中使用 CLIPORT(multi-attr)对其进行了研究。在这些模型中,CLIPORT(multi)是在所有任务的已见和未见拆分的基础上进行训练的,只有正在评估的任务除外,因为它只在已见拆分的基础上进行训练。因此,本次评估测量的是,在 “未见颜色” 的 “将积木放入碗中” 任务中,看到粉色积木是否有助于解决 “未见颜色” 的 “包装盒对” 任务中的 “包装所有粉色和青色盒子” 问题。结果表明,这种明确的迁移带来了显著的改进。例如,在 n = 1000 的 put-blocks-inbowls-unseen-colors 任务中,CLIPORT (multi) 的性能从 45.8 提高到 75.7。
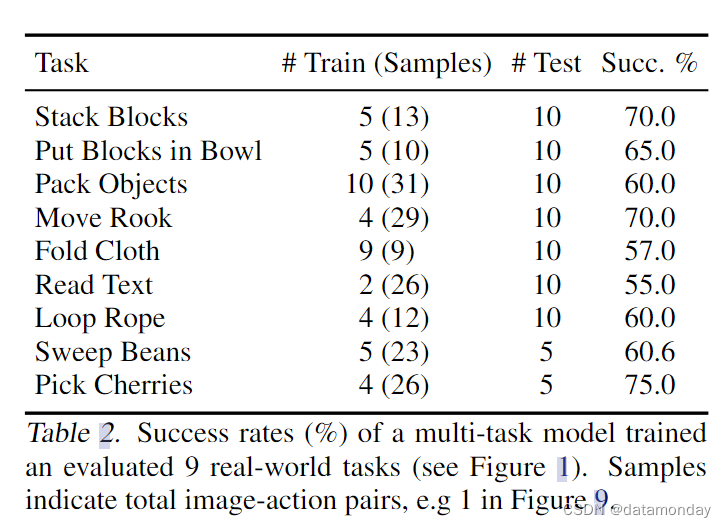
4.3 Real-Robot Experiments

我们使用Franka Panda机械手在硬件上验证了我们的结果。设置详情见附录 D。表 2 报告了在 9 个实际任务中训练和评估的多任务模型的成功率。由于 COVID 的限制,我们无法进行大规模的用户研究,因此我们报告的是每个任务的小型训练集(5-10 个演示)和测试集(5-10 个运行)。总体而言,CLIPORT(multi)在仅有 179 个样本的情况下就能有效地进行小样本学习,其表现与模拟实验中的表现基本一致,其中简单的块操作任务达到了 70% 以上。我们估计,如图 3 所示,要想在真实世界中取得更优异的成绩,至少需要 50 到 100 次训练演示。有趣的是,我们观察到模型有时会利用训练数据中的偏差,而不是学习可执行指令。例如,在 “把积木放进碗里” 中,训练集只有一个样本,即把 “黄色积木” 放进 “蓝色碗” 中。这使得模型很难将 “黄色积木” 放入非蓝色的碗中。但是,只要有一两个例子表明一个彩色积木块被放到了不同颜色的碗里,就足以让模型注意到这些语言。总之,包含良好覆盖预期技能和不变性以及大量训练演示的无偏数据集对于良好的现实世界性能至关重要。
5 Conclusion
我们介绍了 CLIPORT,这是一个端到端框架,用于语言条件下的细粒度操作。我们的实验,特别是多任务模型的实验表明,数据驱动的泛化方法在机器人技术中尚未得到充分应用。端到端方法与正确的动作抽象和空间语义先验相结合,可以快速学习新技能,而不需要自上而下的管道,也不需要针对特定任务的工程设计。
虽然 CLIPORT 可以解决一系列桌面任务,但将其扩展到灵巧的 6-DOF 操作(超越两步基本操作)仍然是一项挑战。因此,它无法处理复杂的部分可观测场景,或为多指手输出连续控制,或预测任务完成情况(更多讨论见附录 I)。但总的来说,我们对数据和结构先验的融合为构建可扩展,可通用的机器人系统而感到兴奋。
A Task Details
B Evaluation Workflow and Validation Results
※ C Two Stream Architecture Details
※ D Robot Setup
Hardware Setup.
所有实体机器人实验都是在带有平行夹持器的Franka Panda机器人上进行的。对于感知,我们使用安装在三脚架上的 Kinect-2 RGB-D 相机,向下看桌子。尽管Kinect-2以1280 × 720的分辨率提供图像,但我们使用下采样的960 × 540图像来实现更快的用户接口。通过 ARUCO ROS 使用 AR 标记计算相机和机器人基础帧之间的外部校准。有关设置的概述,请参见图 8。

Demonstrations and Execution.
为了使用 Franka Panda 收集演示,我们开发了一种 2D 交互工具,该工具使用来自 Kinect-2 的自上而下的 RGB 视图来指定拾取和放置的位置。用户首先在实时 RGB 提要上选择一个 2D 边界框,然后通过单击边界框来选择离散的旋转角度。对于抓取,我们使用一个简单的启发式方法来确定靠近手指的高度。首先,我们对边界框封装的点云进行分割,然后将点云垂直裁剪到夹持器手指的高度,然后通过取平均值计算所选点的3D质心。这个3D质心被用来规划末端执行器的路径,RRT*运动规划器执行预定义的序列——向下、打开/关闭夹持器,抬起。为了执行经过训练的CLIPORT模型,使用了类似的抓取方法,但不是用户指定的边界框,而是以拾取和放置预测(即可视性argmax)为中心的32 × 32作物来计算点云的三维质心。只有扫描和折叠动作不同,因为末端执行器在抓取后不会上升。
Pick Rotations for Parallel Grippers.
模拟中使用的吸力夹持器不需要拾取旋转,因为抓取被指定为针点位置。然而,使用Franka Panda,并行夹持器需要特定的偏航旋转来抓取物体。为了解决这个问题,我们将挑选模块 Qpick 分为两个组件:定位器和旋转器。定位器在给定完整观察和语言输入的情况下预测像素位置 (u, v)。旋转器在 (u, v) 和语言输入处采用 64 × 64 的观察裁剪,并通过从 k 个旋转作物之一中选择来预测离散旋转角度。我们在我们所有的硬件实验中使用 k = 36。虽然可以使用单个模块预测位置和旋转,但这种解耦方法允许我们在单个 GPU (NVIDIA P100) 上拟合模型,并减少裁剪旋转的内存使用。