大数据工具之Trino
简介
不少人没有听说过Trino,但绝大多数人都听说过Presto,一个基于JVM的MPP计算引擎,Presto是一个高性能的、分布式的大数据SQL查询引擎。
诞生于Facebook(脸书),扬名于Linux基金会!
官网:https://trino.io/
广告词:Connect Everything(别人总结的,自己的有点长)
从字面意思可以看到它支持的数据源应该是没有限制的,例如:Hadoop、AWS S3、Alluxio、MySQL、Cassandra、Kafka、ES、Kudu、MongoDB、MySQL等等,一句话,就是在市面能看到的存储,它基本上都支持。
Trino没有自己的存储,实现了存储与计算分离,而存储与计算分离的核心就是基于连接器的架构。连接器为Trino提供了连接任意数据源的接口,也可以自定义编程实现连接器
安装须知
操作系统要求
- 64位Linux系统
- 为运行trino的用户提供足够的unlimit。包括trino能够打开的文件描述符,官方推荐以下配置:
vim /etc/security/limits.confroot soft nofile 131072
root hard nofile 131072#修改完后,退出当前会话,重新登录即可生效。查看配置是否生效:
[root@paratera128 ~]# su root
[root@paratera128 ~]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7154
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 131072
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 7154
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimitedJava运行时要求
Trino要求使用Java 11 64位版本,最低要求为:11.0.11,注意:不支持Java 8,也不支持 Java 12或者Java 13。Trino官方推荐我们使用Azul Zulu的JDK版本。此处,我们选择较新的11.0.12+7版本。
Python版本要求
版本:2.6.x、2.7.x、或者3.x
当前主流的Liunx系统:Centos 7自带的版本是2.7.5,ubuntu16.04自带两个python版本,一个是Python 2.7.12,另一个是Python 3.5.2,够用,如果想折腾另说
节点矩阵
一般来说集群各节点之间都属于局域网环境,把防火墙关了
192.168.137.128节点配置域名映射如下:
#vim /etc/hosts
192.168.137.128 paratera128
192.168.137.129 paratera129
192.168.137.130 paratera130
| node | hostname | role | Memory |
|---|---|---|---|
| 192.168.137.128 | paratera128 | coordinator | 1G |
| 192.168.137.129 | paratera129 | worker | 2G |
| 192.168.137.130 | paratera130 | worker | 2G |
假装Worker给了2G,其实只有一个G(迫于财力),只想说明一点就是coordinator可以只作为协调者,有限的资源应该偏向Worker!
安装过程
创建trino用户
我们这里就不创建了,三台机器都用root账号,如果需要的可以通过命令创建并设置权限:
groupadd trino;
useradd 账号;
usermod 账号 -G trino;
节点免密登录
方便后面资料分发和切换操作
#1、paratera128生成密钥公钥 [root@paratera128 opt]# ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /root/.ssh/id_rsa. Your public key has been saved in /root/.ssh/id_rsa.pub. The key fingerprint is: SHA256:LtZpH8isWa6CncLHG+OsVSaPCL8toJRtmuFMlW7oZrQ root@paratera128 The key's randomart image is: +---[RSA 2048]----+ | | | | | . | | o | |. * . o S | |.X * * = o | |OoX+=.+ X . | |.E=**+ B . . | |o o==o+.. . | +----[SHA256]-----+ [root@paratera128 opt]# cd /root/.ssh/ [root@paratera128 .ssh]# ls -la total 16 drwx------. 2 root root 57 Jul 17 23:44 . dr-xr-x---. 6 root root 4096 Jul 17 23:42 .. -rw-------. 1 root root 1675 Jul 17 23:44 id_rsa -rw-r--r--. 1 root root 398 Jul 17 23:44 id_rsa.pub -rw-r--r--. 1 root root 177 Jul 10 20:18 known_hosts#2、paratera128本机免密,毕竟也要在128上操作 [root@paratera128 .ssh]# ssh-copy-id root@192.168.137.128 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys root@192.168.137.128's password:Number of key(s) added: 1Now try logging into the machine, with: "ssh 'root@192.168.137.128'" and check to make sure that only the key(s) you wanted were added.#3、把id_rsa.pub 公钥分别复制到paratera129,paratera130 /root/.ssh目录下(没有你就mkdir) [root@paratera128 .ssh]# scp id_rsa.pub paratera129:/root/.ssh/ The authenticity of host 'paratera130 (192.168.137.129)' can't be established. ECDSA key fingerprint is SHA256:o/nY3kq4UEVzz7LN5qLMQFwixXTIXU+Zv2Nnytzwtug. ECDSA key fingerprint is MD5:c0:91:28:b9:57:fe:5c:67:93:27:e2:b9:12:f3:2e:cd. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'paratera130,192.168.137.129' (ECDSA) to the list of known hosts. root@paratera130's password: id_rsa.pub [root@paratera128 .ssh]# scp id_rsa.pub paratera130:/root/.ssh/ The authenticity of host 'paratera130 (192.168.137.130)' can't be established. ECDSA key fingerprint is SHA256:o/nY3kq4UEVzz7LN5qLMQFwixXTIXU+Zv2Nnytzwtug. ECDSA key fingerprint is MD5:c0:91:28:b9:57:fe:5c:67:93:27:e2:b9:12:f3:2e:cd. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'paratera130,192.168.137.130' (ECDSA) to the list of known hosts. root@paratera130's password: id_rsa.pub #4、paratera129、paratera130 公钥目录下生成 authorized_keys 文件,对应 #PubkeyAuthentication yes # The default is to check both .ssh/authorized_keys and .ssh/authorized_keys2 # but this is overridden so installations will only check .ssh/authorized_keys AuthorizedKeysFile .ssh/authorized_keys[root@paratera129 .ssh]# cat id_rsa.pub>>authorized_keys [root@paratera129 .ssh]# ls authorized_keys id_rsa.pub[root@paratera130 .ssh]# cat id_rsa.pub>>authorized_keys [root@paratera130 .ssh]# ls authorized_keys id_rsa.pub#5、重启sshd服务 [root@paratera129 .ssh]# service sshd restart Redirecting to /bin/systemctl restart sshd.service[root@paratera130 .ssh]# service sshd restart Redirecting to /bin/systemctl restart sshd.service
安装JDK
zulu11.50.19-ca-jdk11.0.12-linux_x64.tar.gz
下载连接:https://download.csdn.net/download/huxiang19851114/86248146
[root@paratera128 ~]# mkdir /opt/trino
[root@paratera128 ~]# chmod 777 /opt/trino/
# 解压
[root@paratera128 ~]# tar -xvzf zulu11.50.19-ca-jdk11.0.12-linux_x64.tar.gz -C /opt/trino/
# 创建超链接,短小精悍
[trino@ha-node1 ~]$ ln -s /opt/zulu11.50.19-ca-jdk11.0.12-linux_x64/ /opt/jdk11_zulu
[root@paratera128 ~]# ll /opt/trino/ | grep jdk11_zulu
lrwxrwxrwx. 1 root root 48 Jul 17 23:19 jdk11_zulu -> /opt/trino/zulu11.50.19-ca-jdk11.0.12-linux_x64/
#环境遍历配置
[root@paratera128 ~]# vim /etc/profileexport JAVA_HOME=/opt/trino/jdk11_zuluexport PATH=$JAVA_HOME/bin:$PATH
[root@paratera128 ~]# source /etc/profile
[root@paratera128 ~]# java -version
openjdk version "11.0.12" 2021-07-20 LTS
OpenJDK Runtime Environment Zulu11.50+19-CA (build 11.0.12+7-LTS)
OpenJDK 64-Bit Server VM Zulu11.50+19-CA (build 11.0.12+7-LTS, mixed mode)
分发脚本
在这里因为涉及到集群部署,包括安装文件和启动脚本都有很多重复的操作,考虑使用分发脚本的模式,一台配置好后scp过去即可,所以创建一个文件夹把所有trino相关的安装资料都放一块
xync.sh
#!/bin/bash
echo "--------------Start Xync Data......----------------"for node in "paratera129" "paratera130";
doscp -r /opt/trino $node:/optssh $node "ln -s /opt/trino/zulu11.50.19-ca-jdk11.0.12-linux_x64/ /opt/trino/jdk11_zulu"scp /etc/profile $node:/etc/profilessh $node "source /etc/profile"
doneecho "--------------Xync Data Done......----------------"后续有任何需要同时在三台服务器上执行的操作都可以往这里加
安装Trino
trino-server-359.tar.gz
下载链接:https://download.csdn.net/download/huxiang19851114/86248147
解压配置trino
#解压Trino
[root@paratera128 ~]# tar -xvzf trino-server-359.tar.gz -C /opt/trino/#trino解压目录创建数据目录
[root@paratera128 ~]# mkdir /opt/trino/trino-server-359/data#trino解压目录创建配置目录
[root@paratera128 ~]# mkdir /opt/trino/trino-server-359/etc
配置目录将配置如下信息:
- trino节点配置:配置每个trino节点的环境。
- JVM配置:配置JVM的相关参数。
- Config属性:配置trino服务器。
- Catalog属性:配置trino的connector(数据源)
配置节点属性
/etc/node.properties
node.environment=trino_dev
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir=/opt/trino/trino-server-359/data
说明:
- node.environment:集群中的所有trino节点都必须由相同的环境名称。必须以小写字母开头,只能包含小写字母、数字和下划线。
- node.id:安装的trino节点的唯一标识符。每个节点都必须由唯一的标识符。标识符必须以字母数字字符开头,并且只能包含字母数字、- 或 _ 字符。
- node.data-dir:trino的数据目录,trino会在该目录中存放日志、以及其他数据。
配置JVM
/etc/jvm.config
-server
-Xmx3G
-XX:-UseBiasedLocking
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+ExplicitGCInvokesConcurrent
-XX:+ExitOnOutOfMemoryError
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-XX:ReservedCodeCacheSize=512M
-XX:PerMethodRecompilationCutoff=10000
-XX:PerBytecodeRecompilationCutoff=10000
-Djdk.attach.allowAttachSelf=true
-Djdk.nio.maxCachedBufferSize=2000000
每个节点可以配置不同的容量,根据自己服务器内存大小量力而行
配置trino服务器
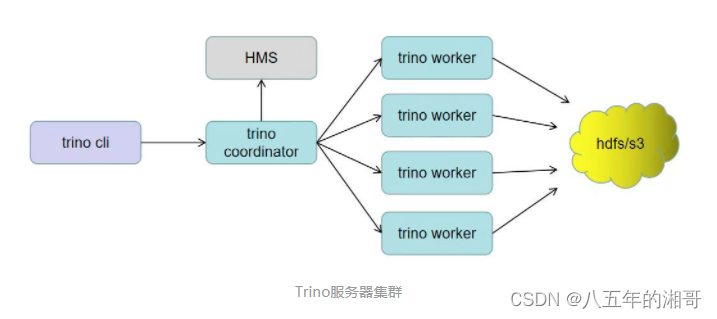
Trino的服务器集群有两种角色:coordinators 和 workers。
Coordinators
- Trino的coordinator是负责解析语句、计划查询和管理 Trino workers的服务器。它是 Trino 安装的“大脑”,也是客户端连接以提交执行语句的节点。每个 Trino 安装都必须有一名 Trino coordinator以及一名或多名 Trino workers。出于开发或测试目的,可以将 Trino 的单个实例配置为执行这两个角色。
- coordinator跟踪每个worker的活动并协调查询的执行。coordinator创建涉及一系列阶段的查询的逻辑模型,然后将其转换为在worker集群上运行的一系列连接任务。
- coordinator使用 REST API 与worker和client进行通信。
Workers
- worker 负责执行任务和处理数据。worker从连接器获取数据并相互交换中间数据。coordinator负责从worker那里获取结果并将最终结果返回给client。
- 当 Trino worker进程启动时,它会将自己通告给coordinator中的discovery服务器,这使得 Trino coordinator可以使用它来执行任务。
- worker使用 REST API 与worker和 Trino coordinator进行通信。
Coordinators配置:/etc/config.properties
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=10080
query.max-memory=1GB
query.max-memory-per-node=1GB
query.max-total-memory-per-node=1GB
discovery.uri=http://paratera128:10080 #服务发现地址(Coordinators节点)
Workers配置:/etc/config.properties
coordinator=false
http-server.http.port=10080
query.max-memory=2GB
query.max-memory-per-node=2GB
query.max-total-memory-per-node=2GB
discovery.uri=http://paratera128:10080 #服务发现地址(Coordinators节点)
配置日志级别
/etc/log.properties
io.trino=INFO
配置connector
catalog可以对应数据schema,可以配置多种语言扩展管理,我们这里配置JMX(Java Management Extensions,即Java管理扩展)意思意思,后续连接不同数据源再创建不同的connector
# 创建catalog目录
mkdir /opt/trino/etc/catalog
vim /opt/trino/etc/catalog/jmx.propertiesconnector.name=jmx
更新分发脚本
#!/bin/bash
echo "--------------Start Xync Data......----------------"for node in "paratera129" "paratera130";
doscp -r /opt/trino $node:/optssh $node "ln -s /opt/trino/zulu11.50.19-ca-jdk11.0.12-linux_x64/ /opt/trino/jdk11_zulu"scp -r /etc/profile $node:/etcssh $node "source /etc/profile"scp -r /opt/trino/trino-server-359 $node:/opt/trino
doneecho "--------------Xync Data Done......----------------"修改Workers节点配置
node.properties修改node.id,与coordinator不同且唯一即可
config.properties修改coordinator=false
config.properties、jvm.config如果资源足够,端口也没有需要修改,可以忽略;
paratera129:
node.environment=trino_dev
node.id=ffffffff-ffff-ffff-ffff-fffffffffffe
node.data-dir=/opt/trino/trino-server-359/data
paratera130:
node.environment=trino_dev
node.id=ffffffff-ffff-ffff-ffff-fffffffffffd
node.data-dir=/opt/trino/trino-server-359/data
一键启停脚本
vim /opt/server.sh#! /bin/bash
EXE_MODE=$1
for node in "paratera128" "paratera129" "paratera130";
dossh $node "su - root -c \"/opt/trino/trino-server-359/bin/launcher ${EXE_MODE}\""
donechmod 777 /opt/server.sh
启停
[root@paratera128 opt]# ./server.sh start
--------------start Trino Node......----------------
Started as 2719
Started as 2920
Started as 2922
--------------start Trino Node Success......----------------安装trino cli客户端
trino-cli-359-executable.jar
下载连接:https://download.csdn.net/download/huxiang19851114/86248133
将jar包导入trino安装/bin目录下/trino-cli目录
[root@paratera128 bin]# mv trino-cli-359-executable.jar trino-cli
[root@paratera128 bin]# chmod 777 trino
[root@paratera128 bin]# ./trino-cli --server paratera128:10080 --catalog system --schema default
trino:default>我们可以通过:http://paratera128:10080/ui/访问trino的web ui。
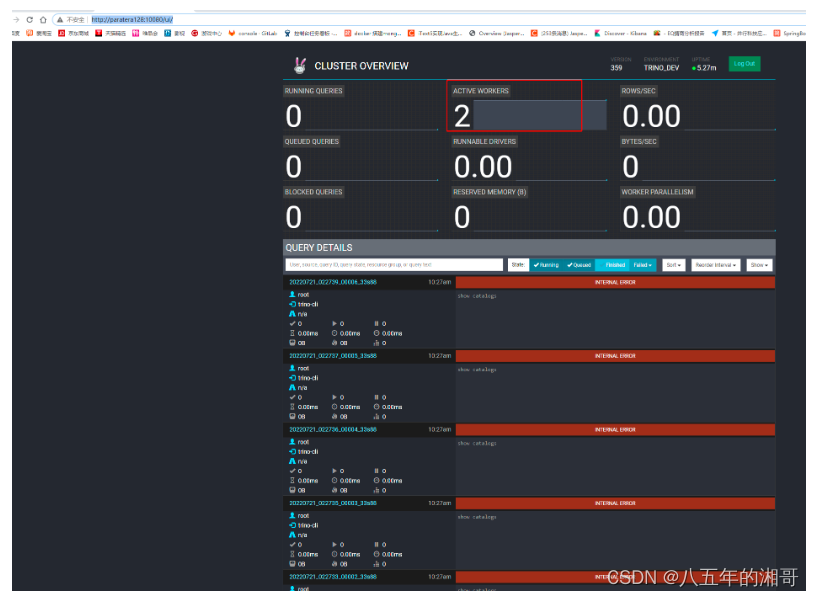
页面很low,现在因为没有任何任务执行,不是0就是空
Trino使用
连接MySQL
Connector
vim /opt/trino/trino-server-359/etc/mysql.propertiesconnector.name=mysql
connection-url=jdbc:mysql://182.92.67.160:3316?enabledTLSProtocols=TLSv1.2&useSSL=false
connection-user=root
connection-password=paratera
这种运行时的文件分发另外创建一个脚本
[root@paratera128 opt]# vim xync-setting.sh
#!/bin/bash
echo "--------------Start Xync Setting......----------------"for node in "paratera129" "paratera130";
doscp -r /opt/trino/trino-server-359/etc/catalog $node:/opt/trino/trino-server-359/etc
doneecho "--------------Xync Setting Done......----------------"[root@paratera128 opt]# chmod 777 xync-setting.sh
重启trino服务
[root@paratera128 opt]# ./server.sh restart
--------------restart Trino Node......----------------
Stopped 5697
Started as 5775
Stopped 8616
Started as 8690
Stopped 8490
Started as 8558
--------------restart Trino Node Success......----------------通过trino-cli查询connector:
[root@paratera128 bin]# ./trino-cli --server paratera128:10080
trino> show catalogs;Catalog
---------jmxmysqlsystem
(3 rows)Query 20220721_022740_00007_33s88, FINISHED, 2 nodes
Splits: 36 total, 36 done (100.00%)
47.75 [0 rows, 0B] [0 rows/s, 0B/s]
查询示例
查询MySQL connector 的数据库Schema信息
trino> show schemas from mysql;Schema
--------------------billing_orderconsoleinformation_schemajira-demojspxcmsjupyterservicemy_selfservicengbillingngbilling_testnoticeperformance_schemapush_web_chartselfservicestage_selfservicets_kbsuser_activity
(16 rows)Query 20220721_023220_00008_33s88, FINISHED, 3 nodes
Splits: 36 total, 36 done (100.00%)
9.04 [16 rows, 270B] [1 rows/s, 30B/s]
切换到数据库进行查询操作
trino> use mysql.console;
USE
trino:console> select * from user_info;id | name | email | real_email | phone | group_id | bonus_level | user_pref | unit | department | office | sex | region | street | h
--------------------------------------------------+----------------+---------------------SELF-0CmEFpMQd2d58yeyzSkQUwiSnBAI7pJp8N7WZJRRxqo | zhangyj | zhangyj@blsc.cn | NULL | NULL | NULL | NULL | 1 | NULL | NULL | NULL | NULL | NULL | NULL | NSELF-0UisYtyGwsZ4RqXmmVtXILrhheBvyswMzwiF085xDZE | zhangleia | zhangleia@blsc.cn | NULL | NULL | NULL | NULL | 1 | NULL | NULL | NULL | NULL | NULL | NULL | Ntrino:console> select count(1) from user_info;_col0
-------23
(1 row)Query 20220721_024807_00015_33s88, FINISHED, 2 nodes
Splits: 17 total, 17 done (100.00%)
12.93 [1 rows, 0B] [0 rows/s, 0B/s]灵魂拷问
如果仅仅从以上来看,我们费了半天劲,还是通过MySQL脚本来进行查询,有啥区别,意义何在?
我们来看看Trino内部是怎么操作的,我们指导MySQL有个Explain执行计划,同样的,Trino也有一个查询计划,查看查询计划:
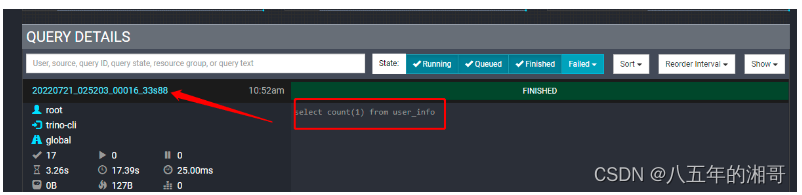
可以看到两台Workers节点参与查询的信息,可以看到130节点分摊了整个任务的16/17,而129节点是1/17
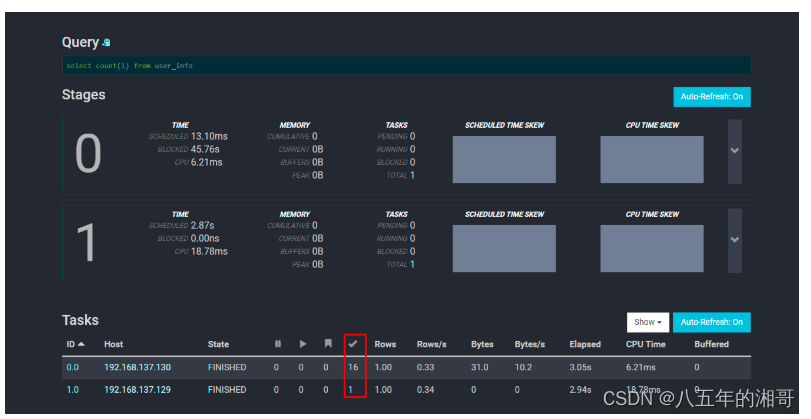
继续进入看详细的查询计划:
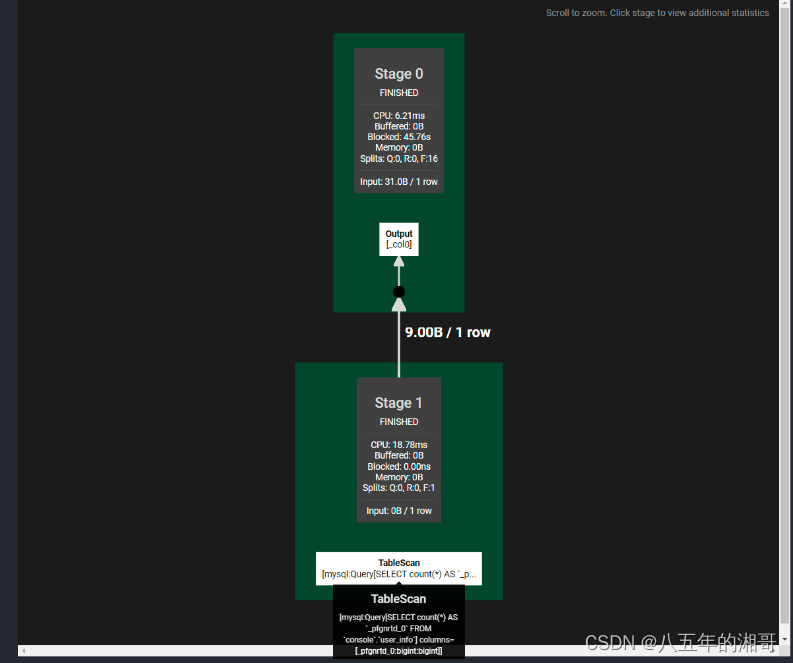
一共分为两个Stage。第一个执行的Stage是TableScan,第二个直接Output输出,所以查询的落脚点其实就在Stage1,我们点击进去看看
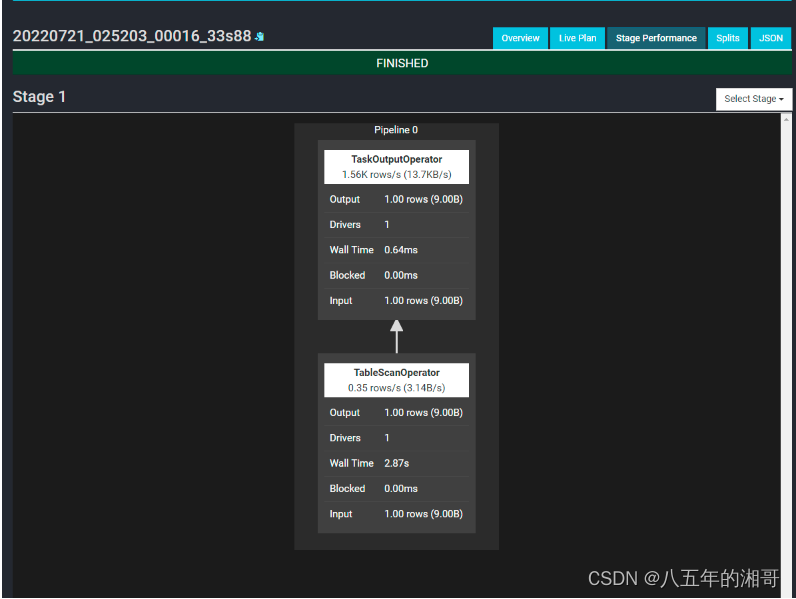
Table Scan并只拉取了一条数据,直接执行了sql语句,然后输出,是不是体现不出Trino查询引擎的强大,甚至完全没必要费这么大劲?
好了,我们来换个复杂点的查询操作:

一共分为4个Stage执行,对应查询Mysql就是4个任务,限于我本地环境只有两个Workers,且迫于财力,虚拟机分配到的内存(2G,1G,1G)和CPU(单核)资源有限,速度上看不出太多的优点,**灵魂拷问:同一个事情一个人做快还是分成好几个步骤,多个task去做更快?**当然,这个事情应该足够复杂!
可以看到Tasks 129,130分别有两个值为1的task,这个其实就是协调器通知的交互线程!
我们再看Live Plan图,原理其实很简单,他把这个SQL的操作拆成了三步:
第一步:穷举出两个关联查询表的数据
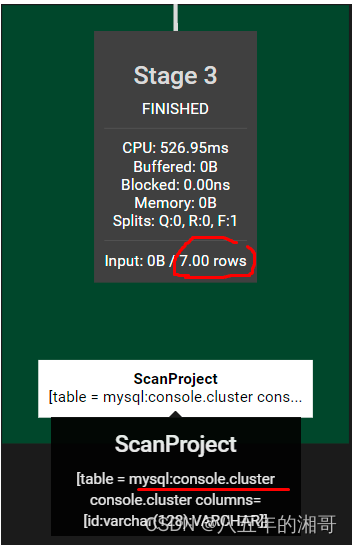
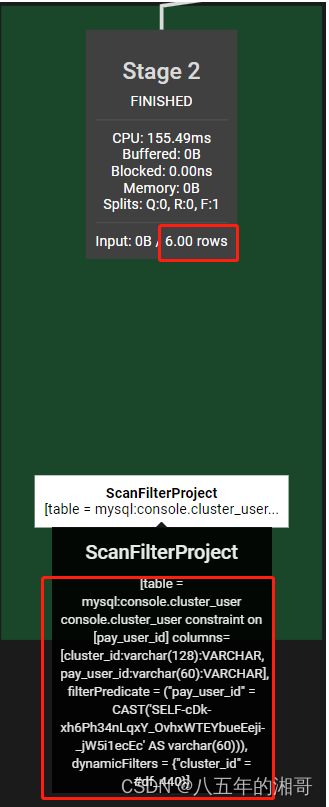
第二步:根据条件对两组数据进行聚合
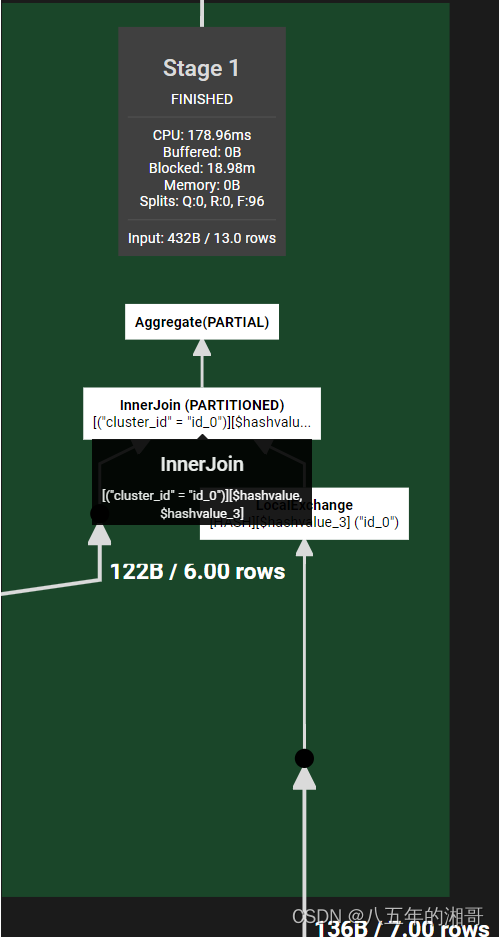
第三步:对聚合数据进行输出
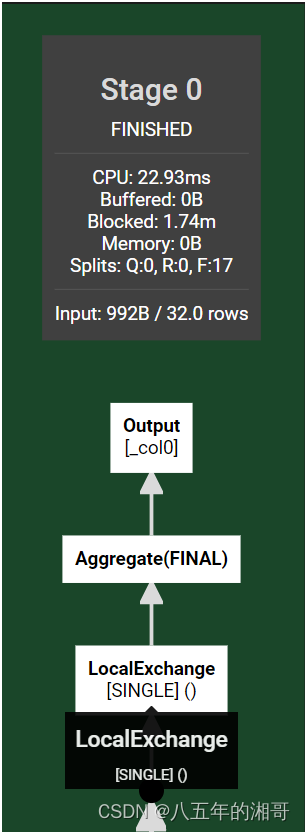
相当于Trino智能给你把查询脚本进行拆分,然后分布到不同的Worker节点进行操作!
Live Plan图不够详细的话,可以通过EXPLAIN计划命令查看
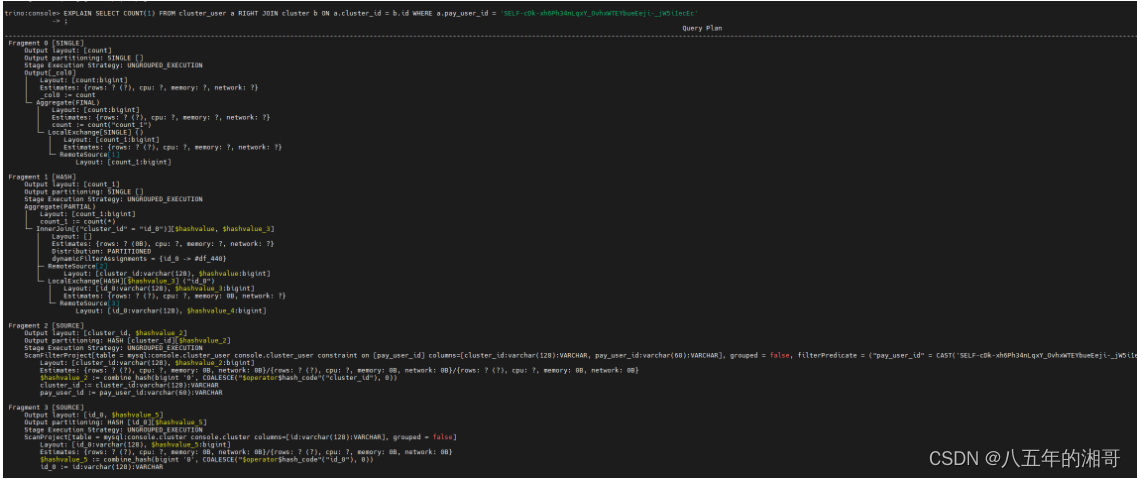
解读:
- 扫描 cluster_user表,Trino自动选择 cluster_id进行hash分区。并且拉取两个字段:cluster_id、$hashvalue_2,这一步包括where条件都是下推到MySQL进行的。
- 扫描 cluster表,按照id_0 hash分区,拉取了id,$hashvalue_5。
- 拉取完数据后,在本地按照hash值执行shuffle分区。然后执行INNER JOIN操作,按分区执行的------灵魂拷问,这一步还跟MySQL有关吗?
- 然后对分区的执行结果再聚合计算,计算并输出最终结果。
灵魂拷问:为什么要这么做,不要想得太深奥了,高端的食材往往只需要最简单的烹饪!同样,高深的设计往往都源于最基础的理论
最后来个图说明一下:

拓展
开启https访问
#1、生成 CA 证书私钥
openssl genrsa -out clustercoord.key 4096
#2、生成 CA 证书
openssl req -x509 -new -nodes -sha512 -days 3650 \-subj "/C=CN/ST=Beijing/L=Beijing/O=example/OU=Personal/CN=paratera.com" \-key clustercoord.key \-out clustercoord.cert#3、合并
cat clustercoord.key clustercoord.cert > ck.pem#4、检查合并密钥是否可用
[root@paratera128 etc1]# openssl rsa -in ck.pem -check -noout
RSA key ok#5、config.properties配置
http-server.https.enabled=true
http-server.https.port=8443
http-server.https.keystore.path=/etc/trino/ck.pem