文章目录
- 前言
- 笔记正文
- 关于模型评测的三个问题
- 为什么需要评测
- 我们需要测什么
- 怎么测试大语言模型
- 主流大模型评测框架
- OpenCompass
- 大模型评测领域的挑战
前言
本文是对于InternLM全链路开源体系系列课程的学习笔记。【OpenCompass 大模型评测】 https://www.bilibili.com/video/BV1Gg4y1U7uc/?share_source=copy_web&vd_source=99d9a9488d6d14ace3c7925a3e19793e
笔记正文
关于模型评测的三个问题
为什么需要评测
对于这么多的模型,需要标准去进行比较,这样才有利于普通用户、开发者、管理机构、产业界的使用。
我们需要测什么
对于大语言模型,需要评测的东西很多,如知识语言推理、长文本生成等。
怎么测试大语言模型
分为基座模型和对话模型、分为客观评测和主观评测、提示词工程。
主流大模型评测框架
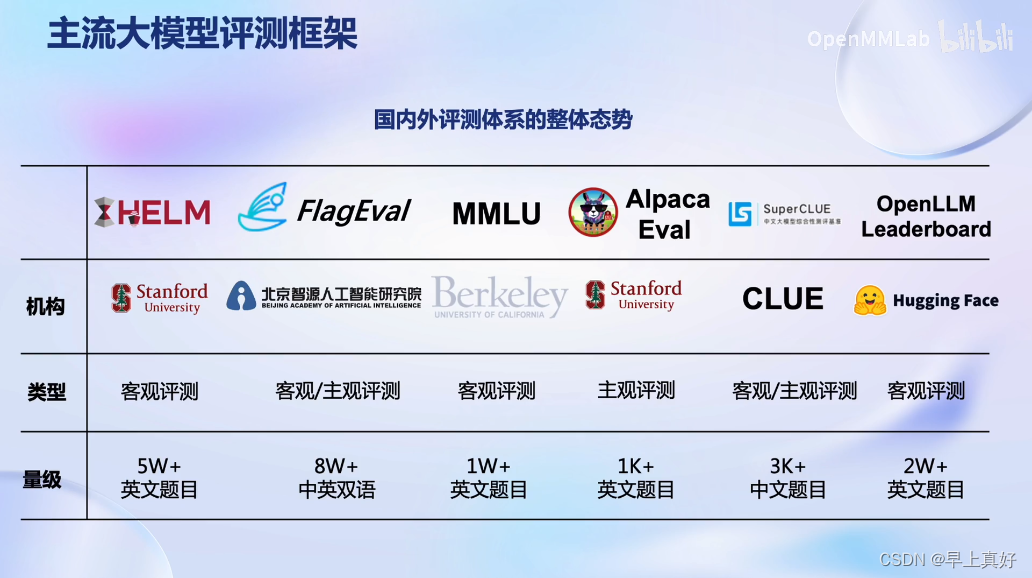
OpenCompass
而OpenCompass是一个比较全面系统的评测框架,受到meta的推荐,也是meta推荐的唯一一个国内评测框架
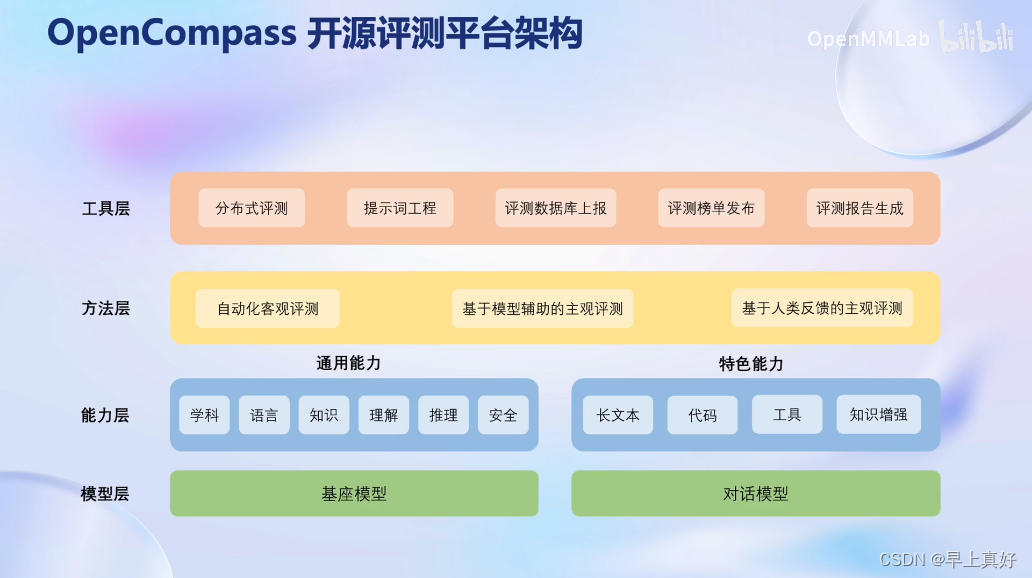
并且支持很多模型和很好的评测流水线设计。
同时除了上面的评测,也在进行前沿探索,如多模态领域和法律等
大模型评测领域的挑战
- 缺少高质量的中文评测集
- 难以准确提取答案
- 能力唯独不足
- 测试集混入训练集
- 测试标准各异
- 人工测试成本高昂
作业后面写



![洛谷: [CSP-J 2023] 小苹果](https://img-blog.csdnimg.cn/direct/293f61c556fd41ae91db94fbe81a77a3.png)