一.这段代码的主要目的是读取IMDB电影数据集,并进行一些基本的数据分析
# coding=utf-8
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt# 定义CSV文件的路径
file_path = './IMDB-Movie-Data.csv'# 使用pandas的read_csv函数读取CSV文件,返回一个DataFrame对象
df = pd.read_csv(file_path)# 打印出DataFrame的信息,包括索引、数据类型、内存使用等
# 注意这里是方法调用,所以后面有括号
print(df.info())# 计算'Rating'列的平均值
# 使用pandas的mean方法计算平均值
print(df['Rating'].mean())# 计算'Director'列中不同导演的数量
# 使用pandas的unique方法去重,然后计算长度
print(len(df['Director'].unique()))# 获取演员的人数
# 首先将'Actors'列中的字符串按逗号分割成列表
temp_actors_list = df['Actors'].str.split(',').tolist()
# 将嵌套列表展开成一个平面列表
actors_list = [i for j in temp_actors_list for i in j]
# 计算演员列表的长度,即演员的数量
actors_num = len(set(actors_list))print(actors_num)在这段代码中,我们首先读取了一个名为IMDB-Movie-Data.csv的CSV文件,并将其转换为一个pandas的DataFrame对象。然后,我们打印出DataFrame的信息。接着,我们计算了Rating列的平均值,并打印出来。然后,我们计算了Director列中不同导演的数量,并打印出来。最后,我们获取了演员的人数,通过将Actors列中的字符串按逗号分割成列表,然后计算了列表中不同演员的数量。
二.这段代码的主要目的是读取IMDB电影数据集,并绘制电影时长(Runtime)的分布直方图
# coding=utf-8
import pandas as pd
from matplotlib import pyplot as plt# 定义CSV文件的路径
file_path = './IMDB-Movie-Data.csv'# 使用pandas的read_csv函数读取CSV文件,返回一个DataFrame对象
df = pd.read_csv(file_path)# 打印出DataFrame的前1行
# print(df.head(1))# 打印出DataFrame的信息,包括索引、数据类型、内存使用等
# print(df.info)# 分析电影时长(Runtime)的分布情况
# 选择图形,直方图
# 准备数据
# 获取'Runtime (Minutes)'列的数据
runtime_data = df['Runtime (Minutes)'].values# 计算时长的最大值和最小值
max_runtime = runtime_data.max()
min_runtime = runtime_data.min()# 计算直方图的组数
# 假设我们希望每5分钟为一组
num_bins = (max_runtime - min_runtime) // 5# 设置图形的大小
plt.figure(figsize=(20, 8), dpi=80)# 绘制直方图
# bins参数设置组数,density参数设置为True表示归一化,即每个直方图的面积为1
# facecolor设置直方图颜色,alpha设置透明度
plt.hist(runtime_data, bins=num_bins, density=True, facecolor='blue', alpha=0.5)# 显示图形
plt.show()在这段代码中,我们首先读取了一个名为IMDB-Movie-Data.csv的CSV文件,并将其转换为一个pandas的DataFrame对象。然后,我们从DataFrame中提取了电影时长的数据。接着,我们计算了电影时长的最大值和最小值,并根据这两个值计算了直方图的组数。最后,我们设置了图形的大小,绘制了电影时长的分布直方图,并显示了图形。效果如下:
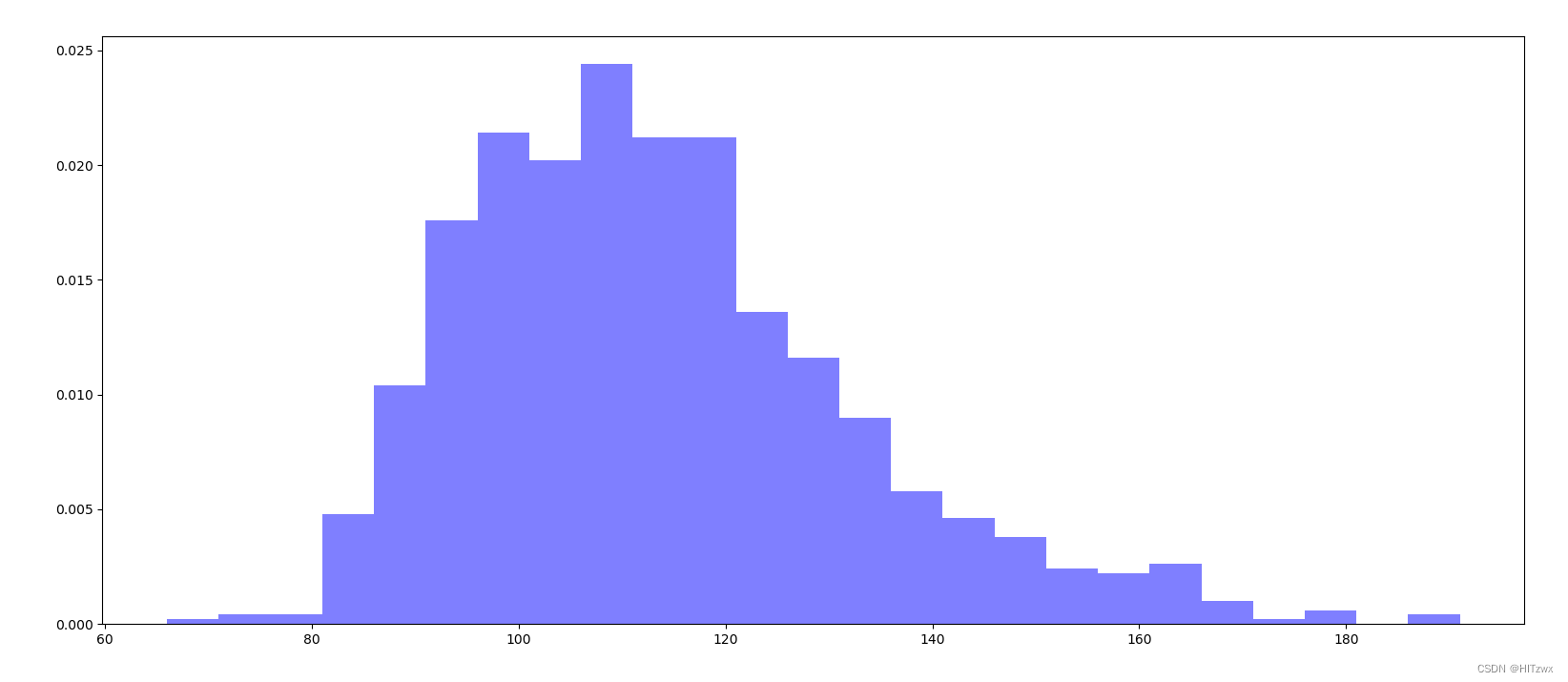
三.这段代码的主要目的是读取IMDB电影数据集,并绘制电影评分(Rating)的分布直方图
# coding=utf-8
import pandas as pd
from matplotlib import pyplot as plt# 定义CSV文件的路径
file_path = './IMDB-Movie-Data.csv'# 使用pandas的read_csv函数读取CSV文件,返回一个DataFrame对象
df = pd.read_csv(file_path)# 打印出DataFrame的前1行
# print(df.head(1))# 打印出DataFrame的信息,包括索引、数据类型、内存使用等
# print(df.info)# 分析电影评分(Rating)的分布情况
# 选择图形,直方图
# 准备数据
# 获取'Rating'列的数据
rating_data = df['Rating'].values# 计算评分的最大值和最小值
max_rating = rating_data.max()
min_rating = rating_data.min()# 计算直方图的组数
# 由于评分是10分制,我们希望每0.5分为一组
num_bins_list = [1.6]
i = 1.6
while i <= max_rating:i += 0.5num_bins_list.append(i)# 设置图形的大小
plt.figure(figsize=(20, 8), dpi=80)# 绘制直方图
# bins参数设置组数列表,density参数设置为True表示归一化,即每个直方图的面积为1
# facecolor设置直方图颜色,alpha设置透明度
plt.hist(rating_data, bins=num_bins_list, density=True, facecolor='blue', alpha=0.5)# 显示图形
plt.show()在这段代码中,我们首先读取了一个名为IMDB-Movie-Data.csv的CSV文件,并将其转换为一个pandas的DataFrame对象。然后,我们从DataFrame中提取了电影评分的数据。接着,我们计算了电影评分的最大值和最小值,并根据这两个值计算了直方图的组数列表。最后,我们设置了图形的大小,绘制了电影评分的分布直方图,并显示了图形。效果如下:
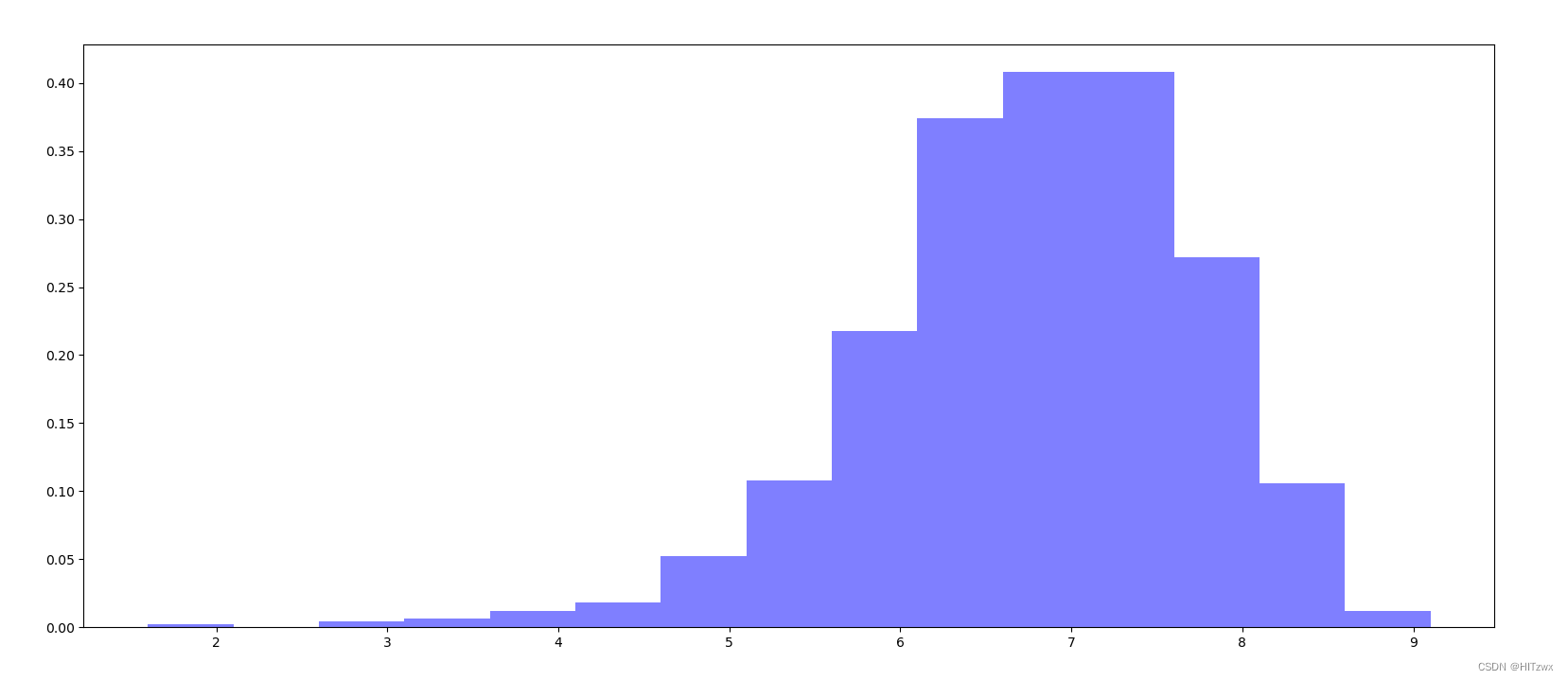
请注意,直方图的组数是通过一个循环动态生成的,每0.5分为一组,从1.6开始,直到最大评分值。这样可以确保每个组的范围是0.5分,符合10分制的电影评分。
上方代码涉及的IMDB电影数据集如下:
IMDB-Movie-Data文件大小:132.7 K|![]() https://wwt.lanzoum.com/ikyre1o643dc
https://wwt.lanzoum.com/ikyre1o643dc


![[BJDCTF2020]ZJCTF,不过如此](https://img-blog.csdnimg.cn/direct/9cf59fd755d645fc99ea69dc8006608b.png)