这两题算是链表的基础题,就遍历删除没啥特点,
83甚至不需要考虑第一个结点的特殊情况,属实是名副其实的easy了
LeetCode:21.合并两个有序链表之第一次的特殊情况-CSDN博客
83. 删除排序链表中的重复元素 - 力扣(LeetCode)
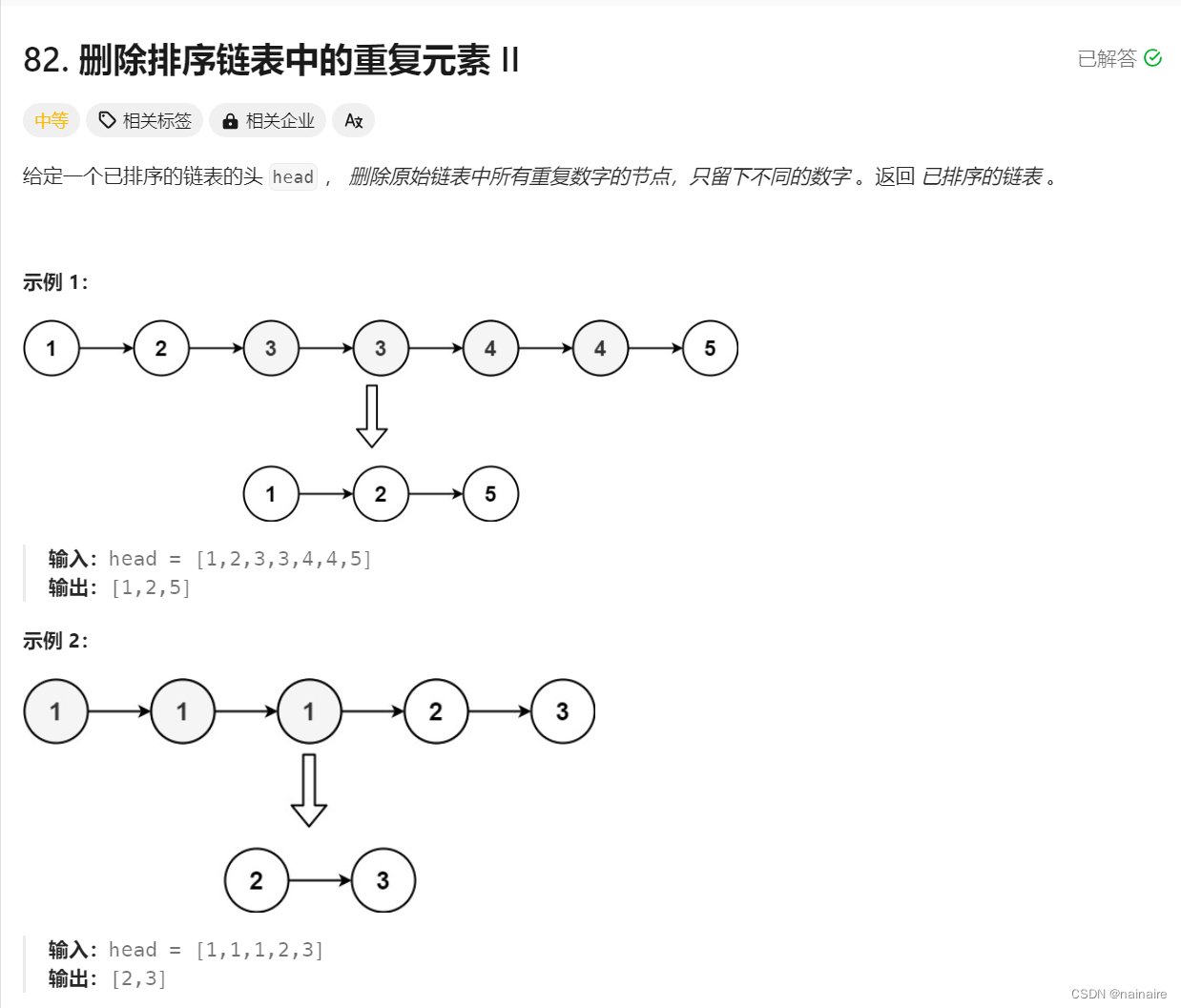
82. 删除排序链表中的重复元素 II - 力扣(LeetCode)
目录
题目:
编辑 思路:
代码+注释:
83:
82:
每日表情包:
题目:

 思路:
思路:
遍历,就看你做的熟不熟悉,快不快,由于是遍历,也没开辟新的空间,所以是时O(n),空O(1)
代码+注释:
83:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
struct ListNode* deleteDuplicates(struct ListNode* head) {struct ListNode* pfast = head, *pslow = head;//本来想写个双指针,不知道起什么名字,就起了个快慢,不过这里的实现更像是pslow 为pcur之意,pfast为ptmp之意//pcur是当前指针之意,ptmp为临时指针之意while(pslow && pslow->next){pfast = pslow->next;if(pfast->val == pslow->val){pslow->next = pfast->next;free(pfast);}else{pslow = pslow->next;}}return head;
}82:
/*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/
struct ListNode* deleteDuplicates(struct ListNode* head) {//打眼一看就知道影响到了第一个结点,//虽然内心一直想尝试一下造个二级指针,存head来玩,不过还是以后玩,现阶段先熟悉基本玩法//写个正规一点的malloc吧struct ListNode* ptmp = (struct ListNode*)malloc(sizeof(struct ListNode));assert(ptmp);struct ListNode* phead = ptmp;ptmp = NULL;phead->next = head;//现有phead 和ptmpstruct ListNode* pcur = phead;//这次相比于删除排序链表中的重复元素I就明现舒服多了//思路就是遍历删除,就是考虑要造几个变量,while(pcur && pcur->next && pcur->next->next){phead->val = pcur->next->val;if(pcur->next->val == pcur->next->next->val){while(pcur && pcur->next){ptmp = pcur->next;if(phead->val == pcur->next->val){pcur->next = pcur->next->next;free(ptmp);}else{break;}}}else{pcur = pcur->next;}}ptmp = phead->next;free(phead);return ptmp;
}每日表情包:

点赞点赞……点赞…求求啦!一个免费的赞可以让我出产更多的……水……文 。





![[BJDCTF2020]ZJCTF,不过如此](https://img-blog.csdnimg.cn/direct/9cf59fd755d645fc99ea69dc8006608b.png)


