链表
链表是一种基本的数据结构,是由一系列节点组成的集合。每个节点包含两个部分:值和指向下一个节点的指针。链表中的节点可以动态地添加、删除,其大小可以根据需要进行扩展或缩小。

链表通常用于处理不固定长度的数据结构,具有插入、删除等操作效率高的优点。与数组相比,链表在随机访问时性能较低,但在增删操作时更为高效。
那么链表和数组的区别是什么呢?
1存储方式:数组在内存中按照地址顺序依次存储,而链表通过节点之间的指针连接起来。
2访问方式:数组可以通过下标直接访问其中的元素,时间复杂度为O(1),而链表需要遍历整个链表才能找到特定节点,时间复杂度为 O(n)。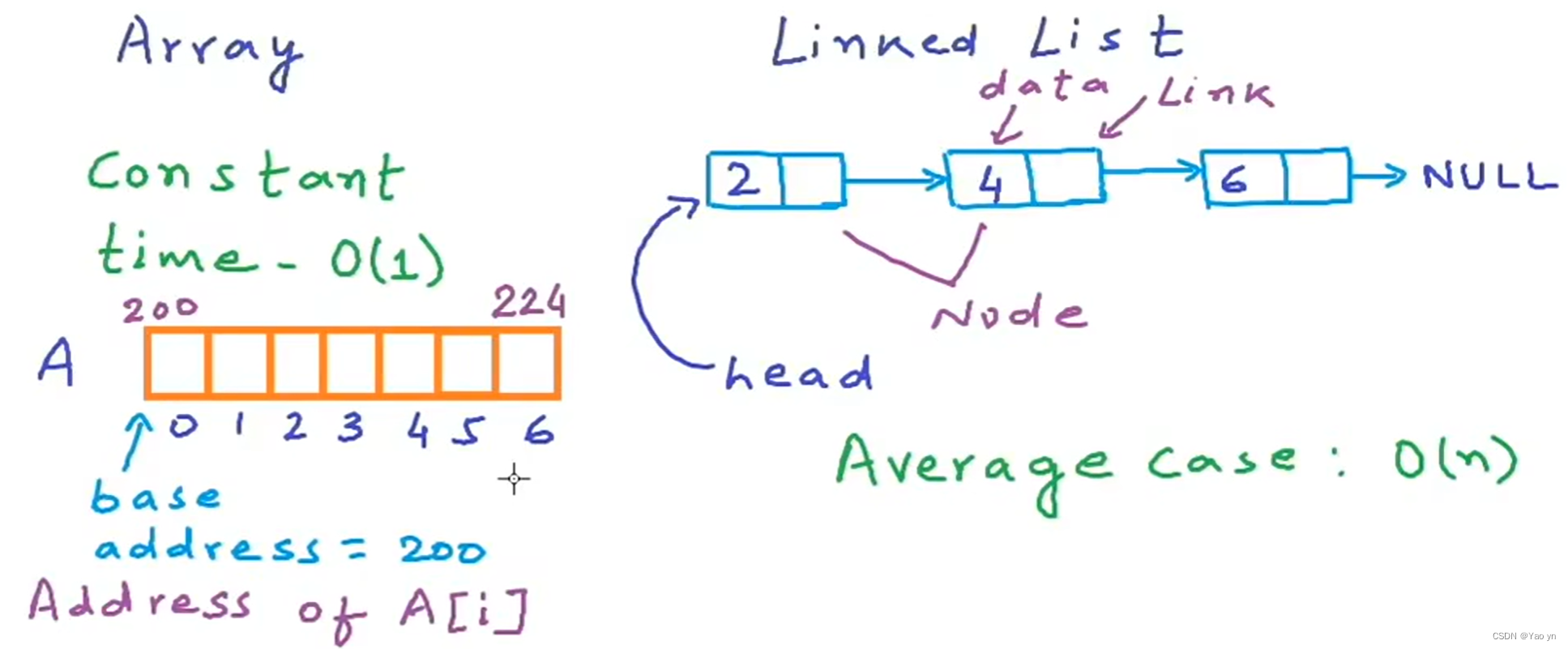
3大小固定性:数组有固定大小,创建时必须指定大小,不能动态增长或缩小。链表则没有这个限制,可以根据需要动态添加或删除节点,大小不受限制。
4插入与删除操作:向数组中插入或删除一个元素需要移动其他元素,开销较大;而链表可以在任意位置高效地进行插入和删除操作。
5内存分配方式:数组在声明时就会占用一段连续内存空间,而链表动态分配内存,在运行期间更加灵活。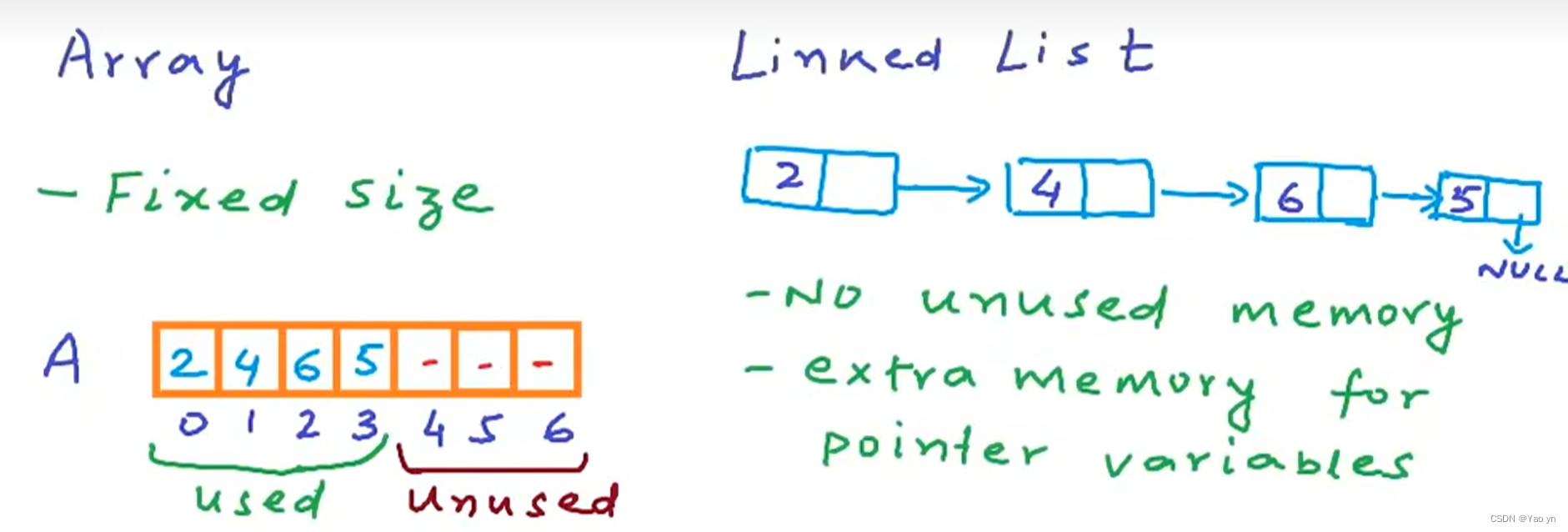
数组的优缺点:
支持快速随机访问
优 内存连续,预读性能好
易于实现和使用需要一段连续的内存空间,大小固定
缺 插入和删除操作需要移动其他元素
如果数组中有大量未使用的空间会浪费内存
链表的优缺点:
可以动态添加和删除节点,大小不受限制
优 插入和删除数据非常高效
不需要一段连续的内存空间随机访问效率低,需要遍历整个链表
缺 链接指针需要额外的空间存储
分配和释放内存需要时间和开销
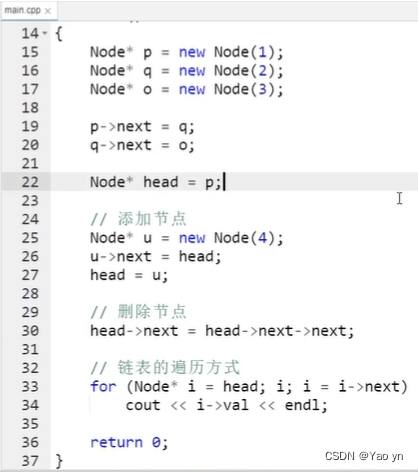
链表的C/C++实现
————————————将链表的逻辑视图映射到C/C++程序————————————
一、在尾部插入节点

struct Node
{int data;Node* link;
};struct Node* A;
A=NULL;
Node*temp=new Node(); //Node*temp=(Node*)malloc(sizeof(Node));
temp->data=2; //(*temp).data=2;
temp->link=NULL; //(*temp).link=NULL;
A=temp;temp=new Node();
temp->data=4;
temp->link=NULL; 另外,我们就可以通过一个循环来到达链表末端,实现到达最后一个节点的基本逻辑。(如下图)
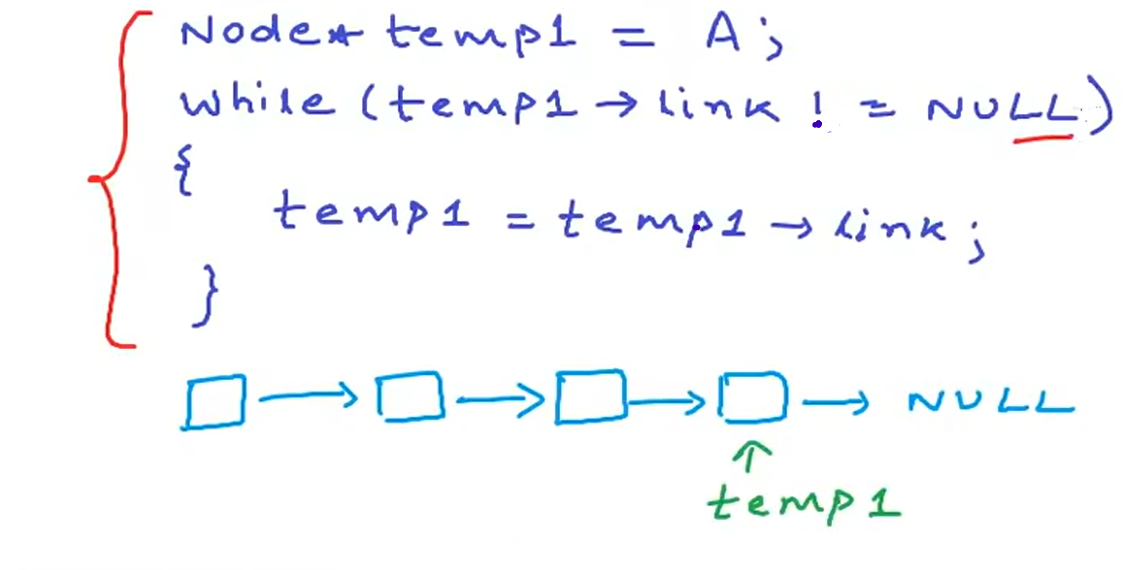
二、在头部插入节点
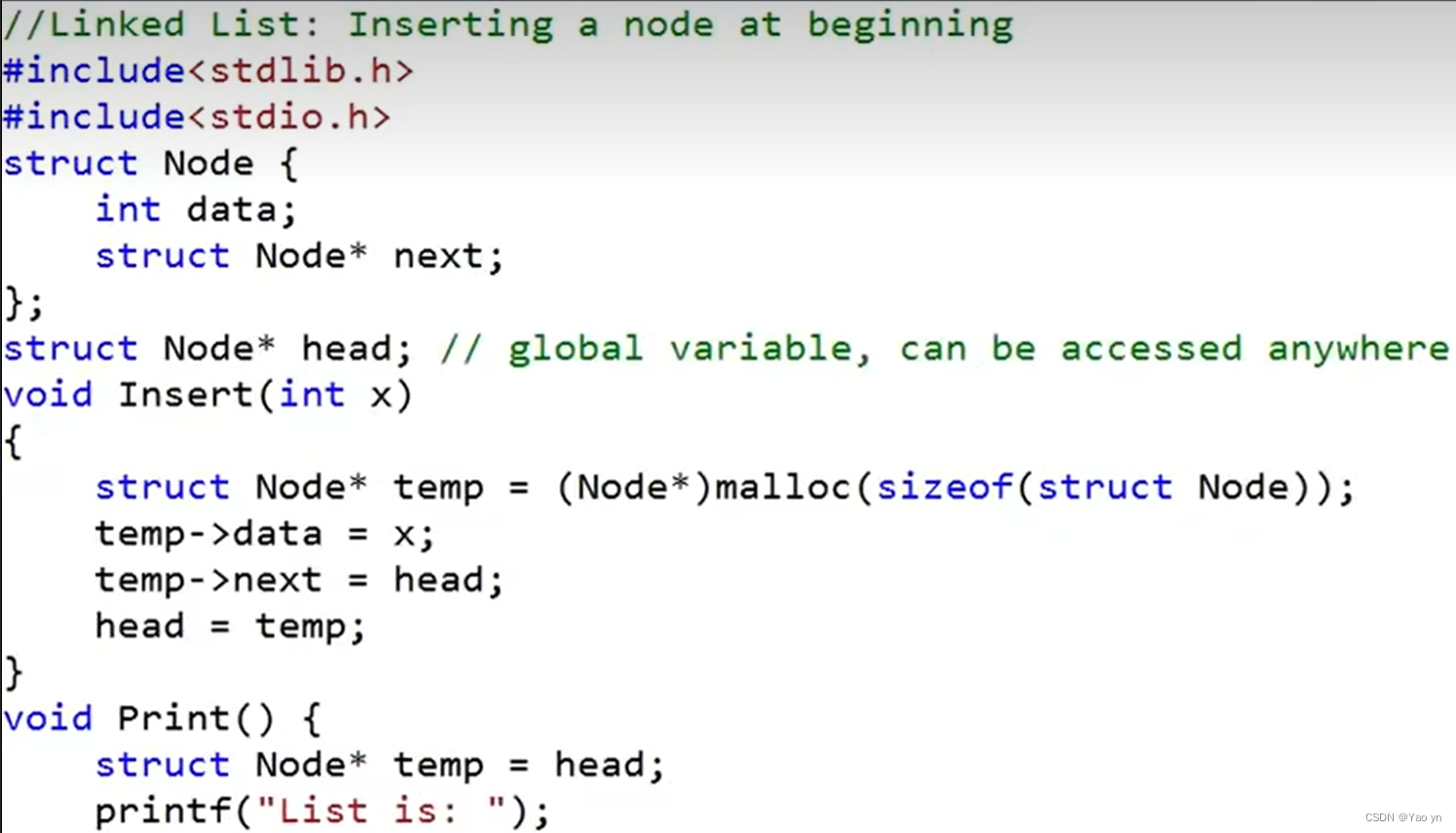

三、其它简易操作