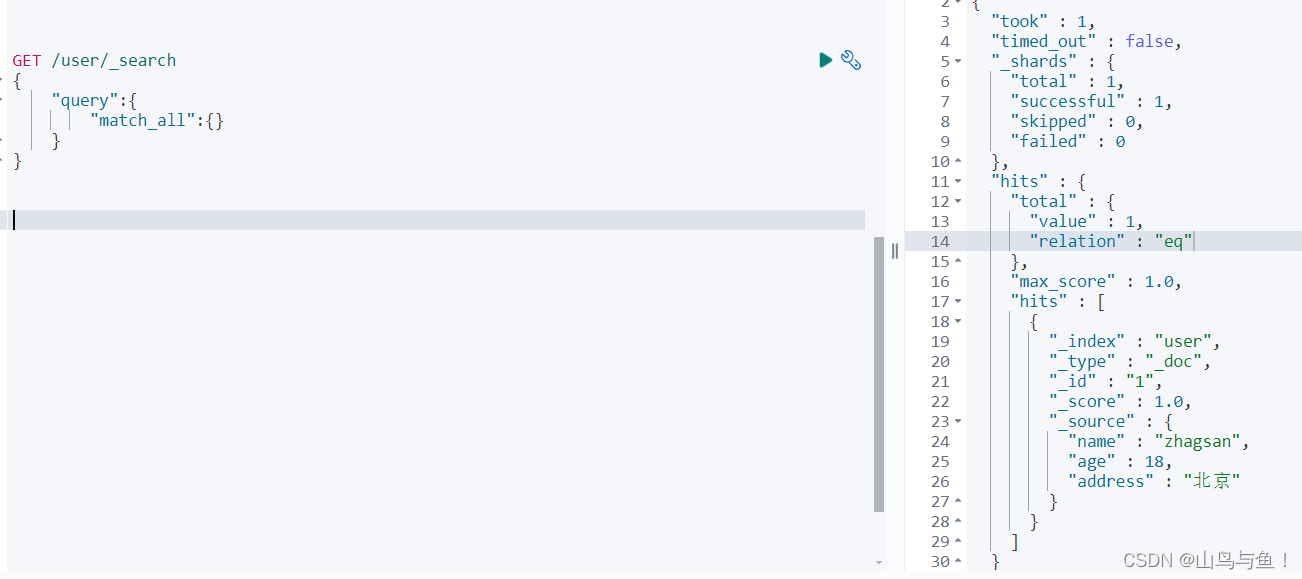
一、文章摘要
在本文中,我们提出了一个通用的隐写框架,用于神经网络实现隐蔽通信。首先,我们设计了一种基线隐写方法,在网络训练过程中将秘密数据嵌入到给定神经网络(封面网络)的卷积层中。对于包含秘密数据的网络(隐写网络),使用矩阵乘法对卷积层的参数进行编码以提取数据。在基线隐写方法的基础上,我们分别针对不同场景扩展了多源和多通道隐写方案,其中允许多个代理在发送方或接收方嵌入或提取秘密数据。同一侧的多个发送方或接收方不知道彼此的存在,保证了每对发送方和接收方之间通信的独立性和安全性。实验结果验证了基线方法的通用性和扩展方案的有效性,包括容量、安全性和鲁棒性。

二、绪论
随着人工智能的发展,深度学习已经成为计算机视觉、语音识别、自然语言处理等领域的关键技术之一[1]。卷积运算允许对特征进行连续滤波和叠加,这使得卷积神经网络成为深度学习中最重要的网络结构,并被广泛应用于各种神经网络中[2]。随着硬件的改进和数据集的细化,卷积神经网络模型如VGG (Visual Geometry Group)[3]、GoogleNet (Google Inception Net)[4]、ResNet (Residual network)[5]和DenseNet (Dense convolutional network)[6]被设计用于不同的任务[7]-[8]。
神经网络也被用于数据隐藏[9],其目的是保护网络模型的财产所有权(称为模型水印)[10],或通过网络模型传输秘密数据(称为模型隐写)[11]。对于模型水印,Darvish等[12]在神经网络特征映射中嵌入水印以抵抗重写攻击。同样,[13]提出了一种带有补偿机制的量化水印嵌入方案来抵抗重写攻击。文献[14]提出了一种用于保持完整性(深度)神经网络的脆弱水印方法。此外,学者们提出了触发集形式的水印方案,攻击者通过某种检测手段恶意破坏触发样本或网络,使触发样本失去与网络的相关性,无法用于验证版权[15]-[16]。Wu等人[17]提出了一种深度神经网络的数字水印框架,该框架对网络进行训练,使生成的图像包含水印信息。
模型隐写与模型水印的区别在于:模型水印将模型的水印信息(标识财产所有权)嵌入到模型中,以保护模型所有者的知识产权。无需刻意隐瞒水印信息的存在,只要能正确提取嵌入的水印信息,不影响封面模型的正常使用即可。此外,也不必追求大的嵌入容量,只要容量能容纳水印信息即可。与模型隐写不同,模型隐写侧重于秘密数据的隐蔽传输,其目的是避免引起第三方的注意。隐藏和嵌入能力是最重要的。
云服务的广泛使用使得模型隐写的使用具有巨大的潜力。如图1所示,发送者将隐写网络伪装成一个使用密钥执行常规机器学习任务的正常模型,并将其上传到云端,如GitHub模型池、Google Drive等。接收方可以从云端下载隐写网络,并使用相应的密钥提取秘密数据。没有密钥的普通客户也可以下载隐写网络来执行常规的机器学习任务。目前,学者们已经对模型隐写进行了一些研究。文献[18]利用后门技术对目标模型下毒,设计了一种方案,可以从模型的输出中提取附加信息,使下毒的模型能够正常执行常规任务。在[19]中,可以将秘密图像嵌入到封面神经网络中。对原始图像集的概率密度函数进行建模。然后,将特定位置的秘密图像嵌入到原始图像集的概率分布中,从而将图像隐藏在神经网络中。在[20]中,模型隐写是通过选择对秘密任务重要而对常规任务不重要的滤波器并设计部分参数优化策略来实现的。它允许包含秘密的网络用于执行常规的机器学习任务,并允许拥有密钥的接收者提取秘密信息。

图1 模型隐写的应用场景
此外,上述方法都是在现有的单源(一个发送方)和单通道(一个接收方)隐写框架中提出的。在某些情况下,例如,在命令分发中,指挥官(发送者)打算将不同的命令(秘密数据)传递给多个军官(接收者)。或者,多个官员(发送者)向官员(接收者)发送不同的消息(秘密数据)。秘密传输应立即进行,以免被怀疑。因此,需要多通道和多源隐写方案。Wang等人[11]提出了一种针对CapsNet的多通道隐写方案,该方案能够向多个接收者传输不同的秘密数据。在[21]中,提出了一种多源隐写方案,该方案允许多个发送方在AlexNet中嵌入秘密数据[22]。上述方案考虑了多通道和多源隐写,但没有足够的可扩展性。此外,这些方案都是针对特定的神经网络设计的,通用性有待提高。
在本文中,我们提出了一个隐写框架,它可以推广到具有满意嵌入容量的卷积神经网络,而不是特定的网络。数据嵌入的操作是在模型训练过程中使用嵌入键来实现的。因此,可以保证封面模型的原始任务的满意性能。在接收端,可以使用相同的密钥提取秘密数据,从而防止冒充嵌入和窃取数据。此外,无需向接收方传输除嵌入密钥外的附加辅助信息。
在此框架的基础上,我们分别为多通道和多源隐写扩展了两种隐写方案。在多源方案中,多个发送方可以通过同一个神经网络传输不同的秘密数据。各个发送者在网络中重叠的位置嵌入数据,因此无法确认彼此的存在。发送方通过嵌入密钥将秘密数据嵌入到神经网络中,使得非源发送方或攻击者无法冒充发送方数据。在多通道方案中,接收方可以使用相应的嵌入密钥提取数据。其余的数据无法获得。值得注意的是,在上述方案中,多个发送方或多个接收方是相互独立的,没有优先级和授权。因此,它也具有更好的保密性,防止数据或密钥泄露。
本文的创新点和贡献总结如下:
(1)我们提出了一个通用的隐写框架,它可以应用于大多数卷积神经网络,而不是特定的模型[11,21]。秘密数据是在封面模型的训练过程中嵌入的,而不是在训练后修改网络参数[23,24]。因此,可以保证原始模型任务的性能。可以使用相应的密钥提取秘密数据,不需要额外的解码网络。
(2)提出的框架可以扩展到多源/多通道的解决方案,而不是只满足单一的应用场景。在多源方案中,多个发送方可以通过同一个神经网络传输不同的秘密数据。每个发送方使用相应的嵌入密钥嵌入数据,因此攻击者或非源发送方无法获取秘密数据。在多通道方案中,多个接收方可以通过同一神经网络提取不同的秘密数据。每个接收方使用相应的密钥提取自己的秘密数据,其余数据不可用。
(3)大量的实验表明,我们的方法可以推广到卷积神经网络,并且可以达到5000比特的最大嵌入容量。AlexNet在MNIST数据集上训练后,嵌入容量达到现有方法的四倍,同时确保了更好的安全性和鲁棒性。
三、提出的方法
在本节中,我们首先提出了提出的基线隐写框架,该框架是为卷积层设计的,因此可以普遍应用于卷积神经网络。然后,我们讨论了基线框架的可扩展性,并分别为多发送方和多接收方扩展了两种隐写方案。
3.1 基本框架
在本小节中,我们将提出一个模型隐写框架。该框架是针对神经网络的卷积结构设计的,因此可以推广到卷积神经网络。在下一小节中,我们将讨论框架的可扩展性,并给出两种扩展方案。
我们的目标是设计一个可以推广到神经网络的隐写框架。由于卷积层在各种神经网络中得到了广泛的应用,所以我们的框架是为卷积神经网络设计的。卷积层是通过卷积操作(类似于图像处理中的“过滤操作”)来完成的,卷积核(权重)作为过滤器。一般的CNN网络使用四维卷积核wnch*w,分别对应卷积核数、通道数、高度和宽度。卷积层旨在保持输入和输出特征图的多维形状一致,保留数据的重要空间信息,并允许网络更好地理解具有形状(如图像)的数据。与全连接层相比,卷积层的输出是由多个通道和卷积核运算得到的复合结果。
具体来说,我们降低了每个卷积核的维数。对单个通道的卷积核矩阵Wh*w进行平均,以保持卷积核参数的整体数据特征。同样,对于一个四维卷积核,我们可以得到承载给定秘密数据的封面序列w^,如图2所示。

图2 获取封面序列^w
在典型的隐写方法中,秘密数据是通过基于矩阵乘法的矩阵编码隐藏在封面介质中。我们还通过矩阵乘法将秘密数据编码到封面序列中。对于t位的秘密数据M = [m1,m2,…,mi,…], mt]∈{0,1}t,序列w = [w1,w2,…,wn*c]使用矩阵乘法编码:

式中,H∈{0,1}(n×c)×t为使用嵌入密钥k生成的嵌入矩阵。y = [y(1), y(2),…, y(i),…,y(t)]是编码后的输出向量。由于秘密数据M是二进制的,我们使用sigmoid函数将输出向量的值限定为[0,1],最后得到y = [y^(1), y(2),…,y(i),…,y^(t)]]∈[0,1]t。需要注意的是,输出向量值域应尽可能接近于M,这是通过在训练过程中在式(7)和式(8)中添加额外的正则化项来实现的。
在现有的隐写框架中,嵌入的密钥可以通过具有安全密钥的阈下通道传输[31]。共享密钥的秘密传输对于所有现有的隐写方案都是必要的。由于嵌入矩阵H是未知的,没有嵌入密钥就无法提取秘密数据。
接收方可以使用已知的嵌入矩阵H和训练好的封面序列w^'提取秘密数据,如式(3)和式(4)所示:

方程(3)中的输出向量y’应该近似于秘密数据M,因为我们在训练过程中添加了正则化项,以确保它们尽可能接近。对y’进行舍入运算后,提取的秘密数据M '如式(4)所示。更简单地说,M’的提取可以表示为:

其中u(x)是阶跃函数。
另外,我们设置提取误差e来评价网络的嵌入能力,即计算提取的秘密数据M′与嵌入的秘密数据M的差值,定义为:

当e = 0时,表示可以正确提取所有的秘密数据。当秘密数据能够正确提取时,网络的最大嵌入量即为嵌入容量。
为了有效地对秘密数据进行编码,在网络训练过程中考虑了两个额外的正则化项:

其中使用Loss1作为正则化项,使y^尽可能接近m。由于sigmoid函数在y(i) = 0附近收敛缓慢,导致一些秘密数据总是难以提取。因此,我们将正则化项Loss2设置为提高y(i) = 0附近的收敛速度,减少提取误差。
隐写网络的总损耗定义为两个分量:

其中Losso为源网络的损失,以保证神经网络分类任务的检测精度,Losse有助于隐写任务。ɑ和β是额外的超参数。ɑ用于调整Losso和Losse的权重。因为隐写术和分类之间是有取舍的。因此,适当的ɑ值可以保证良好的嵌入能力和检测精度。β用于调整Loss1和Loss2的权重。较大的β值会导致梯度爆炸,不利于提取误差的收敛。较小的β值可能导致部分秘密数据无法正确提取。我们将在附录中讨论Losse的梯度,以演示其对数据隐藏任务的影响。
3.2 扩展方案
在现有的隐写框架中,只考虑一个发送方(单一源)和一个接收方(单一通道):将秘密数据M嵌入到封面序列w中,在训练神经网络时,通过正则化项对参数w进行修改。考虑将多个秘密数据嵌入同一个w^中,式(1)可扩展为:

其中嵌入矩阵{H1,H2,…,Hn}对应密钥{K1,K2,…,Kn}。根据我们的方案,密钥将分别分配给使用密钥嵌入或提取秘密数据的n个发送方或接收方。{y1,y2,…,yn}为编码后的输出向量,经过sigmoid映射后,输出{y1,y2,…,y^n}。秘密数据{M1,M2,…,Mn}可由式(5)直接提取。注意,对于某个封面序列,网络的嵌入容量是恒定的,因此,多个秘密数据的嵌入容量之和应与网络一致。也就是说,多个秘密数据将总容量分成多个部分,而总容量保持不变。
在上述隐写框架的基础上,我们扩展了两种对称的隐写方案,分别适用于多发送方(多源)方案和多接收方(多通道)方案。隐写框架允许通过(11)中的一组方程将多个秘密数据嵌入到封面序列中。
对于同一部分,两种方案都要求在同一网络中嵌入多个秘密数据。这些数据应该嵌入在网络中的重叠位置,以确保只有源发送方和接收方或目标接收方和发送方知道这些数据。这是因为非源发送者或非目标接收者可能成为潜在的攻击者或泄密者。
对于不同的部分,在多源方案中,应该分别为相应的源发送方分配多个密钥。接收方应该拥有所有的密钥并提取相应的秘密数据。在多通道方案中,需要为相应的目标接收方分配多个密钥,发送方拥有所有密钥并嵌入相应的秘密数据。
3.2.1 多源方案
多源隐写方案架构如图3所示。它允许多个发送者将多个不同的秘密数据嵌入到封面序列w中,并通过公共通道(例如,上传到云端)将秘密CNN传输给接收方。

图3 多源隐写方案
在发送方,每个发送方在网络训练时被分配相应的嵌入密钥来嵌入秘密数据,并将秘密数据嵌入到网络的重叠位置。在有n个发送方的情况下,第i个发送方可以使用密钥Ki嵌入秘密数据Mi。如果没有相应的密钥,则无法知道其余的数据。而且,没有相应的密钥Ki,秘密数据Mi就无法嵌入到网络中。因此,非源发送方(除拥有Ki的第i个发送方之外的发送方)不能冒充源发送方(拥有Ki的第i个发送方)向接收方发送秘密数据。一个包含秘密数据{M1,M2,…,Mn}的隐写CNN可以上传到云端,并伪装成执行常规机器学习任务的模型。没有对应密钥的普通用户也可以下载隐写 CNN来执行分类任务。在接收方,接收方应授权所有密钥{K1,K2,…, Kn}。通过式(5)可以使用密钥提取出所有对应的秘密数据。因此,在该方案中,只有源发送方和接收方知道秘密数据Mi。保证了每个源发送方和接收方之间通信的独立性和安全性。
3.2.2 多通道方案
对称地,所提出的多通道隐写方案的架构如图4所示。与多源方案相比,在该方案中,接收方有多个代理,因此对应的秘密数据由多个接收端提取。

图4 多通道隐写方案
在发送方,发送方应该被授权使用所有密钥{K1,K2,…, Kn}嵌入相应的秘密数据{M1,M2,…,Mn}。在接收方,每个接收方都被分配了对应的密钥,使用式(5)提取其秘密数据。对于n个接收方,第i个接收方可以使用密钥Ki提取秘密数据Mi。但是,对于其余的数据,如果没有相应的密钥,则无法知道它。因此,对于秘密数据Mi,它不能被非目标接收者(除第i个拥有密钥Ki的接收者之外的接收者)提取。此外,完整的封面序列w^可供所有接收方提取数据,使接收方无法发现秘密数据的其他部分的存在。综上所述,在该方案中,只有目标接收方(第i个接收方拥有Ki)和发送方知道秘密数据Mi。保证了发送方与目标接收方之间通信的独立性和安全性。
四、实现细节
环境设置 所有实验均由TensorFlow实现,并在Windows 10系统上使用NVIDIA GeForce RTX 1080 Ti GPU在Python 3.7环境下进行训练。
数据集 在实验中,我们使用MNIST (Modified National Institute of Standards and Technology Database)[32]和CIFAR-10 (Canadian Institute For Advanced Research)[33]对卷积神经网络模型执行分类任务。MNIST手写数字数据集由60,000个训练和10,000个测试灰度图像组成,维度为28×28像素,平均分为10类。CIFAR-10数据集由50,000个训练图像和10,000个测试图像32×32平均分为10个类。
CNN建模训练设置 CNN模型的训练设置如表1所示,包括数据集、损失项Losso类型、优化器、迭代等。式(9)中的损失项Losso采用交叉熵作为损失函数。Adam优化器[34]和动量优化器[35]分别用于MNIST和CIFAR数据集。对于MNIST数据集,我们采用少量随机数据集的随机训练,以减少计算开销并最大限度地学习数据集的整体特征。例如,ResNet18在MNIST数据集上训练,我们每次随机抓取50批数据点,并进行3000次迭代训练。对于CIFAR-10数据集,我们采用批处理训练,将所有数据集分成多个批次进行训练,并在每个批次中选择“batchsize”的数据,直到训练出整个数据集。例如,在CIFAR-10数据集上训练的ResNet18,我们每次选择500批数据点,并对一个epoch进行100次迭代训练(整个数据集训练一次)。
五、结论
本文提出了一种常用的卷积神经网络隐写方法,并在此基础上提出了两种扩展方案,分别是多源方案和多通道方案。在该方法中,数据嵌入过程与网络训练一起完成,保证了网络本身的性能。可以使用相应的密钥提取数据,而无需传输额外的解码网络。在多源方案中,多个发送方可以通过同一个神经网络传输不同的秘密数据。每个发送方使用一个唯一的密钥来嵌入秘密数据,并且不知道其他发送方的存在。对称地,在多通道方案中,发送方可以通过同一神经网络向多个接收方传输不同的秘密数据。每个接收方使用唯一的密钥来嵌入秘密数据,并且不知道其他接收方的存在。因此,在扩展方案中保证了每对发送方和接收方之间通信的安全性和独立性。大量的实验结果表明,该方法可以推广到卷积神经网络中,具有良好的嵌入能力、安全性和鲁棒性。在扩展方案中,增加源或通道不会降低网络的总嵌入容量和网络性能,安全性与基线方法基本相同。
未来,可以开发以扩大来源或通道为重点的解决方案。这是因为云服务允许多个用户自由上传和下载神经网络。此外,具有多通道或多源的扩展方案意味着大的总嵌入容量。因此,可以开发出广义的大容量嵌入方案。
论文地址:A general steganographic framework for neural network models
没有公布源码