前言
大家好,我是秋意零。
在上一篇中,我们讲解了 StatefulSet 的存储状态;我们发现,它的存储状态,就是利用了 PV 与 PVC 的设计。StatefulSet 自动为我们创建 PVC 并且以 <pvc-name>-<pod-name>-<编号>命名,从而始终与 Pod 编号名一致的绑定。
需要注意的是:StatefulSet 的“滚动更新”是从最后一个 Pod 开始的,为了不破坏拓扑状态。如:主从数据库,主的 Pod 编号是 0,后面是从,如果先更新主数据库 0 编号,那么后面的从数据库就会出现问题。
StatefulSet 的“滚动更新”还允许我们进行更精细的控制,比如:金丝雀发布(Canary Deploy)或者灰度发布,这意味着应用的多个实例中被指定的一部分不会被更新到最新的版本。
StatefulSet 的 partition 字段设置为 2,那么编号小于 2 的 Pod 是不会进行镜像更新的。
$ kubectl patch statefulset mysql -p '{"spec":{"updateStrategy":{"type":"RollingUpdate","rollingUpdate":{"partition":2}}}}'
statefulset.apps/mysql patched今天的内容是 DaemonSet 控制器。
👿 简介
- 🏠 个人主页: 秋意零
- 🧑 个人介绍:在校期间参与众多云计算相关比赛,如:🌟 “省赛”、“国赛”,并斩获多项奖项荣誉证书
- 🎉 目前状况:24 届毕业生,拿到一家私有云(IAAS)公司 offer,暑假开始实习
- 🔥 账号:各个平台, 秋意零 账号创作者、 云社区 创建者
- 💕欢迎大家:欢迎大家一起学习云计算,走向年薪 30 万

系列文章目录
【云原生|探索 Kubernetes-1】容器的本质是进程
【云原生|探索 Kubernetes-2】容器 Linux Cgroups 限制
【云原生|探索 Kubernetes 系列 3】深入理解容器进程的文件系统
【云原生|探索 Kubernetes 系列 4】现代云原生时代的引擎
【云原生|探索 Kubernetes 系列 5】简化 Kubernetes 的部署,深入解析其工作流程
更多点击专栏查看:深入探索 Kubernetes
正文开始:
- 快速上船,马上开始掌舵了(Kubernetes),距离开船还有 3s,2s,1s...

目录
前言
系列文章目录
一、DaemonSet 介绍
Daemon Pod 的意义
二、DaemonSet 的“过人之处”
三、DaemonSet 的镜像版本如何维护
一切皆对象
总结
一、DaemonSet 介绍
DaemonSet 的主要作用,是在集群中运行一个类似守护进程的 Pod 服务(Daemon Pod)。
DaemonSet 管理 Pod 的三个特性:
- 这个 Pod 运行在 Kubernetes 集群中,每一个节点(Node)上;
- DaemonSet 只会在每个节点创建一个 Pod(Daemon Pod);
- 集群中有新节点加入时,DaemonSet 也会马上为这个新节点创建一个 Pod;当然当节点从集群中移除时,这个 Pod 也会回收。
实际上就是为每个节点只创建一个 Pod,就是像所谓的守护程序。
Daemon Pod 的意义
DaemonSet 机制听起来很简单,但是 Daemon Pod 的意义确实是非常重要的。如下:
- 1.各种网络插件的 Agent 组件,用来处理这个节点上容器网络,必须运行在每一个节点上;
- 2.各种存储插件的 Agent 组件,用来在这个节点上挂载远程存储目录,操作容器的 Volume 目录,也必须运行在每一个节点上;
- 3.各种监控组件和日志组件,负责这个节点上的监控信息和日志搜集,也必须运行在每一个节点上。
需要注意的是,DaemonSet 运行的时机,很多时候比整个 Kubernetes 集群出现的时机都要早。
这个乍一听起来可能有点儿奇怪。但其实你来想一下:如果这个 DaemonSet 正是一个网络插件的 Agent 组件呢?
- 首先要知道,在部署 Kubernetes 集群时,没有网络插件,节点的状态就会是 NotReady 状态(NetworkReady=false)。
- 这个情况下,普通 Pod 是不能运行在集群中的。而为了让集群能正常运行 Pod 那么就需要使用 DaemonSet。
这里或许还有一个疑问,就是普通 Pod 在这种 NotReady 情况下不能运行,那 DaemonSet 就能运行吗?
二、DaemonSet 的“过人之处”
要理解 DaemonSet 的“过人之处”。首先,要了解 DaemonSet 的工作过程。
来看一个 DaemonSet 的 YAML 文件:
- 可以看到,DaemonSet 的 YAML 与 Deployment 的 YAML 文件可以说是几乎一模一样,只不过是没有 replicas 字段。因为 DaemonSet 每个节点只需要一个副本,replicas 字段就没有必要存在了。
apiVersion: apps/v1
kind: DaemonSet
metadata:name: example-daemonsetlabels:app: example
spec:selector:matchLabels:app: exampletemplate:metadata:labels:app: examplespec:tolerations:- key: node.kubernetes.io/unreachableoperator: Existseffect: NoExecutecontainers:- name: example-containerimage: nginx:latest那么,DaemonSet 又是如何保证每个 Node 节点上有且只有一个被管理的 Pod 的呢?这是一个典型的“控制器模型”能够处理的问题。
以上面 YAML 为例:
1.DaemonSet Controller,首先从 Etcd 中获取所有 Node 列表,然后遍历所有的 Node,查找检查是否有 app: example标签的 Pod 在运行。
这个查找检查过程有三种情况:
- 没有这种 Pod,那就需要在该 Node 节点上创建一个 Pod;
- 有这种 Pod,需要判断是否为 1,大于 1 就删除;
- 正好有这种 Pod,说明这个节点正常。
2.当查找到有这种 Pod 时,删除节点上多余的 Pod,很容易;当查找到没有这种 Pod 时,如何让 Pod 在指定 Node 节点上创建呢?通过两种方式:
2.1. 配置 DaemonSet 的节点亲和性(nodeAffinity)规则,指定它应该运行在哪些节点上。
节点亲和性(nodeAffinity):可以通俗的理解为,你更喜欢谁,就和谁靠的更近从而在一起(这属于调度内容,详细内容之后章节展开)。
Kubernetes 集群中的网络插件(calico)或者 kube-porxy 组件,它们都是 DaemonSet 控制器方式部署的。我们可以查看它们所管理的 Pod ,如图:
- 可以看到
spec.affinity.nodeAffinity这个字段是 DaemonSet 默认为 Pod 添加的字段,是它创建 Pod 的机制。 requiredDuringSchedulingIgnoredDuringExecution:它的意思是说,这个 nodeAffinity 必须在每次调度的时候予以考虑。
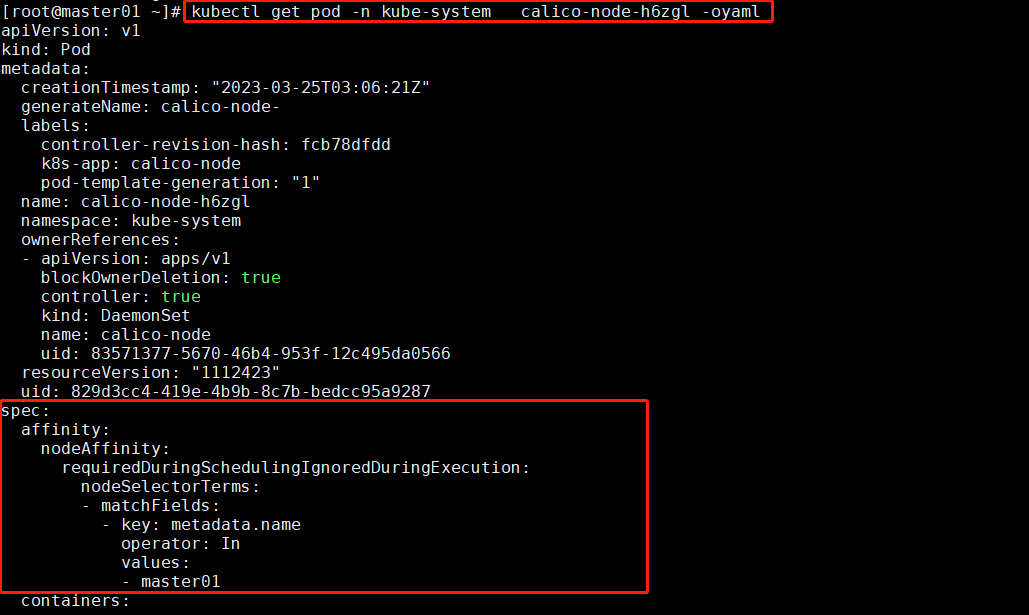
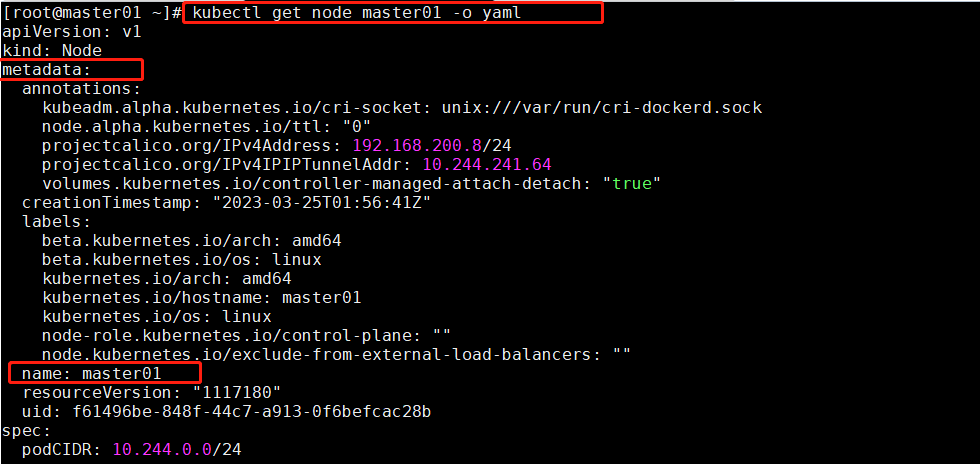
上图中的 matchFields 字段(匹配字段)是我们的匹配 Node 节点的机制,上图中 key: metadata.name和 values: [master01]配置的哪里?看下图,它匹配的是 Node 节点的 YAML 文件中的 metadata.name字段。
2.2 此外,DaemonSet 还会给这个 Pod 自动加上另外一个与调度相关的字段,叫作 tolerations。这个字段意味着这个 Pod,会“容忍”(Toleration)某些 Node 的“污点”(Taint)。
Toleration 和 Taint(容忍和污点):可以通俗的理解为,你能忍受理解某人的缺点,也就不在意它的缺点了。
下面是 DaemonSet 自动生成的一组 tolerations 字段的完整格式:
tolerations:
- key: node.kubernetes.io/not-readyoperator: Existseffect: NoExecute
- key: node.kubernetes.io/unreachableoperator: Existseffect: NoExecute
- key: node.kubernetes.io/disk-pressureoperator: Existseffect: NoSchedule
- key: node.kubernetes.io/memory-pressureoperator: Existseffect: NoSchedule
- key: node.kubernetes.io/unschedulableoperator: Existseffect: NoSchedule上述 tolerations 字段包含了一系列的 toleration 条目,每个条目描述了容忍一个特定污点的规则。例如:
operator: Exists 表示只要存在该污点,就容忍该节点。
effect: NoSchedule 表示不在该节点上进行新的调度。可是,DaemonSet 自动地给被管理的 Pod 加上了这个特殊的 Toleration,就使得这些 Pod 可以忽略这个限制,继而保证每个节点上都会被调度一个 Pod。
node.kubernetes.io/not-ready:表示容忍 NotReady 状态的节点。node.kubernetes.io/unreachable:容忍节点处于 Unreachable 状态。node.kubernetes.io/disk-pressure:容忍节点存在磁盘压力。node.kubernetes.io/memory-pressure:容忍节点存在内存压力。node.kubernetes.io/unschedulable:容忍节点标记为不可调度。
这些 tolerations 使得 DaemonSet 的 Pod 能够在带有这些污点的节点上正常运行。
查看 calico 网络插件 的 Pod 上的 Toleration:
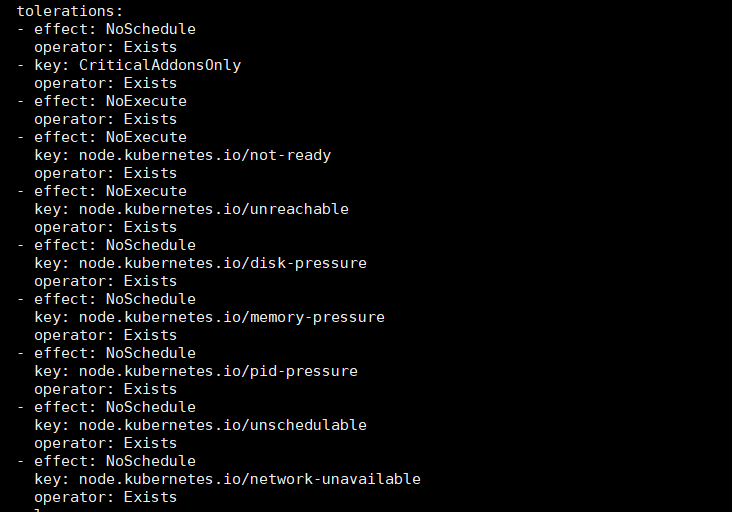
这时,你会想到,我在前面提到的 DaemonSet 的“过人之处”,其实就是依靠 Toleration 实现的。
三、DaemonSet 的镜像版本如何维护
- 创建 DaemonSet 的 YAML 文件:
apiVersion: apps/v1
kind: DaemonSet
metadata:name: example-daemonsetlabels:app: example
spec:selector:matchLabels:app: exampletemplate:metadata:labels:app: examplespec:containers:- name: example-containerimage: nginx:latestimagePullPolicy: IfNotPresent可以看到,现在每个 Node 节点上都有一个 example-daemonset(DaemonSet) 所管理的 Pod:
[root@master01 ~]# kubectl apply -f daemonSet.yaml
daemonset.apps/example-daemonset created[root@master01 ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
example-daemonset-bmfs5 1/1 Running 0 2m5s 10.244.5.14 worker01 <none> <none>
example-daemonset-dgtp4 1/1 Running 0 2m5s 10.244.241.82 master01 <none> <none>- 镜像更新
DaemonSet 与 Deployment 一样都能进行版本管理。使用 kubectl rollout history查看:
[root@master01 ~]# kubectl rollout history daemonset example-daemonset
daemonset.apps/example-daemonset
REVISION CHANGE-CAUSE
1 <none>使用 kubectl set image命令修改镜像版本:
[root@master01 ~]# kubectl set image daemonset/example-daemonset --record example-container=nginx:alpine
Flag --record has been deprecated, --record will be removed in the future
daemonset.apps/example-daemonset image updated使用kubectl rollout history命令再次查看更新版本记录:
[root@master01 ~]# kubectl rollout history daemonset example-daemonset
daemonset.apps/example-daemonset
REVISION CHANGE-CAUSE
1 <none>
2 kubectl set image daemonset/example-daemonset example-container=nginx:alpine --record=true一切皆对象
Deployment 管理这些版本,靠的是“一个版本对应一个 ReplicaSet 对象”。可是,DaemonSet 控制器操作的直接就是 Pod。那么,它的这些版本又是如何维护的呢?
所谓,一切皆对象!
在 Kubernetes 项目中,任何你觉得需要记录下来的状态,都可以被用 API 对象的方式实现。当然,“版本”也不例外。
Kubernetes v1.7 之后添加了一个 API 对象,叫 ControllerRevision,专门用来记录某种 Controller 对象的版本。
[root@master01 ~]# kubectl get controllerrevision
NAME CONTROLLER REVISION AGE
example-daemonset-67d867976 daemonset.apps/example-daemonset 2 10m
example-daemonset-d8494f4bd daemonset.apps/example-daemonset 1 20m[root@master01 ~]# kubectl describe controllerrevision example-daemonset-67d867976我们查看版本 2 是否是我们对应的版本:
- 可以看到,Annotations 记录了,我们 kubectl 修改镜像版本的命令;以及 data 字段保存了该版本对应的完整的 DaemonSet 的 API 对象
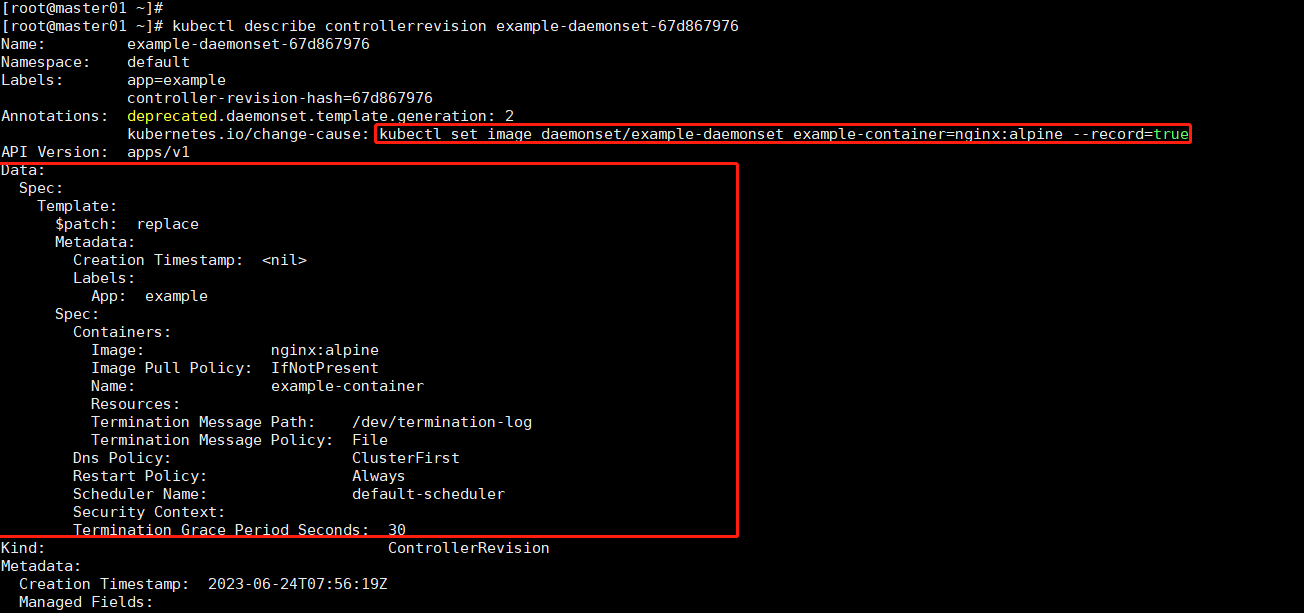
将 DaemonSet 回滚到 Revision=1 时的状态:
kubectl describe controllerrevision可以看到它的Revision 字段,而kubectl rollout undo实际上读取到了 的 ControllerRevision 的对象保存的 Data 字段。而这个 Data 字段里保存的信息,就是Revision=1时这个 DaemonSet 的完整 API 对象。
[root@master01 ~]# kubectl rollout undo daemonset/example-daemonset --to-revision=1
daemonset.apps/example-daemonset rolled back
[root@master01 ~]#[root@master01 ~]# kubectl describe controllerrevision example-daemonset-d8494f4bd在执行完这次回滚完成后,你会发现,DaemonSet 的 Revision 并不会从 Revision=2 退回到 1,而是会增加成 Revision=3。这是因为,一个新的 ControllerRevision 被创建了出来。
[root@master01 ~]# kubectl rollout history daemonset/example-daemonset
daemonset.apps/example-daemonset
REVISION CHANGE-CAUSE
2 kubectl set image daemonset/example-daemonset example-container=nginx:alpine --record=true
3 <none>[root@master01 ~]# kubectl get controllerrevision
NAME CONTROLLER REVISION AGE
example-daemonset-67d867976 daemonset.apps/example-daemonset 2 31m
example-daemonset-d8494f4bd daemonset.apps/example-daemonset 3 41m总结
通过上面的介绍,DaemonSet 的工作过程。
首先,是它的控制循环,查找检查所有 Node 节点上的 Pod 的情况,来决定是否创建或者删除一个 Pod;
其次,在创建 Pod 时,DaemonSet 会自动给这个 Pod 加上一个 nodeAffinity 和 Toleration,来保证 Pod 在指定节点运行,并且忽略 unschedulable “污点”;
最后,DaemonSet 使用 ControllerRevision,来保存和管理对应的“版本”。
StatefulSet 也是直接控制 Pod 对象的,那么它是不是也在使用 ControllerRevision 进行版本管理呢?
没错。在 Kubernetes 项目里,ControllerRevision 其实是一个通用的版本管理对象。这样,Kubernetes 项目就巧妙地避免了每种控制器都要维护一套冗余的代码和逻辑的问题。