C++:容器适配器
- 容器适配器概念
- stack
- queue
- deque
容器适配器概念
容器适配器是在C++标准库中提供的一种容器的封装。它们提供了一种统一的接口,使得不同类型的容器可以以相似的方式被使用。容器适配器有三种类型:栈(stack)、队列(queue)和优先队列(priority_queue)。其中优先队列其实就是数据结构中的堆(heap)。
我们看到这三种数据结构有一个共同的特点,那就是它们的规则是基于数据的,而不是基于内存的。比如说顺序表(vector)要求内存必须是连续的,链表(list)要求一个一个节点的形式来存储数据。它们都对内存有明确的限制。而以上三种数据结构,只是对数据的出入顺序有要求,所以它们的底层可以是vector,list等等其它容器。
也就是说,它们可以将原本的容器进行封装,改变容器的出入规则,但是底层的数据存储依然使用其它的容器。这种模式叫做容器适配器。
接下来带大家实现stack与queue,帮助大家理解这种容器适配器模式。
stack
栈(stack)是一种先进后出(Last-In-First-Out,LIFO)的数据结构,它的特点是只能在栈的一端进行插入和删除操作。在栈中,插入元素的一端称为栈顶(top),删除元素的一端称为栈底(bottom)。栈的插入操作叫做入栈(push),删除操作叫做出栈(pop)。
栈的实现通常有两种方式:数组实现和链表实现。使用数组实现的栈叫做顺序栈,使用链表实现的栈叫做链式栈。
在此处,我们用vector作为底层容器,实现一个顺序栈。
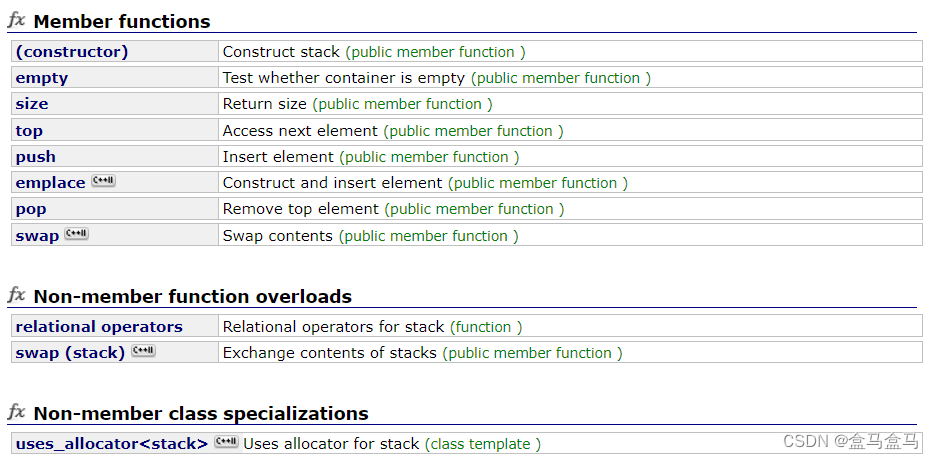
以上就是STL库中stack的所有接口,我们选择里面最重点实现。
先看到基本结构:
template <class T>
class stack
{
private:vector<T> _con;
};
stack类内部,有一个成员变量_con,其类型为vector<T>,这就是我们stack的底层容器,后续我们stack进行操作,本质上都是对vector进行操作。
那么我们的vector哪一边做栈顶好呢?
如果我们用vector的头部做栈顶,那么每次入栈,所有数据都要往后移动一位;每次出栈,所有数据都要往前移动一位。
这会带来大量的时间浪费。
但是用vector的尾部做栈顶,那么每次入栈出栈,都不会影响其它数据,所以最好用尾部做栈顶。
入栈:
入栈其实就是对vector尾插:
void push(const T& x)
{_con.push_back(x);
}
出栈:
出栈就是对vector尾删:
void pop()
{_con.pop_back();
}
返回栈顶元素:
返回栈顶,其实就是得到vector尾部的元素:
const T& top()
{return _con.back();
}
返回栈的大小:
栈的大小,就是vector的大小:
size_t size()
{return _con.size();
}
判断栈是否为空:
栈为空,其实就是vector为空:
bool empty()
{return _con.empty();
}
可以发现,我们将底层设为vector后,无需再考虑底层是如何插入删除,只需要将我们配套的规则对应的接口用上去即可,这就是容器适配器带来的优势。
但是至此,还不算完整的容器适配器设计模式。如果用户想用list做底层,难道我们又要写一个list版本吗?
这是不需要的,我们不如直接传入第二个模板参数,让用户可以自定义需要的底层容器:
template <class T, class Container = vector<T>>
class stack
{
private:Container _con;
};
第二个模板参数container就是我们的底层容器,其默认值为vector,当用户不传入第二个参数,那么默认以vector为底层容器。
当用户需要list版本的stack:
stack<int, list<int>> st;
这样我们就可以让用户想用什么底层容器,就用什么底层容器。
完整代码:
template <class T, class Container = deque<T>>
class stack
{
public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}const T& top(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;
};
queue
队列(Queue)是一种先进先出(First-In-First-Out,FIFO)的数据结构。在队列中,元素只能在一端(队尾)添加,而在另一端(队头)删除。新的元素只能添加到队尾,而只能从队头删除元素。
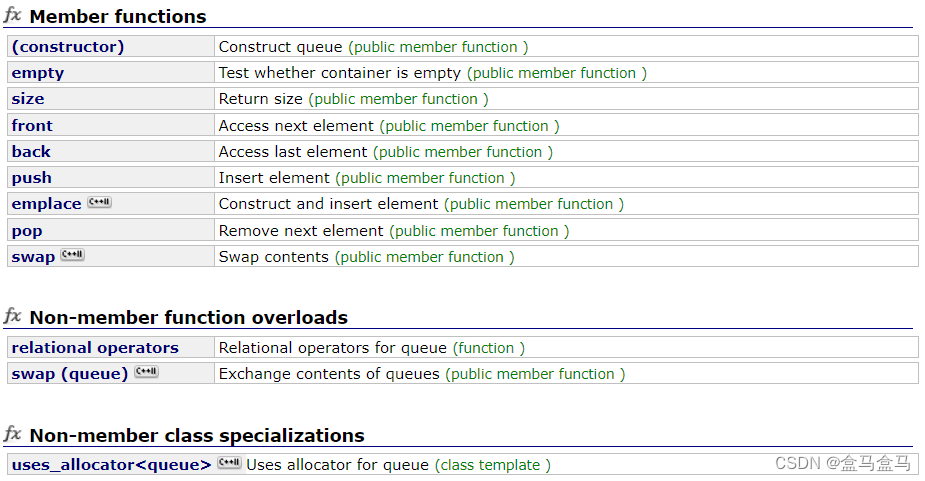
同样的我们来实现一下queue:
相比于vector,list更适合作为queue的底层容器,因为queue需要头部删除,而vector头部删除的代价很大,要移动整个vector的数据,而list不需要,所以queue适合用list作为底层。
有了前面的铺垫,这里我就不额外讲解每个接口了:
template <class T, class Container = list<T>>
class queue
{
public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}const T& front(){return _con.front();}const T& back(){return _con.back();}size_t size(){return _con.size();}bool empty(){return _con.empty();}private:Container _con;
};
前面的两个容器适配器,一个用list做底层,一个用vector做底层。但是在STL中,这两个容器适配器的默认底层容器都是一个叫做deque的容器,接下来我为大家介绍这个容器。
deque
deque是双端队列(double-ended queue)的缩写,它是一种具有特殊特性的线性数据结构。deque允许从两端进行元素的插入和删除操作。
我们看一下deque的结构:
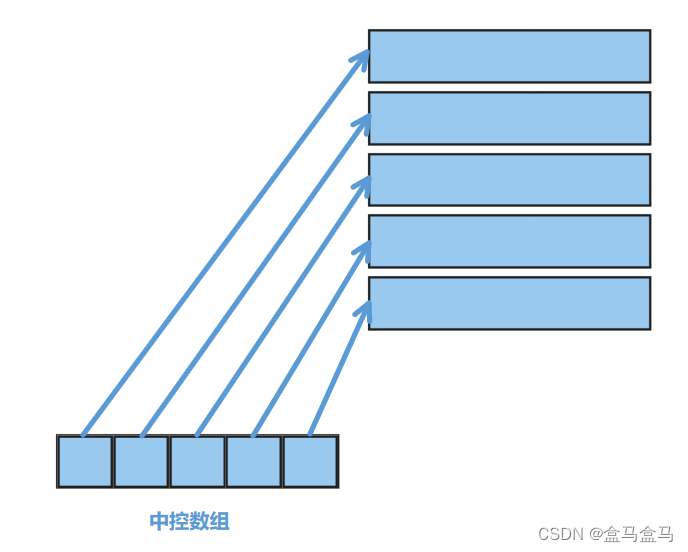
deque分为两个区域,左下角的区域称为中控,其用于控制所有小数组,中控本质上是一个指针数组,内部的每个指针都指向了一个小数组。而我们是在右侧小数组中插入删除数据的。
deque的插入并不是从第一个位置开始插入,而是从中间开始插入。
比如我们要插入数据“12345”:
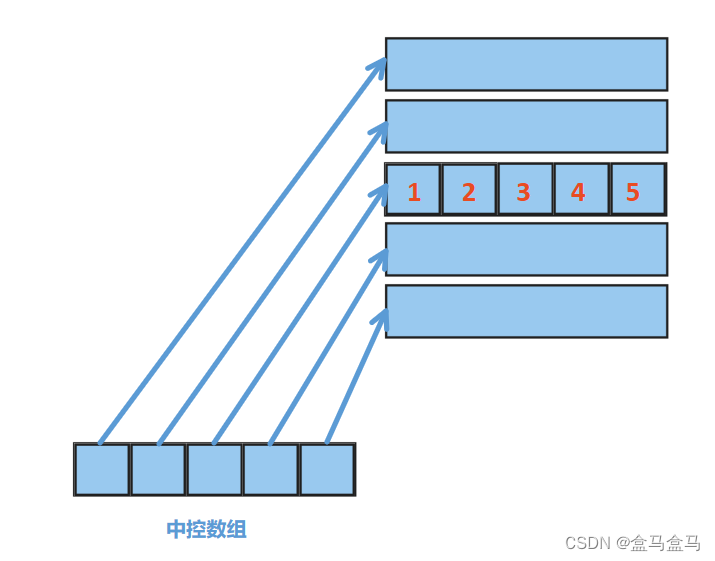
这么做的好处就是:适合头插尾插。
接下来我们再在头部插入数据“678910”:
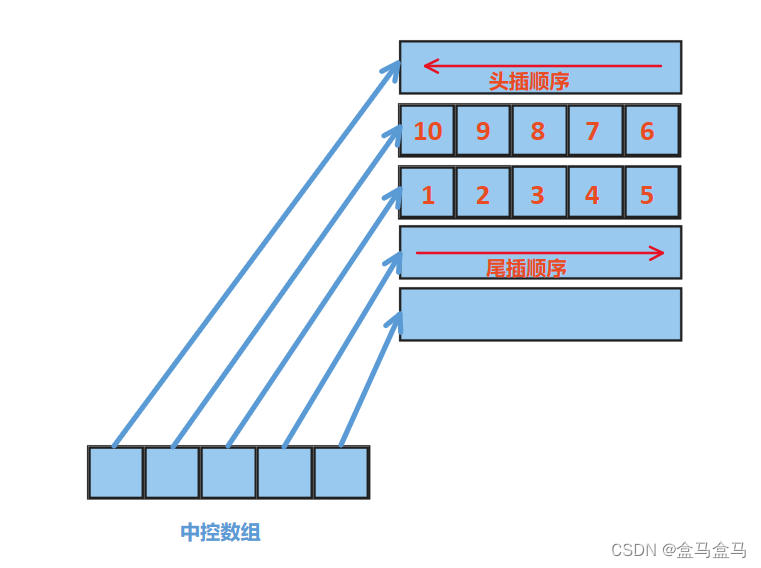
可以看到,我们进行头部插入,不会影响其他数据,这是它相对于vector的优势。而由于其内存是部分连续的,可以通过中控数组的指针偏移量与小数组的指针偏移量来锁定元素。所以其也可以支持下标随机访问。
deque的优势:
- 头尾插入删除效率很高
- 支持下标随机访问
那么它这么好用,为什么不直接替代vector和list呢?
那么我再讲一讲它的致命缺点:极度不适合中间插入。
我们看到,这个结构中,数据被分为了很多个小段,如果我们在中间插入删除数据,就会导致数据的挪动很麻烦,因为会发生不同数组之间的数据迁移。所以其中间插入的效率非常非常低。
这也就是为什么它称为双端队列的原因,就是只适合两端的插入删除,
而stack和queue两种数据结构,刚好都是不会发生中间的插入删除的,所以它们的默认底层容器是deque。
最后总结一下:
deque的特性包括:
-
双端高效插入和删除操作:
deque允许在队列的头部和尾部进行插入和删除操作。这意味着可以在队列的任意一端进行元素的添加和移除,而不仅限于一侧。插入和删除的时间复杂度是O(1),即常数时间。这使得deque在需要高效地在两端进行插入和删除操作的场景下非常有用。 -
随机访问:和数组类似,
deque也支持随机访问。即通过下标访问第i个元素的时间复杂度是O(1)。这是因为在数组实现中,deque使用了连续的存储空间,并且通过指针可以直接定位到指定的元素。 -
空间效率:
deque的空间效率较高。在数组实现中,由于使用了连续的存储空间,没有额外的指针和链表结构,因此空间占用较小。
总结起来,deque是一种具有特殊特性的线性数据结构,它兼具了队列和栈的特点,并且在两端插入和删除操作非常高效,同时也支持随机访问。这使得deque在需要频繁在两端进行插入和删除操作的场景中非常有用。但是不适合中间的插入删除。
容器适配器使得程序员可以不必直接处理底层容器的细节,而是使用统一的接口来操作不同类型的容器。这样,当需要改变底层容器时,只需要修改适配器的类型参数即可,而不需要修改大量的代码。容器适配器的使用可以提高代码的可维护性和可扩展性,同时也使代码更易于理解。