在这里先给屏幕面前的你送上祝福,祝你在未来一年:技术步步高升、薪资节节攀升,身体健健康康,家庭和和美美。
一、介绍
在Hadoop2.4之前,ResourceManager是YARN集群中的单点故障
ResourceManager HA是通过 Active/Standby 体系结构实现的,在任何时候其中一个RM都是活动的,并且一个或多个RM处于备用模式,等待在活动发生任何事情时接管。
二、架构
官网的架构图如下:
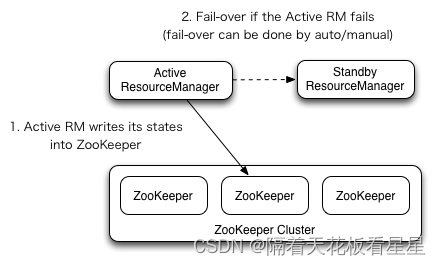
1、Active 状态的 ResourceManager 将自己的状态写入ZooKeeper
2、如果 Active 状态的 ResourceManager状态发生改变,可以通过自动或手动方式完成故障转移
三、故障转移
1、手动转换
如果未启用自动故障切换,管理员必须手动将其中一个ResourceManager转换为活动。要从一个ResourceManager故障切换到另一个ResourceManager,他们应该首先将活动ResourceManager转换为备用ResourceManager,然后将备用ResourceManager转换为活动ResourceManager。相关命令如下:
获取所有RM节点的状态
yarn rmadmin -getAllServiceState
获取 rm1 节点的状态
yarn rmadmin -getServiceState rm1
手动将 rm1 的状态切换到STANDBY
yarn rmadmin -transitionToStandby rm1
或
yarn rmadmin -transitionToStandby -forcemanual rm1
手动将 rm1 的状态切换到ACTIVE
yarn rmadmin -transitionToActive rm1
或
yarn rmadmin -transitionToActive -forcemanual rm1
2、自动切换
ResourceManager可以选择嵌入基于Zookeeper的ActiveStandbyElector来决定哪个ResourceManager应该是Active。当Active宕机或无响应时,会自动选择另一个ResourceManager作为Active,然后由它接管。需要注意的是Yarn不需要像HDFS那样运行单独的ZKFC守护进程,因为嵌入在ResourceManager中的ActiveStandbyElector充当故障检测器和领导者选举人。
配置示例如下:
<property><name>yarn.resourcemanager.ha.enabled</name><value>true</value><description>开启resourcemanager的HA</description>
</property>
<property><name>yarn.resourcemanager.cluster-id</name><value>cluster1</value><description>标识群集。由选举人使用,以确保RM不会作为“活动”接管另一个群集。</description>
</property>
<property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value><description>RM的逻辑ID列表</description>
</property>
<property><name>yarn.resourcemanager.hostname.rm1</name><value>master1</value><description>对于每个rm-ids,指定rm对应的主机名。或者,可以设置rm的每个服务地址</description>
</property>
<property><name>yarn.resourcemanager.hostname.rm2</name><value>master2</value><description>对于每个rm-ids,指定rm对应的主机名。或者,可以设置rm的每个服务地址</description>
</property>
<property><name>yarn.resourcemanager.webapp.address.rm1</name><value>master1:8088</value><description>对于每个rm-ids,指定与之对应的rm web应用程序的host:port</description>
</property>
<property><name>yarn.resourcemanager.webapp.address.rm2</name><value>master2:8088</value><description>对于每个rm-ids,指定与之对应的rm web应用程序的host:port</description>
</property>
<property><name>hadoop.zk.address</name><value>zk1:2181,zk2:2181,zk3:2181</value><description>ZK法定人数的地址。用于两者状态和领导人选举</description>
</property>四、源码分析
在我的上一篇<Hadoop-Yarn-启动篇>博客中有ResourceManager的启动源码,现在我们只将关于HA的部分拿处理分析下
1、设置HA配置
//登录前应设置HA配置this.rmContext.setHAEnabled(HAUtil.isHAEnabled(this.conf));if (this.rmContext.isHAEnabled()) {HAUtil.verifyAndSetConfiguration(this.conf);}public static boolean isHAEnabled(Configuration conf) {//即获取yarn.resourcemanager.ha.enabled的值return conf.getBoolean(YarnConfiguration.RM_HA_ENABLED,YarnConfiguration.DEFAULT_RM_HA_ENABLED);}public static void verifyAndSetConfiguration(Configuration conf)throws YarnRuntimeException {//验证配置是否至少有两个RM id,并且为每个RM-id指定了RPC地址。然后设置RM id。//即 配置文件中的 yarn.resourcemanager.ha.rm-ids 对应配置的多个 RM 节点的RPC地址verifyAndSetRMHAIdsList(conf);//设置 yarn.resourcemanager.ha.id 的值,如果没有配置则通过匹配yarn.reresourcemanager.address来计算verifyAndSetCurrentRMHAId(conf);//验证 Leader 选举服务是否已启用。YARN允许在配置中禁用领导层选举,从而中断自动故障切换verifyLeaderElection(conf);//验证所有服务的地址// RM_ADDRESS 即 yarn.resourcemanager.address// RM_SCHEDULER_ADDRESS 即 yarn.resourcemanager.scheduler.address// RM_ADMIN_ADDRESS 即 yarn.resourcemanager.admin.address// RM_RESOURCE_TRACKER_ADDRESS 即 yarn.resourcemanager.resource-tracker.address// RM_WEBAPP_ADDRESS 即 yarn.resourcemanager.webapp.addressverifyAndSetAllServiceAddresses(conf);}2、添加选举人
//必须在管理员服务后添加选举人
if (this.rmContext.isHAEnabled()) {//获取配置文件中yarn.resourcemanager.ha.automatic-failover.enabled的值,默认true// 启用自动故障切换;默认情况下,只有在启用HA时才会启用它。//获取配置文件中yarn.resourcemanager.ha.automatic-failover.embedded的值,默认true// 启用嵌入式自动故障切换。默认情况下,只有在启用HA时才会启用它。// 嵌入式elector依赖于RM状态存储来处理围栏,主要用于与ZKRMStateStore结合使用。if (HAUtil.isAutomaticFailoverEnabled(conf)&& HAUtil.isAutomaticFailoverEmbedded(conf)) {EmbeddedElector elector = createEmbeddedElector();//添加Curator的领导人选举服务addIfService(elector);rmContext.setLeaderElectorService(elector);}
}protected EmbeddedElector createEmbeddedElector() throws IOException {EmbeddedElector elector;//获取配置文件中 yarn.resourcemanager.ha.curator-leader-elector.enabled 的值,默认true/是否使用Curator-based的选举人进行领导人选举curatorEnabled =conf.getBoolean(YarnConfiguration.CURATOR_LEADER_ELECTOR,YarnConfiguration.DEFAULT_CURATOR_LEADER_ELECTOR_ENABLED);if (curatorEnabled) {//获取ZooKeeper Curator管理器,创建并启动(如果不存在)this.zkManager = createAndStartZKManager(conf);/使用Curator的领导人选举实施elector = new CuratorBasedElectorService(this);} else {elector = new ActiveStandbyElectorBasedElectorService(this);}return elector;
}3、创建并启动ZooKeeper Curator管理器
Curator是Netflix公司在原生zookeeper客户端基础上开源的第三方Java客户端,使用它可以去操作zookeeper创建、删除、查询、修改znode节点
public ZKCuratorManager createAndStartZKManager(Configurationconfig) throws IOException {//提供特定于ZK操作的实用程序方法的Helper类ZKCuratorManager manager = new ZKCuratorManager(config);//获取身份验证List<AuthInfo> authInfos = new ArrayList<>();//获取 yarn.resourcemanager.ha.enabled 值,默认false//获取 yarn.resourcemanager.zk-state-store.root-node.acl + yarn.resourcemanager.ha.id 的值//yarn.resourcemanager.ha.id官方解释:(在第1步已经设置过这个值了)//当前RM的id(字符串)。启用HA时,这是一个可选配置。当前RM的id可以通过显式指定yarn.resourcemanager.ha.id来设置,也可以通过匹配yarn.reresourcemanager.address来计算。具有本地地址的{id}请参阅yarn.resourcemanager.ha.enabled的描述,了解如何使用它的完整详细信息。//yarn.resourcemanager.zk-state-store.root-node.acl官方解释://在HA场景中使用ZKRMStateStore进行围栏时,用于根znode的ACL。ZKRMStateStore支持隐式围栏,允许单个ResourceManager对存储进行写访问。对于围栏,群集中的ResourceManager在根节点上共享读写管理权限,但Active ResourceManager声明具有独占的创建-删除权限。默认情况下,当未设置此属性时,我们使用来自yarn.resourcemanager.zk-cl的acl进行共享管理访问,并使用rm address:random number进行基于用户名的独占创建-删除访问。此属性允许用户设置自己选择的ACL,而不是使用默认机制。为了使围栏发挥作用,应在每个ResourceManager上小心地以不同的方式设置ACL,以便所有ResourceManager都具有共享的管理访问权限,而Active ResourceManager(仅)接管创建-删除访问权限。if (HAUtil.isHAEnabled(config) && HAUtil.getConfValueForRMInstance(YarnConfiguration.ZK_RM_STATE_STORE_ROOT_NODE_ACL, config) == null) {String zkRootNodeUsername = HAUtil.getConfValueForRMInstance(YarnConfiguration.RM_ADDRESS,YarnConfiguration.DEFAULT_RM_ADDRESS, config);// private final String zkRootNodePassword =Long.toString(new SecureRandom().nextLong());//由此可见 zkRootNodePassword 是一个随机数String defaultFencingAuth =zkRootNodeUsername + ":" + zkRootNodePassword;//RM地址和一个随机数构建了一个字节数组byte[] defaultFencingAuthData =defaultFencingAuth.getBytes(Charset.forName("UTF-8"));//构建身份验证摘要String scheme = new DigestAuthenticationProvider().getScheme();AuthInfo authInfo = new AuthInfo(scheme, defaultFencingAuthData);authInfos.add(authInfo);}//开始连接到ZooKeeper集合manager.start(authInfos);return manager;}4、连接ZooKeeper集合
public void start(List<AuthInfo> authInfos) throws IOException {//获取ZooKeeper团队地址 即 hadoop.zk.address// <property>// <name>hadoop.zk.address</name>// <value>zk1:2181,zk2:2181,zk3:2181</value>// <description>ZK法定人数的地址。用于两者状态和领导人选举</description>// </property>//String zkHostPort = conf.get(CommonConfigurationKeys.ZK_ADDRESS);if (zkHostPort == null) {throw new IOException(CommonConfigurationKeys.ZK_ADDRESS + " is not configured.");}//获取 hadoop.zk.num-retries 的值 默认值 1000//ZooKeeper操作的最大重试次数 int numRetries = conf.getInt(CommonConfigurationKeys.ZK_NUM_RETRIES,CommonConfigurationKeys.ZK_NUM_RETRIES_DEFAULT);//获取 hadoop.zk.timeout-ms 的值 默认值 10000//ZooKeepers操作超时(以毫秒为单位)int zkSessionTimeout = conf.getInt(CommonConfigurationKeys.ZK_TIMEOUT_MS,CommonConfigurationKeys.ZK_TIMEOUT_MS_DEFAULT);//获取 hadoop.zk.retry-interval-ms 的值 默认值 1000 //以毫秒为单位重试ZooKeeper操作的频率int zkRetryInterval = conf.getInt(CommonConfigurationKeys.ZK_RETRY_INTERVAL_MS,CommonConfigurationKeys.ZK_RETRY_INTERVAL_MS_DEFAULT);RetryNTimes retryPolicy = new RetryNTimes(numRetries, zkRetryInterval);//设置ZooKeeper身份验证List<ZKUtil.ZKAuthInfo> zkAuths = getZKAuths(conf);if (authInfos == null) {authInfos = new ArrayList<>();}for (ZKUtil.ZKAuthInfo zkAuth : zkAuths) {authInfos.add(new AuthInfo(zkAuth.getScheme(), zkAuth.getAuth()));}//获取客户端框架CuratorFramework client = CuratorFrameworkFactory.builder().connectString(zkHostPort).sessionTimeoutMs(zkSessionTimeout).retryPolicy(retryPolicy).authorization(authInfos).build();//启动client.start();this.curator = client;}5、启动Curator的领导人选举服务
protected void serviceInit(Configuration conf) throws Exception {rmId = HAUtil.getRMHAId(conf);String clusterId = YarnConfiguration.getClusterId(conf);//获取 yarn.resourcemanager.ha.automatic-failover.zk-base-path 的值 默认值 /yarn-leader-election//官网解释:使用基于ZooKeeper的领导人选举时,用于存储领导人信息的基本znode路径。String zkBasePath = conf.get(YarnConfiguration.AUTO_FAILOVER_ZK_BASE_PATH,YarnConfiguration.DEFAULT_AUTO_FAILOVER_ZK_BASE_PATH);latchPath = zkBasePath + "/" + clusterId;//第3步已经设置过了,这里直接取curator = rm.getCurator();//初始化并启动LeaderLatchinitAndStartLeaderLatch();super.serviceInit(conf);}五、总结
1、判断配置文件中是否配置了HA开启
2、如果开启了HA,开始配置并设置启动必要参数
3、根据配置文件添加选举人
4、获取ZooKeeper Curator管理器,创建并启动
5、连接到ZooKeeper集合
6、获取客户端框架并启动

![[缓存] - 1.缓存共性问题](https://img-blog.csdnimg.cn/direct/8319a8221102466c9a4afe72a7cb5882.png)