主动学习和基于Transformer的机器学习模型的结合为有效地训练深度学习模型提供了强有力的工具。通过利用主动学习,数据科学家能够减少训练模型所需的标记数据的数量,同时仍然达到高精度。本文将探讨基于Transformer的机器学习模型如何在主动学习环境中使用,以及哪些模型最适合这项任务。
一、主动学习
主动学习是一种迭代过程,它利用之前获得的标签的反馈来指导选择新的数据点进行标记。它的工作原理是不断选择最具信息量的未标记数据点,这些数据点在标记并纳入训练后有最大的潜力提高模型的性能。这个迭代过程创建了一个高效的工作流程,使您能够以最小的努力快速获得高质量的模型。随着每次迭代,性能提升,允许观察到机器学习模型的改进。
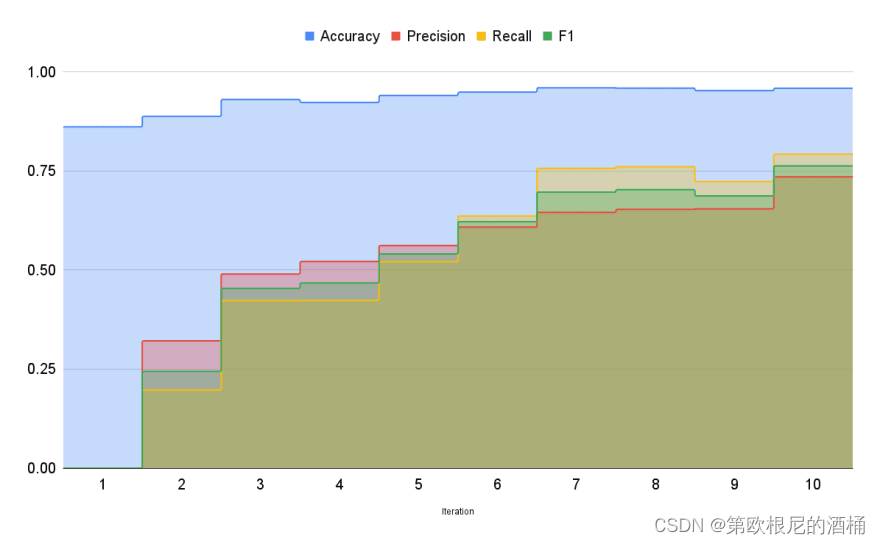
例如,在 MRPC 数据集上进行的一个使用伯特基变换器模型的实验发现,与从一开始就使用完全标记的数据集相比,使用主动学习方法需要的例子减少了21% 。
二、基于transformer的主动学习机器学习模型
基于transformer的机器学习模型有很多,比如说
- BERT
- GPT
- XLNet
这些模型已经被证明在许多自然语言处理任务中取得了最先进的结果,例如问题回答、情绪分析和文档分类。通过在主动学习环境中利用这些类型的模型,您可以快速识别需要标记的最重要的样本,并使用它们来有效地训练模型。此外,这些模型非常容易部署在云平台上,比如 AWS 或 Azure,这使得在活动学习环境中使用它们更加方便。
在Kern AI refinery中,我们使用来自Huggingface的最新(SOTA)Transformer模型从文本数据集中创建嵌入(embeddings)。
通常在新项目开始时就完成这一步,因为拥有所有文本数据的嵌入使我们能够通过计算每个嵌入文本的余弦相似度快速找到相似记录。这可以极大地提高标记速度。
在完成一些数据标记后,我们能够使用这些文本嵌入来训练简单的机器学习算法,比如逻辑回归或决策树。我们不使用这些嵌入来再次训练基于Transformer的模型,因为这些嵌入的质量非常高,即使是简单的模型也能提供高精度的结果。通过主动学习方法,您不仅节省了时间和金钱,还大大减少了后续的计算工作量。
总之,基于Transformer的机器学习模型为使用主动学习技术高效训练深度学习模型提供了强大的工具。通过利用它们捕获文本数据中的上下文信息的能力,您可以快速识别出下一个应该标记的样本,以最小的努力和成本有效地训练您的模型。此外,这些类型的模型具有高度的可扩展性,并且易于在云平台上部署,使它们非常适合在主动学习环境中使用。将所有这些优势结合在一起,难怪基于Transformer的机器学习模型在开发者和数据科学家中越来越受欢迎。