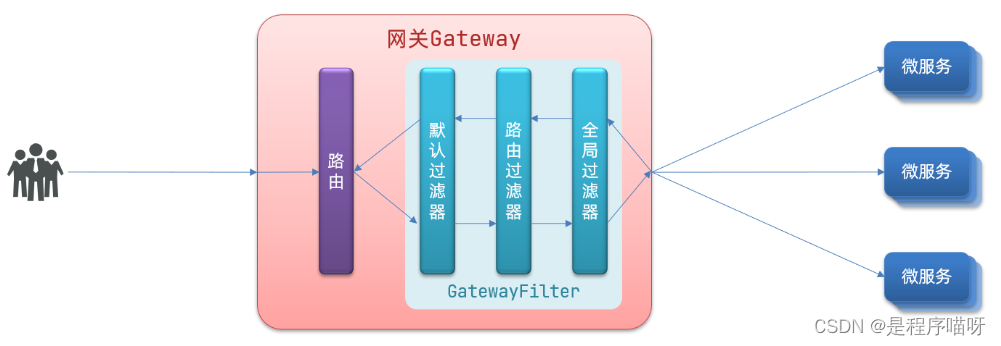
深入探索Pandas:读写JSON文件的终极指南与实战技巧read_json、to_json
在数据分析和处理过程中,JSON(JavaScript Object Notation)是一种常见的数据格式。Pandas库提供了方便而强大的工具,使得读取和写入JSON文件变得十分简便。在本文中,我们将深入探讨Pandas的read_json和to_json方法,介绍它们的参数,并通过实际代码示例演示它们的用法。

1. Pandas的read_json方法
read_json方法允许我们从JSON文件中读取数据,并将其转换为Pandas DataFrame。以下是该方法的常见参数说明:
-
path_or_buf: JSON文件的路径或包含JSON数据的字符串。
-
orient: 数据的方向,决定如何解析JSON数据。常见选项包括’split’、‘records’、‘index’、‘columns’和’values’。
-
typ: 返回的数据类型,可以是
series或frame。 -
dtype: 指定列的数据类型。
示例代码:
import pandas as pd# 从JSON文件中读取数据
json_path = 'sample.json'
df = pd.read_json(json_path, orient='records', typ='frame')# 显示DataFrame的前几行
print(df.head())
2. Pandas的to_json方法
to_json方法用于将Pandas DataFrame保存为JSON文件。以下是该方法的常见参数说明:
-
path_or_buf: JSON文件的路径或可写入的对象。
-
orient: 决定生成的JSON的结构。常见选项包括’split’、‘records’、‘index’、‘columns’和’values’。
-
date_format: 控制日期的格式。
-
force_ascii: 如果为True,则所有非ASCII字符将被转义。
示例代码:
import pandas as pd# 创建一个示例DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 22],'City': ['New York', 'San Francisco', 'Los Angeles']}
df = pd.DataFrame(data)# 将DataFrame保存为JSON文件
json_path = 'output.json'
df.to_json(json_path, orient='records', date_format='iso', force_ascii=False)
3. 代码解析
-
在第一个例子中,我们使用
read_json方法从指定路径的JSON文件中读取数据,并通过指定orient和typ参数来调整数据解析的方式和返回的数据类型。 -
在第二个例子中,我们使用
to_json方法将DataFrame保存为JSON文件。通过调整orient和其他参数,我们可以控制生成的JSON的格式和结构。
通过使用这两个方法,我们可以方便地在Pandas中进行JSON文件的读取和写入操作,为数据分析和处理提供了更灵活的选择。希望这篇文章能够帮助你更好地利用Pandas处理JSON数据。

4. 处理嵌套JSON数据
有时,JSON文件中的数据可能会包含嵌套结构,例如嵌套的字典或列表。Pandas的read_json方法对于这种情况同样适用,并且可以通过orient参数灵活地解析嵌套的数据。
示例代码:
import pandas as pd# 嵌套JSON数据的示例
nested_json_data = '{"name": "John", "age": 30, "address": {"city": "New York", "zipcode": "10001"}}'# 读取嵌套JSON数据
df_nested = pd.read_json(nested_json_data, orient='index', typ='frame')# 显示DataFrame
print(df_nested)
在这个例子中,我们使用read_json读取了一个包含嵌套结构的JSON数据。通过设置orient参数为'index',我们成功地将嵌套的数据转换为DataFrame。
5. 处理时间序列数据
Pandas对于处理时间序列数据也提供了很好的支持。在读取和写入JSON文件时,我们可以利用date_format参数来控制日期的格式。
示例代码:
import pandas as pd
import datetime# 创建一个包含日期的DataFrame
data_with_dates = {'Date': [datetime.date(2022, 1, 1), datetime.date(2022, 1, 2)],'Value': [10, 20]}df_dates = pd.DataFrame(data_with_dates)# 将包含日期的DataFrame保存为JSON文件
json_path_dates = 'output_with_dates.json'
df_dates.to_json(json_path_dates, orient='records', date_format='iso')# 读取包含日期的JSON文件
df_read_dates = pd.read_json(json_path_dates, orient='records')# 显示读取的DataFrame
print(df_read_dates)
在这个例子中,我们创建了一个包含日期的DataFrame,并将其保存为JSON文件。通过设置date_format为’iso’,我们确保了日期的正确转换。然后,我们使用read_json方法读取了这个JSON文件,并成功还原了DataFrame。
通过这些示例,我们展示了Pandas在处理不同类型的JSON数据时的灵活性和便利性。这些功能使得数据分析人员和科学家能够更轻松地进行数据读取和写入,提高了工作效率。希望本文对你理解Pandas中的read_json和to_json方法有所帮助。
6. 处理缺失值和特殊字符
在实际数据处理中,我们经常会遇到缺失值或包含特殊字符的数据。Pandas的read_json方法允许我们通过设置convert_axes参数处理这些情况。
示例代码:
import pandas as pd
import numpy as np# 创建包含缺失值和特殊字符的DataFrame
data_with_missing = {'Name': ['Alice', 'Bob', np.nan],'Age': [25, 30, 22],'City': ['New York', 'San Francisco', 'Los Angeles$%#']}df_missing = pd.DataFrame(data_with_missing)# 将包含缺失值和特殊字符的DataFrame保存为JSON文件
json_path_missing = 'output_with_missing.json'
df_missing.to_json(json_path_missing, orient='records', convert_axes='all')# 读取包含缺失值和特殊字符的JSON文件
df_read_missing = pd.read_json(json_path_missing, orient='records')# 显示读取的DataFrame
print(df_read_missing)
在这个例子中,我们创建了一个包含缺失值和特殊字符的DataFrame,并将其保存为JSON文件。通过设置convert_axes为’all’,我们确保了在读取时能够正确处理缺失值和特殊字符,而不会导致解析错误。
7. 性能优化
当处理大型数据集时,性能是一个重要的考虑因素。Pandas的read_json方法提供了一些参数,可以帮助优化读取大型JSON文件的速度。
示例代码:
import pandas as pd# 读取大型JSON文件并优化性能
json_path_large = 'large_data.json'
df_large = pd.read_json(json_path_large, orient='split', chunksize=10000)# 遍历所有块并合并
result_large = pd.concat(df_large, ignore_index=True)# 显示合并后的DataFrame
print(result_large)
在这个例子中,通过设置orient为’split’和chunksize为块的大小,我们可以有效地处理大型JSON文件,减少内存消耗并提高读取速度。
通过这些实际案例,我们强调了Pandas中read_json和to_json方法的灵活性和实用性,以及如何通过调整参数来适应不同的数据情况。这些功能使得Pandas成为数据处理和分析的强大工具,无论是在小型项目还是大型数据集中都能够发挥重要作用。希望这篇文章对你在实际工作中使用Pandas进行JSON数据处理提供了帮助。
8. 处理复杂JSON结构
有时,JSON文件可能包含复杂的嵌套结构,如多层嵌套的字典和列表。在这种情况下,我们可以使用flatten_json库将复杂结构的JSON文件扁平化,以便更容易地导入到Pandas中。
示例代码:
import pandas as pd
from flatten_json import flatten# 示例复杂嵌套JSON数据
complex_json_data = [{"id": 1,"info": {"name": "Alice","details": {"age": 25,"address": {"city": "New York","zipcode": "10001"}}}},{"id": 2,"info": {"name": "Bob","details": {"age": 30,"address": {"city": "San Francisco","zipcode": "94105"}}}}
]# 扁平化复杂嵌套JSON数据
flat_json_data = [flatten(item) for item in complex_json_data]# 通过扁平化后的数据创建DataFrame
df_complex = pd.DataFrame(flat_json_data)# 显示处理后的DataFrame
print(df_complex)
在这个例子中,我们使用flatten_json库将复杂的嵌套JSON数据扁平化,然后使用Pandas创建DataFrame。这使得处理复杂结构的JSON文件更为方便。
10. 进阶应用:处理JSON中的复合数据
在实际应用中,JSON文件可能包含更为复杂的结构,如包含嵌套数组或多层次的嵌套字典。Pandas提供了处理这类复合数据的方法,通过使用json_normalize函数能够将嵌套数据规范化为平铺形式,使其更容易导入为DataFrame。
示例代码:
import pandas as pd
from pandas import json_normalize# 复合JSON数据示例
compound_json_data = [{"id": 1,"name": "Alice","details": {"addresses": [{"city": "New York", "zipcode": "10001"},{"city": "Los Angeles", "zipcode": "90001"}],"hobbies": ["reading", "traveling"]}},{"id": 2,"name": "Bob","details": {"addresses": [{"city": "San Francisco", "zipcode": "94105"}],"hobbies": ["photography", "cooking"]}}
]# 使用json_normalize处理复合JSON数据
df_compound = json_normalize(compound_json_data, sep='_')# 显示处理后的DataFrame
print(df_compound)
在这个例子中,我们使用json_normalize函数将复合JSON数据规范化为平铺形式的DataFrame。通过设置sep参数,我们定义了列名中的分隔符,以避免列名中出现多层嵌套。
11. 性能优化进阶
当处理非常大的JSON文件时,为了提高性能,可以考虑使用Dask库。Dask是一个并行计算库,它可以处理超出内存范围的大型数据集,提供了与Pandas类似的API。
示例代码:
import dask.dataframe as dd# 使用Dask读取大型JSON文件
dask_df = dd.read_json('large_data.json', lines=True, orient='records')# 进行数据处理操作
result_dask = dask_df.groupby('category').mean()# 显示处理后的结果
print(result_dask.compute())
在这个例子中,我们使用Dask的read_json方法读取大型JSON文件,然后进行一些数据处理操作。compute方法用于触发实际的计算并返回结果。Dask的优势在于可以并行处理大规模数据,适用于需要处理超大型数据集的场景。
通过这些进阶应用,我们展示了Pandas和相关库在处理更为复杂和庞大的JSON数据时的灵活性和性能优化的手段。这对于在实际工作中面对大型和复杂的数据集时非常有价值。希望这些示例对你的数据处理工作有所启发。如有其他问题,请随时提出。
总结:
在本文中,我们深入探讨了Pandas库中用于读取和写入JSON文件的read_json和to_json方法,并提供了详细的参数说明和实际代码示例。我们覆盖了多个方面,包括处理嵌套JSON、时间序列数据、缺失值和特殊字符,以及性能优化的技巧。
我们还介绍了如何处理复杂JSON结构,使用flatten_json库将复杂嵌套的数据扁平化,以及通过json_normalize函数处理包含嵌套数组或多层次嵌套字典的复合数据。
最后,我们进一步展示了性能优化的进阶应用,包括使用Dask库处理大型JSON文件,以及一些处理非常大的数据集的技巧。
通过这些例子,我们强调了Pandas在处理不同类型和规模的JSON数据时的灵活性和实用性。无论是在数据分析、数据清洗还是大数据处理方面,Pandas都提供了丰富的工具和功能,使得数据科学家和分析师能够更加高效地处理和分析数据。希望本文能够帮助读者更好地利用Pandas进行JSON数据的读取和写入,并在实际工作中取得更好的效果。如有任何疑问或需要进一步的帮助,欢迎随时提问。